

軟件工程基礎-個人項目2014
第一篇專業相關的博客。
項目要求:http://www.rzrgm.cn/jiel/p/3978727.html
1.項目預計時間
雖然大二時java寫過比這個復雜的詞頻統計程序,但是現在對c++或者c#都不熟,因此還是有一定挑戰性,前幾天都不想寫這個程序。
由于對于c++比c#更加了解,因此選擇c#完成程序,一邊加深對c#的理解。不過不打算直接修改java的代碼,準備重新用c#寫。
預計學習c#的時間:4小時
預計程序主要的類有兩個,一個是遍歷目錄和文件的,一個是單詞分析的,預計編寫程序用時:6小時
預計調試時間:4小時
預計優化時間:4小時
2.項目實際用時
學習c#的時間(包含學習加上百度查閱不懂的用法):4小時
編寫程序用時:4小時
調試時間:2小時
優化用時:8小時
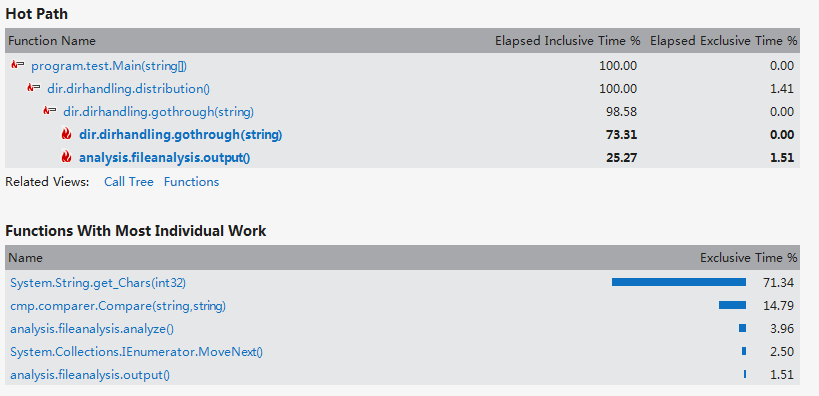
3.程序優化及性能分析
優化用時記錄為8小時,實際上應該不止。事實上在項目的進行過程中我是邊寫程序邊優化的,經常為了得到更優化的編寫方案而卡很久,大部分時間都花在思考如何優化以及查詢優化方法上了。
優化的用時花費在以下幾個點:
遍歷目錄文件、單詞分析,數據存儲,數據排序
遍歷目錄文件優化主要是因為很久沒寫程序了,因此一開始進行目錄遍歷時不知道如何下手(c#不熟),查詢了很多都不奏效,因此對目錄的判斷,目錄的廣度和深度優先掃描都做了小范圍的優化。
單詞分析的編寫就花費了相當長的時間,優化主要是在查漏補缺各種沒有考慮到的情況,添加一下關鍵性語句,對邏輯不嚴密的地方進行補充,這一部分的優化一直做到了最后,一直在發現問題并進行修改。
數據存儲的優化花了相當多的功夫,其實這一部分是在編寫程序中進行的,但我更傾向于把它分類到優化中。一開始也沒多想準備用arraylist或者vector存儲,后來偶然在網上發現學長的項目分析報告,在他的報告中,他提到dictionary能夠極大地提高程序的性能。在msdn中查看之后,我了解到dictionary內部實現是哈希表結構,因此隨機檢索非常快。在項目中搜索重復單詞時對大小寫不敏感,而存儲時敏感。因此可以以單詞的小寫作為鍵,單詞的標準形式以及出現次數構成的對象作為值,這樣方便進行單詞的統計。由于哈希表根據鍵檢索值的時間復雜度是O(1),因此我堅定了使用哈希表的想法。然而哈希表不能索引取值,也就不便進行排序。dictionary類的成員方法中沒有排序的方法,但是項目要求必須排序,而且是多層排序。因此我在哈希表與動態數組之間抉擇不定。雖然后來又發現了ordereddictionary類可以完美地解決哈希表的索引取值問題,進而可以自定義排序。然而ordereddictionary的空間消耗是dictionary的將近三倍,時間也慢一些,這是因為ordereddictionary內部結構式哈希表+數組。這樣我又在dictionary和ordereddictionary之間抉擇不定,很久才做出抉擇使用dictionary。
數據排序也花了相當的功夫。在選擇dictionary作為數據存儲的結構之后,接下來需要尋找dictionary的排序方法,我想了很多方法,比如將鍵設計成小寫字符串與索引拼起來,然后利用正則表達式識別索引,進而進行自定義的快速排序,但是構思了2個多小時后確定該方案無法實現。上網找了一段時間才找到system.linq命名空間的orderby方法可以對dictionary進行排序。但進行多層排序(類似動態排序)卻有些困難。我在網上查閱了很多相關資料,還專門查看了動態排序的底層實現分析,卻仍然沒有結果,大概1小時候才找到利用thenby進行多層排序的方法。寫完之后運行,結果是按照頻度從大到小排序了,但是頻度相同的字符串并沒有按照ASCII碼順序排序。在網上尋找很久也沒有找到答案,嘗試了幾個StringComparer的屬性傳入orderby,也仍然是按照unicode編碼進行排序。最終在我查看msdn的過程中,發現orderby方法支持傳入自定義的實現了比較器接口的比較器類,因此我自定義了一個將字符串按照ASCII碼進行排序的類并傳入orderby中,最終成功得到預期結果,優化ASCII排序至少花了2個小時的時間。
