
解密prompt系列58. MCP - 工具演變 & MCP基礎
 作為`結構化推理`的堅定支持者,我一度對MCP感到困惑:Agent和工具調用的概念早已普及,為何還需要MCP這樣的額外設計呢?本文就來深入探討MCP,看看它究竟解決了什么問題。我們將分幾章解析MCP:本章理清基礎概念和邏輯,后面我們直接以一個Agent為例演示全MCP接入的實現方案。
作為`結構化推理`的堅定支持者,我一度對MCP感到困惑:Agent和工具調用的概念早已普及,為何還需要MCP這樣的額外設計呢?本文就來深入探討MCP,看看它究竟解決了什么問題。我們將分幾章解析MCP:本章理清基礎概念和邏輯,后面我們直接以一個Agent為例演示全MCP接入的實現方案。
作為結構化推理的堅定支持者,我一度對MCP感到困惑:Agent和工具調用的概念早已普及,為何還需要MCP這樣的額外設計呢?本文就來深入探討MCP,看看它究竟解決了什么問題。
我們將分幾章解析MCP:本章理清基礎概念和邏輯,后面我們直接以一個Agent為例演示全MCP接入的實現方案。
工具調用方式的演進
大模型調用工具的概念從ChatGPT亮相后就被提出,其表達形式經歷了三個階段演變:
1. 函數表達階段
早期的工具描述多采用簡單的函數形式,通常通過提示詞(Prompt)要求模型輸出包含工具名稱和參數的JSON對象。例如下面的System Prompt期望模型輸出JSON結構來調用天氣查詢工具:
system_prompt = """你是一個智能助手,可以幫助用戶查詢天氣。
如果你需要查詢天氣,請調用一個名為 'get_current_weather' 的工具。
這個工具需要一個 'location' (字符串,必填) 參數,表示要查詢天氣的城市。
請以 JSON 格式輸出工具調用,例如:
{"tool_name": "get_current_weather", "parameters": {"location": "上海"}}
"""
模型可能輸出
{
"tool_name": "get_current_weather",
"parameters": {
"location": "北京"
}
}
這種方式存在明顯痛點:
- 缺乏統一標準:工具描述格式五花八門
- 推理脆弱:JSON缺乏強約束,易出現格式錯誤
- 解析繁瑣:需額外編寫解析代碼
2. 標準化工具定義
2023年6月,OpenAI推出的Function Calling功能是一個重要轉折點。它引入JSON Schema標準化工具描述,明確定義:
- 工具名稱(name)
- 功能描述(description)
- 參數列表(parameters),包含類型、描述、是否必填等
{
"name": "get_current_weather",
"description": "獲取指定地點的當前天氣信息",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名稱,例如:舊金山、上海"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "溫度單位,攝氏度或華氏度"
}
},
"required": ["location"]
}
}
3. 引入結構化推理
雖然OpenAI,Anthropic等閉源模型先后推出了Function Calling的接口能力,但是眾多開源模型仍無法使用類似的能力,并且手工編寫工具的JSON Schema也較為復雜。
而轉折點則是24年結構化推理的普及,基于掩碼的結構化推理能力(不熟悉的朋友看這里LLM結構化輸出)不僅顯著提升了模型生成工具JSON Schema的準確性,同時還讓Pydantic這個數據驗證和解析庫進入了大家的視野中。
像Langchain、LlamaIndex、DSPY等開源框架都開始引入Pydantic來自動生成工具的JSON Schema。這樣不僅解析部分能自動化標準化,生成工具描述的部分同樣也被標準化。還是上面的查天氣,可以使用Pydantic來標準化入參
from langchain_core.tools import tool
class WeatherInput(BaseModel):
location: str = Field(description="需要查詢天氣的城市名稱")
unit: str = Field(description="溫度單位,可以是 'celsius' 或 'fahrenheit'", default="celsius")
@tool("get_current_weather", args_schema=WeatherInput, return_direct=True)
def get_current_weather(location: str, unit: str):
"獲取指定地點的當前天氣信息"
return ''
MCP基礎概念
既然前三階段解決了工具描述標準化、推理準確性和解析自動化,為什么還需要MCP?
