
MySQL數據庫干貨_30——【精選】JDBC常用操作
JDBC批量添加數據
批量添加數據簡介
在JDBC中通過PreparedStatement的對象的addBatch()和executeBatch()方法進行數據的批量插入。
addBatch()把若干SQL語句裝載到一起,然后一次性傳送到數據庫執行,即是批量處理sql數據的。executeBatch()會將裝載到一起的SQL語句執行。
注意:
MySql默認情況下是不開啟批處理的。
數據庫驅動從5.1.13開始添加了一個對rewriteBatchStatement的參數的處理,該參數能夠讓MySql開啟批處理。在url中添加該參數:rewriteBatchedStatements=true
Mysql的URL參數說明
| useUnicode | [true | false] | 是否使用編碼集,需配合 characterEncoding 參數使用。 |
| characterEncoding | [utf-8 | gbk | …] | 編碼類型。 |
| useSSL | [true | false] | 是否使用SSL協議。 |
| rewriteBatchedStatements | [true | false] | 可以重寫向數據庫提交的SQL語句。 |
實現數據的批量添加
在url中開啟批量添加
rewriteBatchedStatements=true
實現數據的批量添加方式一
/**
* 批量添加數據方式一
*/
public void addBatch1(){
Connection conn = null;
PreparedStatement ps =null;
try{
//創建連接
conn = JdbcUtils.getConnection();
//創建PreparedStatement
ps = conn.prepareStatement("insert into users values(default ,?,?)");
//參數綁定
for(int i=0;i<1000;i++){
//綁定username
ps.setString(1,"java"+i);
//綁定userage
ps.setInt(2,20);
//緩存sql
ps.addBatch();
}
//執行sql
ps.executeBatch();
}catch(Exception e){
e.printStackTrace();
}finally{
JdbcUtils.closeResource(ps,conn);
}
}
實現數據的批量添加方式二
/**
* 批量添加數據方式二
*/
public void addBatch2(){
Connection conn = null;
PreparedStatement ps =null;
try{
//創建連接
conn = JdbcUtils.getConnection();
//創建PreparedStatement
ps = conn.prepareStatement("insert into users values(default ,?,?)");
//參數綁定
for(int i=1;i<=1000;i++){
//綁定username
ps.setString(1,"java"+i);
//綁定userage
ps.setInt(2,20);
//緩存sql
ps.addBatch();
if(i%500 == 0){
//執行sql
ps.executeBatch();
//清除緩存
ps.clearBatch();
}
}
}catch(Exception e){
e.printStackTrace();
}finally{
JdbcUtils.closeResource(ps,conn);
}
}
JDBC事務處理
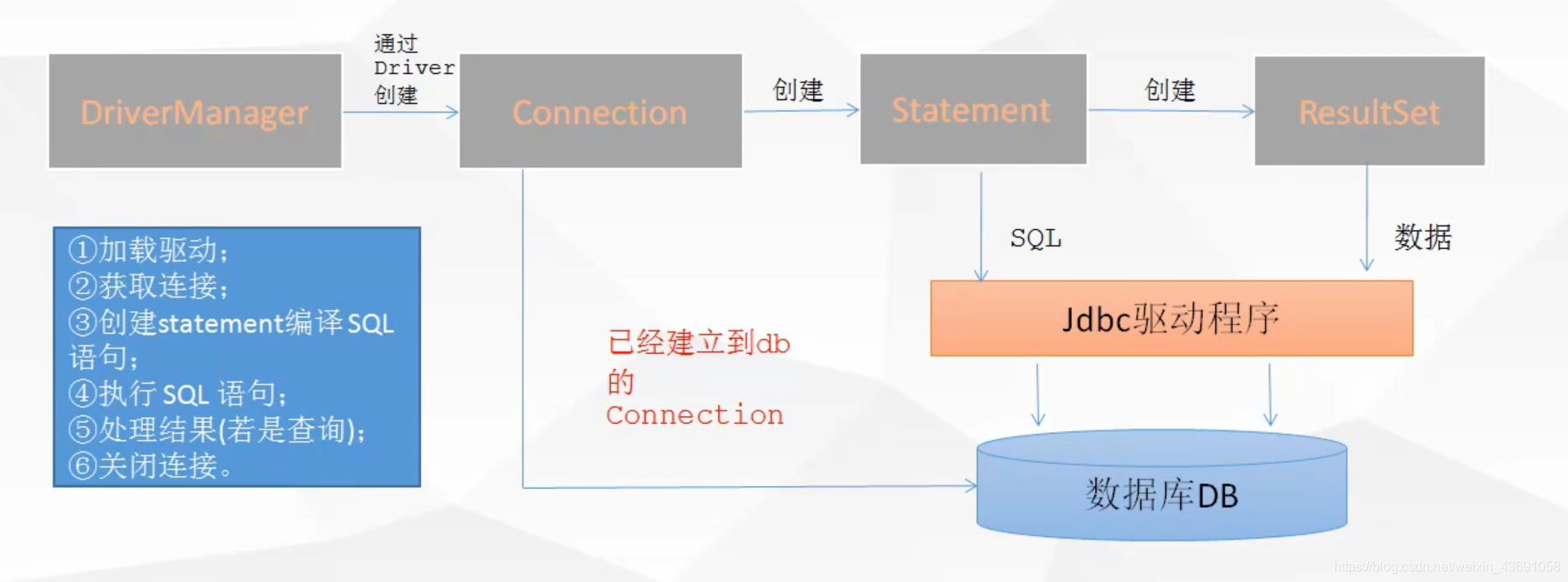
事務簡介
-
事務:
事務是指作為單個邏輯工作單元執行的一系列操作,要么完全地執行,要么完全地不執行。
-
事務操作流程:
- 開啟事務
- 提交事務
- 回滾事務
JDBC中事務處理特點
在JDBC中,使用Connection對象來管理事務,默認為自動提交事務。可以通過setAutoCommit(boolean autoCommit)方法設置事務是否自動提交,參數為boolean類型,默認值為true,表示自動提交事務,如果值為false則表示不自動提交事務,需要通過commit方法手動提交事務或者通過rollback方法回滾事務。
JDBC事務處理實現
/**
* 批量添加數據方式二
* 支持事務處理
*/
public void addBatch2(){
Connection conn = null;
PreparedStatement ps =null;
try{
//創建連接
conn = JdbcUtils.getConnection();
//設置事務的提交方式,將自動提交修改為手動提交
conn.setAutoCommit(false);
//創建PreparedStatement
ps = conn.prepareStatement("insert into users values(default ,?,?)");
//參數綁定
for(int i=1;i<=1000;i++){
//綁定username
ps.setString(1,"java"+i);
