一期0. AI認(rèn)知課/pytorch框架
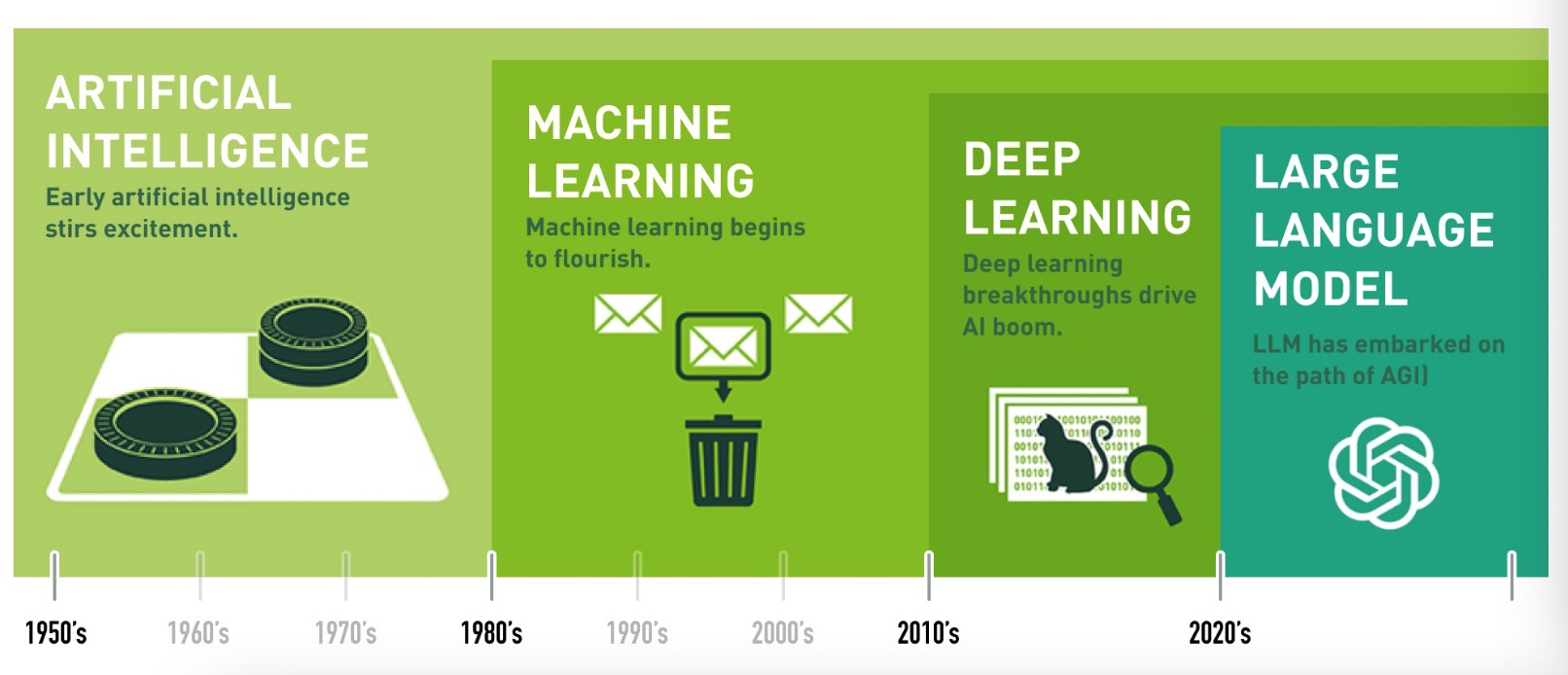
1.1 人工智能發(fā)展史
人工智能發(fā)展史?
學(xué)習(xí)目標(biāo)?
- 了解人工智能發(fā)展歷史
- 了解目前AI的主流技術(shù)方向與就業(yè)方向

- 人工智能 (Artificial Intelligence, 簡稱AI) 這個概念是在1956年提出的. 這一年, 約翰·麥卡錫 (John McCarthy) 和其他幾位科學(xué)家在美國達(dá)特茅斯學(xué)院 (Dartmouth College) 組織了一場研討會, 首次提出了"人工智能"一詞, 標(biāo)志著人工智能作為一門學(xué)科的正式誕生.
- 人工智能這個概念從誕生到今天也只有不到70年的時間, 是一門很年輕的科學(xué).