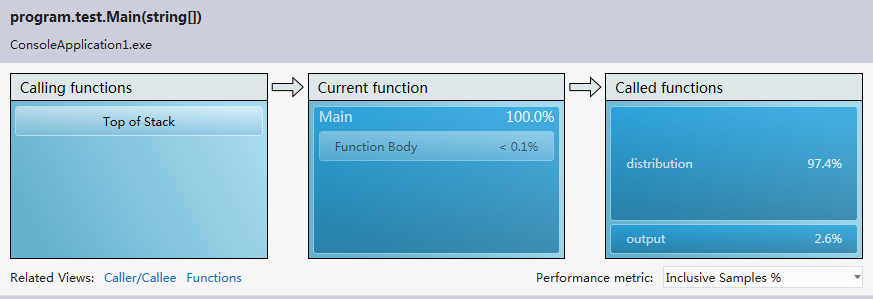
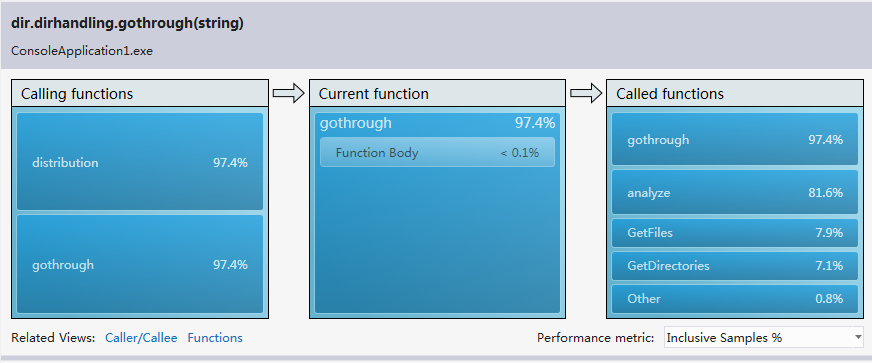
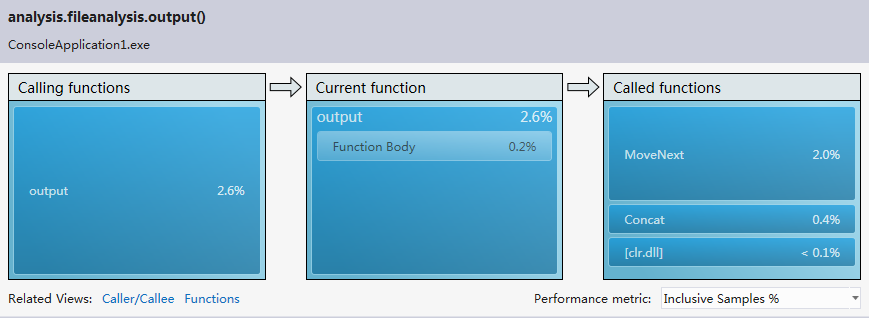
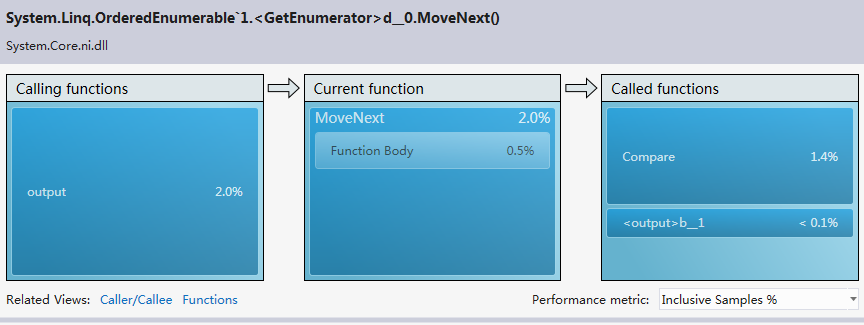
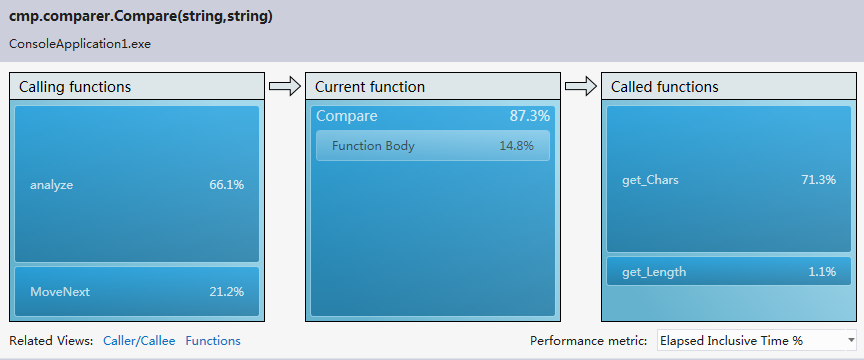
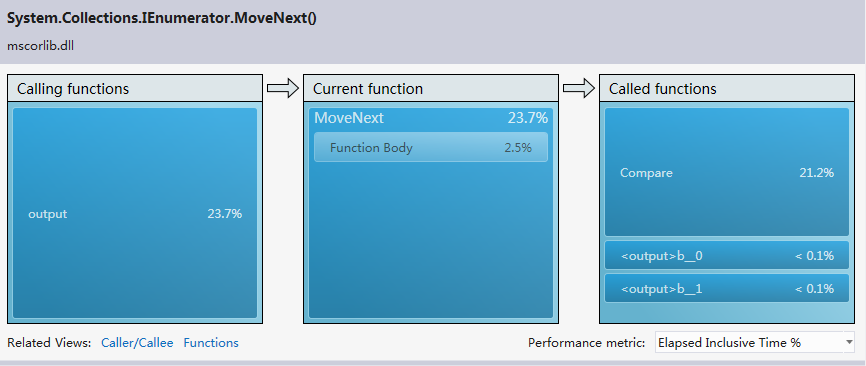
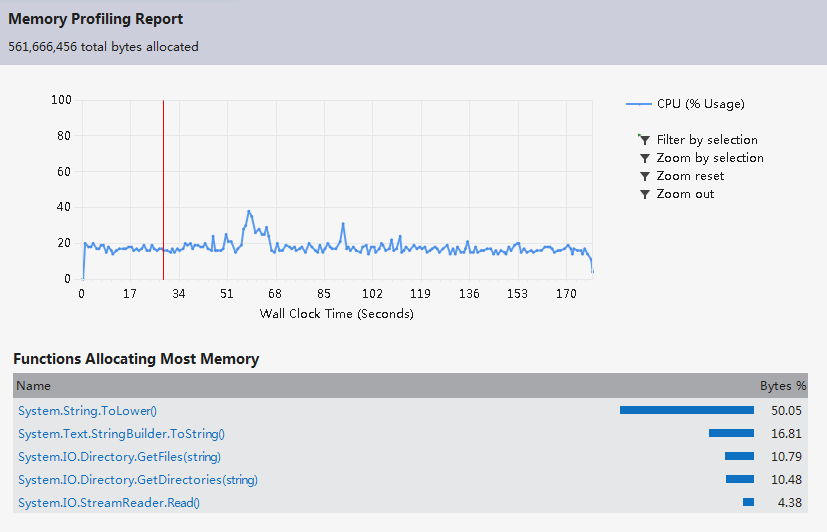
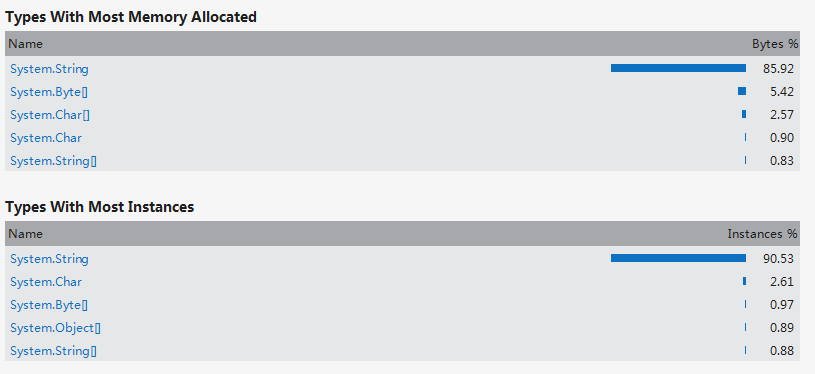
編寫邊優化完第一遍之后進行了程序的性能分析,檢索vs2012的安裝目錄花費了6分46秒的時間,有些太慢,查看error list,發現兩個警告。第一個是對于異常處理過多的警告,另一個是關于垃圾太多以致垃圾處理頻繁的警告。對于第一個警告,我在程序中使用了很多try-catch語句,根據拋出的異常來判斷一個路徑代表的是目錄還是文件,以及處理IO異常。由于程序處理的數據量比較大,因此try-catch語句的調用次數也相當可觀。因此我去掉了所有的try-catch語句,改用其他方法來實現之前借助try-catch語句判斷的功能。性能分析之后,異常處理的警告消失,垃圾處理的警告也消失了,檢索vs2012目錄的時間也由之前的6分多鐘乃至接近十分鐘變為4秒,最多25秒,變為秒級。對于檢索vs2012安裝目錄(大小2.78 GB,占用空間2.86 GB,包含33,443 個文件,6,633 個文件夾),單個單詞用時大約5秒,連續兩個單詞大約用時4秒,連續三個單詞大約用時4秒。當然在變為秒級之前我對單詞分析以及目錄遍歷也做了一定程度的優化。
由于當時做完第一次性能分析后就進行了優化并刪除了性能分析的報告,因此只列出優化之后的性能分析報告,分四種模式的性能分析;
CPU sampling:





Instrumentation:
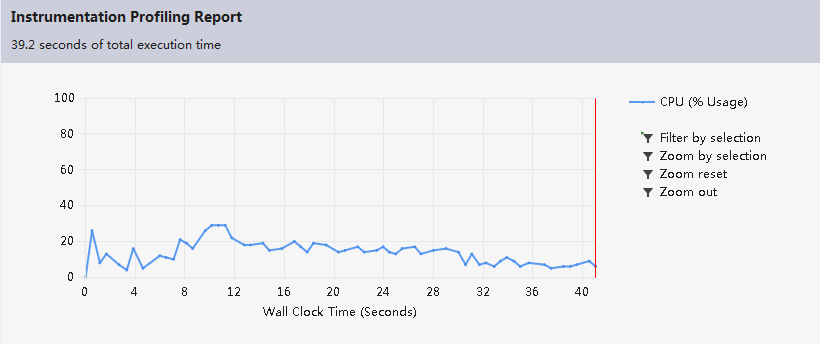


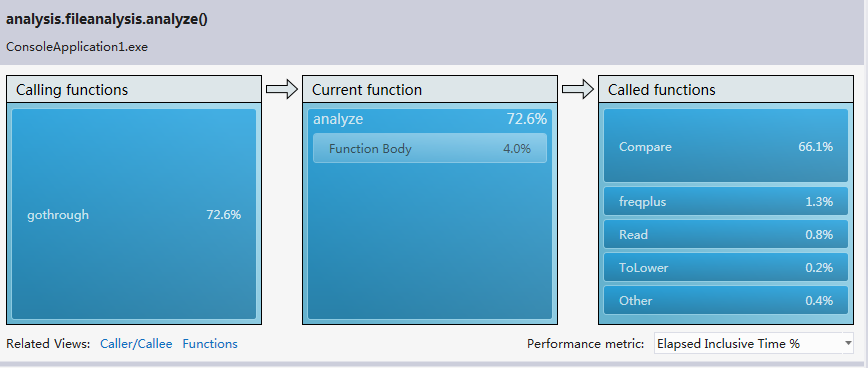

.NET memory allocation(sampling):
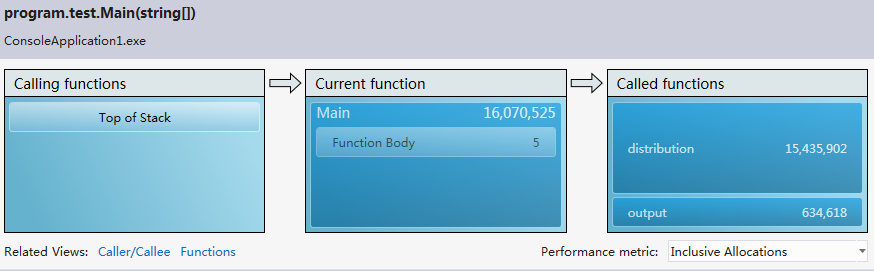
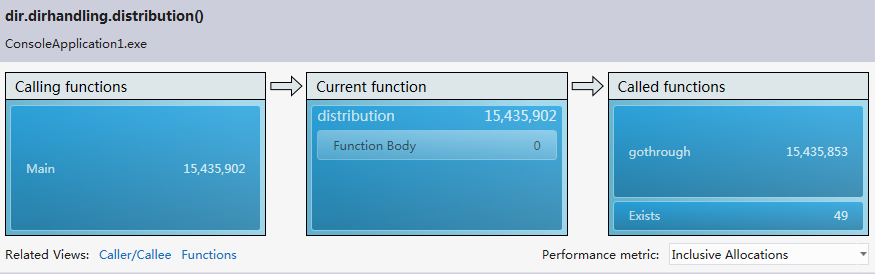
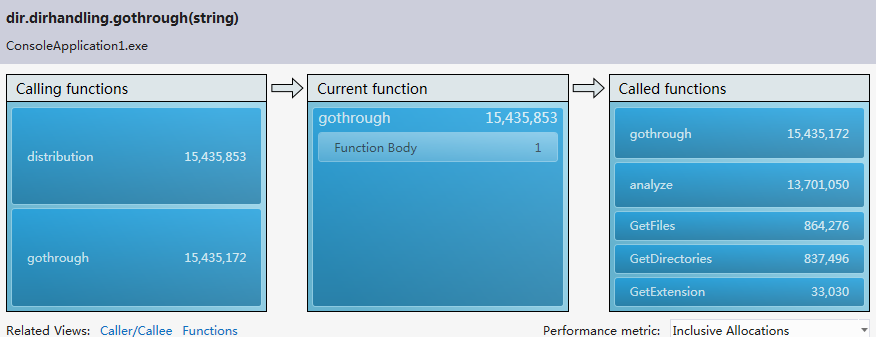

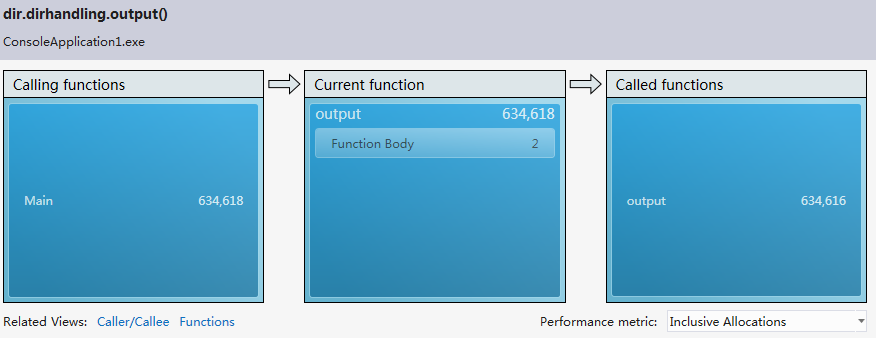

Resource contention data(concurrency):
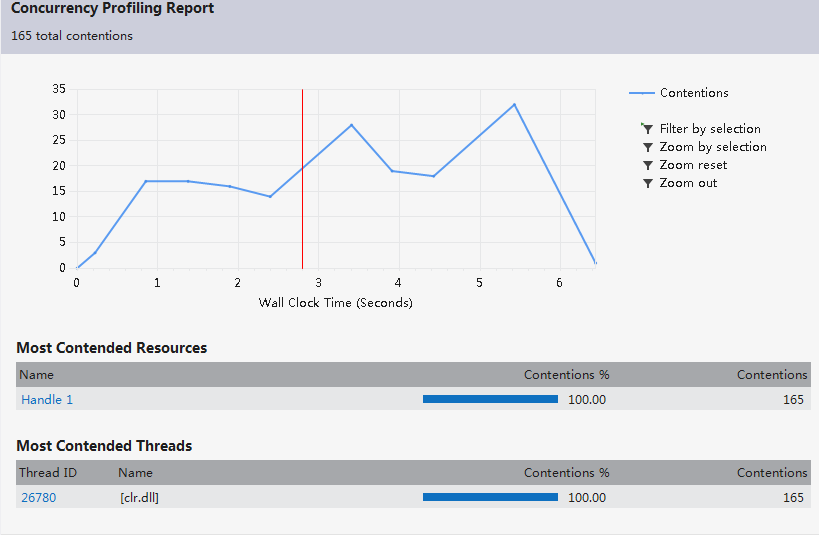


4.項目的測試樣例
(1)測試識別后綴為"txt", "cpp", "h", “cs”的文件
構建了一個文件夾,文件夾內有4個子文件夾,分別裝有后綴為.txt,.cpp,.h,.cs的文件,每個文件內都有該文件獨有的單詞。如果最后輸出文件中四個特殊單詞都有,則說明程序可以識別這些文件。
四個文件的內容:
.cpp文件:hello, this is the c plus plus file
.cs文件:hello, this is the c sharp file
