

.NET+AI: (微家的AI研發框架)什么是內核記憶(Kernel Memory)?
.NET+AI: (微家的AI開發框架)大家趕緊學習!!!
什么是內核記憶(Kernel Memory)
Kernel Memory,內核記憶(KM)是一種多模態人工智能服務,旨在為應用程序提供長期記憶解決方案,模仿人類存儲信息的記憶能力。專門通過自定義連續數據混合管道對數據集進行高效索引,并支持檢索增強生成(RAG)。
KM 可以作為一個Web服務獨立部署,也可以作為一個插件集成到ChatGPT/Copilot/Semantic Kernel 中,也可以作為一個.NET 庫集成到應用中。
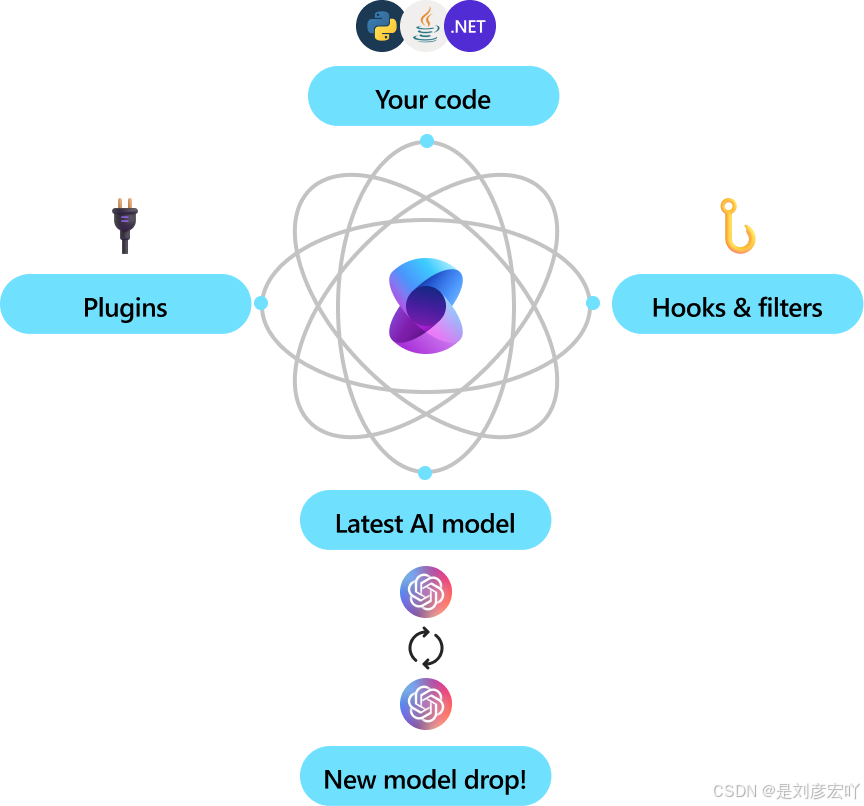
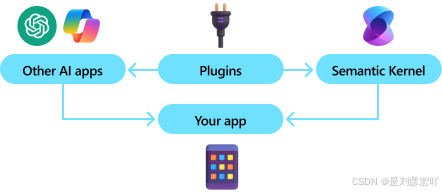
通過利用先進的嵌入和大型語言模型,KM 支持自然語言查詢,以便從索引數據中獲取答案,并返回帶有引用和指向原始來源的鏈接。
Kernal Memory vs Semantic Memory
內核記憶(KM)是一項基于開發語義內核(SK)和語義記憶(SM)過程中所收到的反饋和汲取的經驗教訓而構建的服務。它提供了一些原本需要手動開發的功能,例如存儲文件、從文件中提取文本、提供保護用戶數據的框架等。KM 的代碼庫完全使用.NET 編寫,這消除了用多種語言編寫和維護功能的需求。作為一項服務,KM 可以在任何語言、工具或平臺上使用,例如瀏覽器擴展和 ChatGPT 助手。
語義記憶(Semantic Memory,SM)是適用于 C#、Python 和 Java 的庫,它包裝了對數據庫的直接調用并支持向量搜索。它是作為語義內核(Semantic Kernel,SK)項目的一部分開發的,并且是長期記憶的首次公開迭代。核心庫以三種語言進行維護,而受支持的存儲引擎列表(稱為“連接器”)因語言而異。
| 特性 | Kernel Memory | Semantic Memory |
|---|---|---|
| 數據格式 | Web頁面、PDF、圖像、Word、PowerPoint、Excel、Markdown、文本、JSON、HTML | 僅文本 |
| 搜索 | 余弦相似度、帶過濾器的混合搜索(AND/OR條件) | 余弦相似度 |
| 語言支持 | 任何語言,命令行工具,瀏覽器擴展,低代碼/無代碼應用,聊天機器人,助手等 | C#、Python、Java |
| 存儲引擎 | Azure AI Search、Elasticsearch、MongoDB Atlas、Postgres+pgvector、Qdrant、Redis、SQL Server、內存KNN、磁盤KNN | Azure AI Search、Chroma、DuckDB、Kusto、Milvus、MongoDB、Pinecone、Postgres、Qdrant、Redis、SQLite、Weaviate |
| 文件存儲 | Disk、Azure Blob、AWS S3、MongoDB Atlas、內存(易失性) | - |
| RAG | 是 | - |
| 摘要 | 是 | - |
| OCR | 是,通過Azure Document Intelligence | - |
| 安全過濾器 | 是 | - |
| 大型文檔攝取 | 是,包括使用隊列的異步處理(Azure Queues、RabbitMQ、基于文件的或內存隊列) | - |
| 文檔存儲 | 是 | - |
| 自定義存儲架構 | 一些DBs | - |
| 帶內部嵌入的向量DBs | 是 | - |
| 同時寫入多個向量DBs | 是 | - |
| LLMs | Azure OpenAI、OpenAI、Anthropic、Ollama、LLamaSharp、LM Studio、Semantic Kernel Connectors | Azure OpenAI、OpenAI、Gemini、Hugging Face、ONNX、自定義等 |
| 帶專用分詞器的LLMs | 是 | 否 |
| 云部署 | 是 | - |
| 帶OpenAPI的Web服務 | 是 | - |
核心概念
Document