- 深度學(xué)習(xí)所需要的神經(jīng)網(wǎng)絡(luò)技術(shù)起源于20世紀(jì)50年代, 叫做感知機(jī). 當(dāng)時也通常使用單層感知機(jī), 盡管結(jié)構(gòu)簡單, 但是能夠解決復(fù)雜的問題. 后來感知機(jī)被證明存在嚴(yán)重的問題, 因為只能學(xué)習(xí)線性可分函數(shù), 連簡單的異或 (XOR) 等線性不可分問題都無能為力.

- 1969年Marvin Minsky寫了一本叫做《Perceptrons》的書, 他提出了著名的兩個觀點:
- 1: 單層感知機(jī)沒用, 我們需要多層感知機(jī)來解決復(fù)雜問題.
- 2: 沒有有效的訓(xùn)練算法.
- 20世紀(jì)80年代末期, 用于人工神經(jīng)網(wǎng)絡(luò)的反向傳播算法 (Back Propagation算法, BP算法) 的發(fā)明, 給機(jī)器學(xué)習(xí)帶來了希望, 掀起了基于統(tǒng)計模型的機(jī)器學(xué)習(xí)熱潮, 這個熱潮一直持續(xù)到今天. 人們發(fā)現(xiàn), 利用BP算法可以讓一個人工神經(jīng)網(wǎng)絡(luò)模型從大量訓(xùn)練樣本中學(xué)習(xí)統(tǒng)計規(guī)律, 從而對未知事件做預(yù)測. 這種基于統(tǒng)計的機(jī)器學(xué)習(xí)方法比起過去基于人工規(guī)則的系統(tǒng), 在很多方面顯出優(yōu)越性.
- 這個時候的人工神經(jīng)網(wǎng)絡(luò), 雖也被稱作多層感知機(jī) (Multi-layer Perceptron), 但實際是種只含有一層隱層節(jié)點的淺層模型.


- 2012年, 在著名的ImageNet圖像識別大賽中, 杰弗里·辛頓領(lǐng)導(dǎo)的小組采用深度學(xué)習(xí)模型AlexNet一舉奪冠, AlexNet采用ReLU激活函數(shù), 從根本上解決了梯度消失問題, 并采用GPU極大的提高了模型的運算速度.
- 同年, 由斯坦福大學(xué)著名的吳恩達(dá)教授和世界頂尖計算機(jī)專家Jeff Dean共同主導(dǎo)的深度神經(jīng)網(wǎng)絡(luò), DNN技術(shù)在圖像識別領(lǐng)域取得了驚人的成績, 在ImageNet評測中成功的把錯誤率從26%降低到了15%. 深度學(xué)習(xí)算法在世界大賽的脫穎而出, 也再一次吸引了學(xué)術(shù)界和工業(yè)界對于深度學(xué)習(xí)領(lǐng)域的關(guān)注.
