
解密prompt系列59. MCP實戰:從Low-Level到FastMCP的搭建演進
 ?? 核心挑戰:如何為復雜數據分析任務構建可擴展的代碼沙箱工具?本文將以E2B沙箱為例,通過對比Low-Level與FastMCP兩種MCP-Server實現方案,深入剖析:
- Resource/Tool/Prompt的高階應用場景
- 數據分析coding任務的難點和解決方案
- FastMCP在原有mcp-server的基礎上做了哪些開發簡化
?? 核心挑戰:如何為復雜數據分析任務構建可擴展的代碼沙箱工具?本文將以E2B沙箱為例,通過對比Low-Level與FastMCP兩種MCP-Server實現方案,深入剖析:
- Resource/Tool/Prompt的高階應用場景
- 數據分析coding任務的難點和解決方案
- FastMCP在原有mcp-server的基礎上做了哪些開發簡化
?? 核心挑戰:如何為復雜數據分析任務構建可擴展的代碼沙箱工具?本文將以E2B沙箱為例,通過對比Low-Level與FastMCP兩種MCP-Server實現方案,深入剖析:
- Resource/Tool/Prompt的高階應用場景
- 數據分析coding任務的難點和解決方案
- FastMCP在原有mcp-server的基礎上做了哪些開發簡化
Cluade的經典Demo多是用low level構建,而在最新版本中推出了高級FastMCP,但是工程上的簡化,意味著很多功能被隱藏,所以更適合從low level一步步走過來對MCP設計每一步都很清晰得高級使用用戶,而非新手小白。
這里我選了基于E2B的coding沙箱來搭建MCP server,剛好為下一章我們手搓數據分析智能體做個鋪墊,完整代碼詳見: DAAgent
Coding MCP
?? 真實場景的復雜性:生產級數據分析智能體中的Coding工具遠非Python REPL可勝任,核心痛點在于三類數據流的信息傳遞:
| 數據流類型 | 挑戰場景 | 本方案解決思路 |
|---|---|---|
| code2code | 多段代碼塊變量傳遞 | 持久化存儲(CSV/JSON) |
| code2llm | 執行上下文(stdout/error) | 結構化日志捕獲 |
| code2human | 結果可視化 | Jupyter Notebook組裝 |
那基于以上3點考量,我們要設計的coding MCP server就需要具備以下功能
- sandbox initialize & stop:沙箱創建和銷毀
- upload file:數據分析場景往往依賴前置輸出的csv數據文件
- execude code:最后才是coding工具默認擁有的代碼執行工具
?? 和其他的一些sandbox mcp相比在工具設計上有幾點不同
| 常見功能 | 本方案實現方式 | 選擇依據 |
|---|---|---|
| 庫安裝? | 利用kernle內核內嵌!pip | Coding一致性更好,很多library是在code運行過程中發現的,而非在coding之前制定 |
| 文件下載? | 捕捉所有多模態的執行結果直接返回 | 對輸出文件的目錄管理會更加靈活 |
| 單步代碼執行? | 顯式create/destroy沙箱支持多步coding | 復雜任務通過多步coding傳遞中間變量和持久化文件,同時避免多次pip的時間浪費 |
Low-Level Server
下面我們先用Low-level Server框架來設計Coding MCP。按前面的設計,我們分別需要initialize sandbox,stop sandbox,upload file,execute code這四個工具。
除了執行代碼之外的前三個工具,它們都可以使用文本輸出格式,他們傳遞給模型的信息相對簡單就是是否成功創建、銷毀沙箱、以及是否成功上傳文件,以及對應的沙箱ID標識和文件上傳目錄。所以這三個工具我選擇了文本格式的輸出。代碼執行工具這里,我選擇了結構化輸出,這樣可以更有效的拆分代碼執行后的各種不同日志類型,方面后面的coding步驟定位修復問題。
需要注意的是,構建MCP 工具時不僅要全面完整輸出成功日志,對于報錯也要有詳細的日志輸出,必要時需要返回traceback,否則模型無法獲取完整上下文很難修正工具調用方式。
以下是code 功能層核心代碼實現
# 工具函數定義
async def initialize_sandbox(timeout: int = Field(description='沙箱最大運行時長,單位為秒', default=1000)) -> str:
"""創建一個新的沙箱環境用于代碼執行
"""
global Active_Sandboxes
session_id = str(uuid.uuid4())
logger.info(f'創建沙箱中:session_id = {session_id}')
try:
sandbox = Sandbox(api_key=os.getenv("E2B_API_KEY"), timeout=timeout)
Active_Sandboxes[session_id] = sandbox
except Exception as e:
msg = f'Failed to initialize sandbox: {str(e)}'
logger.warning(e)
return msg
msg = f"Sandbox initialized successfully with session ID: {session_id}"
logger.info(msg)
return msg
async def close_sandbox(session_id: str = Field(description='需要關閉的沙箱id')) -> str:
"""所有代碼運行完畢之后,關閉已有的沙箱環境
:param session_id: 沙箱唯一標識符
:return: 執行日志
"""
global Active_Sandboxes
if session_id in Active_Sandboxes:
sandbox = Active_Sandboxes[session_id]
try:
sandbox.kill()
except Exception as e:
msg = f'Failed to close sandbox with session ID: {session_id}, {str(e)}'
logger.warning(e)
return msg
msg = f"Sandbox close successfully with session ID: {session_id}"
logger.info(msg)
return msg
else:
msg = f"Sandbox failed to stop session ID: {session_id} not found."
