

本項目將會對B站番劇排行的數據進行網頁信息爬取以及數據可視化分析
首先,準備好相關庫
requests、pandas、BeautifulSoup、matplotlib等
因為這是第三方庫,所以我們需要額外下載
下載有兩種方法(以requests為例,其余庫的安裝方法類似):
(一)在命令行輸入
前提:裝了pip( Python 包管理工具,提供了對Python 包的查找、下載、安裝、卸載的功能。 )
(二)通過PyCharm下載
第一步:編譯器左上角File–>Settings…
第二步:找到Project Interpreter 點擊右上角加號按鈕,彈出界面上方搜索庫名:requests,點擊左下角Install ,當提示successfully時,即安裝完成。

準備工作做好后,開始項目的實行
一、獲取網頁內容
def get_html(url):
try:
r = requests.get(url) # 使用get來獲取網頁數據
r.raise_for_status() # 如果返回參數不為200,拋出異常
r.encoding = r.apparent_encoding # 獲取網頁編碼方式
return r.text # 返回獲取的內容
except:
return '錯誤'
def main():
url = 'https://www.bilibili.com/v/popular/rank/bangumi' # 網址
html = get_html(url) # 獲取返回值
print(html) # 打印
if __name__ == '__main__': #入口
main()
爬取結果如下圖所示:
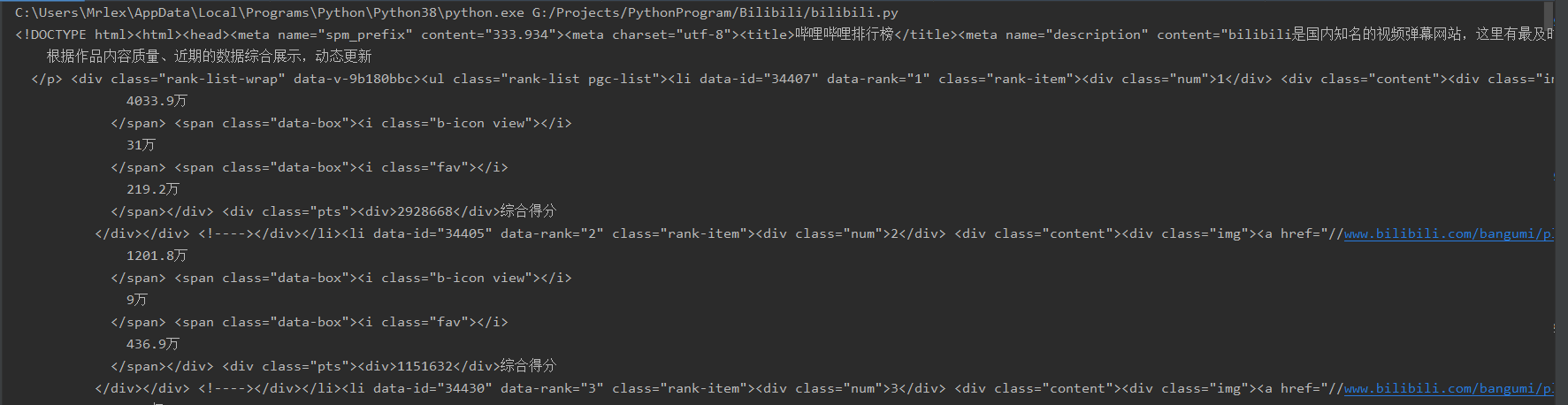
二、信息解析階段:
第一步,先構建BeautifulSoup實例
soup = BeautifulSoup(html, 'html.parser') # 指定BeautifulSoup的解析器
第二步,初始化要存入信息的容器
# 定義好相關列表準備存儲相關信息 TScore = [] # 綜合評分 name = [] # 動漫名字 play= [] # 播放量 review = [] # 評論數 favorite= [] # 收藏數
第三步,開始信息整理
我們先獲取番劇的名字,并將它們先存進列表中
# ******************************************** 動漫名字存儲
for tag in soup.find_all('div', class_='info'):
# print(tag)
bf = tag.a.string
name.append(str(bf))
print(name)
此處我們用到了beautifulsoup的find_all()來進行解析。在這里,find_all()的第一個參數是標簽名,第二個是標簽中的class值(注意下劃線哦(class_=‘info’))。
接著,我們用幾乎相同的方法來對綜合評分、播放量,評論數和收藏數來進行提取
# ******************************************** 播放量存儲
for tag in soup.find_all('div', class_='detail'):
# print(tag)
bf = tag.find('span', class_='data-box').get_text()
# 統一單位為‘萬’
if '億' in bf:
