
解密prompt系列63. Agent訓練方案:RStar2 & Early Experience etc
 當大模型成為Agent,我們該如何教會它“行動”?我們將看到一條演進路線:從優化單一動作(ReTool),到學習長程規劃(RAGEN),再到提升思考質量本身(RStar2),最后到一種不依賴外部獎勵的、更底層的經驗內化方式(Early Experience)。
當大模型成為Agent,我們該如何教會它“行動”?我們將看到一條演進路線:從優化單一動作(ReTool),到學習長程規劃(RAGEN),再到提升思考質量本身(RStar2),最后到一種不依賴外部獎勵的、更底層的經驗內化方式(Early Experience)。
當大模型成為Agent,我們該如何教會它“行動”?純粹的模仿學習(SFT)天花板明顯,而強化學習(RL)又面臨獎勵稀疏、環境復雜、探索成本高的挑戰。本文將帶你深入四種前沿的Agent訓練方案:ReTool, RAGEN, RStar2, 和 Early Experience,看它們如何巧妙地設計環境、利用反饋,讓Agent不僅“能干”,而且“聰明”。
我們將看到一條演進路線:從優化單一動作(ReTool),到學習長程規劃(RAGEN),再到提升思考質量本身(RStar2),最后到一種不依賴外部獎勵的、更底層的經驗內化方式(Early Experience)。
ReTool:讓模型學會“何時以及如何”使用單一工具
- ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
“先學會用一個工具,再談組合拳。”
- 核心目標:教會模型在推理過程中,何時調用一個單一的Code工具(如Python解釋器),并通過RL優化這一決策過程。
- 方法精髓:交錯代碼執行的Rollout機制。模型生成、環境執行、結果注入、模型繼續生成,形成一個動態的交互式軌跡。
ReTool是最基礎的RL Agent訓練,整體流程基本參考了DeepSeek R1-Zero的訓練過程通過先SFT再RL的兩階段訓練流程,教會模型在推理過程中何時調用單一Code工具,通過單輪或多輪工具調用進行任務完成。
?? Step1 - SFT
SFT部分是通過模型反饋來把原始基于文本的推理結果,轉換成包含code工具調用的高質量推理樣本,讓模型先通過模仿學會加入code工具的推理模版。而SFT的樣本格式我們在RL部分一起說。
SFT階段保證了模型推理可以穩定的生成包含code的推理格式,那RL階段的目標是讓模型超越模仿,通過與環境(代碼解釋器)的交互和結果反饋,自主探索和優化工具使用的策略,例如:何時調用工具、調用什么工具、如何處理錯誤等。
這里提一句,當下很多伙伴采用API進行大模型調用,工具調用都通過API傳參實現,而已不知道在各個模型的system prompt內部究竟是如如何處理工具參數的。其實不同模型之間差異還是比較大的,這里提供chat template 參考
?? Step2 - RL
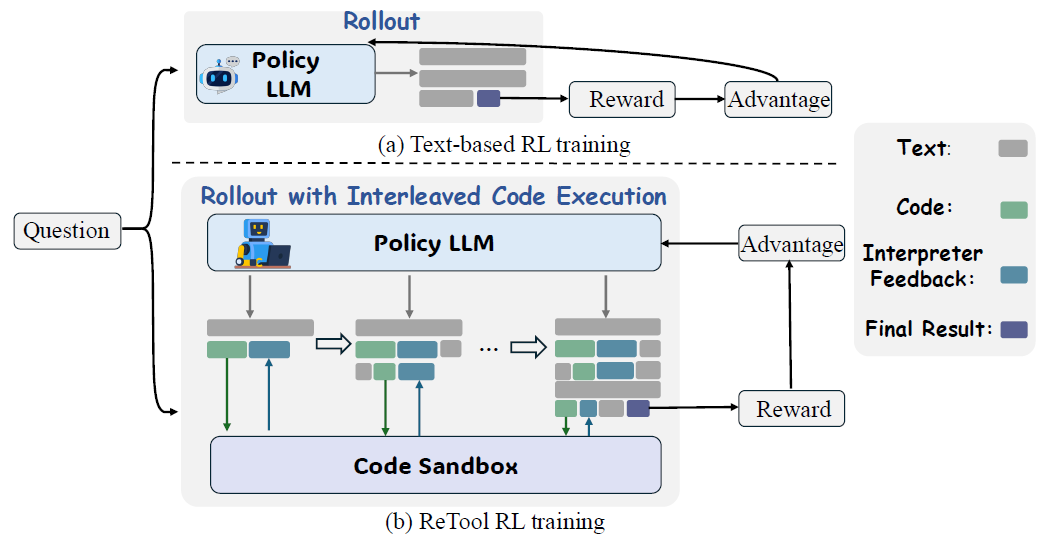