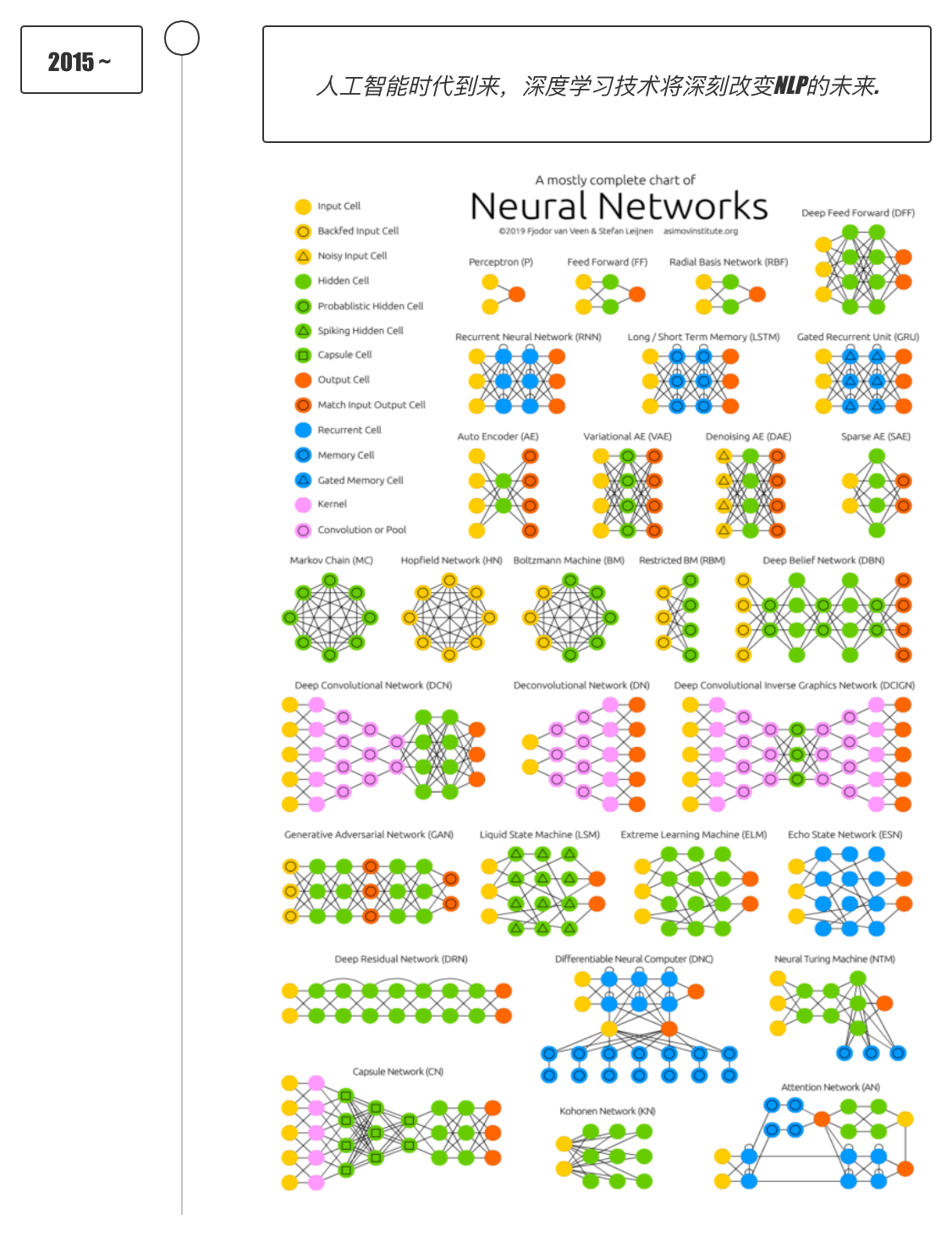
- 2016年, 隨著谷歌公司基于深度學(xué)習(xí)開發(fā)的AlphaGo以4:1的比分戰(zhàn)勝了國際頂尖圍棋高手李世石, 深度學(xué)習(xí)的熱度一時無兩. 后來, AlphaGo又接連和眾多世界級圍棋高手過招, 均取得了完勝. 這也證明了在圍棋界, 基于深度學(xué)習(xí)技術(shù)的機(jī)器人已經(jīng)徹底超越了人類.
- 2017年, 基于強(qiáng)化學(xué)習(xí)算法的AlphaGo升級版AlphaGo Zero橫空出世. 其采用"從零開始", "無師自通"的學(xué)習(xí)模式, 以100:0的比分輕而易舉打敗了之前的AlphaGo. 除了圍棋, 它還精通國際象棋等其它棋類游戲, 可以說是真正的棋類天才.

- 2017年, 谷歌推出了劃時代的作品Transformer, 對整個人工智能的發(fā)展影響深遠(yuǎn). 此外在這一年, 深度學(xué)習(xí)的相關(guān)算法在醫(yī)療、金融、藝術(shù)、無人駕駛等多個領(lǐng)域均取得了顯著的成果. 所以, 也有專家把2017年看作是深度學(xué)習(xí)甚至是人工智能發(fā)展最為突飛猛進(jìn)的一年.
- 2018年, 谷歌推出了BERT, 開啟了預(yù)訓(xùn)練模型和遷移學(xué)習(xí)的時代.
- 2019年, GPT2, T5, AlBERT, RoBERTa, XLNet, 一系列預(yù)訓(xùn)練模型的推出大大提升了AI的應(yīng)用效果.
- 2020年, 深度學(xué)習(xí)擴(kuò)展到更多的應(yīng)用場景, 比如積水識別, 路面塌陷等, 而且疫情期間, 在智能外呼系統(tǒng), 人群測溫系統(tǒng), 口罩人臉識別等都有深度學(xué)習(xí)的應(yīng)用.
- 2021年, 巨量模型大量涌現(xiàn), 參數(shù)規(guī)模從幾百億迅速增長到上萬億.
- 2022年11月30日, ChatGPT橫空出世, 開啟了AI大模型的時代.
- 2023年, 是全世界大模型的戰(zhàn)國時代.
