
Java中如何使用Jsoup進(jìn)行HTML頁(yè)面的簡(jiǎn)單爬蟲(chóng)(爬取圖片)
準(zhǔn)備工作:
1. 一個(gè)HTML頁(yè)面,這里以 https://www.qycn.com/xzx/article/3969.html 為例
2. 新建一個(gè)maven工程,引入jsoup依賴(lài)
<!-- jsoup HTML parser library @ https://jsoup.org/ -->
<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.13.1</version> </dependency>
頁(yè)面圖片如圖所示:
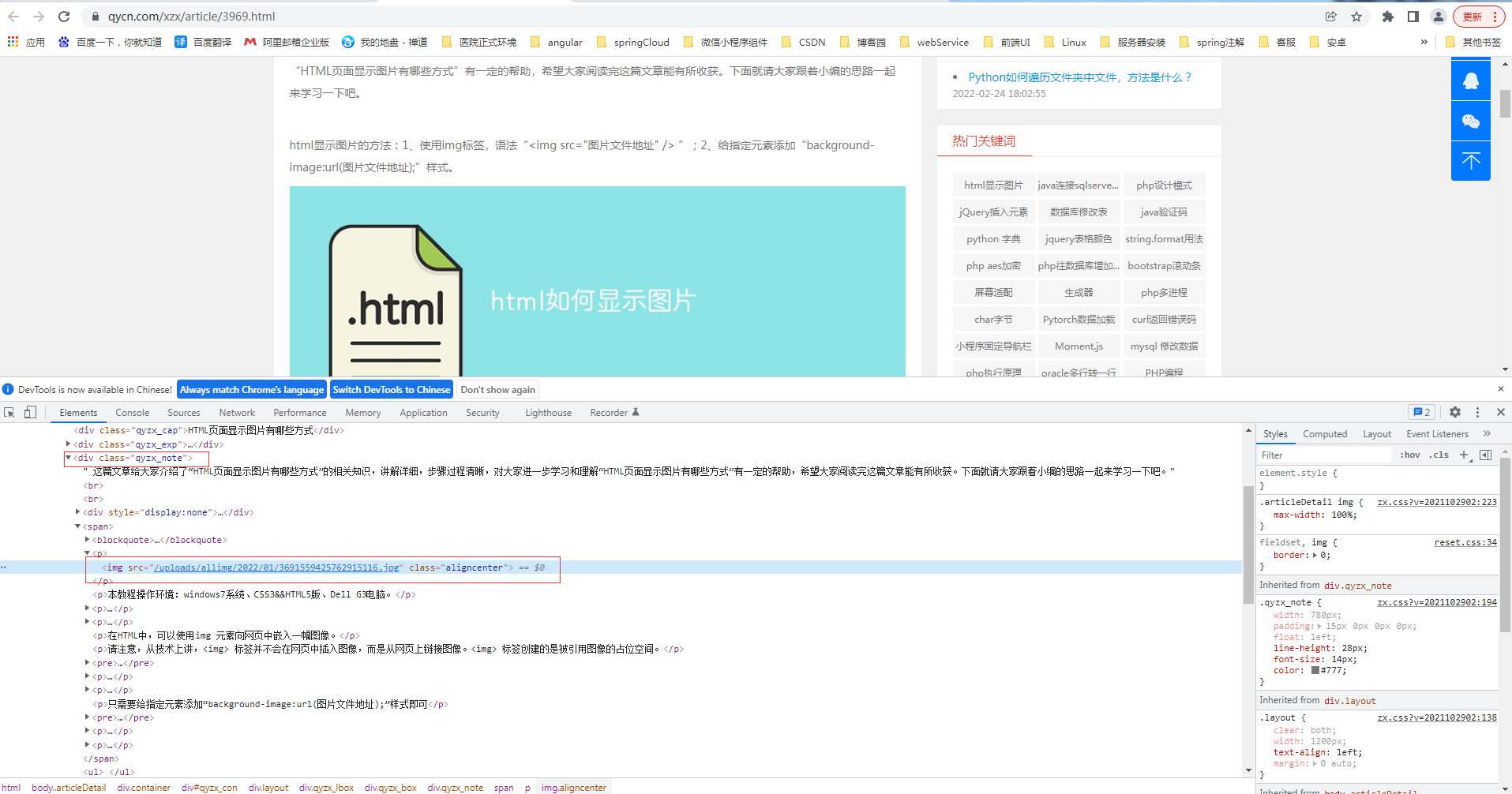
然后F12需要找到包裹圖片的外部DIV的Class屬性名稱(chēng),該名稱(chēng)用來(lái)幫助獲取圖片位置
準(zhǔn)備工作已就緒,本次功能未下載當(dāng)前HTML頁(yè)面上的所有圖片,完整代碼如下:
package com.jsoup.com.jsoup; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.net.HttpURLConnection; import java.net.URL; import java.util.ArrayList; import java.util.List; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.select.Elements; /** * * @ClassName: JsoupUtil * @Description: 圖片爬蟲(chóng) -- 使用jsoup解析html頁(yè)面,獲取需要的路徑,進(jìn)行循環(huán)下載 */ public class JsoupUtil { //定義路徑 static String baseurl = "https://www.qycn.com"; static String geturl = "https://www.qycn.com/xzx/article/3969.html"; static String filepath = "C:\\Users\\Justin\\Desktop\\linshi\\images\\"; public static void main(String[] args) { System.out.println("初始下載頁(yè)面:"+geturl); String html = getHtml(geturl); // html頁(yè)面內(nèi)容 List<String> srclists = getImgSrcListFromHtml(html); // 圖片地址集合 downloadImg(srclists, filepath); // 下載圖片 // 獲取下一個(gè)頁(yè)面進(jìn)行下載 /* List<String> list = getNextPageUrl(html); System.out.println(list.size()); for (int i = 0; i < list.size(); i++) { String url = list.get(i); System.out.println("下一個(gè)下載頁(yè)面:" + url); String html2 = getHtml(url); // html頁(yè)面內(nèi)容 List<String> srclists2 = getImgSrcListFromHtml(html2); // 圖片地址集合 downloadImg(srclists2, filepath); // 下載圖片 }*/ System.out.println("下載完畢"); } /** * * @Title: getHtml * @Description: 獲取頁(yè)面內(nèi)容 * @param @param url * @param @return 頁(yè)面內(nèi)容 * @return String 返回類(lèi)型 * @throws */ public static String getHtml(String url){ String html = ""; try { html = Jsoup.connect(url).execute().body(); } catch (IOException e) { e.printStackTrace(); } return html; } /** * * @Title: getImgSrcListFromHtml * @Description: 獲取頁(yè)面內(nèi)容圖片路徑 * @param @param html 頁(yè)面內(nèi)容 * @param @return 圖片路徑數(shù)組 * @return ArrayList<String> 返回類(lèi)型 * @throws */ public static List<String> getImgSrcListFromHtml(String html){ List<String> list = new ArrayList<>(); //解析成html頁(yè)面 Document document = Jsoup.parse(html); //獲取目標(biāo) Elements elements = document.select("div [class=qyzx_note]").select("img"); int len = elements.size(); for (int i = 0; i < len; i++) {
// list.add(elements.get(i).attr("src")); list.add(baseurl + elements.get(i).attr("src")); } return list; } /** * * @Title: getNextPage * @Description: 從頁(yè)面內(nèi)容中獲取下一個(gè)頁(yè)面路徑 * @param 頁(yè)面內(nèi)容 * @return List<String> 返回頁(yè)面url數(shù)組 * @throws */ public static List<String> getNextPageUrl(String html){ List<String> list = new ArrayList<>(); //解析成html頁(yè)面 Document document = Jsoup.parse(html); //獲取目標(biāo) Elements elements = document.select("div [class=list]").select("a"); for (int i = 0;i<elements.size();i++) { String url = baseurl + elements.get(i).attr("href"); list.add(url); } return list; } /** * * @Title: downloadImg * @Description: 下載圖片 -- 通過(guò)獲取的流轉(zhuǎn)成byte[]數(shù)組,再通過(guò)FileOutputStream寫(xiě)出 * @param @param list 圖片路徑數(shù)組 * @param @param filepath 保存文件夾位置 * @return void 返回類(lèi)型 * @throws */ public static void downloadImg(List<String> list, String filepath){ URL newUrl = null; HttpURLConnection hconnection = null; InputStream inputStream = null; FileOutputStream fileOutputStream = null; byte[] bs = null; try { int len = list.size(); for (int i = 0; i < len; i++) { String finalFilePath = ""; newUrl = new URL(list.get(i)); hconnection = (HttpURLConnection) newUrl.openConnection(); //打開(kāi)連接 hconnection.setRequestMethod("GET"); hconnection.setRequestProperty("Content-Type", "application/json"); hconnection.setRequestProperty("connection", "keep-alive"); hconnection.setRequestProperty("User-Agent", "Mozilla/4.76"); inputStream = hconnection.getInputStream(); //獲取流 bs = getBytesFromInputStream(inputStream); //流轉(zhuǎn)btye[] finalFilePath = filepath + list.get(i).substring(list.get(i).lastIndexOf("/")+1); //獲取圖片名稱(chēng) System.out.println("生成圖片路徑:"+finalFilePath); fileOutputStream = new FileOutputStream(new File(finalFilePath)); fileOutputStream.write(bs); //寫(xiě)出 } } catch (Exception e) { e.printStackTrace(); } finally { try { inputStream.close(); fileOutputStream.close(); } catch (IOException e) { e.printStackTrace(); } } } /** * * @Title: getBytesFromInputStream * @Description: InputStream流轉(zhuǎn)換byte[] * @param @param inputStream * @param @return byte[] * @return byte[] 返回類(lèi)型 * @throws */ public static byte[] getBytesFromInputStream(InputStream inputStream){ byte[] bs = null; try { byte[] buffer = new byte[1024]; int len = 0; ByteArrayOutputStream arrayOutputStream = new ByteArrayOutputStream(); // while((len = inputStream.read(buffer)) != -1){ arrayOutputStream.write(buffer, 0 ,len); } bs = arrayOutputStream.toByteArray(); } catch (IOException e) { e.printStackTrace(); } return bs; } }
結(jié)果展示如圖:
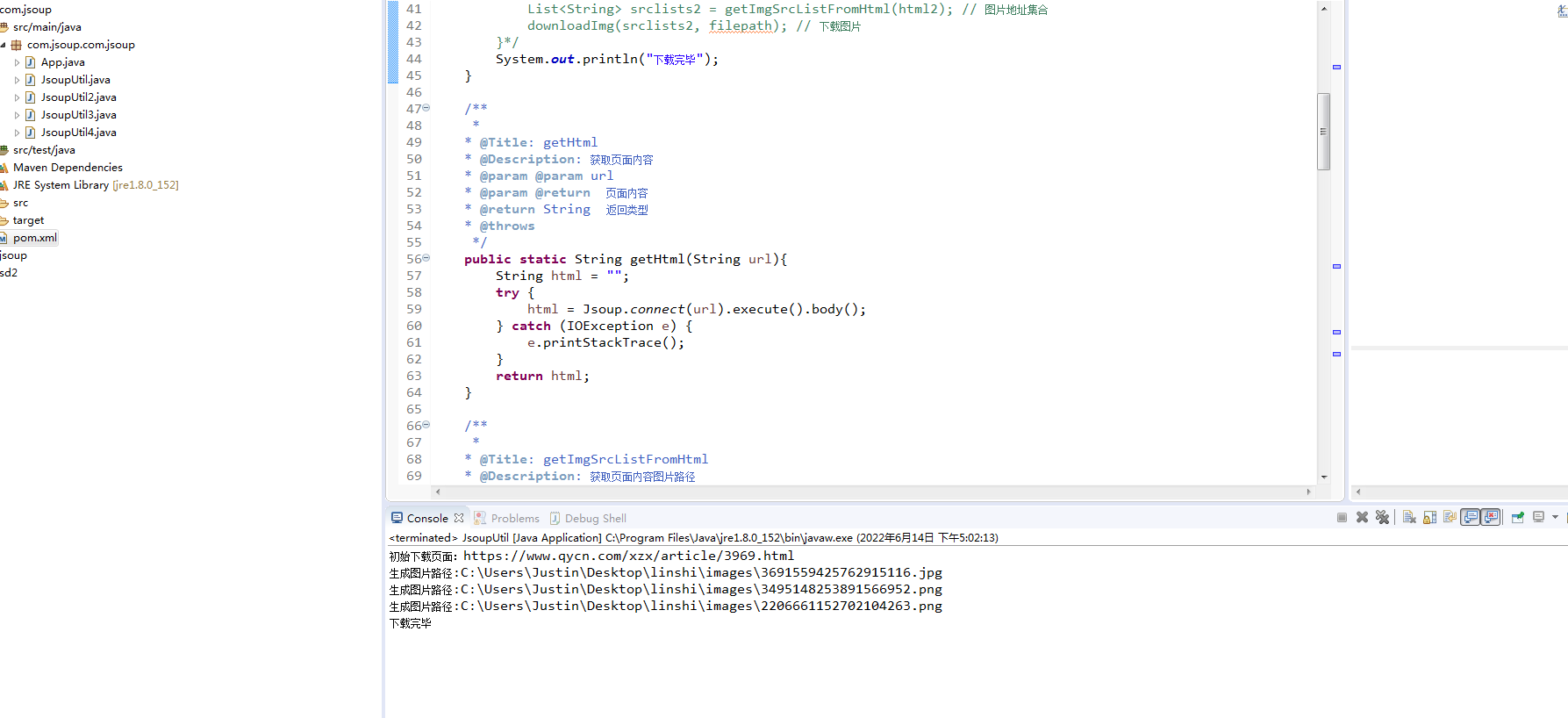
參考來(lái)自:https://blog.csdn.net/qq_37902949/article/details/81257065

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)