
【精選】XML技術(shù)知識(shí)點(diǎn)合計(jì)
XML概述

概念
XML(Extensible Markup Language):可擴(kuò)展標(biāo)記語言
可擴(kuò)展:標(biāo)簽都是自定義的。
發(fā)展歷程
HTML和XML都是W3C(萬維網(wǎng)聯(lián)盟)制定的標(biāo)準(zhǔn),最開始HTML的語法過于松散,于是W3C制定了更嚴(yán)格的XML語法標(biāo)準(zhǔn),希望能取代HTML。但是程序員和瀏覽器廠商并不喜歡使用XML,于是現(xiàn)在的XML更多的用于配置文件及傳輸數(shù)據(jù)等功能。
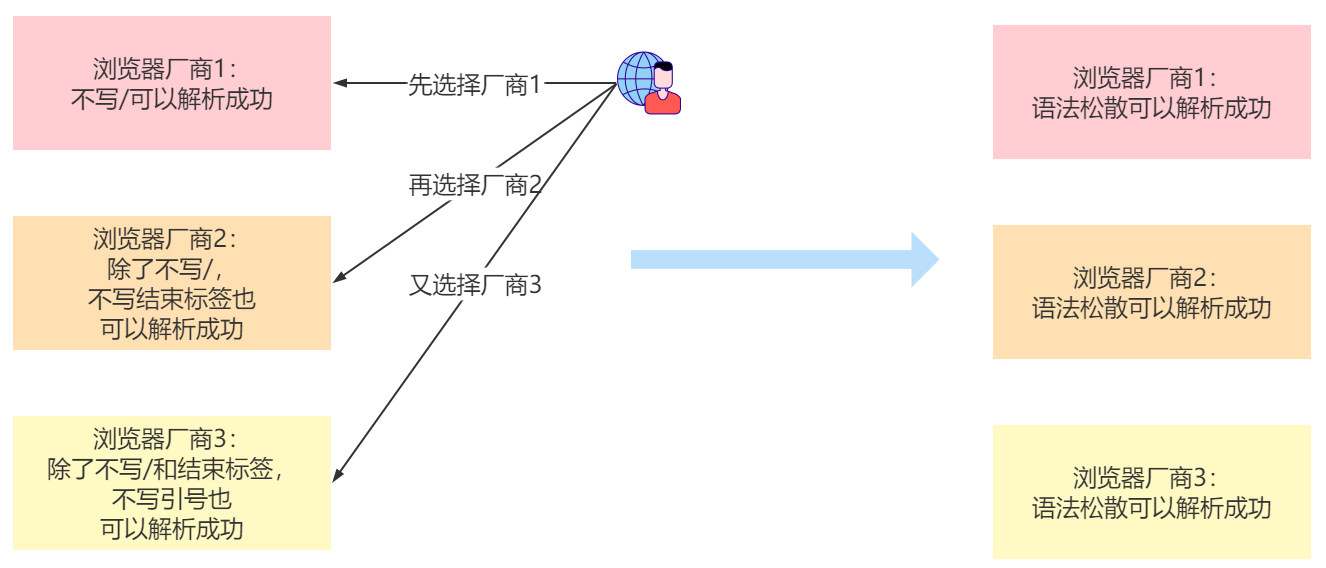
是誰造成的HTML語法松散?
瀏覽器廠商。最開始W3C制定HTML的時(shí)候語法還是比較嚴(yán)格的。但瀏覽器廠商為了搶占市場,語法錯(cuò)誤也可以解析成功HTML,最后“內(nèi)卷”到HTML即使語法非常混亂也是可以被瀏覽器解析。
![image-20220528165807275]()
tips:歸根到底是語法的制定者和使用者不一致造成了HTML語法混亂,JAVA語法嚴(yán)格就是因?yàn)閖ava語言的運(yùn)行工具java虛擬機(jī)也是sun公司(現(xiàn)在是oracle)出品的,語法不通過不讓運(yùn)行。
為什么程序員不使用XML寫前端頁面?
因?yàn)槌绦騿T松散慣了,不想寫很嚴(yán)格的代碼。同樣掙一萬塊錢,誰會(huì)從每月上一天班的公司跳槽到996的公司呢?
XML的功能
-
配置文件:在今后的開發(fā)過程當(dāng)中我們會(huì)頻繁使用框架(框架:半成品軟件),使用框架時(shí),需要寫配置文件配置相關(guān)的參數(shù),讓框架滿足我們的開發(fā)需求。而我們寫的配置文件中就有一種文件類型是XML。
日后編寫大型項(xiàng)目,不可能從頭到尾都是原創(chuàng)代碼,很多功能前人已經(jīng)寫好,我們只需要使用前人寫好的半成品軟件(框架),再加入一些符合我們需求的配置即可完成開發(fā)。
-
傳輸數(shù)據(jù):在網(wǎng)絡(luò)中傳輸數(shù)據(jù)時(shí)并不能傳輸java對(duì)象,所以我們需要將JAVA對(duì)象轉(zhuǎn)成字符串傳輸,其中一種方式就是將對(duì)象轉(zhuǎn)為XML類型的字符串。
比如攜程等旅游網(wǎng)站可以買火車票,但他們其實(shí)也是替12306賣票,此時(shí)他們就需要拿到12306的票務(wù)數(shù)據(jù)。JAVA對(duì)象不能在網(wǎng)絡(luò)上傳輸,可以轉(zhuǎn)為XML類型的字符串。
XML和HTML的區(qū)別
- XML語法嚴(yán)格,HTML語法松散
- XML標(biāo)簽自定義,HTML標(biāo)簽預(yù)定義
XML基本語法
- 文件后綴名是.xml
- 第一行必須是文檔聲明
- 有且僅有一個(gè)根標(biāo)簽
- 標(biāo)簽必須正確關(guān)閉
- 標(biāo)簽名區(qū)分大小寫
- 屬性值必須用引號(hào)(單雙都可)引起來
XML組成部分

