使用 shell 腳本拼接 srt 字幕文件 (srtcat)
背景
前段時間迷上了做 B 站視頻,主要是摩托車方面的知識分享。做的也比較粗糙,就是幾張圖片配上語音和字幕進行解說。嘗試過自己解說,發現錄制視頻對節奏的要求還是比較高的,這里面水太深把握不住。好在以 "在線 免費 文字轉語音" 作為關鍵字搜索一番,發現一個好用的網站——字幕說。好用的語音合成工具千千萬,為什么我對這個情有獨鐘呢?原來它將文字底稿轉換為語音的同時,還輸出了字幕文件 (srt),這個在 B 站的云編輯器中就可以直接導入了,非常方便:
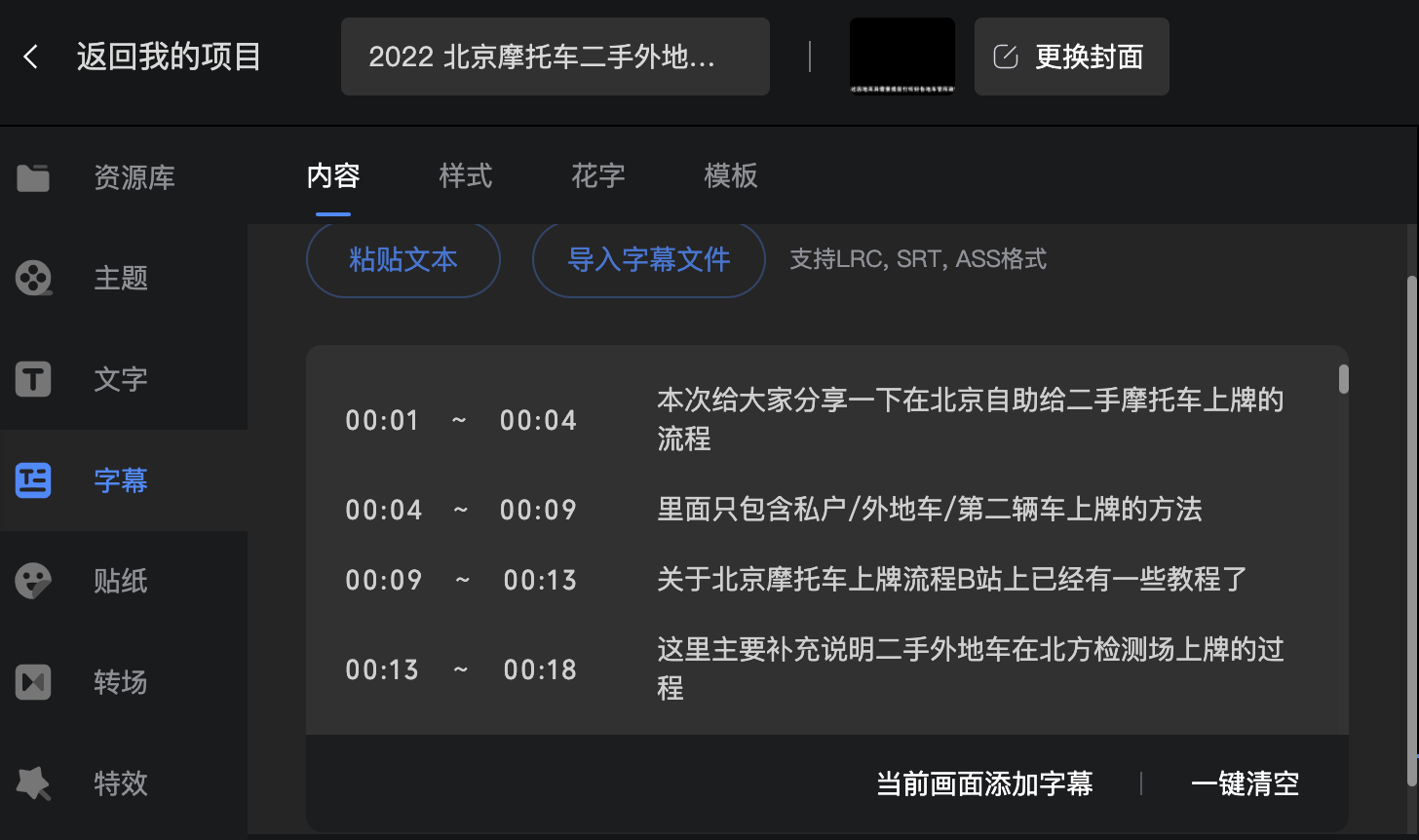
最終效果就會在視頻下方與語音同步播出字幕:

感覺比自動識別的字幕準確率高的多。
白嫖字幕說
像大多數免費工具一樣,免費只是攬客的招牌,畢竟天底下沒有免費的午餐,字幕說限制一次轉換不超過 1000 個漢字:
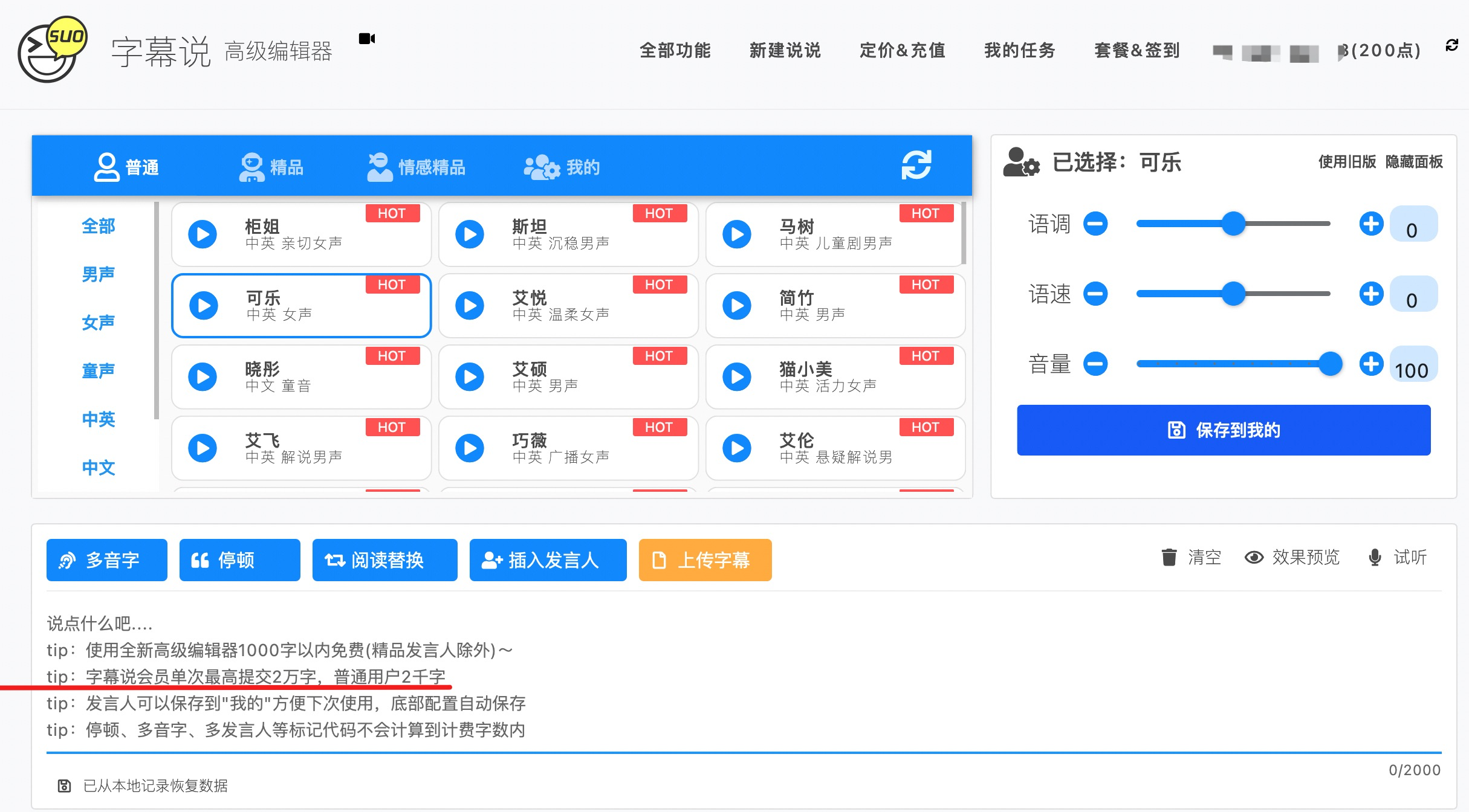
上面雖然標明 2000 字,實際上超過 1000 字已經開始要點數了:
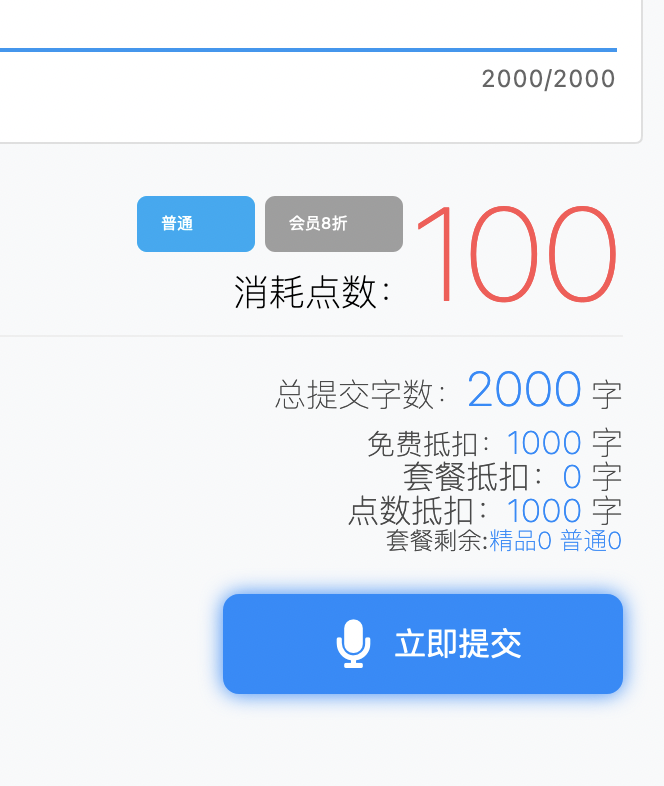
大概是 1 點 10 字的兌換方式,初始賬戶大概有 200 點,只能超 2000 字,而且這 2000 字也得遵守一次不超 2000 字的限制,如果文稿有 3000 字,仍得分兩次生成語音和字幕。
作為白嫖用戶,別說花錢買點數,就是用點數也是不樂意的,每次免費的不是限制 1000 字嗎,那就按這個限制將文稿切分一下:
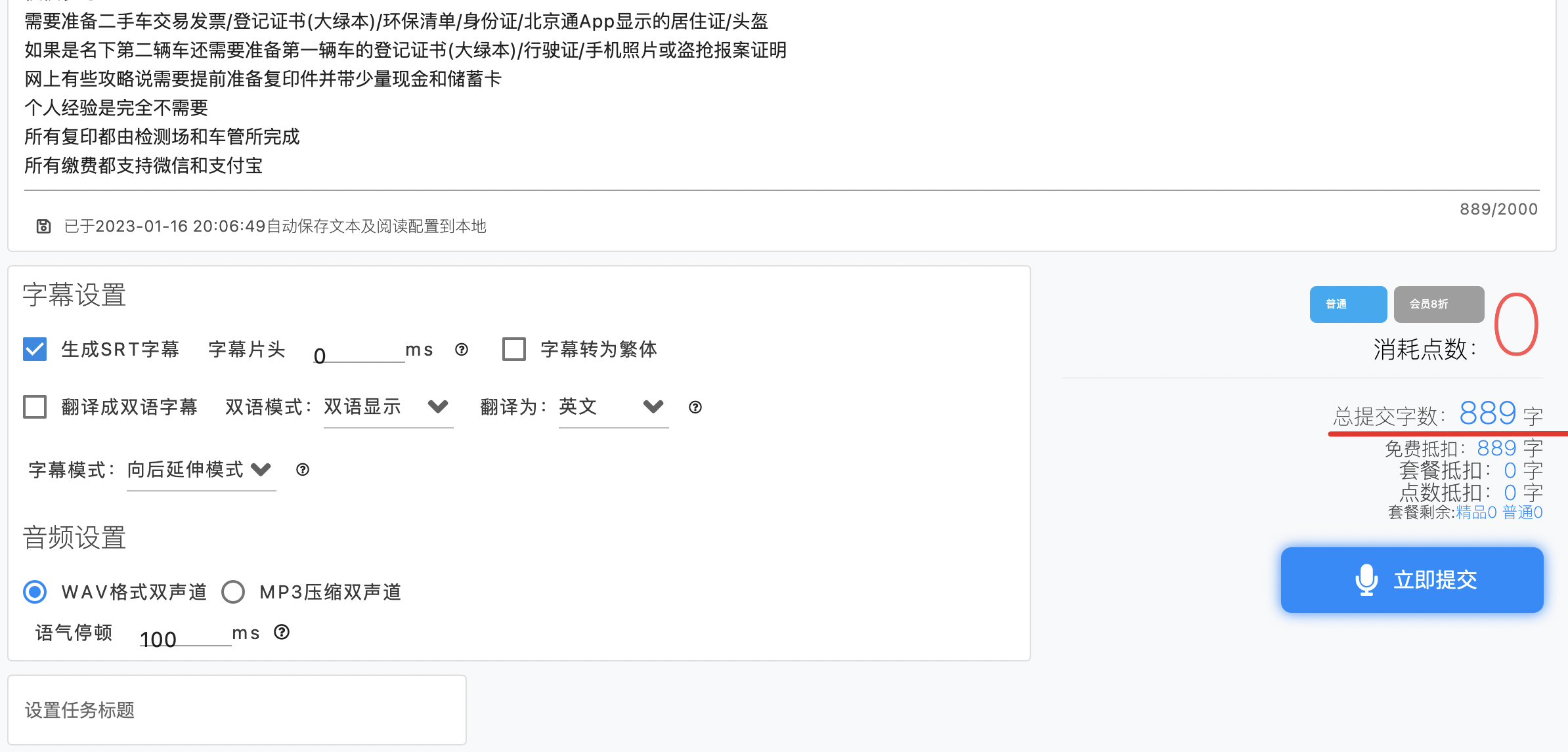
哈哈,果然白嫖成功,點立即提交后就可以跳轉到任務查詢界面了:

轉換完成后可以選擇對應的音頻和字幕文件進行下載,下載后的 srt 文件長這個樣子:
1
00:00:00,000 --> 00:00:04,600
本次給大家分享一下在北京自助給二手摩托車上牌的流程
2
00:00:04,600 --> 00:00:08,680
里面只包含私戶/外地車/第二輛車上牌的方法
3
00:00:08,680 --> 00:00:12,560
關于北京摩托車上牌流程B站上已經有一些教程了
4
00:00:12,560 --> 00:00:17,120
這里主要補充說明二手外地車在北方檢測場上牌的過程