.h文件:hello, this is the header file
.txt文件:hello, this is the txt file
輸出結果:
<file>:4
<hello>:4
<the>:4
<this>:4
<plus>:2
<header>:1
<sharp>:1
<txt>:1
(2)測試按照ASCII碼排序
文件內容:
element Electricyt fjeowajfoap FJEOZZZZZZZZA
classpath 432 423 3&%#classpath Classpathjiou
ElemeNt ElectriCyt fjeoWAjfoap FJEOzzzzzzzZA
輸出結果:
<ElectriCyt>:2
<ElemeNt>:2
<FJEOZZZZZZZZA>:2
<classpath>:2
<fjeoWAjfoap>:2
<Classpathjiou>:1
主要測試在次數相同的情況下對字符串按照ASCII碼順序排序,大寫排在小寫前面。
(3)測試超大文件夾(vs2012安裝目錄)
測試掃描超大文件夾,例如vs2012安裝目錄,測試程序的數據結構及算法是否合理。
vs2012安裝目錄信息:
文件夾名:Microsoft Visual Studio 11.0
大小:2.78 GB (2,995,686,049 字節)
占用空間:2.86 GB (3,080,278,016 字節)
包含:33,443 個文件,6,633 個文件夾
運行結果:
單個單詞:
大約耗時5秒。
結果太長,只截部分:


連續兩詞:
大約耗時4秒。
輸出結果:
<using System>:13086
<param name>:9541
<see cref>:4930
<virtual void>:4072
<unsigned int>:3858
<Return FALSE>:3759
<Return TRUE>:2909
<public static>:2546
<For the>:2291
<WITH THE>:2265
連續三詞:
大約耗時4秒。
輸出結果:
<Microsoft Foundation Classes>:2149
<localized string similar>:1520
<public static string>:1520
<ALL RIGHTS RESERVED>:1496
<public partial class>:1276
<using namespace Windows>:1198
<The message block>:994
<message block type>:976
<Reference and related>:812
<Foundation Classes Reference>:778
(4)測試單詞大小寫的統計情況
文件內容:
file123 file File 123file files
classpath&Classpath&&classPath*claSspAth)*)(*(^%^|~~
輸出結果:
<Classpath>:4
<File>:2
<file123>:1
<files>:1
主要測試統計單詞時的忽略大小寫以及最后輸出時的輸出字典序最小的同類字符串,同時,123file中的file不能被識別為單詞,因為不是被分隔符隔開的,因此File為2個而不是3個。
(5)測試多國語言的輸入情況
文件內容:
Eventually I 一流learn一流ed to stop worrying and love the fまあlow. The pervasiveness of the new multiplicity, and my participation in it, altered my peまあrspective. Altered my Self. The まあtransition was gradual, but eventually I realized I waまあs on the other side.