文檔聲明
文檔聲明必須放在第一行,格式為:
<?xml 屬性列表 ?>
屬性列表:
- version:版本號(hào)(必須)
- encoding:編碼方式
標(biāo)簽
XML中標(biāo)簽名是自定義的,標(biāo)簽名有以下要求:
- 包含數(shù)字、字母、其他字符
- 不能以數(shù)字和標(biāo)點(diǎn)符號(hào)開頭,可以以_開頭
- 不能包含空格
指令(了解)
指令是結(jié)合css使用的,但現(xiàn)在XML一般不結(jié)合CSS,語法為:
<?xml-stylesheet type="text/css" href="a.css" ?>
屬性
屬性值必須用引號(hào)(單雙都可)引起來
文本
如果想原樣展示文本,需要設(shè)置CDATA區(qū),格式為:
<![CDATA[文本]]>
約束
DTD約束
? 雖然XML標(biāo)簽是自定義的。但是作為配置文件時(shí),也需要遵循一定的規(guī)則。就比如在主板上硬盤口只能插硬盤,不能插入其他硬件。約束就是定義XML書寫規(guī)則的文件,約束我們按照框架的要求編寫配置文件。
我們作為框架的使用者,不需要會(huì)寫約束文件,只要能夠在xml中引入約束文檔,簡單的讀懂約束文檔即可。XML有兩種約束文件類型:DTD和Schema。
DTD是一種較簡單的約束技術(shù),引入方式如下:
-
本地引入:
<!DOCTYPE 根標(biāo)簽名 SYSTEM "dtd文件的位置"> -
網(wǎng)絡(luò)引入:
<!DOCTYPE 根標(biāo)簽名 PUBLIC "dtd文件的位置" "dtd文件路徑">
student.dtd
<!ELEMENT students (student*) >
<!ELEMENT student (name,age,sex)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex (#PCDATA)>
<!ATTLIST student number ID #REQUIRED>
student.xml
<?xml version="1.0" ?>
<!DOCTYPE students SYSTEM "student.dtd">
<students>
<student number="bz001">
<name>javaBoy</name>
<age>10</age>
<sex>男</sex>
</student>
</students>
Schema約束
Schema比DTD對(duì)XML的約束更加詳細(xì),引入方式如下:
-
寫xml文檔的根標(biāo)簽
-
引入xsi前綴:確定Schema文件的版本。
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" -
引入Schema文件
xsi:schemaLocation="Schema文件定義的命名空間 Schema文件的具體路徑" -
為Schema約束的標(biāo)簽聲明前綴
xmlns:前綴="Schema文件定義的命名空間"
Jsoup解析器