...每段字幕之間以空行分隔,分為三行內容,分別是序號、播放時間、文字內容。對于文稿中一些比較長的行,后臺會自動拆分為多個字幕段落。
srt 文件拼接
下面將拆分后的音頻和字幕導入 B 站云剪輯中。音頻比較簡單,上傳文件后一段段拖到合成的視頻中就可以了;字幕就麻煩了,云剪輯只支持一次導入一個字幕文件,導入新的字幕會自動清空之前的內容,因此需要將切分后的字幕文件拼接成一整個文件導入。
一開始用了 cat,生成的文件確實包含了所有內容,但是導入后發現只有最后一部分字幕生效了,末尾還保留了一部分前面的字幕,全亂套了:
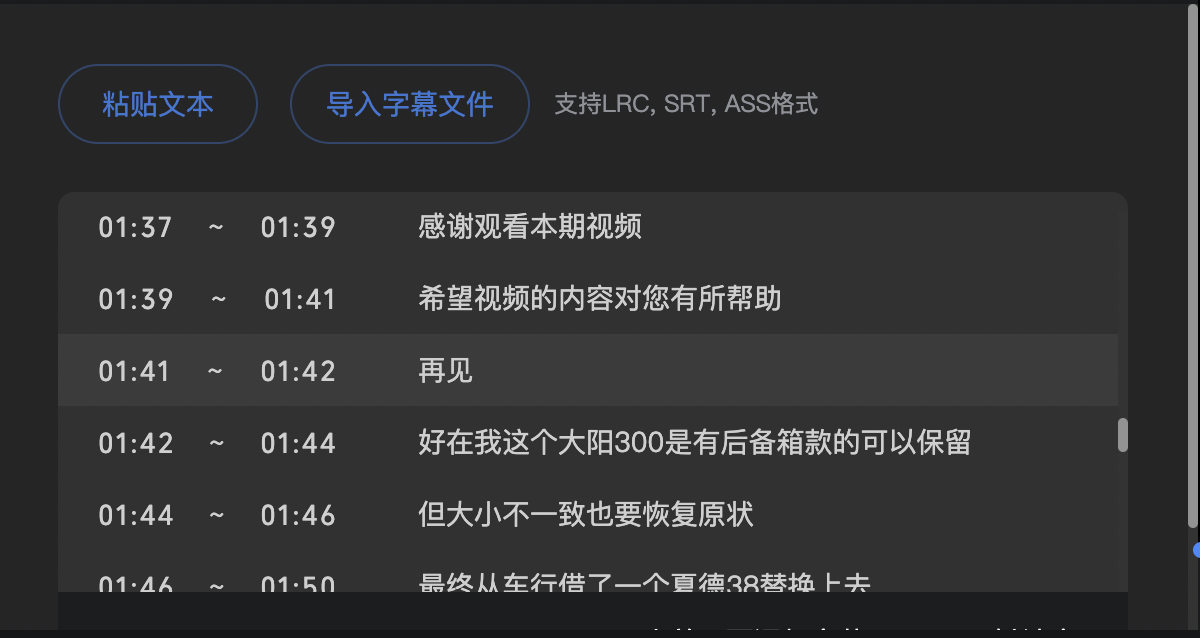
原來,不調整字幕中的序號和播放時間,會導致前面的被后面同序號的字幕所覆蓋。看起來需要找一個字幕文件拼接工具了,經過一番百度,主要找到下面幾個工具
SrtEdit
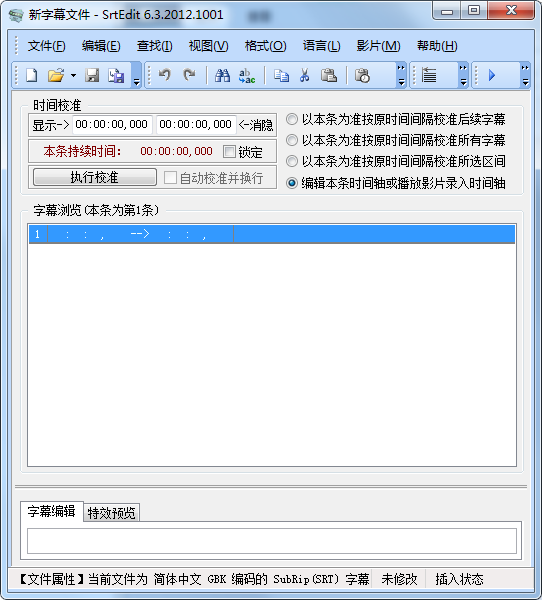
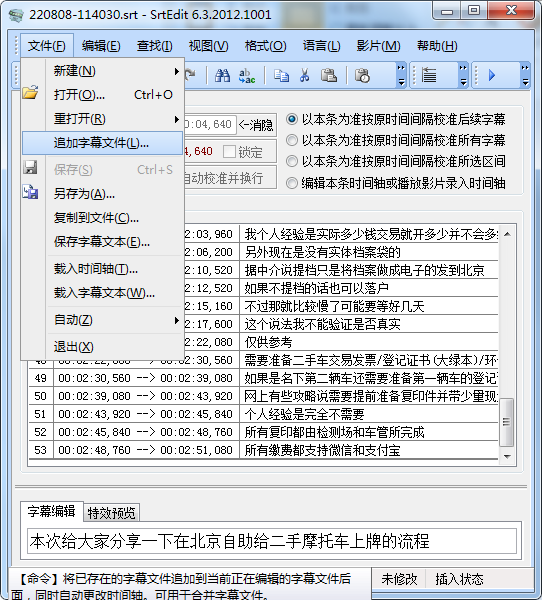
這個是一個專門對字幕文件做各種處理的工具,打開字幕文件后,直接追加即可實現文件的拼接:
追加時還可以選擇新文件的起始時間:
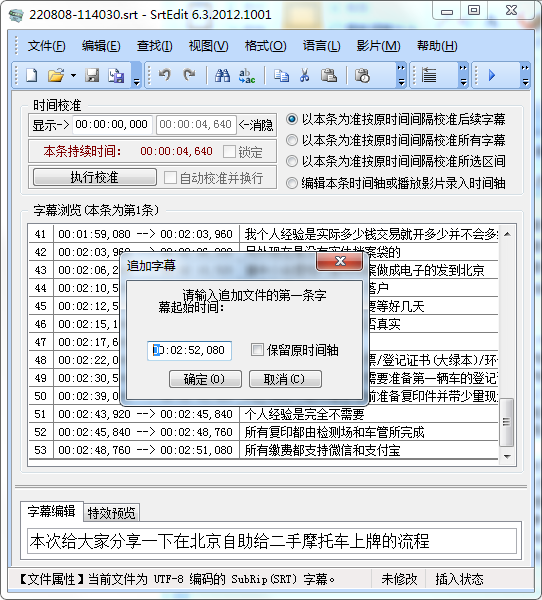
默認是上一個文件結尾時間加 1 秒。追加后就可以直接另存為拼接后的文件。
Srt Sub Master
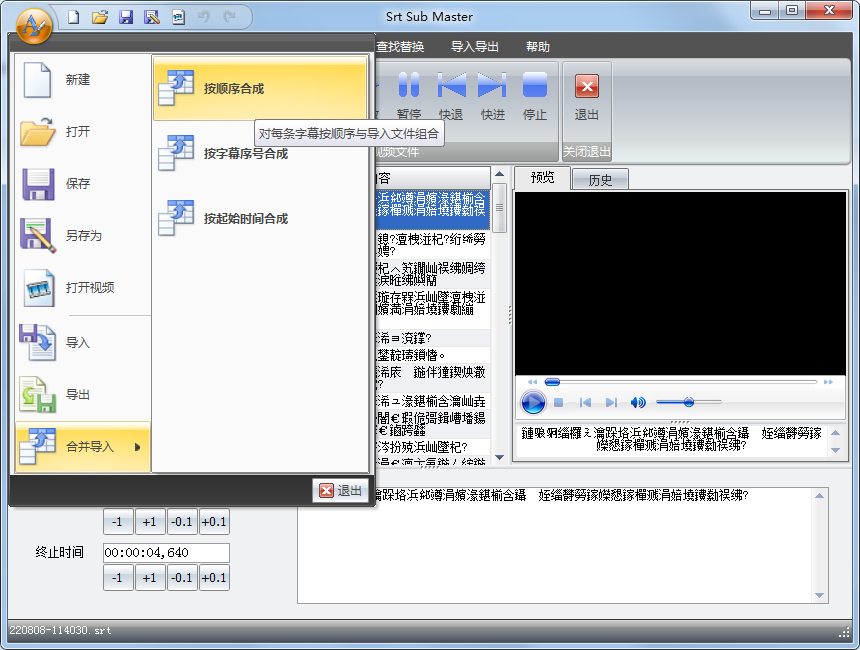
打開第一個文件后選擇:文件->合并導入->按順序合成,在彈出的選項框中進行設置:
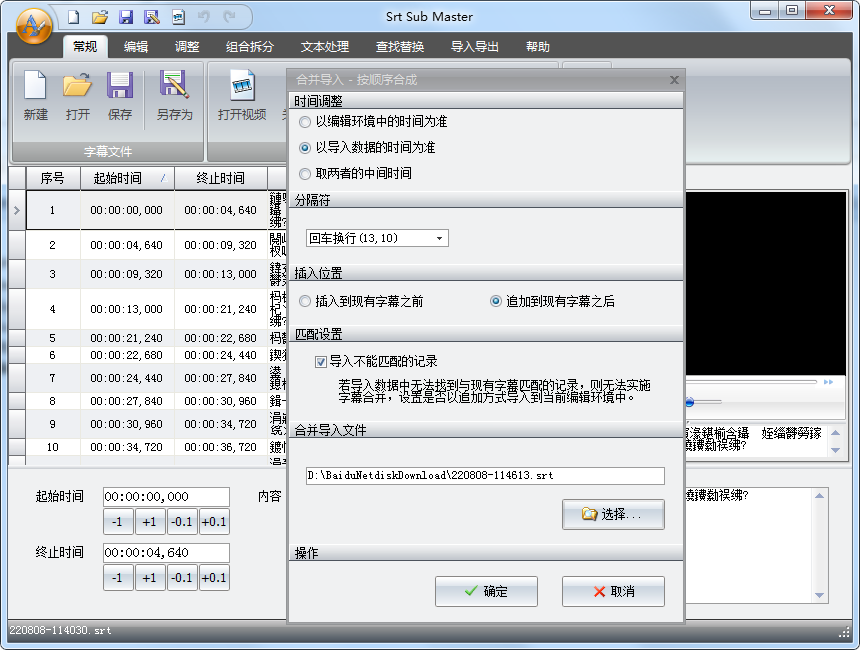
選擇要合并的文件后就可以了:
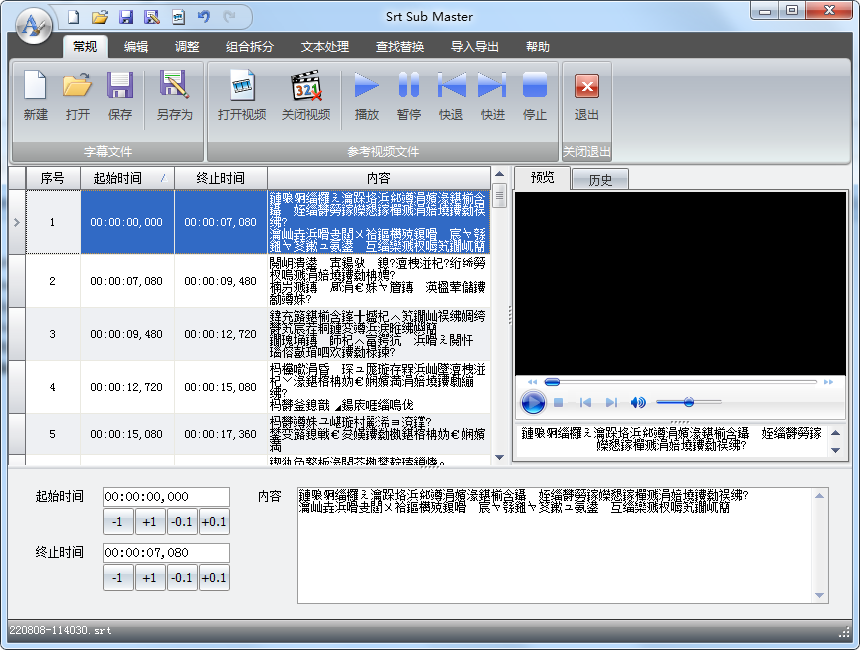
不過最終效果好像是將多條字幕合并到一個時間段上了,貌似是用來整合中英文字幕的。翻了一下應用提供的其它功能菜單,沒發現直接拼接兩個字幕文件的功能,pass
Subtitle Workshop
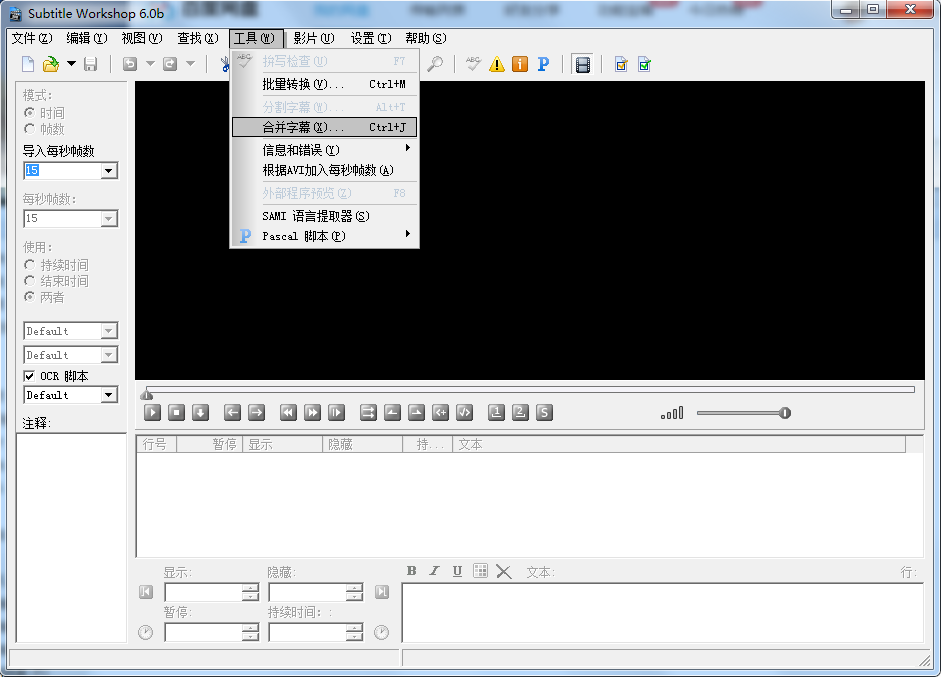
打開軟件后直接選擇:工具->合并字幕
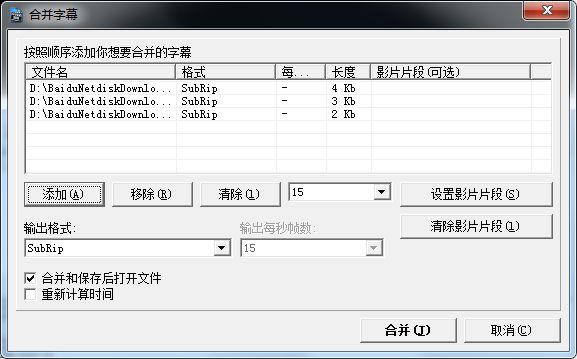
在彈出的選擇框中選擇文件后合并:
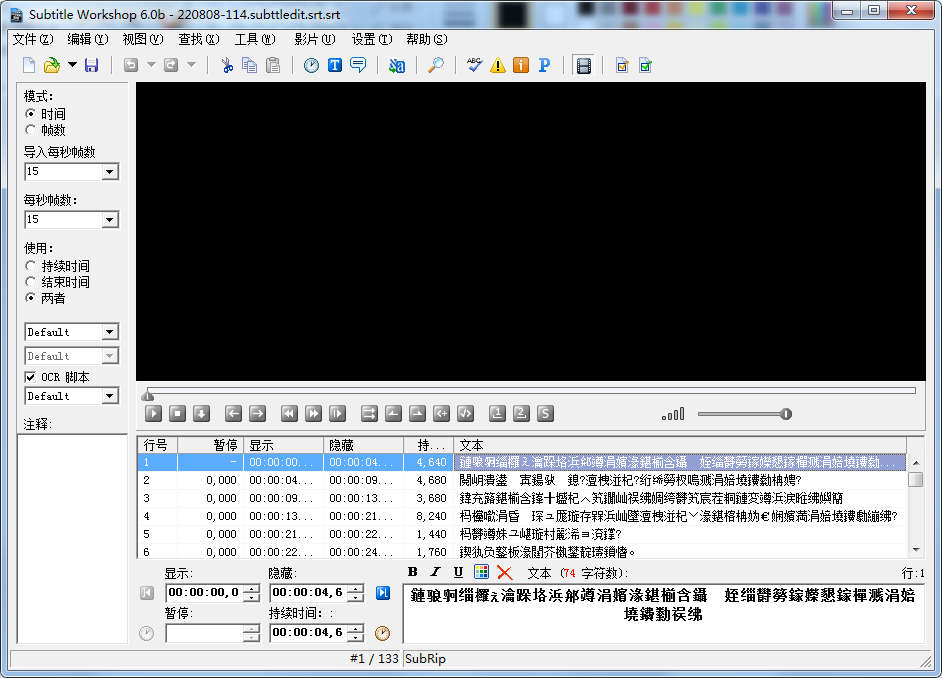
