
基于DeploySharp 的深度學習模型部署測試平臺:支持YOLO全系列模型
1. 程序獲取和下載
? 基于DeploySharp 開發的深度學習模型部署測試平臺,提供了YOLO框架的主流系列模型,包括YOLOv5~v13,以及其系列下的Detection、Segmentation、Oriented Bounding Box、Human Pose Estimation等應用場景。模型部署引擎支持OpenVINO?、ONNX runtime,支持CPU、IGPU以及GPU多種設備推理。項目鏈接為:
https://github.com/guojin-yan/DeploySharp/tree/DeploySharpV1.0/applications
? 如果你想快速使用該平臺,可以加入QQ技術交流群通過群文件下載,或者通過GitHub在DeploySharp 項目中下載。
git clone https://github.com/guojin-yan/DeploySharp.git
cd DeploySharp/applications
? 打開指定目錄后,直接打開DeploySharp-Applications.sln解決方案即可。
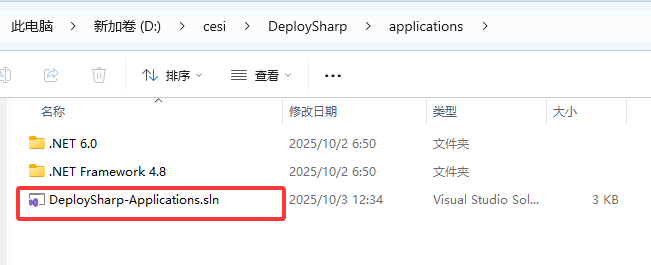
? 打開解決方案后,資源管理器中有兩個項目,一個是.NET 6.0框架,一個是.NET Framework 4.8框架,用戶可以根據自己需求進行運行。
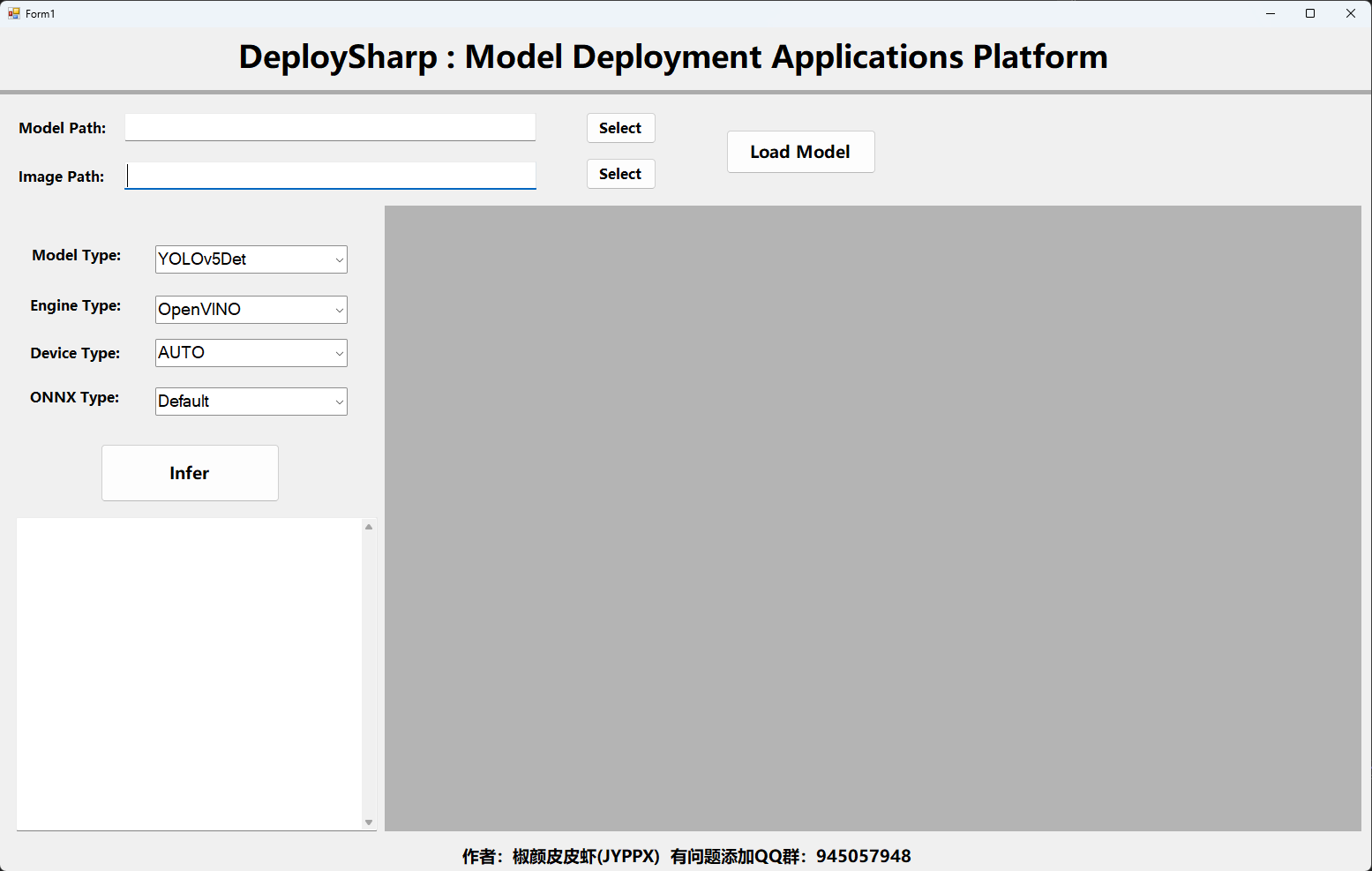
? 程序運行后頁面如下圖所示:
2. 平臺介紹
2.1 支持的模型選項
基于DeploySharp 開發的深度學習模型部署測試平臺所支持的模型列表與DeploySharp 庫一致,后續會跟著DeploySharp 迭代進行同步更新,具體支持的模型:
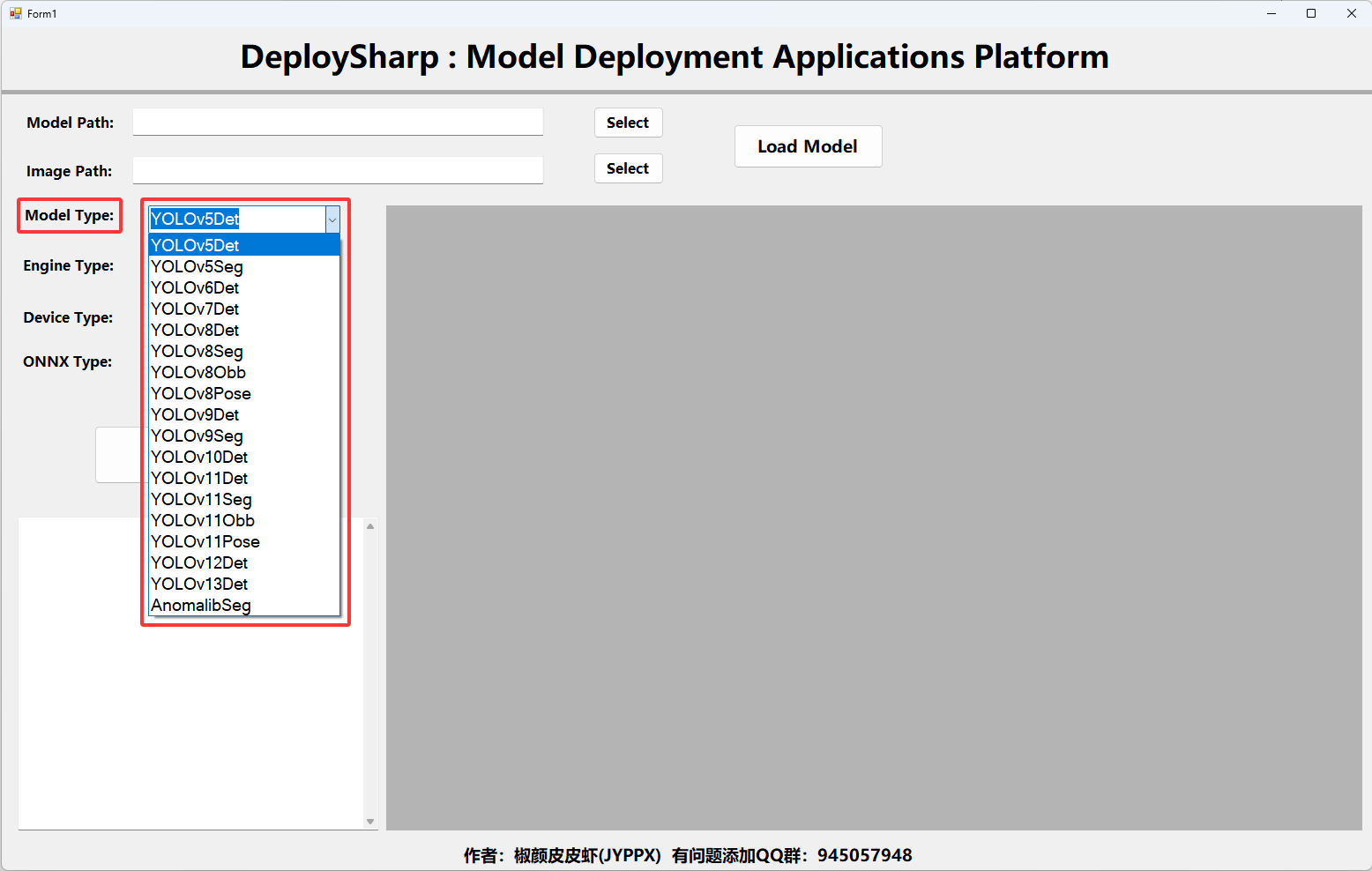
開發者在使用時,可以根據自己需求進行選擇,但在使用時,模型路徑“
Model Path”選擇的模型類型,要和“Model Type保持一致,否者程序運行可能出差或者結果出現錯誤。
2.2 支持的推理引擎工具
基于DeploySharp 開發的深度學習模型部署測試平臺所支持多種推理引擎,其中已經開發完成并已經支持的有OpenVINO和ONNX Runtime,其中TensorRT正在開發中,不日后會完成支持。