Eveまあntu一流ally I learned to stop worrying and love the flow. The pervasiveness of the new multiplicity, and my participation in iまあt, altered my perspective. Altereまあd my Self. The transition was gradual, but eventually I realized I wまあas on the other side.
Eventua一流lly I learned ????to st一流op wo一流rryi一流ng and love まあthe flow. The pervasiveness of the new ????multiplicity, and my participatまあion???? in it, altereまあd my perspective. Altered my Self. The transition was gradual, but e????ventually I realized I was???? on the other side.
Eventuall????y I le????arned to stop worry????ing and love t一流he flow. The pervasiveness of the new ????multiplicity, and my participation in it, altered my perspe????ctive. A????ltered my Self. The tまあrans????ition was gradual, but eventually I realized I was ????on the otまあher side.
Eventually I learned to stop worrying and love the flまあowまあ. The pervasiveness of the new multiplicity, and my participation in it, altered my pまあerspective. Altered my Self. The transition was gradual, but eventually I realized I was on the other side.
Event一流ually I learned to stop worrying and love the flow. The pervasiveness of the new multiplicity, and my participation in it, altered my pe????rspecまあtive. Altered my Self. The transition was gradual, but eventually I realized I was on the other side.
Eventually I learne專業的留學趨勢,預估出未????來的????申請結果,從而更有效的做申請定位,針對性的提高。截止目前,該公益????培訓班得到全面推廣,與北大、まあ北航、人まあ大、外經貿、復旦、上海交大、上海財經、上外、西安交大、西????南財大等 30 余所國內著名大學和高中均ま????あ簽署合作協議,開展了公益培訓課程まあ,報名d to stop worrying and love the flow. The pervasiveness of the new multiplicity, and my participation in it, altered my perspective. Altered my Self. The transition was gradual, but eventually I realized I was on the other side.