文檔,將信息(一個或多個文件,照片,或一段文本)上傳到KM時,這些數據被打包為一個文檔,并擁有唯一ID,通過這個ID 可以更新、替換或刪除該文檔的數據。以下示例中一次導入多個不同類型的文件,但它們被命名為doc001 Document。
var memory = new KernelMemoryBuilder()
.WithOpenAIDefaults(env["OPENAI_API_KEY"])
.Build();
await memory.ImportDocumentAsync(new Document("doc001")
.AddFiles(["file1.txt", "file2.docx", "file3.pdf"]); 如果再次以相同Document ID 導入新文檔,則之前導入的文檔會被覆蓋。
Tag
標簽,是一個鍵值對,通過給Document 打標簽,以便在搜索時,通過指定標簽限定搜索文檔范圍。以下示例中可以看出一個Document 可以有多個Tag,一個Tag 可以有多個值。
var memory = new KernelMemoryBuilder()
.WithOpenAIDefaults(env["OPENAI_API_KEY"])
.Build();
await memory.ImportDocumentAsync(new Document("doc001")
.AddFiles(["file1.txt", "file2.docx", "file3.pdf"])
.AddTag("user", "Taylor")
.AddTag("collection", "meetings")
.AddTag("collection", "NASA")
.AddTag("collection", "space")
.AddTag("type", "news")); Index
索引,KM 利用向量存儲來保存攝入的文檔信息,像 Azure AI Search、Qdrant、Elastic Search、Redis 等解決方案。
為了對不同的數據加以區分,通過指定不同的索引名稱來實現,索引之間的數據是隔離的。在存儲信息、搜索和提問時,KM始終在一個索引的范圍內工作。
換句話說,可以將多個Document 存儲在單個索引下。
var memory = new KernelMemoryBuilder()
.WithOpenAIDefaults(env["OPENAI_API_KEY"])
.Build();
await memory.ImportDocumentAsync(
document: new Document("doc001").AddFiles(["file1.txt", "file2.docx", "file3.pdf"]),
index:"index1");
await memory.ImportDocumentAsync(
document: new Document("doc002").AddFiles(["file4.txt", "file5.docx"]),
index:"index1"); 當未指定index時,將存儲在名為default的索引下。同理,AskAsync和SerachAsync在未指定index時,默認在default索引下進行檢索。
// 在index1索引下檢索
var result = await memory.AskAsync("What is Kernel Memory?", index: "index1");
// 在default索引下檢索
var result2 = await memory.SearchAsync("What is Kernel Memory?");Chunk
對讀取的文檔數據進行處理,將大塊數據分解為更小、更易于處理的單元的過程,稱為chunking,分解得到的單元稱為chunk。
通過分塊,可以將文本拆分為單詞、句子、段落還是整個文檔,分塊級別決定了檢索到的信息的顆粒度。
舉例而言:假設您在法律研究應用程序中使用RAG模型,并且您需要從大型法律文檔中檢索相關部分。用戶詢問,“法律對醫療保健中的數據隱私有什么規定?”。
