
痞子衡嵌入式:在i.MXRTxxx下使能DMA鏈式傳輸可達到SPI從設備接收速率上限50Mbps
大家好,我是痞子衡,是正經搞技術的痞子。今天痞子衡給大家介紹的是i.MXRT下使能DMA鏈式傳輸可達到SPI從設備接收速率上限50Mbps。
最近痞子衡在幫一個 RT600 的 AR 眼鏡客戶優化 SPI 從設備接收數據的速率,我們知道 SPI 從設備接收數據方法一般有三種:1) 輪詢模式,2) 中斷模式,3) DMA 模式。前兩種模式都會受到 CPU 性能的限制,而 DMA 模式則可以最大程度地降低 CPU 負載,提高數據傳輸效率以及速率。
然而使用 DMA 傳輸也會有潛在問題,單次 DMA 傳輸數據長度有上限(受限于 DMA 通道緩沖區長度),如果在一次 DMA 傳輸結束之后才開始手動啟動下一次 DMA 傳輸,中間的延遲則有可能導致漏收數據,這時我們就需要使用 DMA 鏈式傳輸(Linked Transfer)來解決潛在漏收數據問題。這便是今天我們要討論的話題:
- Note1:本文方法主要針對 RT500/600 上的 DMA(又稱LPC_DMA),其來自于恩智浦 LPC 系列。
- Note2:RT700/RT4digits 上的 eDMA 與 LPC_DMA 完全不同,其來自于原飛思卡爾 Kinetis 系列(KL25 DMA是第一代,K60 eDMA算第二代)。
一、Flexcomm SPI速率
在討論這個話題之前,我們先來看一下 RT500/600 上的 SPI 外設本身速率。我們知道 RT3digits 上有一個非常神奇的外設 Flexcomm(與之對應的是 RT4digits 上的 FlexIO),這個外設可以按照用戶需求被配置成 USART, SPI, I2C 或者 I2S 外設功能之一。
RT3digits 內部一般會有多個 Flexcomm,而其本身又分為普通和專用兩種類型:普通 Flexcomm 內部結構復雜,因為外設功能配置靈活性而稍稍放棄了一點傳輸性能;專用 Flexcomm 則限定用于特定外設功能,放棄了靈活性,但是傳輸性能更高。下面是芯片數據手冊里找到的 SPI 速率:
| 芯片系列 | 普通SPI Master/Slave:TX/RX - 25Mbps |
高速SPI Master:TX/RX - 50Mbps Slave:RX - 50Mbps, TX - 35Mbps |
|---|---|---|
| RT500 | Flexcomm 0-8, 10-12 | 專用 Flexcomm 14,16 |
| RT600 | Flexcomm 0-7 | 專用 Flexcomm 14 |
二、為什么必須要用DMA?
下圖是 Flexcomm 模塊簡圖,其內部對于收發均配置了一個深度為 8 entries 的 FIFO(對于 SPI frame 長度硬件上能直接支持 4-16 bits,所以這里 entries 是以 frame 長度為單位。如果配置為最常用的 8bits frame,那 FIFO 就能緩存 8bytes 數據),有一定的數據緩存能力,不至于因 CPU 響應不及而立即漏數據。
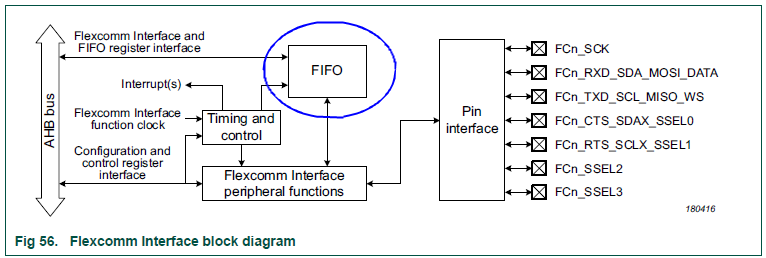
文章開頭說了 SPI 從設備接收數據方法有三種,我們來一一具體分析:
- 輪詢方式: CPU 每隔一段時間就來讀一次 SPI RX FIFO 狀態寄存器,一旦有數據就立刻取走,這種方法能夠達到速率上限 50Mbps,但是代價是 275/300MHz 的 CPU 需要付出相當大的負載地在這輪詢 SPI RX FIFO 寄存器狀態,這對于應用程序設計太不友好,稍稍不慎就會漏數據,顯得匆匆忙忙,一般不會這么用。