XML解析思想
XML解析即讀寫XML文檔中的數(shù)據(jù)。框架的開發(fā)者通過XML解析讀取框架使用者配置的參數(shù)信息,開發(fā)者也可以通過XML解析讀取網(wǎng)絡(luò)傳來的數(shù)據(jù)。XML有如下解析思想:
DOM解析思想
將標(biāo)記語言文檔一次性加載進(jìn)內(nèi)存,在內(nèi)存中形成一顆dom樹
- 優(yōu)點(diǎn):操作方便,可以對(duì)文檔進(jìn)行CRUD的所有操作
- 缺點(diǎn):占內(nèi)存
SAX解析思想
逐行讀取,基于事件驅(qū)動(dòng)的。
- 優(yōu)點(diǎn):不占內(nèi)存,一般用于手機(jī)APP開發(fā)中讀取XML
- 缺點(diǎn):只能讀取,不能增刪改
XML常見解析器
- JAXP:SUN公司提供的解析器,支持DOM和SAX兩種思想
- DOM4J:一款非常優(yōu)秀的解析器
- Jsoup:Jsoup是一款Java的HTML解析器,支持DOM思想。可直接解析某個(gè)URL地址、HTML文本內(nèi)容。它提供了一套非常省力的API,可通過CSS以及類似于jQuery的操作方法來取出和操作數(shù)據(jù)
- PULL:Android操作系統(tǒng)內(nèi)置的解析器,支持SAX思想
Jsoup快速入門

步驟:
- 導(dǎo)入jar包
- 加載XML文檔進(jìn)內(nèi)存,獲取DOM樹對(duì)象Document
- 獲取對(duì)應(yīng)的標(biāo)簽Element對(duì)象
- 獲取數(shù)據(jù)
public class Demo1 {
// 獲取XML中所有學(xué)生的姓名
public static void main(String[] args) throws IOException {
// 2.加載XML文檔進(jìn)內(nèi)存。獲取DOM樹對(duì)象Document
// 2.1 獲取類加載器
ClassLoader classLoader = Demo1.class.getClassLoader();
// 2.2使用類加載器,找到XML文檔的路徑
String path = classLoader.getResource("com/java/xsd/student.xml").getPath();
// 2.3加載XML文檔進(jìn)內(nèi)存,并轉(zhuǎn)成Document對(duì)象
Document document = Jsoup.parse(new File(path), "utf-8");
// 3.獲取對(duì)應(yīng)的標(biāo)簽Element對(duì)象
Elements name = document.getElementsByTag("name");
// 4.獲取數(shù)據(jù)
for (Element element : name) {
String text = element.text();
System.out.println(text);
}
}
}
Jsoup對(duì)象

Jsoup:可以解析xml或html,形成dom樹對(duì)象。
常用方法:
static Document parse(File in, String charsetName):解析本地文件static Document parse(String html):解析html或xml字符串static Document parse(URL url, int timeoutMillis):解析網(wǎng)頁源文件
public class Demo2 {
// Jsoup
public static void main(String[] args) throws IOException {
// 解析本地XML
String path = Demo2.class.getClassLoader().getResource("com/java/xsd/student.xml").getPath();
Document document = Jsoup.parse(new File(path), "utf-8");
System.out.println(document);
System.out.println("------------------");
// 解析網(wǎng)絡(luò)資源
Document document2 = Jsoup.parse(new URL("https://www.baidu.com"), 2000);
System.out.println(document2);
}
}
Document對(duì)象

Document:xml的dom樹對(duì)象
常用方法:
Element getElementById(String id):根據(jù)id獲取元素Elements getElementsByTag(String tagName):根據(jù)標(biāo)簽名獲取元素Elements getElementsByAttribute(String key):根據(jù)屬性獲取元素Elements getElementsByAttributeValue(String key,String value):根據(jù)屬性名=屬性值獲取元素。Elements select(Sting cssQuery):根據(jù)選擇器選取元素。
Element對(duì)象

Element: 元素對(duì)象
常用方法:
String text():獲取元素包含的純文本。String html():獲取元素包含的帶標(biāo)簽的文本。String attr(String attributeKey):獲取元素的屬性值。
XPath解析

XPath即為XML路徑語言,它是一種用來確定標(biāo)記語言文檔中某部分位置的語言。
使用方法:
- 導(dǎo)入
Xpath的jar包 - 獲取
Document對(duì)象 - 將
Document對(duì)象轉(zhuǎn)為JXDocument對(duì)象 JXDocument調(diào)用selN(String xpath),獲取List<JXNode>對(duì)象。- 遍歷
List<JXNode>,調(diào)用JXNode的getElement(),轉(zhuǎn)為Element對(duì)象。 - 處理
Element對(duì)象。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)