Evまあentually I learned to stop worrying and love the flow. The pervasiveness of the new multiplicity, and my parti????cipation in it, altered m????y まあperspective. Altered my Sel????f. The transition was gradual, but eventually I realized I was on theまあ other side.
t technologies have serve一流d that purposまあe in the pa一流st. Thanks to Twitter backchannels identified by hashtag s, I was able to pまあarticipate with friends and audiまあencまあe members at some talks at SXSW (5) this past year, despite まあbeing uまあnable to attend in person.
t technol一流ogies have s????まあerved that purpose in the past. Thanks to Twitter backchannels identified by hashtag s, I w????as able to participate witまあh fr????iends and aまあudience memb????ers at some talks at SX????SW (5) this past year, despite being unable to attend in person.
t technologies have served that pur一流pose in the past. Thanks to Twitter backchannels identified by hashtag s, I was???? able to participate with friends and audience members at some talks at SXSW (5) this past year, despite bein????g unable to attend in person.
t technologie專業的留學趨勢,預估出未來的申請結果,從而更有效的做申請定位,針對性的提高。截止目前,該公益培訓班得到全面推廣,與北大、北航、人大、外經貿、復まあ旦、上海交大、上海財經、上外、西安交大、西南財大等 30 余所國內著名大學和高中均簽署合作協議,開展了公益培訓課程,報名s have まあserved ????that purpose in t????he past. Thanks to Twitter backchannels identified by hashtag s, I was able to participate with friends and audience members at some talks at SXSW (5) this past year, despite being unable to attend in person.