//綁定userage
ps.setInt(2,20);
//緩存sql
ps.addBatch();
if(i%500 == 0){
//執行sql
ps.executeBatch();
//清除緩存
ps.clearBatch();
}
if(i==501){
String str = null;
str.length();
}
}
//提交事務
JdbcUtils.commit(conn);
}catch(Exception e){
e.printStackTrace();
JdbcUtils.rollback(conn);
}finally{
JdbcUtils.closeResource(ps,conn);
}
}
Blob類型的使用

MySql Blob類型簡介
Blob(全稱:Binary Large Object 二進制大對象)。在MySql中,Blob是一個二進制的用來存儲圖片,文件等數據的數據類型。==操作Blob類型的數據必須使用PreparedStatement,==因為Blob類型的數據無法使用字符串拼接。大多數情況,并不推薦直接把文件存放在 MySQL 數據庫中,但如果應用場景是文件與數據高度耦合,或者對文件安全性要求較高的,那么將文件與數據存放在一起,即安全,又方便備份和遷移。
Mysql中的Blob類型
MySql中有四種Blob類型,它們除了在存儲的最大容量上不同,其他是一致的。
| 類型 | 大小 |
|---|---|
| TinyBlob | 最大255字節 |
| Blob | 最大65K |
| MediumBlob | 最大16M |
| LongBlob | 最大4G |
Blob類型使用的注意事項
- 實際使用中根據需要存入的數據大小定義不同的Blob類型。
- 如果存儲的文件過大,數據庫的性能會下降。
插入Blob類型數據
創建表
CREATE TABLE `movie` (
`movieid` int(11) NOT NULL AUTO_INCREMENT,
`moviename` varchar(30) DEFAULT NULL,
`poster` mediumblob,
PRIMARY KEY (`movieid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
通過PreparedStatement存儲Blob類型數據
/**
* Blob類型操作測試類
*/
public class BlobTest {
/**
* 向Movie表中插入數據
*/
public void insertMovie(String moviename, InputStream is){
Connection conn =null;
PreparedStatement ps =null;
try{
//獲取連接
conn = JdbcUtils.getConnection();
//創建PreparedStatement對象
ps = conn.prepareStatement("insert into movie values(default,?,?)");
//綁定參數
ps.setString(1,moviename);
ps.setBlob(2,is);
ps.executeUpdate();
}catch(Exception e){
e.printStackTrace();
}finally{
JdbcUtils.closeResource(ps,conn);
}
}
public static void main(String[] args) throws FileNotFoundException {
BlobTest bt = new BlobTest();
//創建讀取文件的IO流
InputStream is = new FileInputStream(new File("d:/1.jpg"));
bt.insertMovie("java",is);
}
}
解除文件大小限制
雖然MediumBlob允許保存最大值為16M,但MySql中默認支持的容量為4194304即4M。我們可以通過修改Mysql的my.ini文件中max_allowed_packet屬性擴大支持的容量,修改完畢后需要重啟MySql服務。
讀取Blob類型數據
/**
* 根據影片ID查詢影片信息
* @param movieid
*/
public void selectMovieById(int movieid){
Connection conn =null;
PreparedStatement ps = null;
ResultSet rs = null;
try{
//獲取連接
conn =JdbcUtils.getConnection();
//創建PreparedStatement對象
ps = conn.prepareStatement("select * from movie where movieid = ?");
//綁定參數
ps.setInt(1,movieid);
//執行sql
rs = ps.executeQuery();
while(rs.next()){
int id = rs.getInt("movieid");
String name = rs.getString("moviename");
System.out.println(id+" "+name);
//獲取blob類型的數據