最后保存合并后的文件。
這里字幕中的漢字顯示為亂碼,一開始以為是從字幕說導出 srt 文件時沒有選擇帶 BOM 的 utf-8 格式所致:
切換到帶 bom 格式后仍不行:
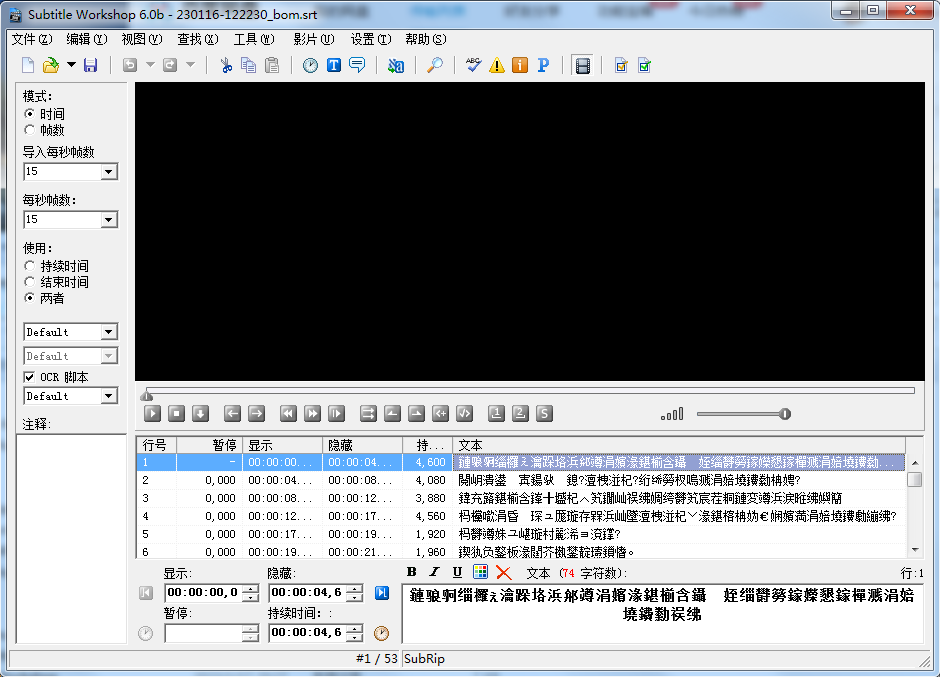
但同樣的亂碼問題,對于 Srt Sub Master 卻可以用上面的辦法解決:
一時半會兒沒弄明白 Subtitle Workshop 是個什么情況,pass
橫評
經過一番對比,Sub Srt Master 沒有找到對應的功能,Subtitle Workshop 在漢字編碼上存在一些問題,最后選擇了 SrtEdit。因為當時比較急,就用選定的這個工具生成的字幕文件導入到 B 站云剪輯去生成視頻了。
srtcat
GUI 工具固然好用,然而有兩個問題:
- 依賴某些平臺,例如 windows,這對 mac 用戶非常不友好
- IDE 形式的圖形工具一般是包羅萬象的,而我的場景非常單一,安裝了許多不必要的功能。
第二點對 SrtEdit 還不明顯,看看其它兩個,有些還和視頻文件耦合在一起,字幕只是其功能中的一小部分。其實 unix 的哲學就是提供 tool 的集合,而非做一個包羅萬象的平臺,工具的生命周期遠遠大于平臺,因為你永遠無法預測將來的用戶會怎么使用。提供單一功能的工具供用戶去選擇來集成在他們的場景中是最好的方式。
基于這個想法,再加上拼接 srt 文件的功能并不復雜,主要是序號和時間上的處理,所以決定使用 shell 腳本手搓一個,名字就叫 srtcat 吧:
> sh srtcat.sh
Usage: srtcat [-t timespan] file1 file2 ...在使用上非常簡單,參數列表為要拼接的 srt 文件,內容都從序號 1 開始,第一個文件的起始時間需要從 00:00:00,000 開始;-t 選項指定文件間的時間間隔,默認 1000 毫秒。拼接結果將打印到 stdout,可以重定向到新文件。錯誤和警告將打印到 stderr 防止污染 stdout 內容。
項目地址:https://github.com/goodpaperman/srtcat
這個工具只包含一個 shell 腳本 srtcat.sh,230 多行,比較好讀,這里不逐行解說了,只說明一下重點功能的方案選型。
拼接過程中時間的處理是個重點,按處理的時序又分為拆分、去零,下面分別說明。
拆分