logger.warning(msg)
return msg
class CodeOutput(BaseModel):
stdout: str
stderr: str
error: str
traceback: str
async def execute_code(session_id: str = Field(description='需要運行代碼的目標沙箱id'),
code: str = Field(description='待運行的代碼')) -> CodeOutput:
"""在沙箱中運行代碼并獲取代碼的所有返回結果,包括stdout、stderr、各類持久化輸出、圖片等等
:param session_id: 沙箱唯一標識符
:param code: 待執行的代碼
:return: 代碼執行返回結構的結構體
"""
global Active_Sandboxes, Execution_DB
if session_id not in Active_Sandboxes:
msg = f'Sandbox with session ID : {session_id} not found'
data = {'error': msg}
else:
try:
sandbox = Active_Sandboxes[session_id]
# sandbox會在server內提供流式的內容輸出
execution = sandbox.run_code(
code,
on_stdout=lambda data: logger.info(data),
on_stderr=lambda data: logger.info(data),
on_error=lambda data: logger.info(data)
)
data = CodeOutput(
stdout=''.join(execution.logs.stdout),
stderr=''.join(execution.logs.stderr),
error=str(execution.error) if execution.error else '',
traceback=execution.error.traceback if execution.error else '',
)
# Store execution record in database
execution_record = {
'timestamp': datetime.now().isoformat(),
'code': code,
'output': execution # 存儲沙箱原始結果即可
}
Execution_DB[session_id]['executions'].append(execution_record)
logger.info(f"Stored execution record for session {session_id}")
except Exception as e:
error_msg = f"Code execution failed: {str(e)}"
traceback_str = traceback.format_exc()
logger.warning(f"Execution error: {error_msg}\n{traceback_str}")
data = CodeOutput(
error=error_msg,
traceback=traceback_str,
stdout='',
stderr=''
)
execution_record = {
'timestamp': datetime.now().isoformat(),
'code': code,
'output': None
}
Execution_DB[session_id]['executions'].append(execution_record)
logger.info(f"Stored error execution record for session {session_id}")
return data
async def upload_file(session_id: str = Field(description='待上傳文件的目標沙箱id'),
file_list: List = Field(description='上傳文件列表,每個都是本地文件的絕對路徑')
) -> str:
"""上傳本地文件到當前正在執行的沙箱中
:param session_id: 沙箱唯一標識ID
:param file_list: 待上傳的本地文件列表,文件名稱包含本地文件路徑
:return: 執行日志
"""
global Active_Sandboxes
if session_id not in Active_Sandboxes:
msg = f'Sandbox with session ID : {session_id} not found'
logger.warning(msg)
return msg
else:
sandbox = Active_Sandboxes[session_id]
return_msg = ''
for file in file_list:
try:
with open(file, 'rb') as f:
sandbox.files.write(file, f.read())
msg = f'Uploading {file} success'
logger.info(msg)
except Exception as e:
msg = f'Uploading {file} failed:' + str(e)
logger.warning(msg)
return_msg += msg + '\n'
return return_msg
下面是low level Server核心list_tool和call_tool的實現,需要用戶顯式定義每一個工具的schema和具體的調用方法, 以下我已經參考后面的FastMCP的高級封裝在定義時做了一些簡化。每個工具的名稱和描述,直接來自函數名稱和注釋,不用再手工填寫。
@server.list_tools()
async def list_tools() -> list[Tool]:
tools = [
Tool(name=initialize_sandbox.__name__,
description=initialize_sandbox.__doc__,
inputSchema={
"type": "object",
"properties": {
"timeout": {
"type": "integer",
"description": "沙箱最大運行時長,單位為秒"
}
},