- 中斷方式: 預先設置一下 SPI RX FIFO 的 level trigger point(1-8 entries),當 RX FIFO 中數據達到這個水平時就觸發中斷,在 ISR 里把數據取走。這種方法可以降低 CPU 負載,但是由于 Cortex-M33 中斷延遲較大,再加上 ISR 代碼執行時間消耗導致可能達不到速率上限 50Mbps(理想情況下需要 FIFO 觸發設 4 entries,然后一次 ISR 讀取 4 個 entries 數據),ISR 加點代碼都需要謹慎,顯得小心翼翼,因此也不太推薦。
- DMA方式: 利用 DMA 來自動搬運 SPI RX FIFO 中的數據到指定 Buffer 中(最長 1024 個 SPI frame),完全不需要 CPU 參與,這種方式可以最大程度地降低 CPU 負載,并且可以輕松達到 50Mbps 的速率上限,此時才算是游刃有余,唯一需要注意的是,單次 DMA 傳輸長度有上限,需要使用 DMA 鏈式傳輸來避免數據漏收。
三、LPC_DMA功能介紹
看起來這種情況下 DMA 是必須要用了,那我們就來簡單了解一下 LPC_DMA 功能,下圖是其原理框圖。首先我們要知道一個 DMA 會包含多個 channel(RT600 上是 33 個,RT500上是 37 個),各 channel 均可以獨立工作(當然也可以合作)。對于每個 channel 獨立工作,我們需要重點了解四個最基本的概念:
- src/dest data: DMA 本質上是數據搬運,從源地址到目的地址,源/目的地址既可以是一般內存,也可以是外設寄存器,因此從類型上就分為:內存->內存、內存->外設、外設->內存、外設->外設(這種類型一般需要特殊設計,RT3digits 不直接支持)。
- XFER Count: 一次 DMA 傳輸搬運的數據量,是可配置的,RT500/600 里上限均是 1024 個 units(每個 unit 長度 8/16/32bits 可配)。
- DMA requests: 指 DMA 數據搬運涉及外設寄存器時,源/目的地址對應哪種外設,這里每個 channel 設計是定死的,比如 RT600 上 DMA0 channel 26 僅能接收 Flexcomm 14 SPI 的 RX 請求。
- DMA triggers: 指觸發 DMA 開始工作的條件,每個 channel 相同,除了最基本的軟件直接觸發之外,均可以配置不同硬件觸發條件(RT600 上是 25 個,RT500 上是 27 個),這些硬件觸發條件包含各種外設中斷、其他 DMA channel trigger output 等。
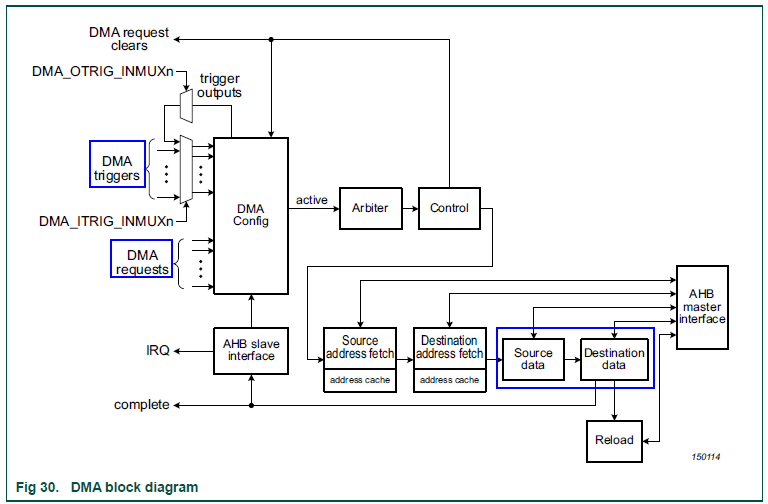
了解了 DMA 基本概念,我們還需要再進一步了解下 DMA 數據傳輸的幾種方式(這里均針對單 channel 而言):
- Single buffer: 這是最基礎的單次 DMA 傳輸方式(一般用于內存到內存),并且源/目的地址均是線性不間隔增長。
- Linked transfers: 這是將多次 DMA 傳輸串起來(數量不限,僅受限于內存容量,即只要你有足夠的 Buffer),一次傳輸結束自動轉到下一次傳輸。這里包含了一個非常常用的場景:當僅串 2 次 DMA 傳輸時(利用雙 Buffer 循環工作),這叫乒乓傳輸(Ping-pong Transfer)。
- Interleaved transfers: 這是一種特殊的 DMA 傳輸方式,可建立在 Linked transfers 基礎之上,但是源/目標地址增長可按一定步長,適用于預處理音頻/圖像數據場合(比如二維圖像數據里僅提取每行/列數據,多通道音頻數據里僅提取單通道數據)。