形如 hh:mm:ss,xxx 格式的時間,首先需要從字符串提取時、分、秒、毫秒四個部分,這部分主要想說一下拆分時間字符串的三種方案。
cut
最直觀的方式就是使用 cut 命令挨個截取:
hour=$(echo "${line}" | cut -b 1-2)
min=$(echo "${line}" | cut -b 4-5)
sec=$(echo "${line}" | cut -b 7-8)
msec=$(echo "${line}" | cut -b 10-12)調用 cut 的命令來處理字符串的缺點是效率比較低,一個時間處理就要啟動 4 個子進程,大量的這種字符串操作,絕對會拖慢腳本效率,替代的方案是 shell 自己的字符串截取:
hour=${line:0:2}
min=${line:3:2}
sec=${line:6:2}
msec=${line:9:3}這樣雖然可以避免上面的性能問題,但也是基于固定長度來截取,這是基于時分秒占用 2 位、毫秒占用 3 位的假設,如果 hour 占用超過 2 位的話 (hour > 99),就全對不上了,考慮到拓展性,方案 1 這種固定長度的方式就 pass 了。
awk
不使用固定長度,那就按關鍵字符分割。首先想到的是 awk 命令,可以通過 -F 選項指定多個分隔符:
line="00:01:02,003 --> 04:05:06,007"
echo "${line}" | awk -F':|,| ' '{ for (i=1; i<=NF; i++) { print $i }}'注意多個字符間通過 | 分隔,效果如下:
> sh awk.sh
00
01
02
003
-->
04
05
06
007那如何將分割的字符串賦值給 shell 變量呢?有很多方法,這里用到了 eval:
line="00:01:02,003 --> 04:05:06,007"
val=$(echo "${line}" | awk -F':|,| ' '{print "hour1="$1";min1="$2";sec1="$3";msec1="$4";hour2="$6";min2="$7";sec2="$8";msec2="$9";"}')
echo "${val}"
eval "${val}"
echo "${hour1}:${min1}:${sec1},${msec1}"