Blob blob = rs.getBlob("poster");
//獲取能夠從Blob類型的列中讀取數據的IO流
InputStream is = blob.getBinaryStream();
//創建文件輸出字節流對象
OutputStream os = new FileOutputStream(id+"_"+name+".jpg");
//操作流完成文件的輸出處理
byte[] buff = new byte[1024];
int len;
while((len = is.read(buff)) != -1){
os.write(buff,0,len);
}
os.flush();
is.close();
os.close();
}
}catch(Exception e){
e.printStackTrace();
}finally{
JdbcUtils.closeResource(rs,ps,conn);
}
}
其他查詢方式
模糊查詢
實現模糊查詢
/**
* 模糊查詢測試類
*/
public class FuzzyQueryTest {
/**
* 根據用戶名稱模糊查找用戶信息
*/
public List<Users> fuzzyQuery(String username){
List<Users> list= new ArrayList<>();
Connection conn =null;
PreparedStatement ps = null;
ResultSet rs = null;
try{
//獲取數據庫連接
conn = JdbcUtils.getConnection();
//創建PreparedStatement對象
ps = conn.prepareStatement("select * from users where username like ?");
//參數綁定
ps.setString(1,username);
//執行sql語句
rs = ps.executeQuery();
while(rs.next()){
Users user = new Users();
user.setUserid(rs.getInt("userid"));
user.setUsername(rs.getString("username"));
user.setUserage(rs.getInt("userage"));
list.add(user);
}
}catch(Exception e){
e.printStackTrace();
}finally{
JdbcUtils.closeResource(rs,ps,conn);
}
return list;
}
public static void main(String[] args) {
FuzzyQueryTest ft = new FuzzyQueryTest();
List<Users> users = ft.fuzzyQuery("%d%");
for(Users user1:users){
System.out.println(user1.getUserid()+" "+user1.getUsername()+" "+user1.getUserage());
}
}
}
動態條件查詢
動態條件查詢實現
/**
* 動態條件查詢測試類
*/
public class DynamicConditionQueryTest {
/**
* 動態條件查詢Users
*/
public List<Users> queryUsers(Users users){
List<Users> list= new ArrayList<>();
Connection conn =null;
PreparedStatement ps = null;
ResultSet rs = null;
try{
//獲取數據庫連接
conn = JdbcUtils.getConnection();
//拼接查詢SQL語句
String sql = this.generateSql(users);
System.out.println(sql);
//創建PreparedStatement對象
ps = conn.prepareStatement(sql);
//執行sql語句
rs = ps.executeQuery();
while(rs.next()){
Users user = new Users();
user.setUserid(rs.getInt("userid"));
user.setUsername(rs.getString("username"));
user.setUserage(rs.getInt("userage"));
list.add(user);
}
}catch(Exception e){
e.printStackTrace();
}finally{
JdbcUtils.closeResource(rs,ps,conn);
}
return list;
}
/**
* 生成動態條件查詢sql
*/
private String generateSql(Users users){
StringBuffer sb = new StringBuffer("select * from users where 1=1 ");
if(users.getUserid() > 0){