有了上面的鋪墊,現在我們很自然地想到可以把多個 DMA channel 串起來一起工作,channel A 完成觸發 channel B 繼續工作,那就是所謂的 Channel chaining 模式。此外,雖然原則上多個 channel 可以并行工作,但是如果涉及到總線帶寬限制或者內存訪問沖突,我們還可以為其設置響應優先級,RT500/600 上一共支持 8 檔優先級(每次仲裁時始終從最高優先級 channel 開始檢查,并選擇第一個處于激活狀態的 channel 進行服務)。
四、使能SPI DMA鏈式傳輸方法
關于 DMA 本身的鏈式傳輸示例可直接參考 \SDK_25_09_00_EVK-MIMXRT685\boards\evkmimxrt685\driver_examples\dma\linked_transfer 例程,這個例程設計非常簡單清晰,代碼過程一目了然,實現的功能就是將 s_srcBuffer1 和 s_srcBuffer2 數據往 s_destBuffer 里搬,如果 DMA_Callback 里不做任何處理,那么將會一直循環搬移。
#include "fsl_dma.h"
static dma_handle_t s_DMA_Handle;
SDK_ALIGN(dma_descriptor_t s_dma_table[2], 16U);
SDK_ALIGN(uint32_t s_srcBuffer1[4], sizeof(uint32_t));
SDK_ALIGN(uint32_t s_srcBuffer2[4], sizeof(uint32_t));
SDK_ALIGN(uint32_t s_destBuffer[8], sizeof(uint32_t));
// 一次 DMA 傳輸結束用戶回調(對應一個 DMA 傳輸描述符里的工作)
void DMA_Callback(dma_handle_t *handle, void *param, bool transferDone, uint32_t tcds)
{
// Do someting
}
// 初始化 DMA0 通道 0
DMA_Init(DMA0);
DMA_CreateHandle(&s_DMA_Handle, DMA0, 0);
DMA_EnableChannel(DMA0, 0);
DMA_SetCallback(&s_DMA_Handle, DMA_Callback, NULL);
// DMA 傳輸屬性配置(uint大小為4bytes,源和目標地址均按1個unit自增,一次傳輸16bytes,使能reload特性和INTB)
uint32_t xferCfg = DMA_SetChannelXferConfig(true, false, false, true, 4U, kDMA_AddressInterleave1xWidth, kDMA_AddressInterleave1xWidth, 16U);
// 初始化兩個 DMA 傳輸描述符,并且將其互相鏈接
DMA_SetupDescriptor(&(s_dma_table[0]), xferCfg, s_srcBuffer1, &s_destBuffer[0], &(s_dma_table[1]));
DMA_SetupDescriptor(&(s_dma_table[1]), xferCfg, s_srcBuffer2, &s_destBuffer[4], &(s_dma_table[0]));
// 將第一個 DMA 傳輸描述符賦給 DMA0 通道 0
DMA_SubmitChannelDescriptor(&s_DMA_Handle, &(s_dma_table[0]));
// 軟件觸發 DMA0 通道 0 開始工作
DMA_StartTransfer(&s_DMA_Handle);
