
痞子衡嵌入式:MCUXpresso IDE下設置代碼編譯優(yōu)化等級的幾種方法
大家好,我是痞子衡,是正經搞技術的痞子。今天痞子衡給大家分享的是MCUXpresso IDE下設置代碼編譯優(yōu)化等級的幾種方法。
最近公司芯片設計團隊正在開發(fā)一款全新的基于 Cortex-M33 內核的芯片,為了保證芯片性能達標,驗證團隊將 coremark 基準測試程序也當作了一個測試用例,而在 RTL 環(huán)境里指定的 C 編譯器是標準 GCC,驗證團隊發(fā)現跑出來的 coremark 程序測試結果與 Arm 給的 Cortex-M33 參考值 4.02 CoreMark/MHz 有一定差距,痞子衡參與了這個問題調查。
在 Arm Cortex-M33 官方主頁,其備注了 4.02 CoreMark/MHz 參考值來自于 EEMBC 官網上的一款 恩智浦 LPC55S69JBD100 芯片跑出來的結果,頁面里備注了跑分結果是在 Arm Clang Compiler v6.12 下開啟最高優(yōu)化等級 -Omax 下得到的,而驗證團隊用得是 GCC,痞子衡斷定問題大概率是由不同編譯器優(yōu)化性能差異引起的,借著這個實際問題,今天痞子衡跟大家聊一聊 MCUXpresso IDE 下編譯優(yōu)化等級設置方法。
- Note:本文使用的 MCUXpresso IDE 軟件版本是 v11.6.0_8187。
一、查看MCUX下GCC版本
有朋友可能會覺得奇怪,文章開頭里明明聊得是 GCC 下 coremark 跑分問題,為何痞子衡引出了 MCUXpresso IDE?其實 MCUXpresso IDE 是恩智浦推出的免費集成開發(fā)環(huán)境,其底層編譯器就是標準 GCC 工具鏈,使用 MCUXpresso IDE,我們就不用像使用 GCC 那樣手動準備相應 Makefile 去做編譯了。
因為我們是借助 MCUXpresso IDE 來測試 GCC 編譯優(yōu)化性能,所以需要了解當前 GCC 版本,可以在 MCUXpresso IDE 安裝目錄如下路徑下找到 GCC 版本信息。執(zhí)行 arm-none-eabi-gcc.exe -v 命令即可知道其版本,MCUXpresso IDE v11.6 使用得是 GCC v10.3.1。
\MCUXpressoIDE_11.6.0_8187\ide\tools\bin\arm-none-eabi-gcc.exe
\MCUXpressoIDE_11.6.0_8187\ide\tools\lib\gcc\arm-none-eabi\10.3.1
二、GCC支持的優(yōu)化等級
既然咱們聊得是優(yōu)化等級設置方法,首先我們得知道 GCC 下支持哪些優(yōu)化等級,我們可以在 MCUXpresso IDE 安裝目錄或者 GCC 官網找到用戶手冊(gcc.pdf),手冊里面 Section 3.11 Options that Control Optimization 章節(jié)有詳細的解釋。
\MCUXpressoIDE_11.6.0_8187\ide\tools\share\doc\gcc-arm-none-eabi\pdf\gcc.pdf
https://gcc.gnu.org/onlinedocs/gcc-10.3.0/gcc.pdf
GCC 本身支持非常多的優(yōu)化策略小項,大概有如下 100 多個,可以在手冊里去看每個小項的具體解釋,了解了這些小項,我們在編譯時當然可以把這些策略參數按需加上去,不過這種方式顯然比較繁瑣。