- RL 樣本構建 - Rollout with Interleaved Code Execution
RL樣本(稱為Rollout)是在訓練過程中動態生成的。ReTool 的核心創新之一就是其支持交錯代碼執行的Rollout機制。
其交互式Rollout流程如下
- 模型生成:策略模型(Policy LLM)接收問題,并開始生成響應。它使用特定的提示模板(論文中圖7),指導其輸出格式。
- 代碼觸發:當模型生成一個代碼塊,并以 標簽結束時,生成過程會暫停。
- 代碼執行:解析出代碼塊中的代碼,會發送到一個安全的代碼沙箱環境中執行(哈哈就是前兩章我們聊的類似E2B的沙箱方案)
- 觀測注入:沙箱的執行結果(無論是成功的計算結果還是錯誤信息)被封裝在
... 標簽中,并回傳給模型。 - 繼續生成:模型將執行結果作為上下文的一部分,繼續生成后續的推理或下一個代碼塊。
- 軌跡完成:重復此過程,直到模型生成最終答案。最終形成一個完整的 混合推理軌跡:[t1, c1, f1, t2, c2, f2, ..., o]。
- RL 訓練方式
- 算法:PPO
- 獎勵設計:follow DeepSeek,僅基于最終答案的正確性。
- 關鍵訓練技術:
- Interpreter Feedback Masking:在計算PPO損失時,屏蔽
<interpreter>標簽內的所有Token(因為這不是模型生成的)。這是保證訓練穩定性的關鍵。 - KV-Cache Reuse:當代碼執行時,緩存之前生成的所有KV-Cache,只計算反饋Token的新Cache,大幅降低內存開銷,加速訓練。
- 異步代碼沙箱:構建一個分布式的、異步的代碼執行環境,避免代碼執行成為訓練瓶頸。
- Interpreter Feedback Masking:在計算PPO損失時,屏蔽
RAGEN:在多輪隨機環境中學會“深謀遠慮”
- RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
“人生不是單步決策,Agent也是。”
- 核心目標:在多輪、隨機性的環境(游戲)中,訓練模型的長程規劃與決策能力。
- 方法精髓:基于完整軌跡的強化學習。模型不僅要輸出動作,還要輸出思考過程,并對整個思考-行動序列進行優化。
Agent RL訓練無外乎以下幾個核心要素:環境構建、軌跡生成、RL訓練。我們按順序來說
?? step1 - 環境構建
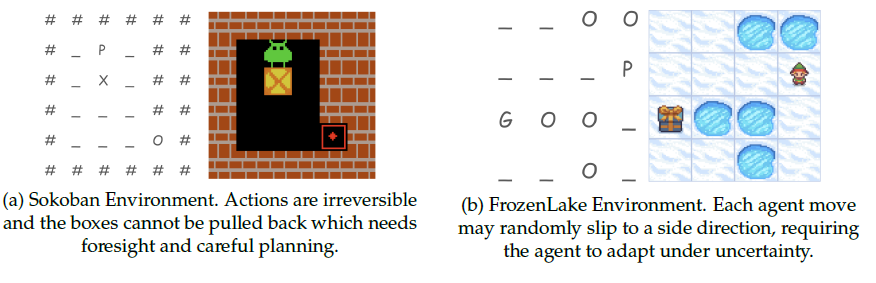
我們先來說下環境構建,RAGEN雖然考慮到了動態隨機環境的重要性但只設計了較為簡化的游戲環境
- slot Machine(問就是中文詞敏感):單輪隨機環境,測試在符號語義下的風險敏感推理。
- 推箱子:多輪確定性環境(起始和終止位置固定),因為推箱子的行為不可逆(往回推),所以用于測試不可逆的長視野規劃。
- 冰面濕滑的推冰塊:多輪隨機環境(因為冰面濕滑,agent行為存在不確定性),測試在隨機轉移下的規劃能力。
?? step2 - 軌跡構建
有了環境我們看下論文是如何構建Agent行為軌跡的。 每個樣本都從一組初始狀態開始,讓模型隨機生成N條完成軌跡,軌跡中的每一步,模型都輸出一個結構化的、包含推理過程的行為如下:
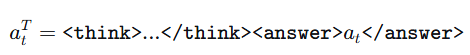
<think>...</think>:模型內部的推理過程,是“慢思考”的體現。<answer>...</answer>:最終提交給環境執行的具體動作。
以上的三種環境會根據Agent行為給出或隨機或確定的反饋,隨后Agent會基于反饋給出進一步行動直到完成。整個軌跡中所有的組成部分(包括思考令牌和執行令牌)都會參與策略梯度計算,這意味著模型被激勵去生成那些能帶來高回報的推理過程。
?? step3 - RL訓練
首先每種環境都有對應的獎勵函數設計如下,包含每一步的得分和對最終結果的得分,同時為了保證推理格式穩定可被解析,還有格式獎勵,當模型沒有按照以上推理格式輸出時會有0.1的扣分。
| 環境 | 任務獎勵規則 | 設計意圖與說明 |
|---|---|---|
| slot Machine | 選擇低風險臂(Phoenix):固定獲得 +0.15 選擇高風險臂(Dragon):從伯努利分布(0.25)采樣,成功+1.0,失敗+0.0 預期收益:Dragon (0.25) > Phoenix (0.15) |
這是一個探索與利用的權衡測試。低風險臂獎勵更穩定,但高風險臂長期期望更高。模型需要通過推理克服短期頻繁的失敗,堅持選擇高期望選項。 |
| Sokoban | 稀疏獎勵與密集懲罰結合: ? 每個箱子在目標點上:+1 ? 每個箱子不在目標點上:-1 ? 任務完成時:+10 ? 每執行一個動作:-0.1 |
? 鼓勵最終解決問題(+10)。 ? 引導模型高效解決問題(每步-0.1)。 ? 通過箱子位置的正負獎勵提供中間的、弱監督信號,幫助模型學習。 |
| Frozen Lake | 極端的稀疏獎勵: ? 成功到達目標(G):+1 ? 其他所有情況(掉入冰洞、未完成):0 每一步只有1/3的概率成功 |
這是最困難的獎勵設置。模型在成功之前幾乎沒有任何反饋,必須通過多次試錯來學習有效的策略。 |
其次對比傳統單步RL只使用(prompt,response)樣本對,只對最終輸出結果計算獎勵,論文引入了StarPO框架對整個軌跡計算累計獎勵,并支持PPO、GRPO多種優化策略 。這種基于完整軌跡的訓練目標對于模型的長規劃與多輪決策能力有顯著提升,原因是:
- 稀疏性:尤其是在Frozen Lake和Bandit中,獎勵非常稀疏或具有欺騙性,這迫使模型必須發展出有效的多步推理和規劃能力,而不能依賴密集的、步步為營的獎勵信號。
- 軌跡級視角:通過GAE(γ=1.0, λ=1.0)和軌跡級優化目標,模型被明確地訓練去關注長期回報,這對于多輪決策至關重要。
在如何把整個軌跡的整體獎勵,計算到每一步的每個token上,論文使用了GAE(1.0,1.0)作為優勢估計函數。既未來獎勵不打折,并且使用多次隨機軌跡的價值(模特卡洛)來進行優勢估計。(不過這個參數設計和論文本身選擇的環境有關,回合較短,并且強調無偏性),想更多了解GAE的可以劃到文末去看GAE小課堂。