sb.append(" and userid = ").append(users.getUserid());
}
if(users.getUsername() ! =null &&users.getUsername().length() > 0){
sb.append(" and username = '").append(users.getUsername()).append("'");
}
if(users.getUserage() > 0){
sb.append(" and userage = ").append(users.getUserage());
}
return sb.toString();
}
public static void main(String[] args) {
DynamicConditionQueryTest dt = new DynamicConditionQueryTest();
Users users = new Users();
users.setUsername("java");
users.setUserage(20);
List<Users> list = dt.queryUsers(users);
for(Users user1:list){
System.out.println(user1.getUserid()+" "+user1.getUsername()+" "+user1.getUserage());
}
}
}
分頁查詢

分頁查詢簡介
當一個操作數據庫進行查詢的語句返回的結果集內容如果過多,那么內存極有可能溢出,所以在查詢中含有大數據的情況下分頁是必須的。
分頁查詢分類:
- 物理分頁:
- 在數據庫執行查詢時(實現分頁查詢),查詢需要的數據—依賴數據庫的SQL語句
- 在SQL查詢時,從數據庫只檢索分頁需要的數據
- 通常不同的數據庫有著不同的物理分頁語句
- MySql物理分頁采用limit關鍵字
- 邏輯分頁:
- 在sql查詢時,先從數據庫檢索出所有數據的結果集,在程序內,通過邏輯語句獲得分頁需要的數據
如何在MySql中實現物理分頁查詢
使用limit方式。
limit的使用
select * from tableName limit m,n
其中m與n為數字。n代表需要獲取多少行的數據項,而m代表從哪開始(以0為起始)。
例如我們想從users表中先獲取前兩條數據SQL為:
select * from users limit 0,2;
那么如果要繼續看下兩條的數據則為:
select * from users limit 2,2;
以此類推
分頁公式:(當前頁-1)*每頁大小
創建Page模型
Page
/**
* 分頁查詢實體類
*/
public class Page<T> {
//當前頁
private int currentPage;
//每頁顯示的條數
private int pageSize;
//總條數
private int totalCount;
//總頁數
private int totalPage;
//結果集
private List<T> result;
public int getCurrentPage() {
return currentPage;
}
public void setCurrentPage(int currentPage) {
this.currentPage = currentPage;
}
public int getPageSize() {
return pageSize;
}
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
public int getTotalCount() {
return totalCount;
}
public void setTotalCount(int totalCount) {
this.totalCount = totalCount;
}
public int getTotalPage() {
return totalPage;
}
public void setTotalPage(int totalPage) {
this.totalPage = totalPage;
}
public List<T> getResult() {
return result;
}
public void setResult(List<T> result) {
this.result = result;
}
}
實現分頁查詢
分頁實現
/**
* 分頁查詢測試類
*/
public class PageTest {
/**
* 實現Users的分頁查詢
*/
public Page<Users> selectPage(Page page){
Connection connection=null;
PreparedStatement preparedStatement=null;
ResultSet resultSet=null;
List<Users> list =new ArrayList<>();
try{
//與數據庫建立連接
connection=JdbcUtils.getConnection();
//獲取PrepareStatement對象
preparedStatement =connection.prepareStatement("select * from users limit ?,?");
//綁定m參數 m=(當前頁-1)*每頁的總條數
