

volatile關鍵字是干啥用的呢?
關鍵字:
可見性:當一個修改一個共享變量時,另一個線程可以讀取到修改的值
內存屏障:是一組處理器指令,用于實現對內存操作順序的限制
緩存行:緩存中可以分配的最小存儲空間,處理器填寫緩存線時會加載整個緩存線,需要使用多個主內存讀周期
原子操作:不可中斷的一個或一系列操作
緩存行填充:當處理器識別到從內存中讀取操作數是可緩存的,處理器讀取整個緩存行到適當的緩存(L1,L2,L3的或所有)
緩存命中:如果進行高速緩存操作的內存位置任然是下次處理器訪問的地址時,處理器從緩存中讀取操作數,而不是內存中
寫命中:當處理器將操作數寫回到一個內存的區域時,他會首先檢查這個緩存的內存地址是否在緩存行中,如果存在一個有效的緩存行,則處理器將這個操作數寫回到緩存,而不是寫回到內存中
寫缺失:一個有效的緩存行被寫入到不存在的內存區域
volatile簡介:保證共享變量可見性,屬于輕量級的synchronized,,但是比synchronized的使用和執行成本低,不會引起上下文切換與調度
再給volatile修飾的值賦值時候,會用到lock前綴指令,lock前綴指令的作用:
1、將當前緩存行的數據寫回到內存中
2、這個寫回內存的操作會使在其他cpu里緩存了該內存地址的數據無效
為了提高運行速率,處理器不會直接讀取內存中的數據,而是將內存中的數據緩存在內部緩存中,內部緩存是以緩存行為單位進行工作的,在沒有volatile關鍵字修飾的情況下,處理器只會與內部緩存交互,當我們程序修改內部緩存中值的情況下,不知道什么時候才能寫回到內存中(synchronized關鍵字除外),即便寫到了內存中,其他線程也不一定能夠及時讀取到修改后的最新值。
volatile修飾過的變量在進行寫操作時,會向處理器發送一個lock前綴指令,將這個變量所在緩存行的變量寫回到內存中,但是即便寫回到內存中,其他線程依舊讀取的是舊值,程序運行依舊有問題,因此就在多核心處理器下,為了保證每個處理器緩存區數據一致,就有了MESI緩存一致性協議,每個處理器通過總線嗅探機制自己緩存的數據是否過期,當處理器發現自己緩存行數據所對應的地址被修改時,就會將當前緩存行設置為無效狀態,,當處理器對該緩存行數據進行修改時,會重新從內存中讀取該數據到處理器中
MESI緩存一致性協議的兩條實現原則:
一、Lock前綴指令會引起處理器緩存回寫到內存中:
lock前綴指令導致在執行指令期間聲言處理器的lock信號,在多處理器中,lock信號確保在聲言該信號期間,處理器可以獨享任何共享內存(這樣做消耗過大,在最近的處理器里一般不會鎖總線,因為鎖住總線會導致總線不能被CPU訪問,也就意味著不能訪問系統內存,而是鎖緩存)
1.M 修改 (Modified) 這行數據有效情況下,緩存行數據被修改了,與主內存中的數據不一致情況下,數據只存在于本處理器緩存中,該數據為M狀態。
2.E 獨享 (Exclusive) 這行數據有效,數據和主內存中的數據一致,數據只存在于本處理器緩存中(可以理解為單核處理器情況下,數據緩存與內存中數據一致)。
3.S 共享 (Shared) 這行數據有效,數據和主內存中的數據一致,數據存在于很多處理器緩存中
4. I 無效 (Invalid) 這行數據無效,當總線嗅探機制發現處理器緩存中數據與主內存數據不一直情況下,會將緩存中數據置為無效
二、volatile 的優化
LinkedTransferQueue:在使用volatile修飾時,會使用增加字節的方式來優化出隊與入隊的性能(使用許多4個字節的引用增加到64個字節)
為什么追加到64個字節能夠提高并發編程效率呢?