在實驗過程中論文有以下幾點發現
- 多步RL中PPO和GRPO的效果存在差異,影響因素主要在于價值函數是否好估計(任務隨機性低),容易估計的場景PPO有效果優勢
- Echo Trap:效果衰減的原因之一RL會擬合到表面的pattern,導致模型推理進行模式循環,損失多樣性。(雖然但是我感覺這和RL本身的設計相關,有些task specific)
為了穩定長行為軌跡的RL訓練,論文提出了StarPO-S,包含以下三點核心改進
- 基于不確定性的軌跡過濾:僅保留軌跡方差最高的topK軌跡,過濾本身確定性比較高的軌跡,避免模型過度模仿形成固化的推理pattern
- 移除在單輪RL訓練中常用的KL Divergence:也是處于鼓勵模型更大范圍探索的考慮(idea來自Seed的DAPO論文,后面微軟RStar也沿用了)
- 增加非對稱clip上界大于下界:$ \epsilon_{\text{high}} = 0.28, \epsilon_{\text{low}} = 0.2 $(idea來自Seed的DAPO論文,后面微軟的RStar也沿用了)
整體上RAGEN和其他Agent RL訓練論文因為在環境選取上的差異而顯得不太一樣,最重要的差異在于更多真實環境任務是很難獲得中間步驟獎勵的。所以我們接下來看下微軟在真實任務上實驗多輪agent優化的技術報告,并對比一些結論差異。
RStar2-Agent - 用工具調用作為“磨刀石”,讓模型Think Smarter
- rStar2-Agent: Agentic Reasoning Technical Report
“通過空間擾動,讓模型學習如何想得更好而非更長。”
- 核心目標:通過引入Code工具調用帶來的環境反饋與噪聲,利用RL全面提升基模型本身的思考質量,而非僅僅是工具調用成功率。
- 方法精髓:漸進式RL訓練與正確軌跡重采樣。
微軟RStar2的出發點很有趣,并非使用RL直接提升Agent效果,而是使用Code工具引入環境噪聲,從而全面提升基模型的思考效果(think smarter而非longer)。這和MiniMax-M2作者近期的觀點不謀而合既Agent的泛化能力是在模型一切可能的操作空間上適應擾動的能力。下面我們分RL優化算法和訓練策略兩部分展開。
?? 核心算法:GRPO-ROC
論文采用了和DeepSeek相同的GRPO算法,并且和前面的RAGEN一樣沿用了DAPO提出的移除KL,增加非對稱CLIP來鼓勵模型空間探索的策略。
在此基礎上論文先是指出了當前RL訓練的兩個問題
- 基于結果的獎勵機制:無法對中間過程是否正確給出有效監督,可能存在冗長無效錯誤的中間推理過程,哈哈尤其是前一陣出現的一些中間模型經常會出現循環思考的問題,那思考過程長的讓人不忍直視。
- 環境噪聲:來自工具調用和工具執行過程中的各類報錯帶來的環境噪聲,其實我感覺不一定是報錯,各類正負向的環境反饋,相比原始的模型思考來說其實都是擾動(非內生)
針對以上問題論文提出了GRPO-RoC優化算法(Resample on Corret)。實現很簡單就是在訓練時先生成兩倍的探索軌跡,針對答案正確的軌跡只保留質量最高的50%(中間工具調用報錯更低、格式錯誤更少),同時對答案錯誤的軌跡進行均衡50%降采樣。
