
GEO數據庫轉錄組芯片數據處理與R分析:以GSE65682為例
找到感興趣的GEO數據集后,如何從GEO網站上根據數據集編號下載呢?并且下載后怎么在R中對數據集進一步處理成后續分析所要的形式呢?以數據集(GSE65682)為例,為大家詳細演示下如何使用R script 窗口的腳本進行下載和分析。
1.數據集獲取
首先進入GEO網站官網(如下圖所示),在檢索位置輸入數據集編號,點擊箭頭指向的位置進一步運行搜索。

搜索之后會彈出如下界面,重點檢查物種類型(Homo sapiens)和數據集的類型,演示的數據集是芯片數據(Expression profiling by array)。

頁面向下滾動,如圖所示,展示了該數據集對應的注釋文件及數據集內包含的樣本。其中,注釋文件GPL13667是我們重點關注的對象。
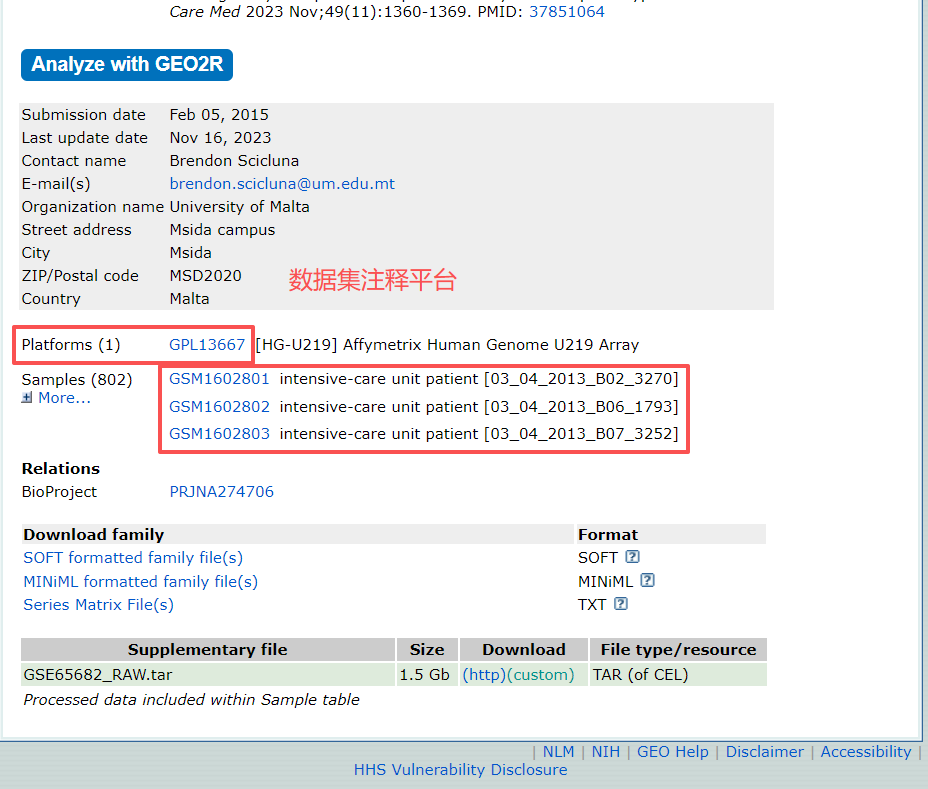
點擊GPL13667可查看注釋文件信息。將頁面滾動至“Data table header descriptions”部分,快速了解注釋文件所包含的信息。如圖所示,該注釋文件中包含了芯片的探針ID及其對應的基因符號(gene symbol),這些信息將在后續分析中被用到。
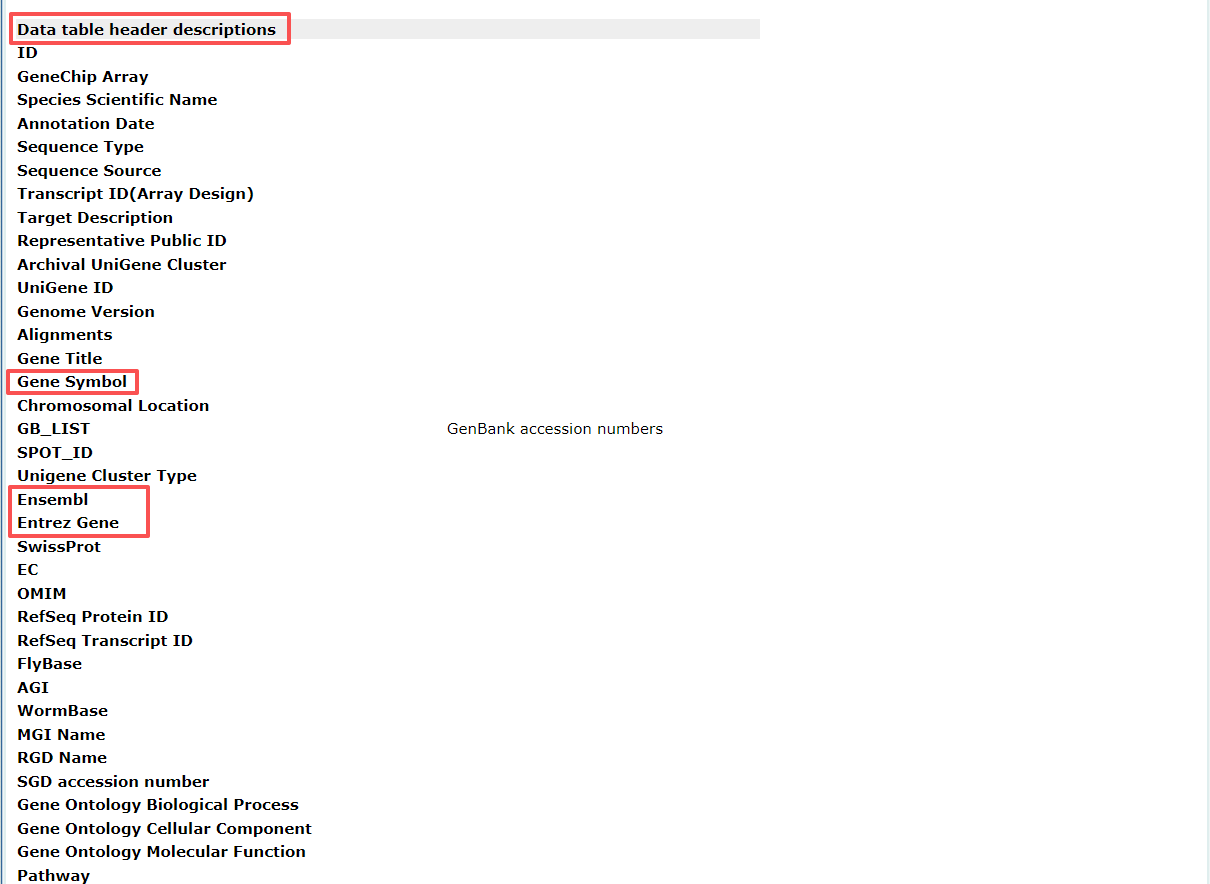
注意:GEO數據集如果只包含探針ID和對應的ENTREZID,則需要先將探針ID 轉換為ENTREZID,再將ENTREZID轉換為gene symbol。
2. 數據下載與處理
獲取以上信息后即可直接進入R用代碼自動下載數據
獲取數據:
下載安裝相關的R包;
library(BiocManager)
install("GEOquery")
加載所需R包;
library(GEOquery)
library(limma)
library(affy)
library(data.table)
library(dplyr)
鏈接GEO,在線下載數據集和注釋文件(探針ID轉symbol)
下載數據集
gset <- getGEO('GSE65682', destdir=".", # 下載到當前目錄
AnnotGPL = TRUE, ## 下載注釋文件
getGPL = TRUE, ## 獲取平臺信息
GSEMatrix = TRUE) ## 以GSEMatrix格式獲取數據
獲取表達矩陣數據
exp <- exprs(gset[[1]])
獲取到的表達矩陣行名為芯片的ID,列名為樣本ID。

獲取樣本的臨床信息和注釋文件
獲取樣本的臨床信息
cli <- pData(gset[[1]]) ## 獲取臨床信息
獲取平臺注釋信息(探針與基因的對應關系)
GPL <- fData(gset[[1]]) ## 獲取平臺信息