- 2024年, 2月份Sora橫空出世, 5月GPT-4o, DeepSeek-v2, 快手可靈, 都是最前沿的成果.
人工智能關(guān)鍵詞?
- 人工智能 (Artificial Intelligence)
- 機(jī)器學(xué)習(xí) (Machine Learning) - 深度學(xué)習(xí) (Deep Learning)
- 大語言模型 (Large Language Model)
AI技術(shù)方向 & 就業(yè)方向?
- AI主流技術(shù)方向:
- ASR: 語音
- CV: 視覺
- NLP: 語言
- MM: 多模態(tài)
- RS: 搜廣推
- RL: 強(qiáng)化學(xué)習(xí)
- AI主流就業(yè)方向:
- AI算法工程師
- AI大模型工程師
- AI研發(fā)工程師
- AI應(yīng)用開發(fā)工程師
- AI產(chǎn)品經(jīng)理
- AI訓(xùn)練師
- AI數(shù)據(jù)標(biāo)注師
2.1 人工智能的奇點ChatGPT
人工智能的奇點ChatGPT?
學(xué)習(xí)目標(biāo)?
- 理解ChatGPT的發(fā)展脈絡(luò)和重大意義.
ChatGPT時刻?
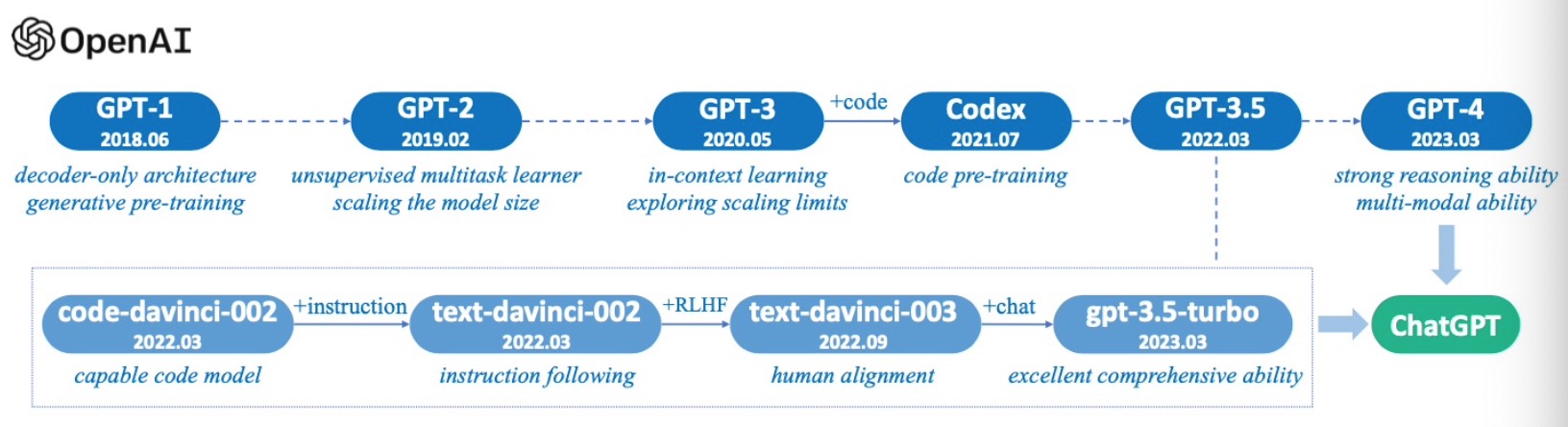
- 2017年6月Transformer橫空出世!!!
- 2018年6月GPT, 參數(shù)量1.1億, 核心點是基于Transformer Decoder的masked multi-head self-attention
- 2019年2月GPT2, 參數(shù)量15億, 核心點是融合了prompt learning, 省去了微調(diào).
- 2020年5月GPT3, 參數(shù)量1750億, 核心點是通過ICL(In-Context Learning)開啟了prompt新范式.
- 2021年7月Codex, 基于GPT3進(jìn)行了大量的代碼訓(xùn)練而產(chǎn)生的模型Codex, 使其具備了代碼編寫和代碼推理能力.
- 2021年10月OpenAI內(nèi)部發(fā)展出了GPT3.5, 但未對外公開.