GCC 為了化繁為簡,將這些策略小項做了分類整理,形成了如下 8 個等級(基于代碼大小和運行速度兩個方向逐步加檔),我們在實際編譯時一般直接用這 8 個優(yōu)化等級即可。
| 優(yōu)化等級 | 策略解釋 |
|---|---|
| -O0 | 不進行任何優(yōu)化(如果沒有指定優(yōu)化級別,即為此默認設置)。 |
| -O或者-O1 | 在不影響編譯速度的前提下,盡量采用一些優(yōu)化算法降低代碼大小和提高可執(zhí)行代碼的運行速度。 -此等級執(zhí)行了 45 個策略小項。 |
| -O2 | 犧牲部分編譯速度,采用幾乎所有的目標配置支持的優(yōu)化算法,用以提高目標代碼的運行速度。 -此等級在-O1所有優(yōu)化策略小項之上增加了 48 個策略小項。 |
| -O3 | 采取很多向量化算法,提高代碼的并行執(zhí)行程度,比如利用現代CPU中的流水線,Cache等,目標是寧愿增加目標代碼的大小,也要拼命的提高運行速度。 -此等級在-O2所有優(yōu)化策略小項之上增加了 16 個策略小項。 |
| -Os | 與-O3有異曲同工之妙,但兩者的目標不一樣,這個等級是為了盡量的降低目標代碼的大小,這對于存儲容量很小的設備來說非常重要。 -此等級在-O2所有優(yōu)化策略小項之上減掉了 6 個策略小項,然后使能了 -finline-functions 策略。 |
| -Ofast | 不會嚴格遵循語言標準,會針對某些語言啟用部分優(yōu)化,以達到最快的運行速度。 -此等級在-O3所有優(yōu)化策略小項之上增加了 -ffast-math 和 -fallow-store-data-races 策略。 |
| -Og | 在保持快速編譯和良好調試體驗的同時,提供合理的優(yōu)化級別。 |
| -Oz | 比-Os更激進的去降低目標代碼的大小,GCC v12.x 之后的版本才引入。 |
三、MCUX下設置優(yōu)化等級的三種方法
在 MCUXpresso IDE 工程里,我們有三種方法來設置優(yōu)化等級,分別針對單個函數、單個源文件、整個工程源文件。
3.1 在源文件中設置
第一種優(yōu)化等級設置方法主要針對單個函數,即使用 __attribute__ 來修飾函數(這其實是 GCC 下通用做法,與 MCUX 關系不大),經過修飾的函數可以不受 MCUXpresso IDE 工程整體優(yōu)化等級設置影響。
void __attribute__((optimize("O3"))) function(void)
{
...
}
第二種優(yōu)化等級設置方法主要針對多個相鄰函數或者整個源文件,即使用如下 #pragma 組合語句來修飾代碼(這也是 GCC 下通用做法,與 MCUX 關系不大),經過修飾的代碼也同樣不受 MCUXpresso IDE 工程整體優(yōu)化等級設置影響。
#pragma GCC push_options // 代碼作用范圍起始處
#pragma GCC optimize("O3") // 代碼優(yōu)化等級設置
void function1(void)
{
...
}
void function2(void)
{
...
}
...
#pragma GCC pop_options // 代碼作用范圍結尾處
3.2 在IDE選項中設置