提取平臺信息中的探針ID和基因符號列
gpl <- GPL[, c("ID", "Gene Symbol")]
清洗基因符號列:對于多個基因符號用"http:/// "分隔的情況,只取第一個基因符號
gpl$"Gene Symbol" <- data.frame(sapply(gpl$"Gene Symbol", function(x) unlist(strsplit(x, "http:/// "))[1]), stringsAsFactors = F)[, 1]
去除基因符號前后的空格
gpl$"Gene Symbol" <- trimws(gpl$"Gene Symbol")
將表達矩陣轉換為數據框格式
exp <- as.data.frame(exp)
在表達矩陣中添加探針ID列
exp$ID <- rownames(exp)
將表達矩陣與平臺注釋信息按探針ID合并
exp_symbol <- merge(exp, gpl, by = "ID")
移除包含NA值的行
exp_symbol <- na.omit(exp_symbol)
檢查基因符號的重復情況
table(duplicated(exp_symbol$"Gene Symbol"))
對重復的基因符號取平均值(去重)
exp_unique <- avereps(exp_symbol[, -c(1, ncol(exp_symbol))], ID = exp_symbol$"Gene Symbol")
移除基因符號為"---"的行(無效基因符號)
exp_unique <- exp_unique[row.names(exp_unique) != "---", ]
保存結果
write.csv(exp_unique,"GSE65682_exp_unique.csv")
提取臨床信息中的樣本ID、28天死亡事件和生存時間列
group_info <- as.data.frame(cli[, c(1, 52, 55)])
根據28天死亡事件信息創建分組變量,無事件為健康組,1為死亡,其他為存活
group_info <- group_info %>%
mutate(group = ifelse(mortality_event_28days:ch1 == "NA", "Healthy",
ifelse(mortality_event_28days:ch1 == "1", "Dead","Alive")))
重命名列使其更易讀
group_info <- group_info %>% rename("sample" = "...1",
"status" = "mortality_event_28days:ch1",
"time" = "time_to_event_28days:ch1")