如果系統采用文檔級分塊,它將檢索整個法律文檔,這可能是壓倒性和低效的。然而,通過使用段落級分塊,系統能檢索專門討論醫療保健數據隱私法的段落,給用戶一個高度相關和簡潔的答案。
如果沒有分塊,系統可能會檢索文檔中不相關的部分,從而提供糟糕的用戶體驗。通過分塊,檢索變得有針對性和有意義,增強了模型生成準確和上下文感知響應的能力。
核心技術與框架解析
Semantic Kernel:連接AI與業務邏輯的橋梁
Semantic Kernel是微軟推出的開源框架,它能無縫整合大語言模型(LLM)能力與傳統代碼邏輯,讓開發者可以通過自然語言提示詞和C#代碼結合的方式,快速構建AI驅動的應用。其核心優勢在于提供了插件系統(Plugins)、記憶系統(Memory)和規劃能力(Planning),這三者共同構成了實現RAG和MCP Agent的基礎。
RAG:讓應答更精準的知識檢索增強
RAG技術的核心是通過檢索外部知識庫,為LLM提供精準的上下文信息,從而讓生成的回答更符合業務事實。在銷售場景中,產品手冊、價格表、促銷政策等都是關鍵的知識庫內容。借助RAG,系統能在回答客戶關于“某款產品的折扣力度”“售后服務范圍”等問題時,不再依賴LLM的通用訓練數據,而是從企業內部知識庫中檢索最新、最準確的信息,避免出現過時或錯誤的回答。
MCP Agent:多能力協同的銷售智能體
MCP Agent(Multi-Capability Agent)指具備多種業務能力的智能代理,它能根據客戶問題自動調用不同的功能模塊(如產品查詢、價格計算、訂單狀態跟蹤等),實現端到端的智能應答。在Semantic Kernel中,MCP Agent可以通過規劃能力分析用戶意圖,然后調用對應的插件完成任務,例如當客戶詢問“購買100臺A產品能享受多少折扣”時,Agent會先調用產品信息插件獲取A產品的基礎價格,再調用折扣計算插件根據采購量算出具體折扣,最后整合結果生成自然語言回答。
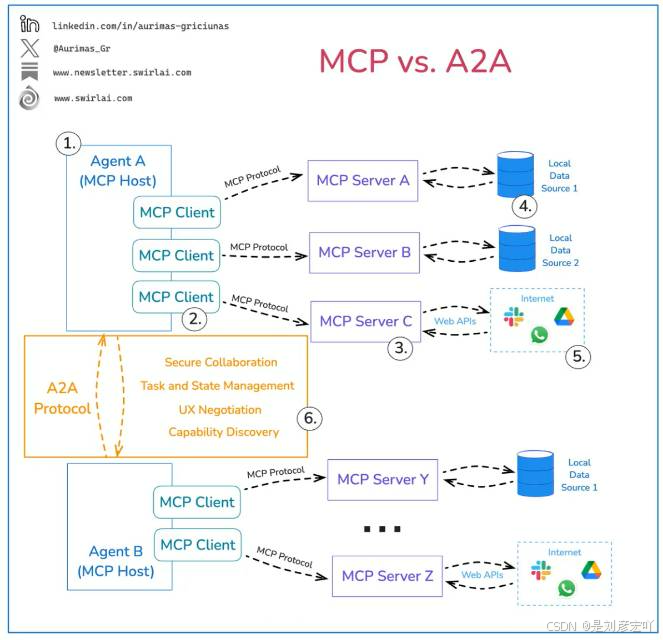

這張圖表列出了20個關于AI代理(Agent)的核心概念,每個概念都有簡短的描述和圖標。以下是這些概念的整理:
- Agent(代理):能夠感知、推理并采取行動以實現目標的自主實體。
- Environment(環境):代理操作和交互的周圍上下文。
- Perception(感知):代理解釋感官或環境數據的過程。
- State(狀態):代理對世界當前內部條件或表示。
- Memory(記憶):存儲最近或歷史信息以供連續性和學習使用。
- Large Language Models(大型語言模型):支持語言理解和生成的基礎模型。
- Reflex Agent(反射代理):基于預定義的“條件-行動”規則做出決策的代理。
- Knowledge Base(知識庫):代理用于做出決策的結構化或非結構化數據存儲庫。
- CoT (Chain of Thought)(思維鏈):代理為復雜任務表達中間步驟的推理方法。
- React(反應):結合逐步推理與環境行動的框架。
- Tools(工具):代理用來增強能力的API或外部系統。
- Action(行動):代理執行的任何任務或行為。
- Planning(規劃):制定一系列行動以實現特定目標。
- Orchestration(協調):協調多個步驟、工具或代理以完成任務流程。
- Handoffs(交接):不同代理之間任務或工作的轉移。
- Multi-Agent System(多代理系統):多個代理在同一環境中操作和協作的框架。
- Swarm(群體):許多代理遵循局部規則而無需中央控制的涌現智能行為。
- Agent Debate(代理辯論):代理爭論對立觀點以完善或改進最終響應的機制。
- Evaluation(評估):衡量代理行動有效性的過程。
- Learning Loop(學習循環):代理通過持續從反饋中學習來改進性能的循環。
這些概念涵蓋了AI代理的各個方面,從基本的定義和功能到更復雜的交互和學習過程。
系統架構與實現步驟
架構設計
銷售業務智能應答系統的架構主要分為三層:
- 數據層:存儲產品信息、價格政策、銷售案例等知識庫數據,可采用向量數據庫(如Qdrant、Milvus)存儲文本向量,以便高效檢索。