論文希望通過這樣的方式在保留通過正負軌跡對比習得經驗的基礎上,提升模型在正確軌跡上的推理效果,減少錯誤、低效的中間思考和工具調用。
?? 漸進式訓練流程
有了訓練策略,我們繼續看下RStar2是如何基于Qwen-14B-base模型進行訓練的。
首先訓練過程中模型進行多輪思考和工具調用的chat template如下,assistant通過REACT給出工具調用,再用user角色返回工具結果,然后繼續循環直到任務完成。不過不同模型對工具輸出的角色處理其實是不同的,像DeepSeek就是都放在assistant角色下用/<tool_output/>包裹,個人比較建議實用原模型本身的工具處理模版(在chat template中),這里論文使用的是qwen模型。
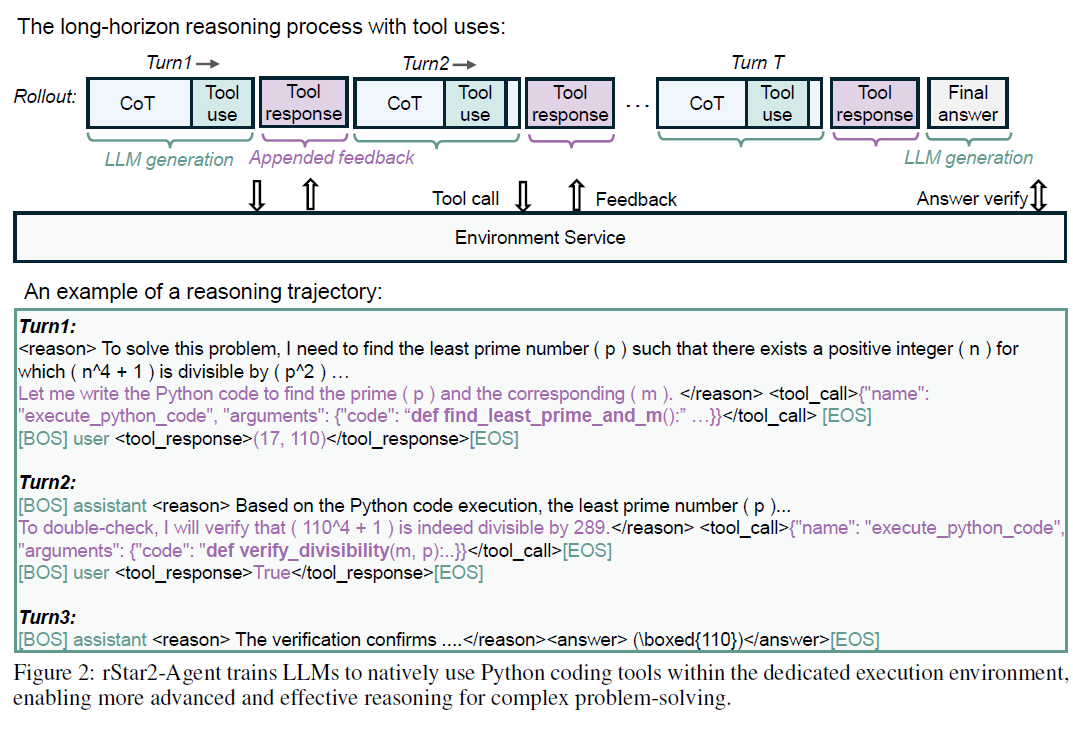
其次Base模型會順序經過以下兩個階段訓練
- non-reasoning SFT:突出無思考,只使用指令完成、JSON格式、基礎code工具調用樣本進行訓練,為后面的RL推理format奠定基礎。因此會得到理解能力顯著下降,但是工具調用略有上升,且回答會變得很短的一階段模型。
- multi-turn RL:這里構建了42K的高質量問答對涵蓋各類可驗證數學問題。通過3階段RL訓練
- RL stage-1: 42K樣本 + GRPO-ROC + 最長8K輸出長度 + 300stesp,鼓勵模型生成更有效簡短的reasoning,訓練和評估指標都基本穩定,超過8K的樣本占比也穩定在10%左右,平均回答長度4K
- RL stage-2: 把輸出長度提升到12K再訓練85stesp,平均回答長度提升到6K
- RL stage-3(125steps):此時多數樣本模型已經能完全正確回答,因此論文增加離線數據過濾策略使用最新的模型checkpoint推理,并過濾出17.3K難樣本(8次隨機推理中存在錯誤),然后在12K輸出長度上,再訓練了125個steps。
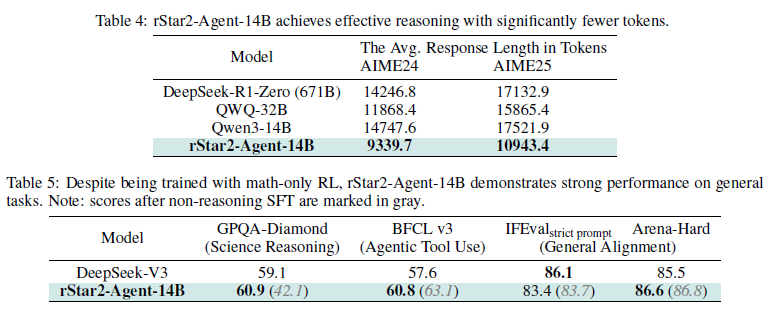
不難看出RStar2的訓練突出了漸進式這個核心思路。通過漸進式推理長度延長來兼顧模型思考效果和思考長度,通過漸進式難度提升來兼顧不同難度樣本的有效學習(避免簡單問題過度學習)。
在最終效果上,在訓練領域的數學類問題上RStar2的思考長度均顯著下降,但是在通用類問題的解決效果上依舊有穩定的提升 —— Think Smarter。
Agent Learning via Early Experience
- Agent Learning via Early Experience
- Scaling Agents via Continual Pre-training
“在學會跑之前,先學會看和想。”
- 核心目標:在正式的RL訓練之前,通過一種不依賴外部獎勵的方式,讓Agent通過自主探索來學習環境動態,為后續學習打下堅實基礎。
- 方法精髓:將Agent的早期探索經驗直接轉化為監督學習的信號,內化一個“世界模型”。