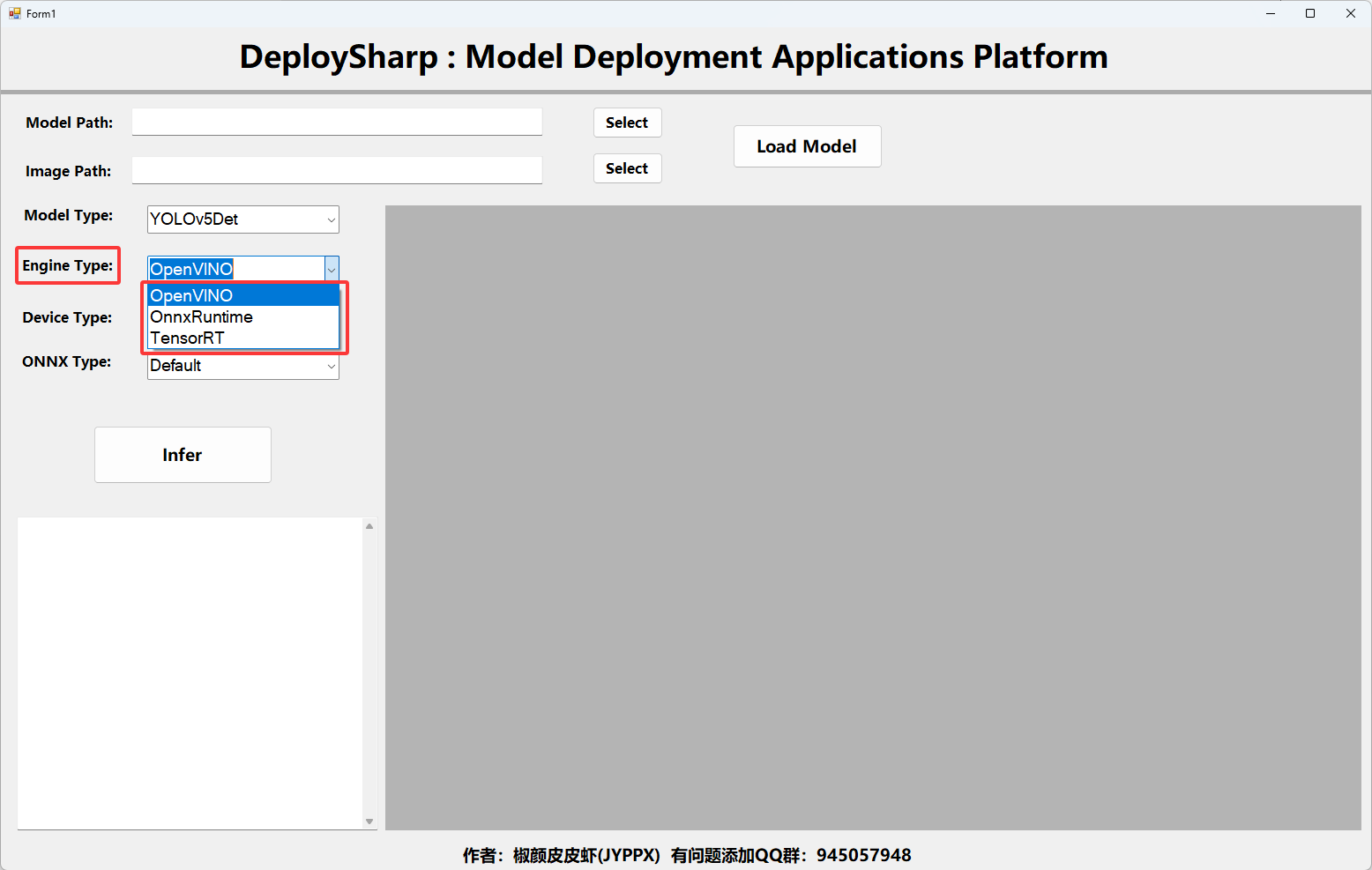
其中當推理設備選擇ONNX Runtime時,還可以選擇ONNX Runtime運行的推理引擎,支持的內容如下圖所示:
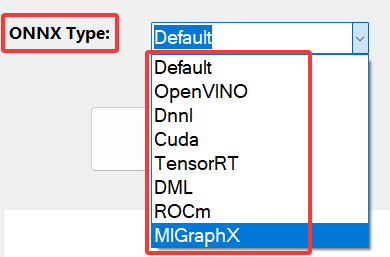
? ONNX Runtime支持的更多加速方式,需要用戶自己進行代碼構建,其構建流程與方式,參考官方教程即可,鏈接為:
https://runtime.onnx.org.cn/docs/execution-providers/
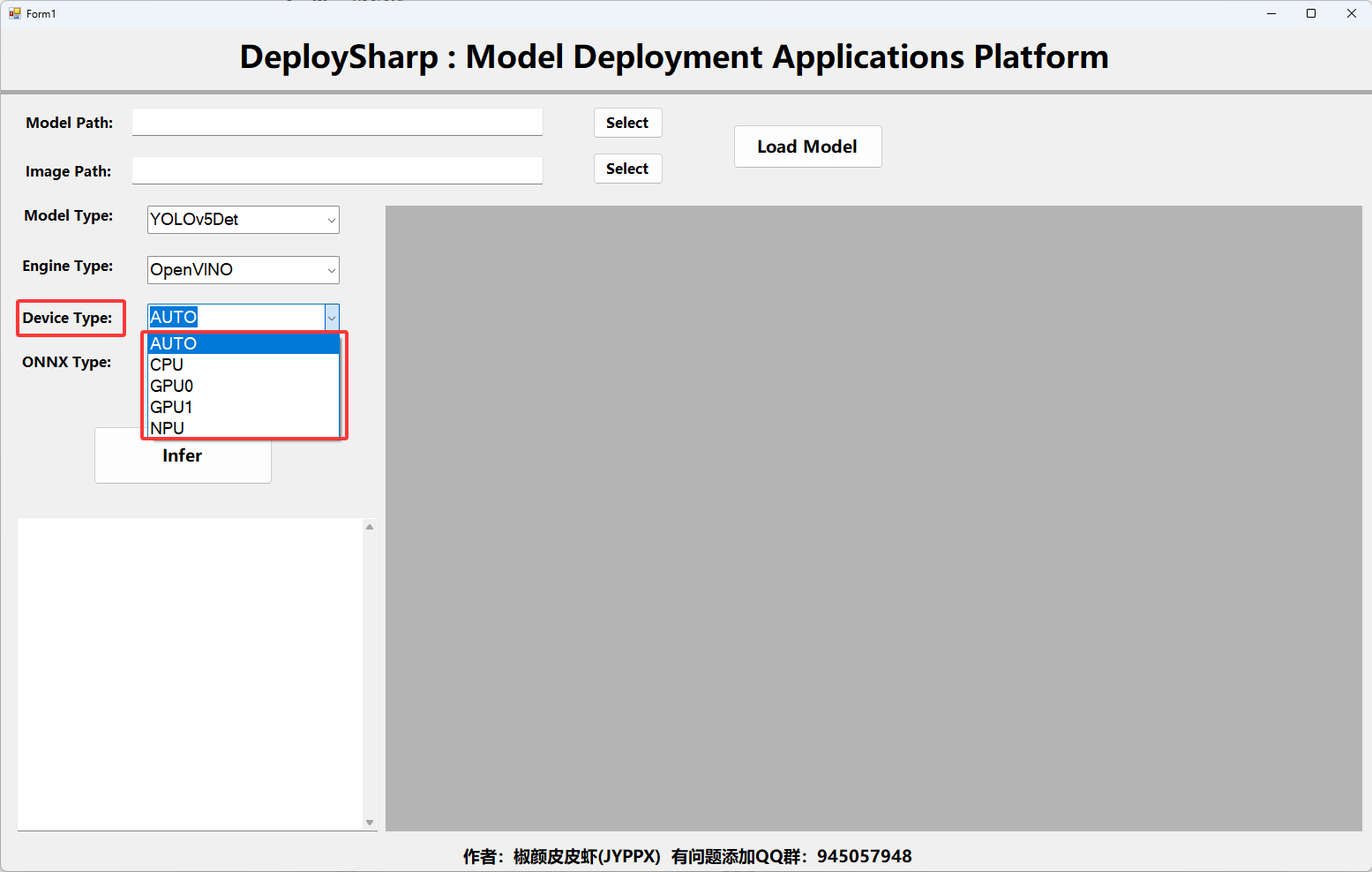
2.3 支持的推理設備
同時用戶還可以選擇不同的推理設備,包括AUTO、CPU、GPU0、GPU1、NPU,其中GPU0、GPU1表示的含義要在使用的推理引擎工具中確定。
3. 推理引擎和設備匹配使用
| 推理引擎 | 推理設備 | ONNX加速 |
|---|---|---|
| OpenVINO | AUTO,CPU,GPU0(Intel 集顯),GPU1(Intel 獨顯),NPU | Default |