- 核心層:基于Semantic Kernel實現,包含RAG模塊(負責知識檢索)、MCP Agent模塊(負責意圖解析與能力調用)和LLM接口(對接GPT-4、Azure OpenAI等模型)。
- 應用層:提供API接口或前端交互界面,供銷售人員或客戶使用,支持文本輸入、語音輸入等多種交互方式。
具體實現步驟
環境準備與項目初始化
安裝Semantic Kernel相關NuGet包: Microsoft.SemanticKernel 、 Microsoft.SemanticKernel.Plugins.Memory 等。
配置LLM服務:通過API密鑰連接Azure OpenAI或其他LLM服務,在Semantic Kernel中初始化 Kernel 對象。
構建RAG模塊知識庫導入:將產品手冊、價格表等文檔解析為文本片段,使用Semantic Kernel的 TextChunker 進行分塊處理。
向量存儲:調用 Kernel.Memory.SaveInformationAsync 方法,將文本片段及其向量存儲到向量數據庫中。
檢索邏輯:當接收用戶問題時,通過 Kernel.Memory.SearchAsync 檢索與問題最相關的知識庫片段,作為上下文傳遞給LLM。
開發MCP Agent能力插件
- 產品查詢插件:實現 GetProductInfo(string productName) 方法,返回產品規格、價格等信息。
- 折扣計算插件:實現 CalculateDiscount(int quantity, string productId) 方法,根據采購量和產品ID計算折扣。
- 訂單查詢插件:實現 GetOrderStatus(string orderId) 方法,查詢訂單的當前狀態。
- 將插件注冊到Semantic Kernel: kernel.ImportPluginFromObject(new SalesPlugins(), “SalesPlugins”) 。
Agent規劃與應答生成
- 意圖解析:通過Semantic Kernel的 FunctionCalling 能力,讓LLM分析用戶問題,判斷是否需要調用插件或直接使用RAG檢索結果。
- 多步驟處理:對于復雜問題(如“對比A和B產品的價格,并計算購買50臺的總成本”),Agent會規劃調用順序(先調用產品查詢插件獲取A、B價格,再調用折扣計算插件分別計算成本,最后匯總)。
- 結果生成:將插件返回的數據或RAG檢索到的知識,通過LLM整理為自然、易懂的回答。
場景驗證與優勢體現
以一個實際銷售場景為例:客戶詢問“你們的旗艦款打印機現在有什么優惠?如果公司采購20臺,加上三年保修,總費用是多少?”
系統的處理流程如下:
接收問題后,MCP Agent通過意圖解析,確定需要調用“產品查詢”“折扣計算”和“保修價格”三個插件。
調用產品查詢插件獲取“旗艦款打印機”的基礎價格和產品ID。
調用折扣計算插件,根據采購量20臺和產品ID,計算出對應的折扣比例。
調用保修價格插件,獲取三年保修的單臺費用。
結合RAG檢索到的“當前針對企業采購的額外10%補貼”信息,匯總計算總費用。
最后通過LLM生成包含具體價格明細、優惠說明的回答,同時附上產品參數鏈接(來自知識庫)。
該系統的優勢在于:
- 準確性:依賴企業內部知識庫和業務插件,避免LLM幻覺,確保價格、政策等信息精準無誤。
- 高效性:MCP Agent自動完成多步驟處理,無需人工干預,縮短響應時間。
- 擴展性:新增產品或業務規則時,只需更新知識庫或開發新插件,無需重構整個系統。
總結與展望
基于Semantic Kernel構建的銷售業務智能應答系統,通過RAG解決了知識精準性問題,借助MCP Agent實現了復雜業務場景的自動化處理,為銷售團隊提供了強大的智能支持。在實際應用中,還可結合用戶畫像、歷史對話記錄等數據進一步優化應答效果,例如根據客戶過往采購記錄推薦合適的優惠方案。
隨著LLM技術和Semantic Kernel框架的不斷發展,這類智能應答系統將在銷售線索挖掘、客戶關系維護等領域發揮更大作用,推動銷售業務向更高效、更智能的方向轉型。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號