最近Meta放出的這篇重量級論文其實和前面的Agent RL都有些不同,個人感覺它并非用于替代Agent RL訓練,相反是用于在Agent RL之前搭建LLM和Agent的橋梁。本質上筆者感覺和阿里之前推出的Agentic CPT,在LLM之后增加Agent軌跡的后訓練思路有些相似(哈哈雖然論文里說的出發點截然不同),但Early Experience的訓練目標和訓練數據構建方案更native(scaling)。
論文提出了3個重要的概念
?? World Exploration:全方位探索世界是很重要的
世界探索,解決的是專家標注軌跡單一的問題
針對真實世界的問題,我們可以生成專家標注的執行軌跡,但是軌跡本身是單一的,它對整個世界的其他狀態的探索是不充分的,因此會導致模型在遇到非標準情形時缺乏處理能力。
因此論文在每個可枚舉的環境狀態上,都在專家的Action之外,隨機采樣了另外K個行為,和該行為會導致的環境反饋。這樣我們就能得到一份對環境探索更加全面的數據集
本質上環境狀態的變化(觀測)就是對行為質量的最好監督信號(反饋),但這個監督信號我們要如何通過訓練內化到模型參數中呢?
?? World Modeling:使用NTP來內化Early Experience
世界建模,解決的是讓智能體學習“如果我做這個動作會發生什么?”的問題
有趣的是論文又回到了最原始的Next Token Prediction。使用當前狀態和行動作為上文(x),而環境的反饋作為(Y),讓模型通過預測環境的可能反饋,來內化對環境的理解(世界模型)。這種訓練的選擇擺脫了RL對于監督信號的依賴。同時考慮到前面生成的非專家軌跡的量級往往比專家軌跡大很多個數量級,因此論文這里選擇了兩階段訓練,先使用rollout進行大量訓練,再在專家軌跡上進行訓練。
但在真實世界中感覺還有一些需要解決的問題,一個是環境的動態性,例如不同時間搜索引擎的返回內容是不同的;以及環境的復雜性,能否充分描述當前環境和環境變化是非常復雜,例如你該如何描述金融市場的變化,只有價格變化顯然是不充分的。
以及上述的訓練目標限定在了單步,把Agent長程行為簡化成了單步的MDP,也就是基于當前狀態,給出行為,獲得的狀態轉移,并未把長程的行為決策對最終結果的影響考慮在內。
?? Self-Reflection:通過軌跡對比來獲取更多對行為決策的認知
自我反思,解決的是讓模型學習“為什么行動A比行動B效果更好的原因”
前面兩步已經奠定了論文的核心思路,和前面RStar和RAGEN等相同,論文也增加了軌跡對比
,從專家軌跡和隨機采樣的軌跡對比中來獲取更多對應行為結果的反饋。
論文通過以下的Prompt來從軌跡對比中不做專家經驗好在哪里?錯誤的行為有哪些局限和低效的地方

不過和之前memory論文不同的是,這部分Reflection沒有作為Note來在推理時使用,而是也使用NTP進行模型參數訓練,來訓練模型對于行為決策的理解。
以下是步驟2和3分別構建的環境反饋訓練樣本和軌跡對比訓練樣本。

?? 關鍵洞察:
- 經驗即信號:即使沒有獎勵,環境狀態的變化本身就是一種強大的監督信號。
