
ES查詢優(yōu)化隨記1: 多路向量查詢 & KNN IO排查 & 高效Filter使用
 本章主要覆蓋以下
多Query向量查詢的各種方案:Script,Knn(mesearch)
KNN查詢IOUtil過(guò)高問(wèn)題排查
如何使用Filter查詢更高效
本章主要覆蓋以下
多Query向量查詢的各種方案:Script,Knn(mesearch)
KNN查詢IOUtil過(guò)高問(wèn)題排查
如何使用Filter查詢更高效
哈哈最近感覺自己不像算法倒像是DB,整天圍著ES打轉(zhuǎn),今天查IO,明天查內(nèi)存,一會(huì)優(yōu)化查詢,一會(huì)優(yōu)化吞吐。畢竟RAG離不開知識(shí)庫(kù),我們的選型是ES,于是這一年都是和ES的各種糾葛。所以順手把近期獲得的一些小tips記下來(lái),萬(wàn)一有人和我踩進(jìn)了一樣的坑,也能早日爬出來(lái)。當(dāng)前使用的ES版本是8.13,和7版本有較大的差異,用7.X的朋友這一章可能有不適配。本章主要覆蓋以下
?
- 多Query向量查詢的各種方案:Script,Knn(mesearch)
- KNN查詢IOUtil過(guò)高問(wèn)題排查
- 如何使用Filter查詢更高效
多Query向量查詢的各種方法
大模型的知識(shí)庫(kù)都離不開向量查詢,并且當(dāng)前的RAG往往會(huì)對(duì)用戶query進(jìn)行多角度的改寫和發(fā)散,因此會(huì)涉及多query同時(shí)進(jìn)行向量查詢。如果用ES實(shí)現(xiàn)的話,常用的有以下幾種形式
- 多向量Pooling Script查詢:多個(gè)query的向量平均后進(jìn)行查詢,查詢效果不好,因?yàn)镻ooling往往會(huì)損失很多信息,雖然把多個(gè)向量壓縮成了一個(gè)向量,查詢效率更高壓力更小,但是效果差的離譜。但是對(duì)使用ES 7.X版本的朋友可能也是一種選擇。
query_body = {
"size":10
"query": {
"bool": {
"must": [{
"script_score": {
"query": {"match_all": {}},
"script": {
"source": f"cosineSimilarity(params.query_vector, 'vectors')",
"params": {"query_vector": avg_embedding}
}
}
}]
}
}
}
- 向量script循環(huán)取cosine的最大值或者平均值:使用ES 7且的朋友一般的選項(xiàng),因?yàn)?的版本里部分沒有KNN的支持,因此只能使用script線性遍歷向量。而不把所有向量召回的內(nèi)容都取回來(lái)進(jìn)行重排序主要是IO的考慮,返回的條數(shù)更少傳輸壓力更小。以下為python的查詢示例,embedding_list是多query的向量數(shù)組。
query_body = {
"query": {
"function_score": {
"script_score": {
"script": {
"source": """
double max_score = -1.0;
if (doc[params.field].size() == 0) return 0; // 空值保護(hù)
for (int i=0; i<params.length; i++) {
double similarity = cosineSimilarity(
params.query_vectors[i],
params.field
);
max_score = Math.max(max_score, similarity);
}
return max_score;
""",
"params": {
"length": len(embedding_list),
"query_vectors": embedding_list,
"field": "vectors"
}
}
},
"boost_mode": "replace"
}
}
}
response = es.search(index=index, body=query_body)
- 多向量KNN查詢:用ES8版本的一般會(huì)考慮KNN查詢,每個(gè)向量單查KNN,對(duì)同一個(gè)index的多條KNN查詢推薦使用msearch組合查詢并返回。
query_body = {
"query": {
"bool": {
"must": [{
"knn": {
"field": 'vectors',
"query_vector": embedding_item,
"num_candidates": 10
}
}]
}
}
}
KNN查詢IO打滿的問(wèn)題排查
在使用以上KNN搜索時(shí),我們遇到一個(gè)問(wèn)題,就是一使用KNN查詢,IOUitl指標(biāo)就會(huì)打滿,進(jìn)而影響其他所有查詢?nèi)蝿?wù),導(dǎo)致線上查詢會(huì)Hang住,如下圖所示。
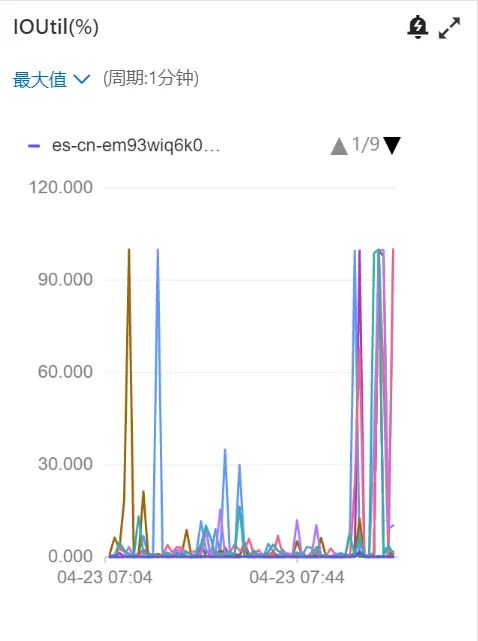
經(jīng)過(guò)阿里ES大佬的幫助,我們定位了問(wèn)題,核心是HNSW圖向量沒有加載到內(nèi)存里,因此在查詢時(shí)觸發(fā)了向量加載,因此大量的IO都是在進(jìn)行向量搬運(yùn)操作,搬多久IO就打滿多久,解決的方案主要分2步