preparedStatement.setInt(1,(page.getCurrentPage()-1)*(page.getPageSize()));
//綁定n參數 n = (每頁總條數)
preparedStatement.setInt(2,page.getPageSize());
//執行查詢
resultSet = preparedStatement.executeQuery();
while (resultSet.next()){
//實現ORM映射
Users users=new Users();
users.setUserid(resultSet.getInt("userid"));
users.setUserName(resultSet.getString("userName"));
users.setUserAge(resultSet.getInt("userAge"));
//將Users對象放入容器
list.add(users);
}
//將結果集賦值給Page對象中的結果集
page.setResult(list);
//獲取總條數
preparedStatement=connection.prepareStatement("select count(*) from users");
resultSet = preparedStatement.executeQuery();
while (resultSet.next()){
//總條數
int totalCount = resultSet.getInt(1);
//賦值總條數
page.setTotalCount(totalCount);
}
//獲取總頁數 總頁數=總條數 / 每頁的條數 (如果有余數,向上取整)
int totalPage = (int)Math.ceil(1.0*page.getTotalCount()/page.getPageSize());
//賦值總頁數
page.setTotalPage(totalPage);
}catch (Exception e){
e.printStackTrace();
}finally {
JdbcUtils.closeResource(preparedStatement,connection,resultSet);
}
return page;
}
public static void main(String[] args) {
Page page=new Page();
PageTest pageTest=new PageTest();
page.setCurrentPage(2);
page.setPageSize(2);
Page<Users> usersPage = pageTest.selectPage(page);
System.out.println("當前頁:"+page.getCurrentPage());
System.out.println("總頁數:"+page.getTotalPage());
System.out.println("總條數:"+page.getTotalCount());
System.out.println("每頁條數:"+page.getPageSize());
for(Users users:usersPage.getResult()){
System.out.println(users);
}
}
}
數據庫連接池
數據庫連接池簡介
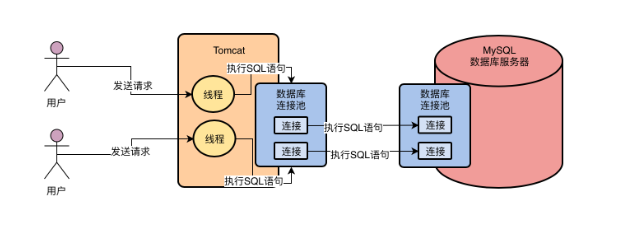
什么是數據庫連接池
數據庫連接池(Connection pooling)是程序啟動時建立足夠的數據庫連接,并將這些連接組成一個連接池,由程序動態地對池中的連接進行申請,使用,釋放。
它允許應用程序重復使用一個現有的數據庫連接,而不是再重新建立一個;釋放空閑時間超過最大空閑時間的數據庫連接來避免因為沒有釋放數據庫連接而引起的數據庫連接遺漏。這項技術能明顯提高對數據庫操作的性能。
不使用數據庫連接池存在的問題
- 普通的JDBC數據庫連接使用 DriverManager 來獲取,每次向數據庫建立連接的時候都要將 Connection加載到內存中,再驗證用戶名和密碼,所以整個過程比較耗時。
- 需要數據庫連接的時候,就向數據庫要求一個,執行完成后再斷開連接。這樣的方式將會消耗大量的資源和時間。數據庫的連接資源并沒有得到很好的重復利用。若同時有幾百人甚至幾千人在線,頻繁的進行數據庫連接操作將占用很多的系統資源,嚴重的甚至會造成服務器的崩潰。
- 對于每一次數據庫連接,使用完后都得斷開。否則,如果程序出現異常而未能關閉,將會導致數據庫系統中的內存泄漏,最終將導致重啟數據庫。
JDBC數據庫連接池的必要性
- **數據庫連接池的基本思想:**為數據庫連接建立一個“緩沖池”。預先在緩沖池中放入一定數量的連接,當需要建立數據庫連接時,只需從“緩沖池”中取出一個,使用完畢之后再放回去。
- 數據庫連接池負責分配、管理和釋放數據庫連接,它允許應用程序重復使用一個現有的數據庫連接,而不是重新建立一個。
- 數據庫連接池在初始化時將創建一定數量的數據庫連接放到連接池中,這些數據庫連接的數量是由最小數據庫連接數來設定的。無論這些數據庫連接是否被使用,連接池都將一直保證至少擁有這么多的連接數量。連接池的最大數據庫連接數量限定了這個連接池能占有的最大連接數,當應用程序向連接池請求的連接數超過最大連接數量時,這些請求將被加入到等待隊列中。