- Scaling Law依然有效:這種基于經驗的后訓練方式,效果會隨著模型規模增大而顯著提升。
- RL的“完美預備役”:經過Early Experience訓練的模型,再進行RL微調,其效果遠超直接SFT后RL的方案。它相當于讓模型在“上學”前,先擁有了豐富的“生活常識”。
優勢函數(GAE)小課堂
1. 為什么需要優勢函數
在強化學習中,我們的目標是讓模型學會選擇累計回報更高的行為,那最樸素的方案就是使用軌跡累計回報作為權重,來更新每一步的梯度。
但直接使用整體軌跡獎勵的問題有兩個
- 方差大:在于不同軌跡帶來的獎勵會存在顯著差異導致方差過大
- 非等權:每一個行為對于最終獎勵帶來的貢獻是不一樣的
那解決方案就是引入基線,并且是根據每一步狀態計算的基線,用整體軌跡獎勵減去基線獎勵作為當前步驟的獎勵,這就是所謂的優勢函數概念啦
2. 優勢函數定義
優勢函數 ( A(s_t, a_t) ) 被定義為:
- $ Q(s_t, a_t) $:動作價值函數,表示在狀態 $ s_t $下執行動作 ( a_t ) 后,能獲得的期望累積回報,也就是前面提到當前狀態和行為下整體軌跡的期望價值。
- $ V(s_t) $:狀態價值函數,表示在狀態 $ s_t $ 下,遵循當前策略能獲得的平均期望累積回報,也就前面提到的基線。
因此,優勢函數衡量的是:在狀態 $ s_t $ 下,采取某個特定動作 $a_t $ 比遵循當前策略的“平均”動作要好多少。
- 如果 $ A(s_t, a_t) > 0 $:說明這個動作比平均動作好,應該增加其概率。
- 如果$ A(s_t, a_t) < 0 $:說明這個動作比平均動作差,應該減少其概率。
但是真實情況下Q和V都是未知的,因此我們需要對A進行估計,這里就引出了不同的估計方案。
3. 優勢函數估計
- 蒙特卡洛估計:高方差,低偏差(用無數次的模擬事實說話)
從t時刻的狀態開始,隨機試驗N次,用軌跡結束的實際累計回報作為Q和V的估計。因為使用多條軌跡所以估計相對無偏,但隨著軌跡越長往往方差越大,因為后續步驟帶來的隨機性越高。
- 時序差分估計: 低方差,高偏差(持續預測與修正)
相對的TD只看立即獎勵和下一個狀態的折現價值,因為不考慮后續步驟因此方差較低,但是依賴于價值函數V估計的準確性,如果V估計偏差較大則TD估計的偏差會很大。
4. GAE-均衡方差與偏差
GAE 的核心思想是:將以上兩種估計器結合起來,通過一個參數 $\lambda $ 作為偏差-方差的權衡。
GAE 的定義如下:
讓我們來解析下這個公式,其中 $ \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) $ 就是前面的TD 誤差。只不過不止包含下一步,還包含未來的每一步的TD誤差衰減后的加權平均。兩個超參數
- \(\lambda\):控制方差和偏差,為0則退化成時序差分,為1則桂花味蒙特卡洛估計
- \(\gamma\):未來獎勵的折現因子,決定了未來獎勵對當前狀態的重要性影響

 浙公網安備 33010602011771號
浙公網安備 33010602011771號