多數處理器的L1,L2,L3緩存的高速緩存行都是64個字節寬,不支持部分填充,如果隊列的頭節點與尾節點都不足64個字節的話處理器會將他們讀取到同一個緩存行,在多處理器下,每個處理器都會緩存同樣的頭節點和尾節點,當一個處理器試圖修改頭節點時,會將整個緩存行鎖定,那么在緩存一致性機制的作用下,那么,會導致其他處理器不能訪問自己高速緩存的尾節點,從而嚴重影響了隊列的執行效率,從而在該隊列中將其追加到64個字節后,使其不在同一個緩存行中,防止其頭節點與尾節點相互鎖定。當然也有部分處理器緩存行為32個字節,只需補齊到32個字節,也能達到同樣的效果;如果共享變量如果不會被經常刷新的話也沒必要補充字節(畢竟這是一種以空間換時間的做法)
注意:在jdk7下單純的增加無用字段是無法達到這樣效果的,jdk會淘汰貨重新排列無用字段,需要使用其他方式來擴充(如將無用字段寫在父類中繼承)
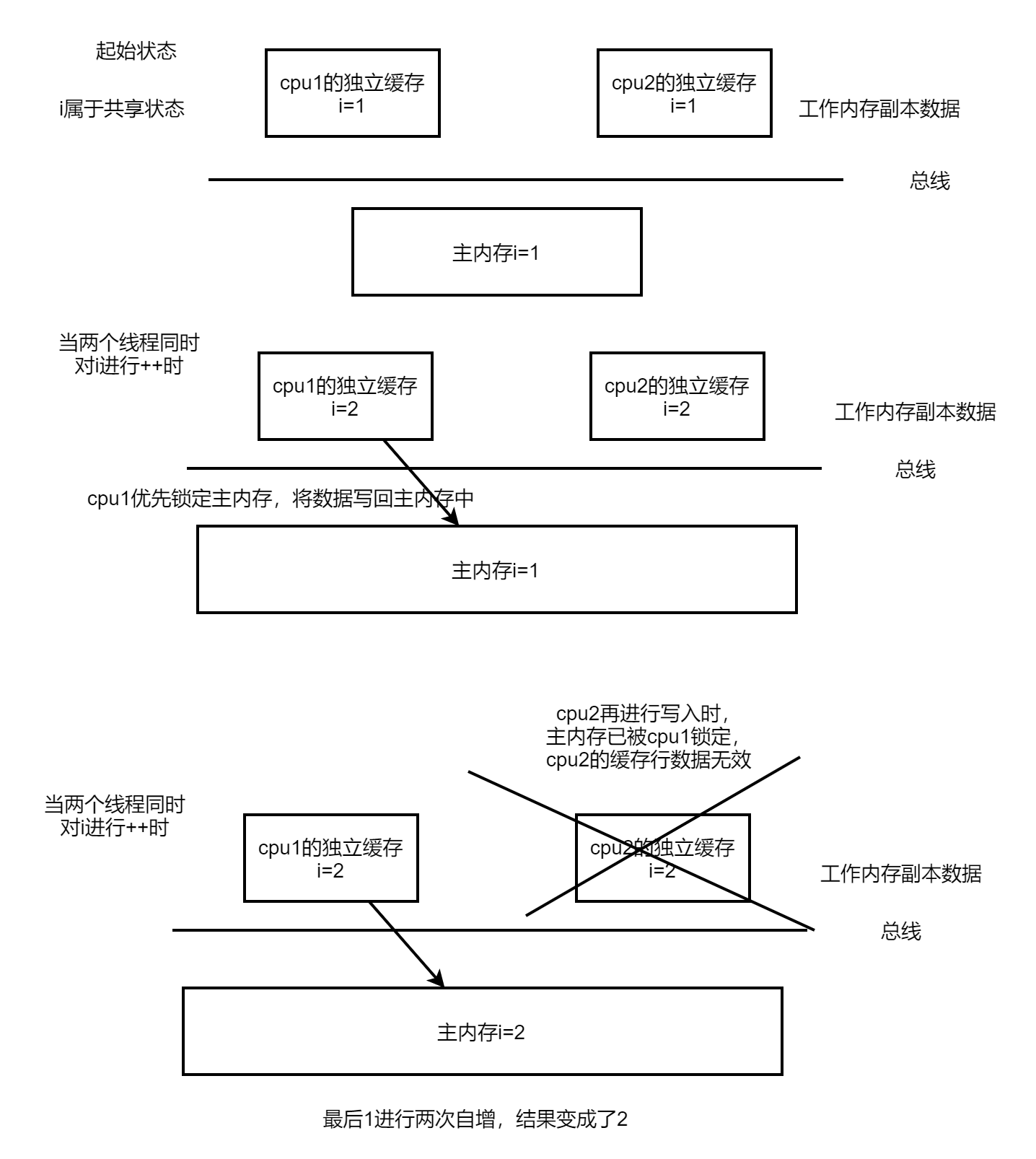
三、volatile關鍵字不能保證原子性?
| CPU1 | CPU2 |
| i=1 | i=1 |
| i+1 | i+1 |
| i=2 | i=2 |

 浙公網安備 33010602011771號
浙公網安備 33010602011771號