echo "${hour2}:${min2}:${sec2},${msec2}"運行效果如下:
> sh awk.sh
hour1=00;min1=01;sec1=02;msec1=003;hour2=04;min2=05;sec2=06;msec2=007;
00:01:02,003
04:05:06,007eval 后就可以使用 shell 變量hour1/min1/sec1/msec1引用第一個時間、使用hour2/min2/sec2/msec2引用第二個時間,這里變量名可以任意設置。
IFS
awk 雖然直觀,但是仍要調起一個子進程,有沒有更高效的方法呢?網上搜到一篇文章,說可以用 shell 自帶的 IFS 分隔符設置來處理日期拆分,感覺還蠻符合我這個場景的,拿來試驗一下:
#! /bin/sh
line="00:01:02,003 --> 04:05:06,007"
OLD_IFS="${IFS}"
IFS=":, "
arr=(${line})
IFS="${OLD_IFS}"
for var in "${arr[@]}"
do
echo "${var}"
doneIFS 字符串的每個字符就是一個分割符。運行上面這段腳本,得到:
> sh ifs.sh
00
01
02
003
-->
04
05
06
007使用 ${arr[0]}:${arr[1]}:${arr[2]},${arr[3]} 引用第一個時間,${arr[5]}:${arr[6]}:${arr[7]},${arr[8]} 引用第二個時間。
橫評
從性能上講,IFS 方式是最優解,shell 字符截取次之,awk+eval 次之,cut 最末;從可拓展性角度講 (hour > 99),IFS、awk 方式優于 shell 字符截取和 cut;從直觀性上講,awk+eval 最優、shell 字符截取和 cut 次之,IFS (使用 arr[N] 引用) 最末。考慮到腳本以后使用場景,面對比較大的 srt 文件,性能將成為一個瓶頸,因此選擇 IFS 來盡量提升腳本性能,雖然犧牲了直觀性,不過保留了可拓展性。
去零
拆分后的時間變量是字符串,有前導零時,直接參與加法運算時,偶爾會出現下面的錯誤:
srtcat.sh: line 8: 080: value too great for base (error token is "080")原因是將毫秒 080 識別為八進制 (前綴 0 為八進制,前綴 0x 為十六進制) ,而八進制中最大的數字是 7,遇到超過 7 的數字就會報錯。