"required": ["timeout"],
}),
Tool(name=close_sandbox.__name__,
description=close_sandbox.__doc__,
inputSchema={
"type": "object",
"properties": {
"session_id": {
"type": "string",
"description": "需要關閉的沙箱id"
}
},
"required": ["session_id"],
}),
Tool(name=execute_code.__name__,
description=execute_code.__doc__,
inputSchema={
"type": "object",
"properties": {
"session_id": {
"type": "string",
"description": "待運行代碼的沙箱id"
},
"code": {
"type": "string",
"description": '待運行的代碼'
}
},
"required": ["session_id", "code"],
},
outputSchema=CodeOutput.model_json_schema()),
Tool(name=upload_file.__name__,
description=upload_file.__doc__,
inputSchema={
"type": "object",
"properties": {
"session_id": {
"type": "string",
"description": "待上傳文件的目標沙箱id"
},
"file_list": {
"type": "array",
"description": "上傳文件列表,每個都是本地文件的絕對路徑"
}
},
"required": ["session_id", "file_list"]
})
]
return tools
@server.call_tool()
async def call_tool(name: str, arguments: dict[str, Any]):
"""
call tool返回結構并不局限在Text, Audio 和 Image類型, 如果你定義復雜結構體,返回Any類型即可
"""
try:
match name:
case initialize_sandbox.__name__:
result = await initialize_sandbox(arguments['timeout'])
result = [TextContent(type="text", text=result)]
case close_sandbox.__name__:
result = await close_sandbox(arguments['session_id'])
result = [TextContent(type="text", text=result)]
case upload_file.__name__:
result = await upload_file(arguments['session_id'], arguments['file_list'])
result = [TextContent(type="text", text=result)]
case execute_code.__name__:
result = await execute_code(arguments['session_id'], arguments['code'])
result = result.dict()
case _:
raise ValueError('Error calling tool: input name do not match any tool name')
return result
except Exception as e:
raise ValueError(f'Error calling tool: {str(e)}')
async def main():
options = server.create_initialization_options()
async with stdio_server() as (read_stream, write_stream):
await server.run(read_stream, write_stream, options)
if __name__ == '__main__':
import asyncio
asyncio.run(main())
唯一在開發時讓我有些困惑的在于call_tool的返回類型,因為需要兼容結構化輸出和純文本輸出這兩種類型,細看server的Type Hint會發現call_tool的輸出類型是Sequence[ContentBlock] | dict[str, Any], 也就是結構化和非結構化(純文本)的輸出類型分別是List和Dict兩種類型,會被解析到兩個不同的字段content和structuredContent。
本質上是否以文本格式返回的爭議點在于工具返回內容的使用方是工具?模型?人類?,純文本默認了工具的使用方是模型,但其實很多場景下并不是,例如多步工具調用傳遞參數、工具作為程序控制器、編程場景、數據分析場景等等。于是官方代碼后面才把StructuredContent加上,git上有不少討論,感興趣的可以去瞅瞅Bring back the concept of "toolResult" (non-chat result)
High-Level FastMCP
有了Low-Level API的基礎FastMCP就好理解多了。以下是效果相同,基于FastMCP這個High Level API的MCP工具實現,code功能部分和以上相同就不重復了。
from mcp.server.fastmcp import FastMCP
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger("e2b-sandbox")
# 服務初始化
mcp = FastMCP("code-sandbox")
Active_Sandboxes = {}
load_dotenv() # 讀取env文件中的E2B API Key
@mcp.tool()
async def initialize_sandbox(timeout: int = Field(description='沙箱最大運行市場,單位為秒', default=1000)) -> str:
"""創建一個新的沙箱環境用于代碼執行
:return: str: 返回初始化日志包含啟動沙箱id
"""
...