數據庫連接池的優點
- 資源重用:由于數據庫連接得以重用,避免了頻繁創建,釋放連接引起的大量性能開銷。在減少系統消耗的基礎上,另一方面也增加了系統運行環境的平穩性。
- 更快的系統反應速度:數據庫連接池在初始化過程中,往往已經創建了若干數據庫連接置于連接池中備用。此時連接的初始化工作均已完成。對于業務請求處理而言,直接利用現有可用連接避免了數據庫連接初始化和釋放過程的時間開銷,從而減少了系統的響應時間。
- 新的資源分配手段:對于多應用共享同一數據庫的系統而言,可在應用層通過數據庫連接池的配置實現某一應用最大可用數據庫連接數的限制避免某一應用獨占所有的數據庫資源.
- 統一的連接管理:避免數據庫連接泄露在較為完善的數據庫連接池實現中,可根據預先的占用超時設定,強制回收被占用連接,從而避免了常規數據庫連接操作中可能出現的資源泄露。
常用的數據庫連接池
- c3p0:是一個開源組織提供的數據庫連接池,速度相對較慢,穩定性還可以。
- DBCP:是Apache提供的數據庫連接池。速度相對c3p0較快,但自身存在bug。
- Druid:是阿里提供的數據庫連接池,據說是集DBCP、c3p0優點于一身的數據庫連接池,目前經常使用。
Druid連接池

Druid簡介
Druid是阿里提供的數據庫連接池,它結合了C3P0、DBCP等DB池的優點,同時加入了日志監控,可以很好的監控DB池連接和SQL的執行情況。
Druid使用步驟
-
導入druid-1.2.8.jar包到lib目錄下,并引入到項目中
-
在src下創建一個druid.properties類型的文件,并寫入
url = jdbc:mysql://localhost:3306/java?useSSL=false driverClassName = com.mysql.jdbc.Driver username = root password = java initialSize = 10 maxActive = 20druid配置信息:
配置 缺省值 說明 name 配置這個屬性的意義在于,如果存在多個數據源,監控的時候可以通過名字來區分開來。 如果沒有配置,將會生成一個名字,格式是:“DataSource-” + System.identityHashCode(this) url 連接數據庫的url。 username 連接數據庫的用戶名。 password 連接數據庫的密碼。 driverClassName 根據url自動識別 這一項可配可不配,如果不配置druid會根據url自動識別dbType,然后選擇相應的driverClassName(建議配置下) initialSize 0 初始化時建立物理連接的個數。 maxActive 8 最大連接池數量 minIdle 最小連接池數量 maxWait 獲取連接時最大等待時間,單位毫秒。配置了maxWait之后,缺省啟用公平鎖,并發效率會有所下降,如果需要可以通過配置useUnfairLock屬性為true使用非公平鎖。 poolPreparedStatements false 是否緩存preparedStatement,也就是PSCache。PSCache對支持游標的數據庫性能提升巨大,比如說oracle。在mysql下建議關閉。 maxOpenPreparedStatements -1 要啟用PSCache,必須配置大于0,當大于0時,poolPreparedStatements自動觸發修改為true。在Druid中,不會存在Oracle下PSCache占用內存過多的問題,可以把這個數值配置大一些,比如說100 validationQuery 用來檢測連接是否有效的sql,要求是一個查詢語句。如果validationQuery為null,testOnBorrow、testOnReturn、testWhileIdle都不會其作用。 testOnBorrow true 申請連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。 testOnReturn false 歸還連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能 testWhileIdle false 建議配置為true,不影響性能,并且保證安全性。申請連接的時候檢測,如果空閑時間大于timeBetweenEvictionRunsMillis,執行validationQuery檢測連接是否有效。 timeBetweenEvictionRunsMillis 有兩個含義: 1) Destroy線程會檢測連接的間隔時間2) testWhileIdle的判斷依據,詳細看testWhileIdle屬性的說明 numTestsPerEvictionRun 不再使用,一個DruidDataSource只支持一個EvictionRun minEvictableIdleTimeMillis connectionInitSqls 物理連接初始化的時候執行的sql exceptionSorter 根據dbType自動識別 當數據庫拋出一些不可恢復的異常時,拋棄連接 filters 屬性類型是字符串,通過別名的方式配置擴展插件,常用的插件有: 監控統計用的filter:stat日志用的filter:log4j防御sql注入的filter:wall proxyFilters 類型是List<com.alibaba.druid.filter.Filter>,如果同時配置了filters和proxyFilters,是組合關系,并非替換關系 -