下面介紹幾種解決方案:
${var##0*}
一開始是想用 shell 字符串截取,通過 ## 實現從左向右最長匹配,通過0*匹配全零串,但是發現這個方案不行:
> var=080
> echo ${var##0*}
> echo ${var#0*}
80
> var=007
> echo ${var##0*}
> echo ${var#0*}
07主要是 shell 將##0*理解為了匹配所有數字,直到遇到符號或字母時才會停止匹配,導致匹配非零數字。pass
sed
然后想到的就是 sed 的正則匹配及數字提取:
> var=007
> echo $var | sed -n 's/0*\([0-9]*\)/\1/p'
7
> var=080
> echo $var | sed -n 's/0*\([0-9]*\)/\1/p'
80
> var=123
> echo $var | sed -n 's/0*\([0-9]*\)/\1/p'
123通過0*匹配前導零、[0-9]*匹配剩下的數字。這個方案缺陷很明顯,時間的每個分量需要啟動一個單獨的 sed 子進程,和之前的 cut 一樣,性能肯定好不了。
$(())
參考網上的一篇文章,使用了一個 shell 運算符的奇技淫巧:
> var=080
> echo $((1${var}-1000))
80
> var=007
> echo $((1${var}-1000))
7
> var=123
> echo $((1${var}-1000))
123就是在明確字符串數字位數后,加一個前導 1 使其成為 1xxxx 的形式,此時轉換為數字不會報錯,再減去因為加前綴 1 導致的數字增長值 (例如對于 3 位數字是 1000),就還原成了原本的數字,且前導零也去除了。這個方法的缺陷也很明顯,需要事先知道數字字符串位數,拓展性 (hour>99) 不好。
awk
之前在對比拆分方案時曾經介紹過 awk,如果使用 awk+eval 方案,則將前導零刪除就是順手的事兒:
line="00:01:02,003 --> 04:05:06,007"
val=$(echo "${line}" | awk -F':|,| ' '{print "hour1="$1/1";min1="$2/1";sec1="$3/1";msec1="$4/1";hour2="$6/1";min2="$7/1";sec2="$8/1";msec2="$9/1";"}')