return msg
@mcp.tool()
async def close_sandbox(session_id: str = Field(description='需要關閉的沙箱id')) -> str:
"""所有代碼運行完畢之后,關閉已有的沙箱環境
:return: 執行日志
"""
...
return msg
class CodeOutput(TypedDict):
results: List
stdout: str
stderr: str
error: str
traceback: str
@mcp.tool()
async def execute_code(session_id: str = Field(description='需要運行代碼的沙箱id'),
code: str = Field(description='待運行的代碼')) -> CodeOutput:
"""在沙箱中運行代碼并獲取代碼的所有返回結果
:return: 代碼執行返回結構體包含stdout,stderr,error
"""
...
return data
@mcp.tool()
async def upload_file(session_id: str = Field(description='上傳到目標沙箱的唯一標識符'),
file_list: List = Field(description='上傳文件列表,每個都是本地文件的絕對路徑')
) -> str:
"""上傳本地文件到當前正在執行的沙箱中
:return: 執行日志
"""
...
return return_msg
if __name__ == '__main__':
mcp.run(transport='stdio')
從中我們可以發現FastMCP在服務開發上做了以下幾點簡化
- 服務器創建和啟動的簡化:FastMCP可以像flask、FastAPI一樣直接mcp.run啟動
- 工具(資源、prompt)定義和調用的簡化:無需顯式構建list_tool和call_tool API,使用mcp.tool裝飾器直接注冊工具,背后的tool Manager會自動完成以上工具說明和工具調用方法的構建,resource和prompt也是同理。
- 上下文和日志的簡化:看實現FastMCP抽象了Context對象來簡化日志和進度管理,但這塊我還沒具體用過就不做展開。
?? 簡單說下FastMCP的架構核心:

- FastMCP引入了3個核心管理器Tool、Resource、Prompt Manger:每個manager內部都各自實現了注冊(add_tool)、獲取(list_tool)、調用(call_tool)的功能,共同維護服務內所有的tool、resource和prompt
class FastMCP:
def __init__(self, ...):
self._tool_manager = ToolManager(...)
self._resource_manager = ResourceManager(...)
self._prompt_manager = PromptManager(...)
- FastMCP通過裝飾器和自動類型推斷簡化注冊:在裝飾器注冊工具后,通過typing和pydantic BaseModeln能自動完成工具輸入參數和輸出類型的解析直接生成list_tool的schema。并且對比low-level,FastMCP基于pydantic提供了更多參數驗證的功能。
def tool(self, name=None, title=None, description=None):
def decorator(fn):
# 自動分析函數簽名
func_metadata = func_metadata(fn)
# 自動生成參數schema
parameters = func_metadata.arg_model.model_json_schema()
# 注冊到工具管理器
self._tool_manager.add_tool(fn, name, title, description)
return fn
return decorator
考慮到FastMCP開發的便捷性,后面再進一步的MCP開發我們都會基于FastMCP開發,不再演示low-level server的實現(哈哈哈用low-level的耐心已耗盡)。
MCP用法腦暴
Prompt有啥用?
和工具不同,Prompt是用戶手動選擇,而非模型選擇的。 本質上只是Server提供者給到的一些工具指令的最佳實踐而已,mcp的使用者可以選擇用或者不用。
不過一個有意思的使用方式,是在團隊內部可以整一個prompt-mcp-server來把大家在平時開發中親測好用的一些prompt累積起來,避免各自為戰和重復勞動,哈哈準備搞起來~
Resource vs Tool
Tool和Prompt的用法相對常見,但是Resource的存在一度讓我很難理解,我看到了包括以下的幾種解釋
- Get vs Post:Tool和Resource的區別就是Get和Post的區別,工具可以執行任務而Resource只能獲取信息。誰說Tool不能用Get方法了?
- 和文件或數據庫對接返回數據:Resource專用于和文件和數據庫對接,用于返回模型需要的數據。Tool不是一樣也能對接數據庫和系統文件?