后來我思考良久才意識到MCP解決的不是Agent算法問題,而是工程問題,可以類比設計模式中的Adapter接口轉換思想,MCP推出的是工具的標準化協議。與其說是搭建新的MCP工具服務,不如說是把已有的服務通過MCP的鏈接中樞轉接成統一協議的AI工具服務。
理解MCP:從完整工具調用流程說起
要理解MCP的作用,需先看LLM調用工具的完整流程:
- 構建上下文:Agent獲取可用工具列表及其描述(JSON Schema/Prompt)
- 模型推理:LLM結合用戶Query和工具上下文生成工具調用指令
- 執行調用:Client解析指令并調用對應服務(本地函數/進程/遠程API)獲取
- 處理結果:Client獲取工具結果并反饋給LLM進行后續處理
工具發展的前三個階段主要解決步驟2的準確性和接口標準化,而步驟1(獲取工具列表)和步驟3(調用異構服務),步驟4(處理服務結果) 的工程化集成缺乏統一方案,這也是MCP的價值所在
MCP的核心價值:統一協議,降低復雜度
在沒有MCP時,每個Agent需為每個工具服務定制開發連接邏輯,這里包括接口定義,錯誤處理,鑒權等等。**當存在M個Agent和N個工具服務時,復雜度是O(M×N)(接近平方級)。
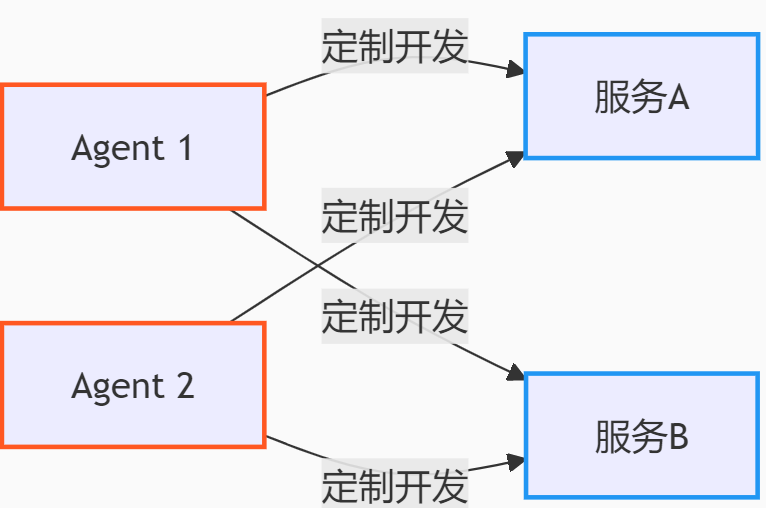
而引入MCP后,MCP通過標準協議解決這個問題把復雜度降低到M+N

- Client側:Agent只需集成通用MCP客戶端,將請求編碼為標準MCP消息(JSON-RPC 2.0格式)
- Server側:每個工具服務部署MCP服務端適配器,轉換請求并返回標準化響應
MCP除核心連接簡化外,還提供:
- 動態上下文構建:工具列表通過標準list_tools方法動態獲取,無需在Agent內部硬編碼工具描述
- 協議標準化:明確定義工具發現、調用、返回結構、錯誤處理等標準操作,無需每個Agent獨立處理
- 傳輸無關性:支持HTTP、Stdio等多種傳輸層,統一了Agent進程內本地工具和遠程API調用
MCP協議
說到這里MCP相關的核心架構已經比較清晰了,就是按照JSON-RPC 2.0標準協議通信(使用JSON作為消息格式)的Server-Client服務架構,其中client和Server各自提供以下核心能力
- Client:在智能體啟動時會初始化客戶端,每個對應的MCP Server都初始化一個對應的客戶端
- 初始化:根據Server類型(Stdio/HTTP)建立連接
- 發現工具:通過統一的
list_tools獲取可用工具及描述 - 調用工具:將模型輸出封裝為統一的工具標準請求call_tool請求服務端,同時服務端也會返回標準化的工具調用結果
- Server:每個(一組)工具都設計啟動一個對應的服務端
- 提供工具描述:實現
list_tools返回工具定義 - 執行工具調用:通過
call_tool轉換并執行實際工具 - 傳輸層適配:
Stdio:用于本機進程間通信Http:用于跨網絡調用
- 提供交互提示:可選提供推薦Prompt模板(工具說明/結果解釋)
對于MCP中的高級概念如Resource、Roots、Sampling、Elicitation,僅靠定義難以理解。在接下來的章節中,我們將通過具體案例探討這些概念。
當然其實還有一層概念也就是在client的外層,也就是智能體層或應用層,例如cursor, windsurf, claude desktop等等,在MCP中稱之為Host層,這一層也更多是和Resource訂閱、Prompt使用這些高級概念相關,我們放在后面的章節再說了。
想看更全的大模型論文·微調預訓練數據·開源框架·AIGC應用 >> DecryPrompt

 浙公網安備 33010602011771號
浙公網安備 33010602011771號