保存結果
write.csv(group_info,"GSE65682_group_info.csv",row.names = FALSE)
讀取之前保存的表達矩陣數據
expr_data <- read.csv("GSE65682_exp_unique.csv")
讀取分組信息
group_info <- read.csv("GSE65682_group_info.csv")
獲取所有唯一的樣本ID
sample_ids <- unique(group_info$sample)
將表達矩陣的行名設置為第一列(基因名)
rownames(expr_data) <- expr_data$X
提取表達矩陣中與分組信息匹配的樣本列
expr_data_subset <- expr_data[, colnames(expr_data) %in% sample_ids]
從分組信息中篩選出非健康樣本(敗血癥樣本)
group_sepsis <- group_info %>%
filter(group != "Healthy")
獲取疾病組樣本的ID
sample_id <- unique(group_sepsis$sample)
提取疾病組樣本的表達數據
exp_sepsis <- expr_data_subset[, colnames(expr_data_subset) %in% sample_id]
創建只包含樣本和分組信息的簡化數據框
group <- group_info[c("sample", "group")]
轉置表達矩陣(樣本為行,基因為列)
sample_exp <- t(expr_data_subset)
轉換為數據框格式
sample_exp <- as.data.frame(sample_exp)
將行名(樣本ID)轉換為數據框的一列
sample_exp <- tibble::rownames_to_column(sample_exp, var = "sample")
將分組信息與表達數據按樣本ID進行匹配
joined_df <- group %>% right_join(sample_exp, by = "sample")
保存結果
write.csv(joined_df,"GSE65682_exp_group.csv",row.names = F)
在得到處理后的表達矩陣以及臨床信息后,就可以進行后續的很多個性化分析了,比如差異分析、生存分析,以及風險模型的構建等下游分析,因此這最初的第一步也是最重要的一步。
感謝大家的觀看!以上內容涵蓋了從GEO數據庫下載轉錄組芯片數據到進行數據處理的完整流程。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號