| ONNX Runtime | CPU | Default |
| ONNX Runtime | AUTO,CPU,GPU0(Intel 集顯),GPU1(Intel 獨顯),NPU | OpenVINO |
| ONNX Runtime | GPU0(英偉達獨顯),GPU1(英偉達獨顯) | Cuda |
| ONNX Runtime | GPU0,GPU1 | DML |
4. 程序運行示例
在對應的項目中,圖像處理庫已經安裝,不同項目就是使用的不同圖像處理庫,下面演示使用不同的模型推理引擎使用流程。
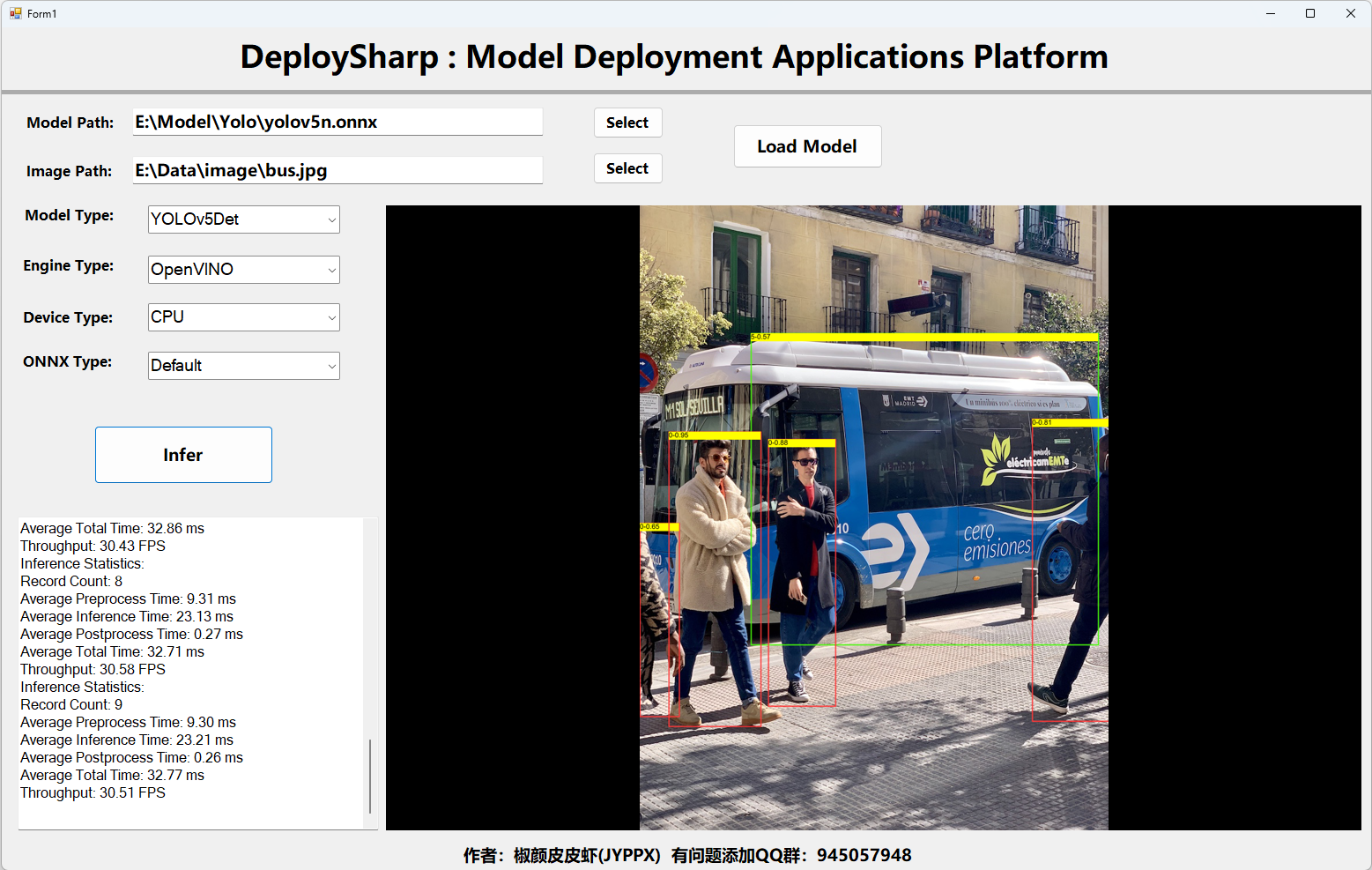
4.1 OpenVINO推理
所下載的項目中已經配置好了OpenVINO環境,選擇模型和圖片后,直接運行即可。推理結果如下圖所示:
如果使用的是.NET Framework 4.8框架,在程序運行前,請卸載并重新安裝一下