第一步優(yōu)化圖大小,原始我們的圖使用Float32存儲(chǔ)的,ES8.15提供了int4,int8存儲(chǔ),8.17好像還提供壓縮比例更高的存儲(chǔ)方式,因此我們r(jià)eindex了索引修改成了INT8存儲(chǔ)。但是發(fā)現(xiàn)優(yōu)化后IO指標(biāo)并未下降。
于是就有了第二步預(yù)加載,大佬給出的解釋是HNSW算法存在大量的隨機(jī)讀,除了HNSW圖,還會(huì)讀取原始或量化后的向量數(shù)據(jù),這些數(shù)據(jù)也需要加載到內(nèi)存中進(jìn)行查詢(從磁盤加載)。而解決這個(gè)問(wèn)題的辦法就是預(yù)加載。以int8_hnsw為例,預(yù)加載的方式如下,需要先關(guān)閉索引,完成預(yù)加載,再開啟索引。因此必須在非業(yè)務(wù)使用期進(jìn)行操作,百萬(wàn)級(jí)的索引大小大概幾分鐘就能完成以下操作,不過(guò)我們?cè)陬A(yù)加載時(shí)有時(shí)會(huì)引起集群的不穩(wěn)定,因此建議在業(yè)務(wù)低峰期操作。
# 關(guān)閉索引
POST your_index/_close
# 調(diào)整preload參數(shù)
PUT your_index/_settings
{
"index.store.preload": ["vex", "veq"]
}
# 開啟索引
POST your_index/_open
只不過(guò)以上預(yù)加載存在一個(gè)問(wèn)題,就是預(yù)加載的內(nèi)容會(huì)持續(xù)存在緩存中,也算是用空間換時(shí)間的方案,如果有太多索引需要做預(yù)加載,應(yīng)該會(huì)存在競(jìng)爭(zhēng)關(guān)系,不過(guò)在我們的配置下還未出現(xiàn)這個(gè)問(wèn)題,所以大家在預(yù)加載時(shí)需要關(guān)注下內(nèi)存等指標(biāo)變化
Filter的三種不同使用方式
依舊圍繞向量搜索,在使用向量時(shí)在我們的場(chǎng)景中一般會(huì)有時(shí)間Filter,根據(jù)不同的時(shí)效性分層和時(shí)效性抽取結(jié)果選取不同的查詢時(shí)間段,和整個(gè)index大小相比,時(shí)效性filter往往能大幅縮減查詢的索引范圍,但是使用filter的方式不同,對(duì)查詢效率有較大影響。
- pre filter:過(guò)濾條件在knn的filter語(yǔ)句中
{"knn": {
"field": "vectors",
"query_vector": [-0.0574951171875, 0.0222320556640625, ...],
"num_candidates": 3,
"filter": [{
"range": {
"publishDate": {
"lte": "2025-04-22",
"gte": "2023-04-22",
"format": "yyyy-MM-dd"
}
}
}
]
}
}
- post filter:過(guò)濾條件在bool的filter語(yǔ)句中
{
"bool": {
"must": [{
"knn": {
"field": "vectors",
"query_vector": [-0.0574951171875, 0.0222320556640625, ...],
"num_candidates": 3,
}
}],
"filter": [{
"range": {
"publishDate": {
"lte": "2025-04-22",
"gte": "2023-04-22",
"format": "yyyy-MM-dd"
}
}
}]
}
}
- 過(guò)濾條件在must語(yǔ)句中
{
"bool": {
"must": [{
"range": {
"publishDate": {
"lte": "2025-04-22",
"gte": "2023-04-22",
"format": "yyyy-MM-dd"
}
}
},
{
"knn": {
"field": "vectors",
"query_vector": [-0.0574951171875, 0.0222320556640625, ...],
"num_candidates": 3,
}
}]
}
}
以上三種查詢方式的對(duì)比如下
| Filter方式 | 查詢效率 |
|---|---|
| Pre Filter | 查詢效率最高,前置過(guò)濾會(huì)縮減knn查詢范圍提高查詢效率 |
| Post Filter | 查詢效率較低,在非KNN的其他查詢場(chǎng)景這是查詢效率最高的寫法。但在KNN場(chǎng)景中會(huì)比只用KNN更慢,因?yàn)槭窃贙NN搜索結(jié)果拿到后進(jìn)行后置過(guò)濾,同時(shí)會(huì)導(dǎo)致最終返回的數(shù)量可能少于查詢數(shù)量 |
| 過(guò)濾條件在must語(yǔ)句中 | 查詢效率最低,在filter語(yǔ)句中ES會(huì)直接忽略不滿足條件的文檔,而在must語(yǔ)句中所有文檔都會(huì)參與評(píng)分。并且Filter語(yǔ)句ES會(huì)緩存過(guò)濾條件使得后續(xù)查詢更快而must不會(huì)進(jìn)行緩存 |

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)