num = float(re.search(r'\d(.\d)?', bf).group()) * 10000
# print(num)
bf = num
else:
bf = re.search(r'\d*(\.)?\d', bf).group()
play.append(float(bf))
print(play)
# ******************************************** 評論數存儲
for tag in soup.find_all('div', class_='detail'):
# pl = tag.span.next_sibling.next_sibling
pl = tag.find('span', class_='data-box').next_sibling.next_sibling.get_text()
# *********統一單位
if '萬' not in pl:
pl = '%.1f' % (float(pl) / 10000)
# print(123, pl)
else:
pl = re.search(r'\d*(\.)?\d', pl).group()
review.append(float(pl))
print(review)
# ******************************************** 收藏數
for tag in soup.find_all('div', class_='detail'):
sc = tag.find('span', class_='data-box').next_sibling.next_sibling.next_sibling.next_sibling.get_text()
sc = re.search(r'\d*(\.)?\d', sc).group()
favorite.append(float(sc))
print(favorite)
# ******************************************** 綜合評分
for tag in soup.find_all('div', class_='pts'):
zh = tag.find('div').get_text()
TScore.append(int(zh))
print('綜合評分', TScore)
其中有個.next_sibling是用于提取同級別的相同標簽信息,如若沒有這個方法,當它找到第一個’span’標簽之后,就不會繼續找下去了(根據具體情況來疊加使用此方法);
還用到了正則表達式來提取信息(需要導入庫‘re’)
最后我們將提取的信息,存進excel表格之中,并返回結果集
# 存儲至excel表格中
info = {'動漫名': name, '播放量(萬)': play, '評論數(萬)': review,'收藏數(萬)': favorite, '綜合評分': TScore}
dm_file = pandas.DataFrame(info)
dm_file.to_excel('Dongman.xlsx', sheet_name="動漫數據分析")
# 將所有列表返回
return name, play, review, favorite, TScore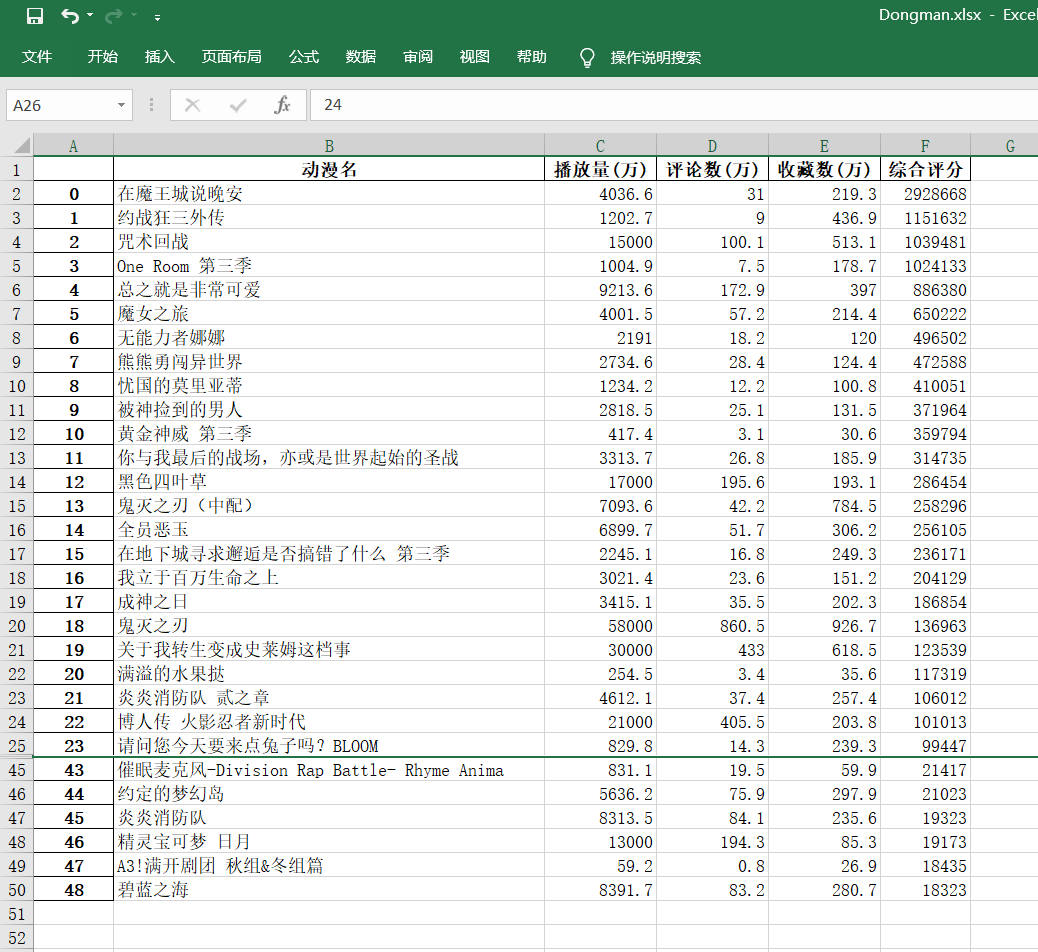

 浙公網安備 33010602011771號
浙公網安備 33010602011771號