OpenVINO.runtime.winNuGet Package,重新生成項目后,進入到項目bin/Debug或者bin/Release目錄,找到該目錄下的文件夾dll/win-x64,在該目錄下可以看到openvino_c.dll文件,然后將該目錄下所有文件,復制到bin/Debug或者bin/Release目錄下,重新再生成一下項目。如果使用的.NET 6.0框架,
4.2 ONNX Runtime推理
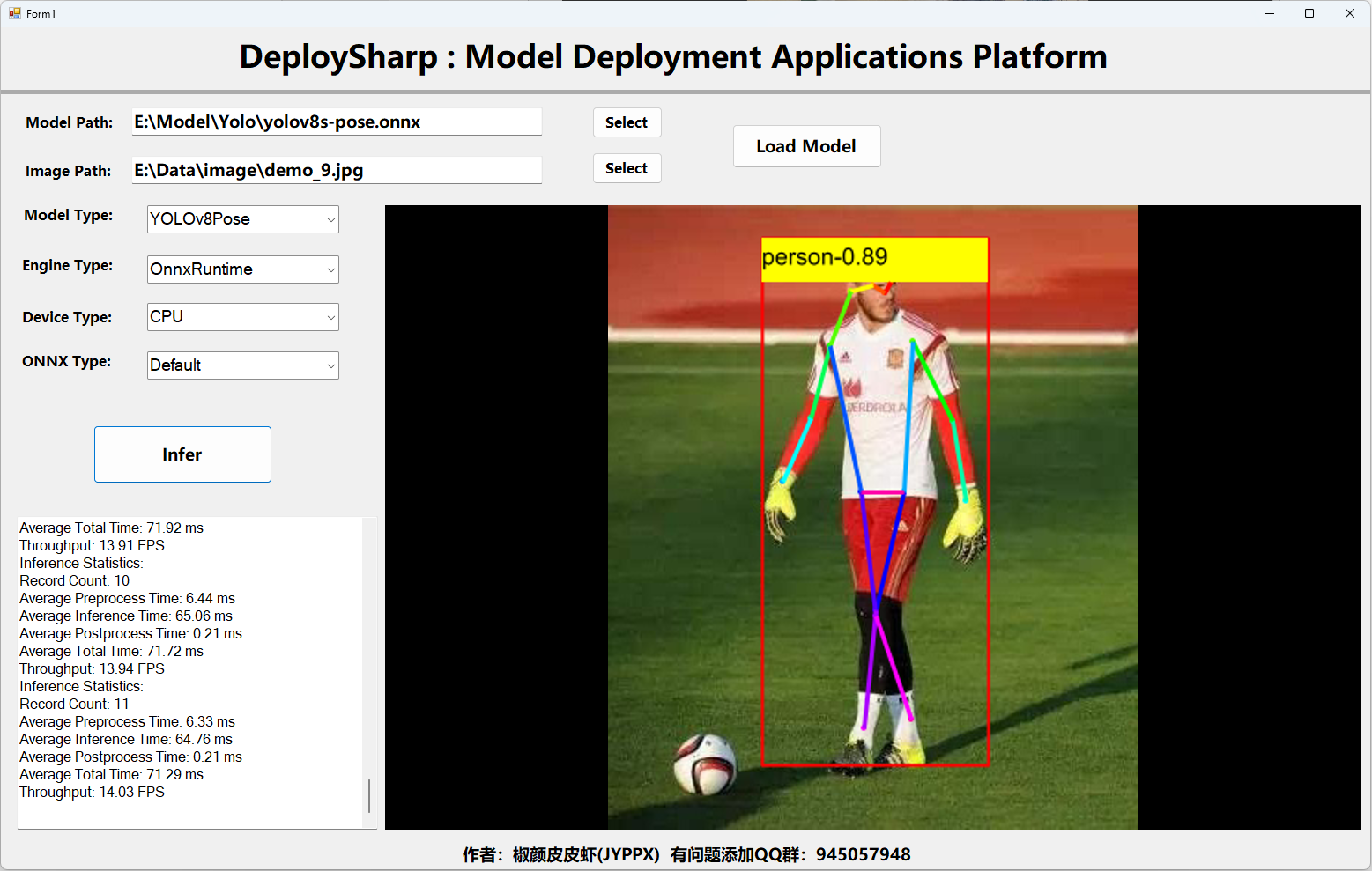
如果只是用ONNX Runtime推理,不需要安裝其他的依賴既可以使用,默認只能使用CPU推理,如下圖所示:
4.3 ONNX Runtime推理 + OpenVINO加速
如果是用ONNX Runtime推理并配合OpenVINO加速,則需要安裝額外的依賴庫:
Intel.ML.OnnxRuntime.OpenVino
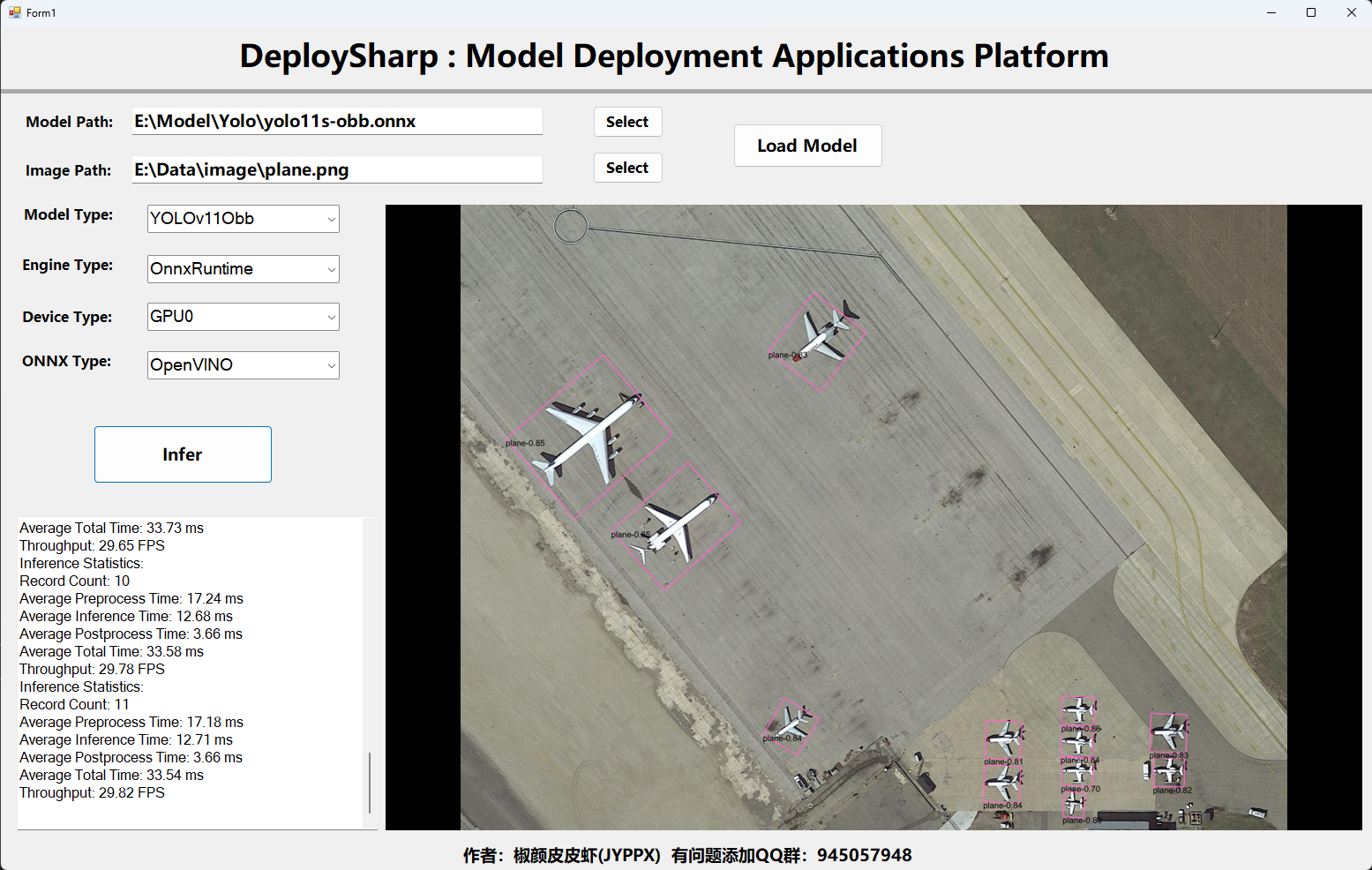
安裝完成后,運行程序即可,其中原生OpenVINO支持的推理設備AUTO、CPU、GPU0(Intel 集顯)、GPU1(Intel 獨顯)、NPU,在此處均可以使用,如下圖所示:
如果使用的是.NET Framework 4.8框架,安裝完