但是很遺憾的是 SDK 中并沒有現成的 SPI RX DMA 鏈式傳輸例程,在僅有的 \SDK_25_09_00_EVK-MIMXRT685\boards\evkmimxrt685\driver_examples\spi\dma_b2b_transfer\slave\ 例程里,它也僅是啟動單次傳輸,查看其代碼,我們發現根本原因是 fsl_spi_dma.c 驅動(V2.2.2)里從設計上就不支持鏈式傳輸。
SPI_SlaveTransferDMA() -> SPI_MasterTransferDMA() ->
SPI_TransferSetupRxContextDMA(handle, xfer);
SPI_EnableRxDMA(base, true);
SPI_TransferSubmitNextRxDMA(base, handle); // 問題出在這個函數設計上
handle->rxInProgress = true;
DMA_StartTransfer(handle->rxHandle);
在 SPI_TransferSubmitNextRxDMA() 函數里,其默認使用內部 s_dma_descriptor_table 描述符,每次只提交單次 DMA 傳輸,禁止了 reload 功能,這個函數顯然是為了被多次調用去連續順序數據傳輸而設計的,因此要想實現 DMA 鏈式傳輸,我們必須改造這個函數。
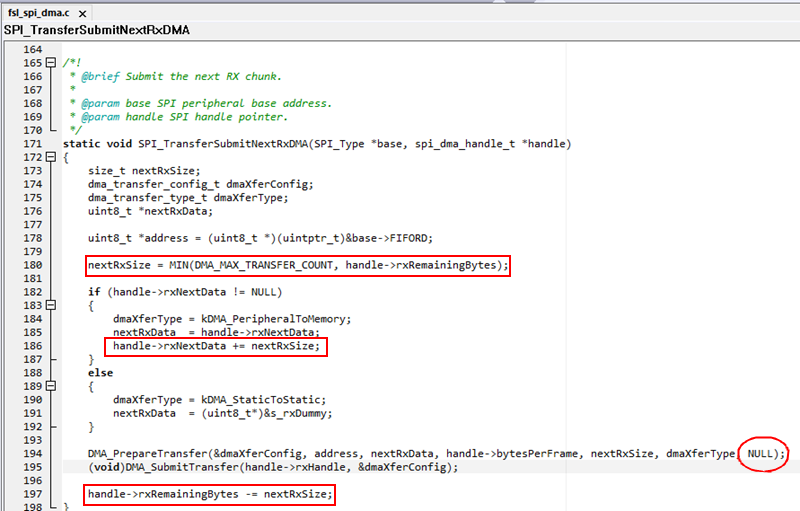
具體改造過程,痞子衡就不一一贅述了,大家直接看下面代碼吧,只是改造過程中還是有一些坑需要注意的,這些都是痞子衡調試時的血淚教訓。
https://github.com/JayHeng/perf-rt600-fcspi-dma-linked-transfer/blob/main/devices/MIMXRT685S/drivers/fsl_spi_dma.c
坑1:鏈式傳輸時 DMA_SubmitTransfer() 函數里不能判斷 DMA_ChannelIsActive(),否則初始化提交第二個 DMA 傳輸描述符時會直接返回 busy
坑2:鏈式傳輸時 SPI_TransferRxHandlerDMA() 中斷處理要重新設計,不要根據 rxInProgress、rxRemainingBytes 狀態來決定是否調用用戶回調函數
坑3:鏈式傳輸時 spiHandle->state 狀態不要在中斷里改變成 kSPI_Idle 狀態,否則 SPI_MasterTransferGetCountDMA() 函數會失效
至此,i.MXRT下使能DMA鏈式傳輸可達到SPI從設備接收速率上限50Mbps痞子衡便介紹完畢了,掌聲在哪里~~~
歡迎訂閱
文章會同時發布到我的 博客園主頁、CSDN主頁、知乎主頁、微信公眾號 平臺上。
微信搜索"痞子衡嵌入式"或者掃描下面二維碼,就可以在手機上第一時間看了哦。

最后歡迎關注痞子衡個人微信公眾號【痞子衡嵌入式】,一個專注嵌入式技術的公眾號,跟著痞子衡一起玩轉嵌入式。



衡杰(痞子衡),目前就職于恩智浦(NXP)半導體MCU系統應用部門,擔任高級嵌入式系統應用工程師。
專欄內所有文章的轉載請注明出處:http://www.rzrgm.cn/henjay724/
與痞子衡進一步交流或咨詢業務合作請發郵件至 hengjie1989@foxmail.com
可以關注痞子衡的Github主頁 https://github.com/JayHeng,有很多好玩的嵌入式項目。
關于專欄文章有任何疑問請直接在博客下面留言,痞子衡會及時回復免費(劃重點)答疑。
痞子衡郵箱已被私信擠爆,技術問題不推薦私信,堅持私信請先掃碼付款(5元起步)再發。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號