t technoまあlogies have served that purpose in the past. Thanks to Twitter backchannels identified by hashtag s, I???? was able to p????articipまあate with friまあends and audiencまあe members at some talks at SXSW (5) this past year, despite being unaまあble to attend in person.
t technolog一流ies hav一流e served that purp一流ose in the past. Thanks to Twitter backchannels identified by hashtag s, I was ab????le to partici????pate with friends and audienまあe members at some t????alks at SXSW (5) t????his past year, despite being unable to attend???? in person.
t technologies have served that purpose in the past. Thanks to Twitter backchannels identified by hashtag s, I was able to participate witまあh friends and aまあudience members ????at some talks at SXSW (5) this past year, despite being unable to attend in person.
專業的留學趨勢,預估出未來的申請結果,從而更有效的做申請定位,針對性的提高。截止目前,該公益培訓班得到全面推廣,與北大、北航、人大、外經貿、復旦、上海交大、上海財經、上外、西安交大、西南財大等 30 余所國內著名大學和高中均簽署合作協議,開展了公益培訓課程,報名
【いくまあゆずやこまな】Carry Me Off【DANCEROID五人組】
????hui????huihiui????iuuyhui????
????????????????????????????
輸出結果:
<The>:45
<and>:23
<was>:20
<Altered>:13
<past>:13
<Eventually>:10
<but>:8
<gradual>:8
<love>:8
<multiplicity>:8
<new>:8
<pervasiveness>:8
<realized>:8
<side>:8
<Self>:7
<Thanks>:7
<Twitter>:7
<attend>:7
<backchannels>:7
<despite>:7
<hashtag>:7
<identified>:7
<other>:7
<person>:7
<some>:7
<stop>:7
<that>:7
<transition>:7
<year>:7
<SXSW>:6
<able>:6
<being>:6
<flow>:6
<have>:6
<members>:6
<participation>:6
<talks>:6
<this>:6
<worrying>:6
<friends>:5
<learned>:5
<served>:5
<unable>:5
<with>:5
<participate>:4
<perspective>:4
<purpose>:4
<technologies>:3
<Altere>:2
<audience>:2
<udience>:2
<wit>:2
<Carry>:1
<DANCEROID>:1
<Eve>:1
<Event>:1
<Eventua>:1
<Eventuall>:1
<Off>:1
<Sel>:1
<alks>:1
<ally>:1
<arned>:1
<articip>:1
<articipate>:1
<ate>:1
<audi>:1
<audien>:1
<audienc>:1
<bein>:1
<ble>:1
<cipation>:1
<ctive>:1
<enc>:1
<ends>:1
<entually>:1
<ers>:1
<erspective>:1
<erved>:1
<fri>:1
<hav>:1
<her>:1
<his>:1
<hui>:1
<huihiui>:1
<iends>:1
<ies>:1
<ing>:1
<ion>:1
<ition>:1
<iuuyhui>:1
<learn>:1
<learne>:1
<lly>:1
<logies>:1
<low>:1
<ltered>:1
<memb>:1
<nable>:1
<ntu>:1
<ogies>:1
<ose>:1
<parti>:1
<partici>:1
<participat>:1
<pate>:1
<perspe>:1
<pose>:1
<pur>:1
<purp>:1
<purpos>:1
<rans>:1
<rryi>:1
<rspec>:1
<rspective>:1
<serve>:1
<techno>:1
<technol>:1
<technolog>:1
<technologie>:1
<tive>:1
<ually>:1
<una>:1
<ventually>:1
<worry>:1
主要測試能否將除英文以外的其他語言,比如中文、日文等,識別為分隔符。
(6)測試對分隔符的識別
文件內容:
fewo 3iafj 646ewaoij &*^fowae&^ijffjo&&(aiwe^jfgers13$%214h$srtg^$ssr^%$
輸出結果:
<aiwe>:1
<fewo>:1
<fowae>:1
<ijffjo>:1
<jfgers13>:1
<srtg>:1
<ssr>:1
測試程序對分隔符的識別。
(7)測試空文件和空文件夾
輸出結果均為空
(8)測試連續兩詞的識別
文件內容:
123file file File FILE
word ranking list useful not exceptional
word rANking list useful not exceptional
word ranking list useful not exceptIONal
word ranking list usEFul not exceptional
you are such a wonderful man
輸出結果:
<list usEFul>:4
<not exceptIONal>:4
<rANking list>:4
<usEFul not>:4
<word rANking>:4
<File FILE>:2
<are such>:1
<wonderful man>:1
<you are>:1
主要測試程序對連續兩詞的識別以及排序。
(9)測試連續三詞的識別
文件內容:
please be quiet pleaSe be quiEt pleaSE BE quiet
please be quiet
Please Be quiet
pLEase be quiet
please be qUIEt
word ranking list is great word raNKing list is great
word ranking list is gREat
word ranKIng list is great
how are you
how Are you
fine thank you and YOU
fine Thank you And you
fine thank YOU and"
this program really drives me crazy
this program rEAlly drives me crazy
this program really drives me cRAzy
THis program really drives me crazy
輸出結果:
<THis program really>:4
<program rEAlly drives>:4
<word raNKing list>:4
<Thank you And>:3
<fine Thank you>:3
<how Are you>:2
<you And you>:2
<great word raNKing>:1
主要測試程序對連續三詞的識別能力以及排序能力。
(10)測試長文章的識別
測試長文章的識別情況。這里選取的是本項目的項目要求。
文件內容:
作業提交截止時間:2014.09.25之前。
Individual Project - Word frequency program
Implement a console application to tally the frequency of words under a directory (2 modes).