第三種優(yōu)化等級設置方法主要針對工程全部源文件,即在 MCUXpresso IDE 工程選項里 Optimization Level 一欄項目里做切換選擇,這里基本上與 GCC v10.3 優(yōu)化等級定義是一致的,但是缺少了 -Ofast 選項。
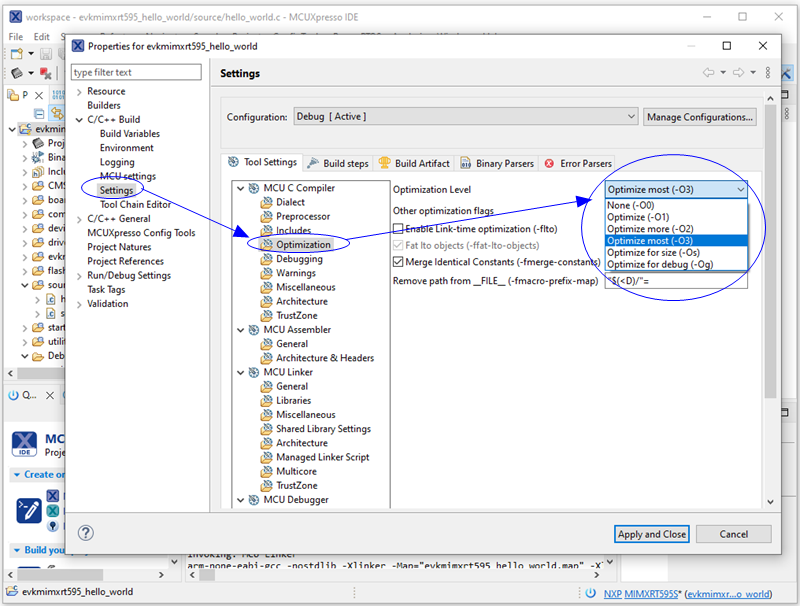
四、MCUX下設置-Ofast等級
痞子衡找了一塊 MIMXRT595-EVK 開發(fā)板(主芯片為 Cortex-M33 內核),在其配套 SDK 里的 hello world 工程基礎之上移植了 coremark 程序,在 IAR v9.10 最高優(yōu)化等級下(High-Speed, No size constraints)得到了 3.94 CoreMark/MHz 的跑分,這很接近 Arm 基準值,但是在 MCUXpresso IDE 最高優(yōu)化等級下(-O3)僅得到了 2.76 CoreMark/MHz。
莫非是必須要在 MCUXpresso IDE 下開啟 GCC 的最快運行優(yōu)化等級 -Ofast 才能得到理想 coremark 跑分,但是 MCUXpresso IDE 選項里并沒有 -Ofast 怎么辦?別著急,剛才工程選項下還有 Other optimization flags 后門,我們在這里手動添加上 -Ofast 比 -O3 多的那兩個優(yōu)化策略小項,以及 MCUX 團隊要求的 -fno-semantic-interposition 小項,這樣基本就等于 - Ofast 效果。
-ffast-math -fallow-store-data-races -fno-semantic-interposition
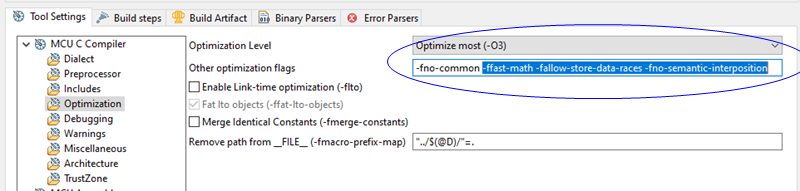
重新編譯,再跑一次 -Ofast 等級下的 MCUXpresso IDE 工程,發(fā)現 coremark 跑分結果并沒有比 -O3 等級下有多大提升,想了想雖然跑不到 IAR 上 3.94 CoreMark/MHz 的高分有點不甘心,但是這也很正常嘛,免費的 GCC 編譯器如果能達到商業(yè) IAR 編譯器那樣的效果,那人家商業(yè)編譯器還怎么收費呢,理解萬歲!
至此,MCUXpresso IDE下設置代碼編譯優(yōu)化等級的幾種方法痞子衡便介紹完畢了,掌聲在哪里~~~
歡迎訂閱
文章會同時發(fā)布到我的 博客園主頁、CSDN主頁、知乎主頁、微信公眾號 平臺上。
微信搜索"痞子衡嵌入式"或者掃描下面二維碼,就可以在手機上第一時間看了哦。

最后歡迎關注痞子衡個人微信公眾號【痞子衡嵌入式】,一個專注嵌入式技術的公眾號,跟著痞子衡一起玩轉嵌入式。



衡杰(痞子衡),目前就職于恩智浦(NXP)半導體MCU系統(tǒng)應用部門,擔任高級嵌入式系統(tǒng)應用工程師。
專欄內所有文章的轉載請注明出處:http://www.rzrgm.cn/henjay724/
與痞子衡進一步交流或咨詢業(yè)務合作請發(fā)郵件至 hengjie1989@foxmail.com
可以關注痞子衡的Github主頁 https://github.com/JayHeng,有很多好玩的嵌入式項目。
關于專欄文章有任何疑問請直接在博客下面留言,痞子衡會及時回復免費(劃重點)答疑。
痞子衡郵箱已被私信擠爆,技術問題不推薦私信,堅持私信請先掃碼付款(5元起步)再發(fā)。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號