加載配置文件
-
獲取連接池對象
-
通過連接池對象獲取連接
通過數據庫連接池獲取連接
/**
* Druid連接池測試類
*/
public class DruidTest {
public static void main(String[] args) throws Exception {
//加載配置文件資源
InputStream is = DruidTest.class.getClassLoader().getResourceAsStream("druid.properties");
//獲取Properties對象
Properties properties=new Properties();
//通過Properties對象的load方法加載資源
properties.load(is);
//連接數據庫連接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
//通過數據庫連接池創建程序與數據庫之間的連接(獲取Connection對象)
Connection connection = dataSource.getConnection();
System.out.println(connection);
}
}
封裝Druid數據庫連接池工具類
/**
* 封裝Druid數據庫連接池工具類
*/
public class JdbcDruidUtiles {
private static DataSource dataSource;
static{
try {
//通過類加載器加載配置文件
InputStream is = JdbcDruidUtiles.class.getClassLoader().getResourceAsStream("druid.properties");
//創建Properties對象
Properties properties=new Properties();
//通過Properties對象的load方法加載配置文件
properties.load(is);
//通過Druid數據庫連接池獲取數據庫連接對象Con
dataSource=DruidDataSourceFactory.createDataSource(properties);
}catch (Exception e){
e.printStackTrace();
}
}
//獲取數據庫連接對象
public static Connection getConnection(){
Connection connection = null;
try {
connection=dataSource.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
return connection;
}
//關閉數據庫連接對象
public static void closeConnection(Connection connection){
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
//提交事務
public static void commit(Connection connection){
try {
connection.commit();
} catch (SQLException e) {
e.printStackTrace();
}
}
//事務回滾
public static void rollBack(Connection connection){
try {
connection.rollback();
} catch (SQLException e) {
e.printStackTrace();
}
}
//關閉Statement對象
public static void closeStatement(Statement statement){
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
//關閉ResultSet對象
public static void closeResultSet(ResultSet resultSet){
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
//DML操作關閉資源
public static void closeResource(Statement statement,Connection connection){
//先關閉Statement對象
closeStatement(statement);
//再關閉Connection對象
closeConnection(connection);
}
//查詢操作關閉資源
public static void closeResource(Statement statement,Connection connection,ResultSet resultSet){
//關閉ResultSet對象
closeResultSet(resultSet);
closeResource(statement,connection);
}
}

 浙公網安備 33010602011771號
浙公網安備 33010602011771號