網絡抓包文件太大,如何切分
背景
節前最后幾天了,隨便寫點水文吧,今天就記錄一下,當我們拿到的網絡抓包文件太大,應該怎么分析。
一般來說,我們個人抓包的話,linux上用tcpdump比較多,抓的時候也會用捕獲表達式,抓出來的包一般不大,用wireshark分析就很容易。
但是,前一陣的一個晚上,dba突然找我,看能不能幫忙一起分析一個網絡抓包文件,連了會議后一看,大小有4g,這么大的包,wireshark打開都很是困難,分析也很卡。
這么大的包,怎么來的呢,原來是網絡同事直接在路由器上抓的,過濾條件就是某個數據庫服務器的ip:1433端口(sql server數據庫)。既然過濾了,包還這么大?問了下,原來在路由器上抓了整整一個半小時,然后這個庫流量又大,所以最終就有4g。
dba的訴求是,某個數據庫客戶端發了某些sql,導致把數據庫服務器搞死了,現在就是要找出來是哪個客戶端,哪個sql。
最終呢,我只是給dba同事說了下,怎么拆分包,怎么查看包里的sql;后續忙起來后,我也沒問進度,估計已經解決了吧。
這里就簡單記錄下,遇到這種大的包,怎么拆分。
editcap
editcap這個命令是wireshark自帶的,一般就在wireshark目錄下,像我這邊在:C:\Program Files\Wireshark\editcap.exe,我一般會加入到環境變量PATH。
介紹如下:
Editcap is a program that reads some or all of the captured packets from the infile, optionally converts them in various ways and writes the resulting packets to the capture outfile (or outfiles).
即,可以讀取pcap/pcapng類型的文件,通過各種方式進行一些處理、轉換,然后將結果寫入到另外的文件。
說明文檔:

在我們場景中,一般使用如下幾個選項就行了:

按時間
按包的開始時間
-A
Saves only the packets whose timestamp is on or after start time. The time is given in the following format YYYY-MM-DD HH:MM:SS[.nnnnnnnnn] (the decimal and fractional seconds are optional).
比如,對于如下這個包:
editcap file20230325.pcap file20230325-after-pm-3.pcap -A "2023-03-25 15:00:00"
其中,file20230325-after-pm-3.pcap就是要保存的文件名,-A就是選擇15點以后的報文。
可以看下圖示例效果:

獲取包的時間范圍
但你可能有個疑問,如果不知道包的時間范圍呢?
可以先用如下命令獲取:
capinfos file20230325.pcap

按包的結束時間
-B
Saves only the packets whose timestamp is before stop time. The time is given in the following format YYYY-MM-DD HH:MM:SS[.nnnnnnnnn] (the decimal and fractional seconds are optional).
editcap file20230325.pcap file20230325-start3-end310.pcap -A "2023-03-25 15:00:00" -B "2023-03-25 15:10:00"

按包的數量
-c <packets per file>
Splits the packet output to different files based on uniform packet counts with a maximum of <packets per file> each. Each output file will be created with a suffix -nnnnn, starting with 00000. If the specified number of packets is written to the output file, the next output file is opened. The default is to use a single output file.
這個是把大文件拆分,按照包的數量,屆時,每個子文件里的包的數量是一致的。
editcap file20230325.pcap -c 100000 file20230325-by-packets-number.pcap
效果:

但可以看到,每個里面都有1w個包


按時間間隔
-i
Splits the packet output to different files based on uniform time intervals using a maximum interval of
each. Floating point values (e.g. 0.5) are allowed. Each output file will be created with a suffix -nnnnn, starting with 00000. If packets for the specified time interval are written to the output file, the next output file is opened. The default is to use a single output file.
單位是秒。
我們示例文件總共是1000多秒。

editcap file20230325.pcap -i 100 file20230325-by-seconds.pcap

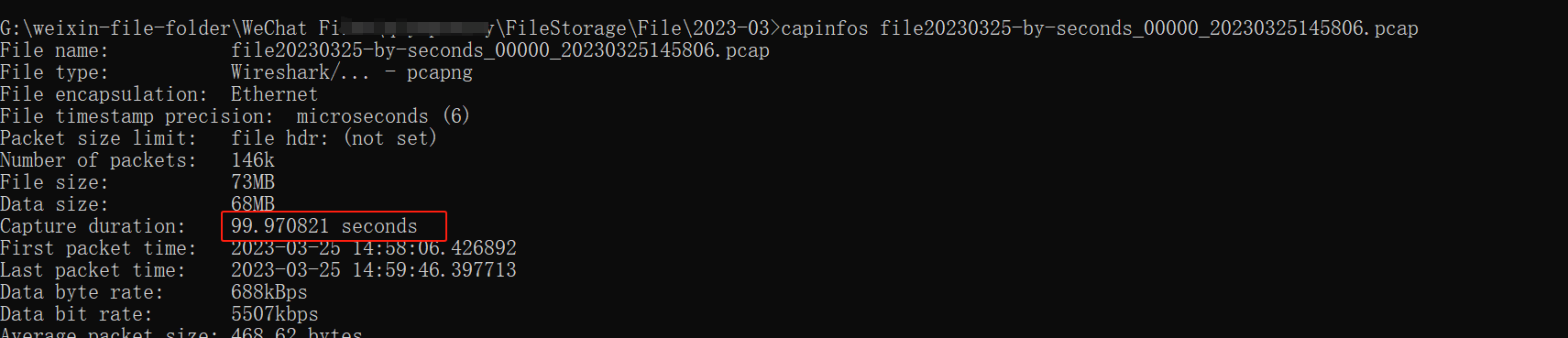

組合時間范圍、包的數量兩個選項
editcap file20230325.pcap file20230325-start3-end310-packets-number.pcap -A "2023-03-25 15:00:00" -B "2023-03-25 15:10:00" -c 10000

這個就是,本來按照時間范圍,只會生成一個包。加了-C后,就繼續按包的數量拆分了。
組合時間范圍、時間間隔兩個選項
editcap file20230325.pcap file20230325-start3-end310-seconds.pcap -A "2023-03-25 15:00:00" -B "2023-03-25 15:10:00" -i 100

按序號

命令中可以指定序號,但是默認是刪掉這些序號的包。
-r
Reverse the packet selection. Causes the packets whose packet numbers are specified on the command line to be written to the output capture file, instead of discarding them.
加了-r后,意味著反選。即保留這些序號的包。
官方示例:
To limit a capture file to packets from number 200 to 750 (inclusive) use:
editcap -r capture.pcapng small.pcapng 200-750

我這邊也試了下:
editcap -r file20230325.pcap file20230325-frame-number.pcap 1-100

總結
也沒啥好總結的。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號