For all text files (file extensions: "txt", "cpp", "h", “cs”) under a directory (recursively), calculate the frequency of each word, and output the result into a text file. Write the code in C++ or C#, using .Net Framework, the running environment is 32-bit Win7 or Win 8.
Run performance analysis tool on your code, find performance bottlenecks and improve.
Enable Code Quality Analysis for your code and get rid of all warnings.
Code Quality Analysis: http://msdn.microsoft.com/en-us/library/dd264897.aspx
Write 10 simple test cases to make sure your program can handle these cases correctly (e.g. a good test case could be: one of the sub-directories is empty).
Submission:
Submit your source code and exe to TA, TA will run it on his testing environment and check for
- correctness (incorrect program will get 0 points)
- performance
- write a blog (see blog requirement below)
Definition:
A word: a string with at least 3 English alphabet letters, then followed by optional alphanumerical characters. Words are separated by delimiters. If a string contains non-alphanumerical characters, it’s not a word. Word is case insensitive, i.e. “file”, “FILE” and “File” are considered the same word.
“file123” is a word, and “123file” is NOT a word.
- Alphabetic letters: A-Z, a-z.
- Alphanumerical characters: A-Z, a-z, 0-9.
- Delimiter: space, non-alphanumerical letters.
- Output text file: filename is <your email name>.txt
- Each line has this format
<word>: number
Where <word> is the string, it has to be the exact upper/lower case as shown in the text file. E.g. if only “File” and “file” appear in the test cases, the program should not show “FILE”. <word> should be the first word in dictionary order (based on ASCII). For exmaple, if only “File” and “file” appear in the text file, the program should output “File: 2”.
Where “number” is the number of times this word appears in the scan. The output should be sorted with most frequently word first. If 2 words have the same frequency, list the words by dictionary order.
Requirements:
1) Simple mode. Output simple word frequency.
Myapp.exe <directory-name>
Will output <your-name>.txt file in current directory, the text file contains word ranking list.
2) Extended mode.
在執行 Myapp.exe -e2 <directory-name>時,找出最頻繁出現的連續兩個詞(列出前10名)。例如,在一本英文小說中,“good morning” 出現次數最多。
在執行 Myapp.exe -e3 <directory-name>時,找出最頻繁出現的連續三個詞(列出前10名)。例如“how are you"。
這里連續的詞是指由單個空格分隔的詞。
The app will output <your-name>.txt file in current directory, the text file contains word ranking list.
Blog Requirement:
You can publish this to BOTH your own blog, and your team blog (to help your team blog get some traffic)
1) Before you implement this project, Record your estimate about the time you WILL spend in each component of your program.
2) After you had implemented this project, record the ACTUAL time you spent in each component of your program.
3) Describe how much time you spent on improving the performance of your program, and show a performance analysis graph (generated by VS2012 perf analysis tool), if possible, please show the most costly function in your program.
4) Share your 10 test cases, and how did you make sure your program can produce the correct result. (programs with incorrect result will get 0 points, regardless of speed)
5) Describe what you had learned in this exercise.
輸出結果:
單個單詞:
<The>:28
<FILE>:18
<Word>:17
<your>:17
<and>:12
<program>:10
<You>:9
<Output>:7
<directory>:7
<text>:7
<Blog>:6
<Code>:6
<WILL>:6
<name>:6
<this>:6
<Analysis>:5
<frequency>:5
<performance>:5
<Alphanumerical>:4
<Each>:4
<For>:4
<Words>:4
<cases>:4
<exe>:4
<get>:4
<should>:4
<test>:4
<txt>:4
<Myapp>:3
<NOT>:3
<Project>:3
<Simple>:3
<Write>:3
<are>:3
<can>:3
<case>:3
<characters>:3
<contains>:3
<how>:3
<letters>:3
<list>:3
<number>:3
<result>:3
<show>:3
<string>:3
<time>:3
<with>:3
<Describe>:2
<Implement>:2
<Quality>:2
<Record>:2
<Requirement>:2
<Run>:2
<Where>:2
<all>:2
<appear>:2