echo "${val}"
eval "${val}"
echo "${hour1}:${min1}:${sec1},${msec1}"
echo "${hour2}:${min2}:${sec2},${msec2}"和之前對比,僅僅在 awk 命令內部構造賦值表達式時為每個字段增加了一個除 1 操作 (/1),awk 就自動將字符串轉換為數字了:
> sh awk.sh
hour1=0;min1=1;sec1=2;msec1=3;hour2=4;min2=5;sec2=6;msec2=7;
0:1:2,3
4:5:6,7實測乘 1 (*1) 也可,這也太方便了。
橫評
將拆分和去零結合起來,有以下幾種搭配:
- $((var:0:2)) + sed
- $((var:0:2)) + $((1$var-100))
- awk+eval
- IFS + sed
- IFS + $((1$var-100))
由于 cut 方案明顯不如 shell 字符串截取性能好,這里統一使用 $((var:0:2)) 代替 cut,它形成了前兩種方案,明顯第二種更優;awk+eval 本身就能刪除前導零,就沒有再和 sed 或 $((1$var-100)) 去做組合;IFS 方案也有兩種組合,明顯第二種更優。這樣一精簡,就只剩三個最終備選方案了:
- $((var:0:2)) + $((1$var-100))
- awk+eval
- IFS + $((1$var-100))
方案 1 和方案 3 差別不大,優勢都是性能高、缺陷都是拓展性差;方案 2 的優勢是拓展性好、可讀性高,缺陷是性能差。
再縮小我的應用場景,一般字幕文件再大,也很少有 hour > 99 的情況,而文件內容多的時候,成千上萬行卻是輕輕松松,對性能要求比較高,對拓展性要求比較小。綜合考慮,決定犧牲拓展性,追求性能,方案 2 pass。方案 1 和方案 3 均可,目前工具使用的是方案 3。
結語
當時因為制作視頻急用,沒有用到這個工具,直接使用了 SrtEdit 的輸出。這個工具能 run 以后,特地找之前的文件做驗證,發現拼接后的文件與 SrtEdit 生成的完全一樣,下次再做類似視頻,應該可以不用離開 mac 平臺了,哈哈。