以上的說法并沒說服我,看了看多server也只發現Resource和tool之前還有以下幾點不同
- 訂閱和推送:Resource可以實現訂閱推送機制,從模型主動獲取數據變更,到檢測數據變更并推送給模型,但是這依賴客戶端是否有類似的設計,需要客戶端訂閱resource變更
- 多模態數據類型:還是前面的思路tool的返回結果默認是傳遞給模型的,因此以文本作為主要格式,后面才加入了structureOutput,而resource則支持數據流、二進制等更多數據類型
個人感覺resource的使用特性還在摸索階段,我還沒太想明白哈哈哈,要是大家有好的思路以歡迎評論區留言~
在server里面我設計了一個jupyter resource,用于當整個任務完成后,把所有code和code執行結果打包成jupyter notebook回傳給客戶端,進行展示。這里我選擇把jupyter notebook按照nb4的格式返回json字符串的思路,當然返回二進制流也是可以的。
server部分的代碼如下,在生產場景一般這里會使用OSS等遠程存儲,直接把ipynb上傳到云,在客戶端再直接使用返回的鏈接去云上下載文件即可,這里咱都在本地就簡化成回傳文件信息了~
@mcp.resource("file://notebook/{session_id}.ipynb",
mime_type='application/json')
async def get_execution_history(session_id: str) -> str:
"""獲取指定session的所有代碼和代碼執行歷史記錄,以Jupyter Meta Data形式返回
"""
global Execution_DB
cell_list = []
code_counter = 0
logger.info('get jupyter history')
if session_id in Execution_DB:
session_data = Execution_DB[session_id]
executions = session_data.get('executions', [])
for execution_record in executions:
cell_list.append({
"cell_type": "code",
"execution_count": code_counter,
"metadata": {},
"source": execution_record['code'],
"outputs": parse_nb(execution_record["output"])
})
code_counter += 1
notebook = update_notebook_data(cell_list)
logger.info(f"Generated notebook for session {session_id}")
# 返回notebook的JSON內容作為bytes,這樣客戶端會接收到真正的ipynb文件內容
return json.dumps(notebook,ensure_ascii=False)
else:
raise ValueError(f'Sandbox with session ID : {session_id} not found')
MCP Client
說完服務端,咱最后來看下客戶端,需要注意的是low-level mcp和high-level FastMCP接口也存在細微差異,簡單說fastmcp返回值嵌套減少了一層,考慮后面都會以FastMCP為主,這里只展示FastMCP對應client的相關代碼和結果
from fastmcp import Client
from fastmcp.client.transports import StdioTransport
# 使用Transport的原因為為了制定server.py腳本的路徑
transport = StdioTransport(
command="python",
args=["-m", "src.servers.e2b_high_level.server"],
env={"LOG_LEVEL": "DEBUG"}
)
session = Client(transport)
async with session:
# List available prompts
prompts = await session.list_prompts()