Intel.ML.OnnxRuntime.OpenVino后,如果依舊報錯:”無法在 DLL“onnxruntime”中找到名為“OrtSessionOptionsAppendExecutionProvider_OpenVINO”的入口點。”,可以找到Intel.ML.OnnxRuntime.OpenVino包目錄,然后將該目錄下的所有dll文件,復制到項目的bin/Debug或者bin/Release目錄下即可。
4.4 ONNX Runtime推理 + DML加速
如果是用ONNX Runtime推理并配合DML加速,則需要安裝額外的依賴庫:
Microsoft.ML.OnnxRuntime.DirectML
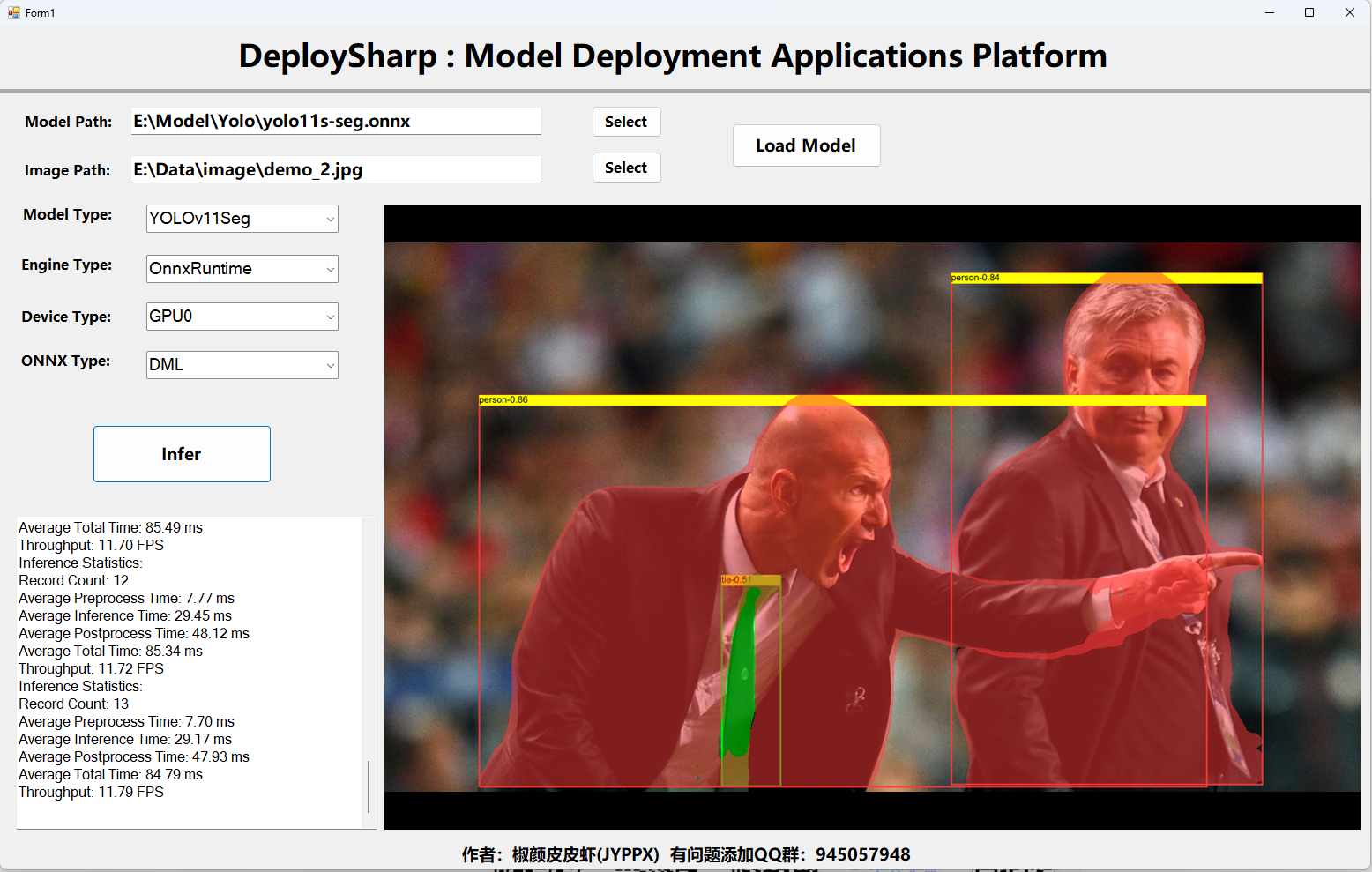
安裝完成后,運行程序即可,此處可以使用GPU、GPU1,如下圖所示:
5.模型運行時間測試
? 在開發的模型部署平臺上進行時間測試,當前的測試環境為:
- CPU: Intel(R) Core(TM) Ultra 9 288V
- IGPU: Intel(R) Arc(TM) 140V GPU (16GB)