目前 srtcat 工具支持 mac、linux、windows 三種平臺 (windows 需要 git bash),總之能運行 shell 的系統都支持。
之前在做方案選擇時一直強調性能取向,那 srtcat 目前采用的方案真的有更強的性能嗎?下面做個試驗,選擇三個測試文件,總計 500 多行:
> wc -l 220808*
211 220808-114030.srt
183 220808-114613.srt
135 220808-114838.srt
532 220808.txt
1061 total選取兩種方案,一種是 awk+eval,另一種是 IFS+$((1$var-100)),先看第一種方案的性能:
> time sh srtcat.awk.sh 220808-114*.srt > 220808.txt
...
real 0m1.826s
user 0m0.822s
sys 0m1.186s總耗時 1.826 s。再看第二種方案:
> time sh srtcat.ifs.sh 220808-114*.srt > 220808.txt
...
real 0m1.539s
user 0m0.669s
sys 0m1.037s總耗時 1.539 s,快了 0.287 s,提速約 1.2 倍。cut 和 sed 的方案沒有試,因為那個肯定慢的離譜。
參考
[1]. 字幕說
[2]. sed 提取固定間隔行
[3]. [愛幕] 一個在線字幕編輯器
[4]. 【Linux】Shell命令 getopts/getopt用法詳解
[5]. shell腳本報錯 value too great for base
[6]. srtsubmaster用戶手冊字幕編輯視頻字幕音頻字幕(精品)
[7]. 使用Subtitle Workshop把幾個srt 字幕文件合并
[8]. shell去除字符串前所有的0
[9]. shell 腳本去掉月份和天數的前導零
[10]. 詳細解析Shell中的IFS變量
[11]. shell腳本實現printf數字轉換N位補零
[12]. SRT字幕格式
本文來自博客園,作者:goodcitizen,轉載請注明原文鏈接:http://www.rzrgm.cn/goodcitizen/p/concat_srt_files_by_shell_scripts.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號