print(f"Available prompts: {[p.name for p in prompts]}")
# List available resources:靜態resource
resources = await session.list_resources()
print(f"Available resources: {[r.uri for r in resources]}")
# List available resource templates:動態resource
templates = await session.list_resource_templates()
print(f"Available templates: {[r.uriTemplate for r in templates]}")
# List available tools
tools = await session.list_tools()
print(tools)
print(f"Available tools: {[t.name for t in tools]}")
# 初始化沙箱
result = await session.call_tool("initialize_sandbox", arguments={"timeout": 1000})
print(f"Tool result: {result.content[0].text}")
# 實際上session_id應該由模型基于上文,在下一步execute code的工具調用中推理得到
session_id = result.content[0].text.split(':')[1].strip()
# 上傳文件
current_dir = os.path.dirname(os.path.abspath(__file__))
result = await session.call_tool("upload_file",
arguments={"session_id": session_id,
"file_list": [os.path.join(current_dir, 'tests',
'fund_information.csv')]})
print(f"Tool result: {result.content[0].text}")
# 執行2步代碼: 對于結構化輸出,call_tool內部會根據tool的output schema,自動進行model validate解析
result = await session.call_tool("execute_code",
arguments={"session_id": session_id, "code": test_code1})
print(f"Execute Code: {result.structured_content}")
result = await session.call_tool("execute_code",
arguments={"session_id": session_id, "code": test_code2})
print(f"Execute Code: {result.structured_content}")
# 直接獲取notebook文件內容 - 使用application/octet-stream
notebook_resource = await session.read_resource(f'file://notebook/{session_id}.ipynb')
with open( f'notebook_{session_id}.ipynb', 'w',encoding='UTF-8') as f:
f.write(notebook_resource[0].text)
# 關閉沙箱
result = await session.call_tool("close_sandbox", arguments={"session_id": session_id})
print(f"Tool result: {result.content[0].text}")
結果如下
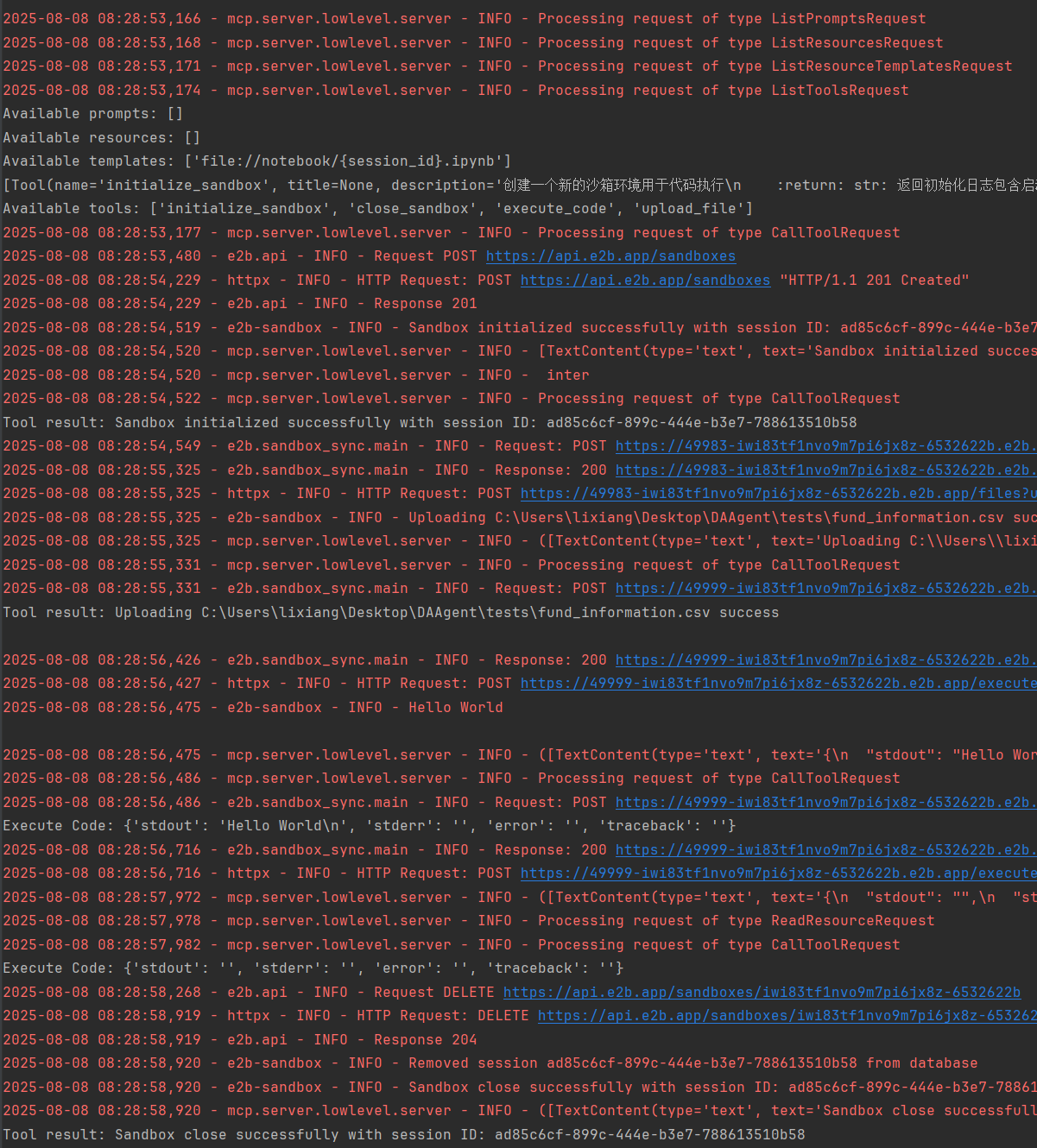
使用資源獲取的notebook文件如下

學習資源列表
想看更全的大模型論文·Agent·開源框架·AIGC應用 >> DecryPrompt

 浙公網安備 33010602011771號
浙公網安備 33010602011771號