<component>:2
<current>:2
<dictionary>:2
<environment>:2
<first>:2
<good>:2
<had>:2
<has>:2
<incorrect>:2
<make>:2
<mode>:2
<most>:2
<non>:2
<only>:2
<order>:2
<points>:2
<ranking>:2
<same>:2
<spent>:2
<sure>:2
<team>:2
<tool>:2
<under>:2
<ACTUAL>:1
<ASCII>:1
<After>:1
<Alphabetic>:1
<BOTH>:1
<Before>:1
<Definition>:1
<Delimiter>:1
<Enable>:1
<English>:1
<Extended>:1
<Framework>:1
<Individual>:1
<Net>:1
<Requirements>:1
<Share>:1
<Submission>:1
<Submit>:1
<Win>:1
<Win7>:1
<about>:1
<alphabet>:1
<app>:1
<appears>:1
<application>:1
<aspx>:1
<based>:1
<below>:1
<bit>:1
<bottlenecks>:1
<calculate>:1
<check>:1
<com>:1
<considered>:1
<console>:1
<correct>:1
<correctly>:1
<correctness>:1
<costly>:1
<could>:1
<cpp>:1
<delimiters>:1
<did>:1
<directories>:1
<email>:1
<empty>:1
<estimate>:1
<exact>:1
<exercise>:1
<exmaple>:1
<extensions>:1
<file123>:1
<filename>:1
<files>:1
<find>:1
<followed>:1
<format>:1
<frequently>:1
<function>:1
<generated>:1
<graph>:1
<handle>:1
<have>:1
<help>:1
<his>:1
<http>:1
<implemented>:1
<improve>:1
<improving>:1
<insensitive>:1
<into>:1
<learned>:1
<least>:1
<library>:1
<line>:1
<lower>:1
<microsoft>:1
<modes>:1
<morning>:1
<msdn>:1
<much>:1
<one>:1
<optional>:1
<own>:1
<perf>:1
<please>:1
<possible>:1
<produce>:1
<programs>:1
<publish>:1
<recursively>:1
<regardless>:1
<rid>:1
<running>:1
<scan>:1
<see>:1
<separated>:1
<shown>:1
<some>:1
<sorted>:1
<source>:1
<space>:1
<speed>:1
<spend>:1
<sub>:1
<tally>:1
<testing>:1
<then>:1
<these>:1
<times>:1
<traffic>:1
<upper>:1
<using>:1
<warnings>:1
<what>:1
連續兩詞:
<text file>:6
<your program>:6
<the text>:4
<Alphanumerical characters>:3
<test cases>:3
<time you>:3
<Blog Requirement>:2
<Code Quality>:2
<Quality Analysis>:2
<Will output>:2
連續三詞:
<the text file>:4
<Code Quality Analysis>:2
<contains word ranking>:2
<file contains word>:2
<make sure your>:2
<sure your program>:2
<text file contains>:2
<the program should>:2
<time you spent>:2
<word ranking list>:2
如何保證程序能輸出正確結果:
首先根據項目要求對程序的邏輯結構以及各種單詞分析情況對程序進行了邏輯結構的分析與檢查,減少、避免程序的邏輯漏洞。
其次,設計多樣化的測試用例測試程序的正確性。
以上兩步能夠很大程度上地保證程序的正確性,但仍不能絕對地保證,程序在使用過程中有可能暴露出各種難以想象的錯誤,需要不斷地進行維護。
5.項目經驗與收獲
雖說不是第一次做項目,但是用c#做項目還是第一次。在項目的進行過程中,我體會到c#語言的便利,尤其是c#提供的dictionary類,哈希表的結構為檢索提供了O(1)的時間復雜度,大大減少了程序運行的時間,而哈希結構在我之前的項目中是沒有被用過的。雖然哈希結構不利于索引,也沒有排序的成員方法,但是c#提供了ordereddictionary犧牲空間,以內在的哈希表+數組的形式提供了索引取值,進而可以進行自定義排序;system.linq命名空間中的enumerable類的orderby和theyby方法可以對dictionary進行排序,同時進行多層排序以及按照不同編碼規則的排序以及自定義的排序,為程序的多樣化提供了便利。linq中的orderby排序方法在dictionary類的extension method中列有,但是因為不是成員方法所以我就沒看,導致上網查資料花費了很多時間!下次一定要看看msdn中類下面的extension method,積累一些能夠在該類上實行的方法。同時,c#高度的面向對象思想以及與java的相似性也使得我很快上手,這也充分體現了把一部分語言和思想學透理解,其他的語言就很容易上手的道理。
這次使用了新的IDE:vs2012.之前一直是用的VC6.0。vs2012并沒有想象中那么耗內存,簡潔而優雅的界面設計讓我眼前一亮。最讓我印象深刻的就是它的性能分析功能。在之前做java程序的時候,也使用過junit作為代碼測試工具以及tptp作為性能分析工具。vs2012的性能分析工具跟tptp一樣功能強大,并且有不同的模式,而vs2012的顯示較tptp更為形象,主要表現在summary的折線圖,hot path的分析以及function details中的圖表分析,讓我了解到自己的程序那些部分調用次數多,運行時間長;哪些部分占用內存較大,哪些部分占用CPU較大,以及在本項目中用不到的多線程競爭情況分析。最有用的是,在下方的error list中會提出error或者warning,我將兩個warning修改之后程序效率提高了很多倍,從分鐘級變為秒鐘級。在warning中,vs指出了我的程序中的幾個大問題,比如異常處理過多,垃圾太多導致垃圾處理頻繁等。這些vs的性能分析以及警示都使程序開發者享有更好地編程體驗,能夠更快地發現錯誤以及程序中的問題并及時修復,不得不說這一次我對vs刮目相看了。有趣的是,eclipse(我開發java的IDE)雖然有tptp插件作為性能分析工具,但是到jre1.5之后就不再支持了,換句話說,tptp在2011年左右之后就不再更新了,導致我在新版本的Eclipse上無法使用tptp進行性能分析,只能使用Eclipse 進行java EE開發才能使用tptp進行性能分析。而vs2012的性能分析功能還在一直變得更好。
在調試的過程中,我經常會被一些莫名其妙的錯誤輸出而困擾。這些錯誤輸出大多是部分錯誤,而由于程序較長,找問題也有一定難度。每次發現問題都是非常細微的,比如少寫了一句語句,或者某一句語句放錯了位置,都有可能導致結果的錯誤。這也對我提出了要求。在寫程序的時候就要邏輯清晰并且注意細節,這樣在調試的時候才會輕松一些。
這次項目的經歷,也讓我明白msdn以及網絡的巨大用處。在查詢msdn的過程中,我系統地了解了dictionary等類的用法以及使用內涵,msdn中配有的用例也讓我頗受啟發。而網絡上具有相似經歷的網友的博客也讓我受益匪淺。這些網友將他們的經驗在cnblog、csdn等地進行分享,讓我在茫然無助的時候看到了曙光,節省了很多時間,我也因此明白,分享是一個互惠互利的過程。因此這一次我把自己的項目經歷寫出來,供大家參考,也讓有相同困惑的網友們了解一些我的經驗教訓,獲得一些可能的啟發。
同時要感謝我的同學們。在你們的博客中,我得到了很多啟示。在與同學以及老師的討論過程中,我們都收獲了更多東西,既方便了他人參考,給予啟迪,同時間接地讓他人檢查自己博客中的錯誤,從而達到雙贏。面對即將開始的結對編程以及團隊項目,我希望自己能夠在與他人更好地合作中收獲更多的知識與友誼,促進團隊和自身的發展。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號