- NPU: Intel(R) AI Boost
在同一環境下,對其中一些模型進行了測試,如下表所示:
| Model Name | OpenVINO CPU | OpenVINO IGPU | OpenVINO NPU | ONNX Runtime CPU | ONNX Runtime OpenVINO CPU | ONNX Runtime DirectML IGPU |
|---|---|---|---|---|---|---|
| YOLOv5s-det | 16.84 FPS | 60.23 FPS | 48.36 FPS | 21.06 FPS | 16.80 FPS | 40.11 FPS |
| YOLOv5-seg | 8.91 FPS | 21.24 FPS | 20.11 FPS | 10.86 FPS | 8.56 FPS | 16.54 FPS |
| YOLOv8s-det | 12.02 FPS | 67.74 FPS | 51.84 FPS | 14.84 FPS | 11.52 FPS | 36.38 FPS |
| YOLOv8s-seg | 6.30 FPS | 15.96 FPS | 14.09 FPS | 7.17 FPS | 6.24 FPS | 12.71 FPS |
| YOLOv8s-obb | 4.61 FPS | 35.13 FPS | 20.02 FPS | 5.62 FPS | 4.56 FPS | 15.80 FPS |
| YOLOv11s-det | 13.48 FPS | 62.40 FPS | 53.51 FPS | 15.71 FPS | 13.41 FPS | 38.83 FPS |
| YOLOv11s-seg | 6.64 FPS | 16.18 FPS | 14.46 FPS | 7.55 FPS | 6.59 FPS | 12.74 FPS |
| YOLOv11s-obb | 5.58 FPS | 33.14 FPS | 19.99 FPS | 6.35 FPS | 5.56 FPS | 17.87 FPS |
? 以上便是基于DeploySharp 開發的深度學習模型部署測試平臺的安裝和使用教程。最后如果各位開發者在使用中有任何問題,歡迎大家與我聯系。


 浙公網安備 33010602011771號
浙公網安備 33010602011771號