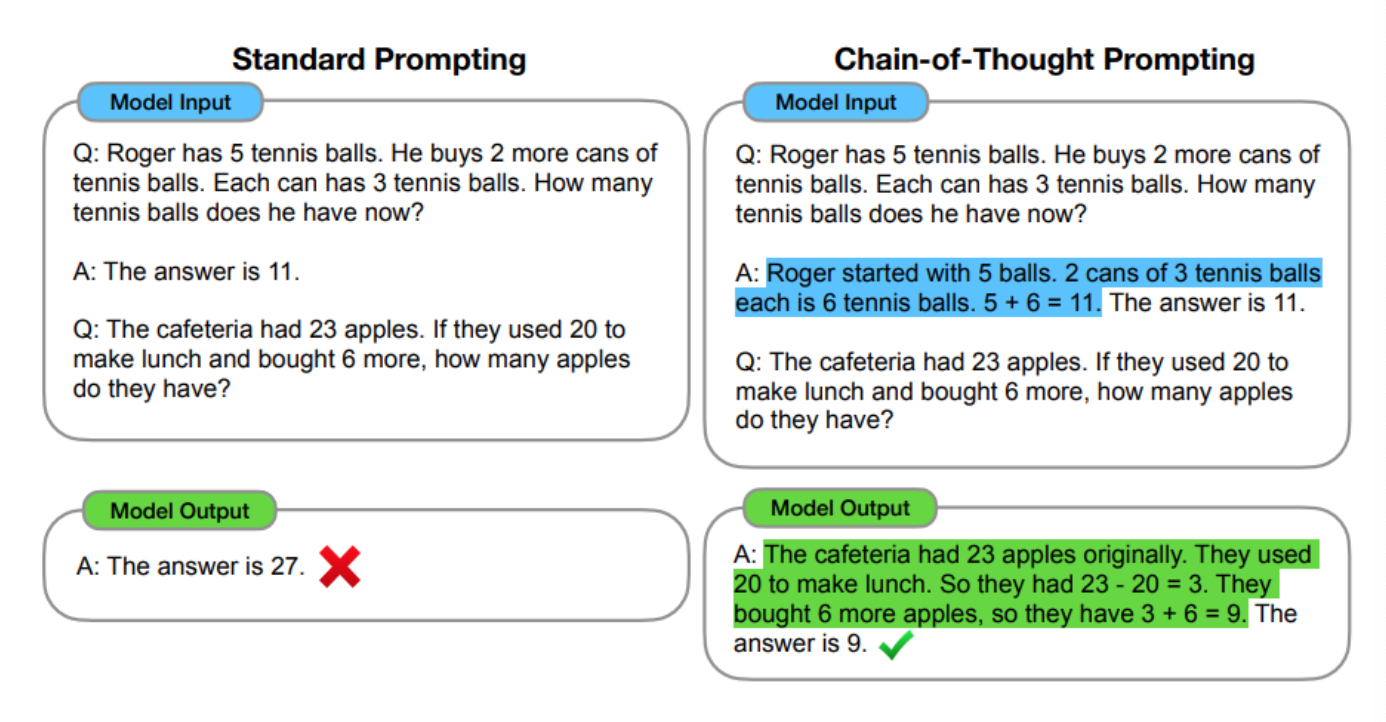
- 2022年1月Google提出思維鏈技術(shù)CoT (Chain of Thought)
- 2022年11月30日, OpenAI正式發(fā)布chatGPT, 核心點是基于GPT3.5, 融合了Codex + 強(qiáng)化學(xué)習(xí)的技術(shù).
- 2023年3月, OpenAI正式發(fā)布GPT4, 增加了多模態(tài)能力.
- 2024年2月, OpenAI正式發(fā)布Sora, 首次完成60s穩(wěn)定, 流暢, 一致性的視頻生成模型.

- https://www.bilibili.com/video/BV17u4m1P7yM/?spm_id_from=333.788&vd_source=df7ff49c7ff2ca7e998b84c4369f1a59
- 2024年5月, OpenAI正式發(fā)布GPT-4o, 流浪地球2的電影場景第一次進(jìn)入現(xiàn)實.
- https://www.bilibili.com/video/BV1pt421M7CG/?vd_source=df7ff49c7ff2ca7e998b84c4369f1a59
3.1 AI前端界面
AI前端界面?
學(xué)習(xí)目標(biāo)?
- 了解一個具備AI能力的簡單前端界面.
- 理解未來的前端, 后端工程師要具備AI開發(fā)的能力.
- 這里是AI課程, 不是前端課程, 只作為一個引子, 展示給同學(xué)們一個具備AI能力的前端界面.
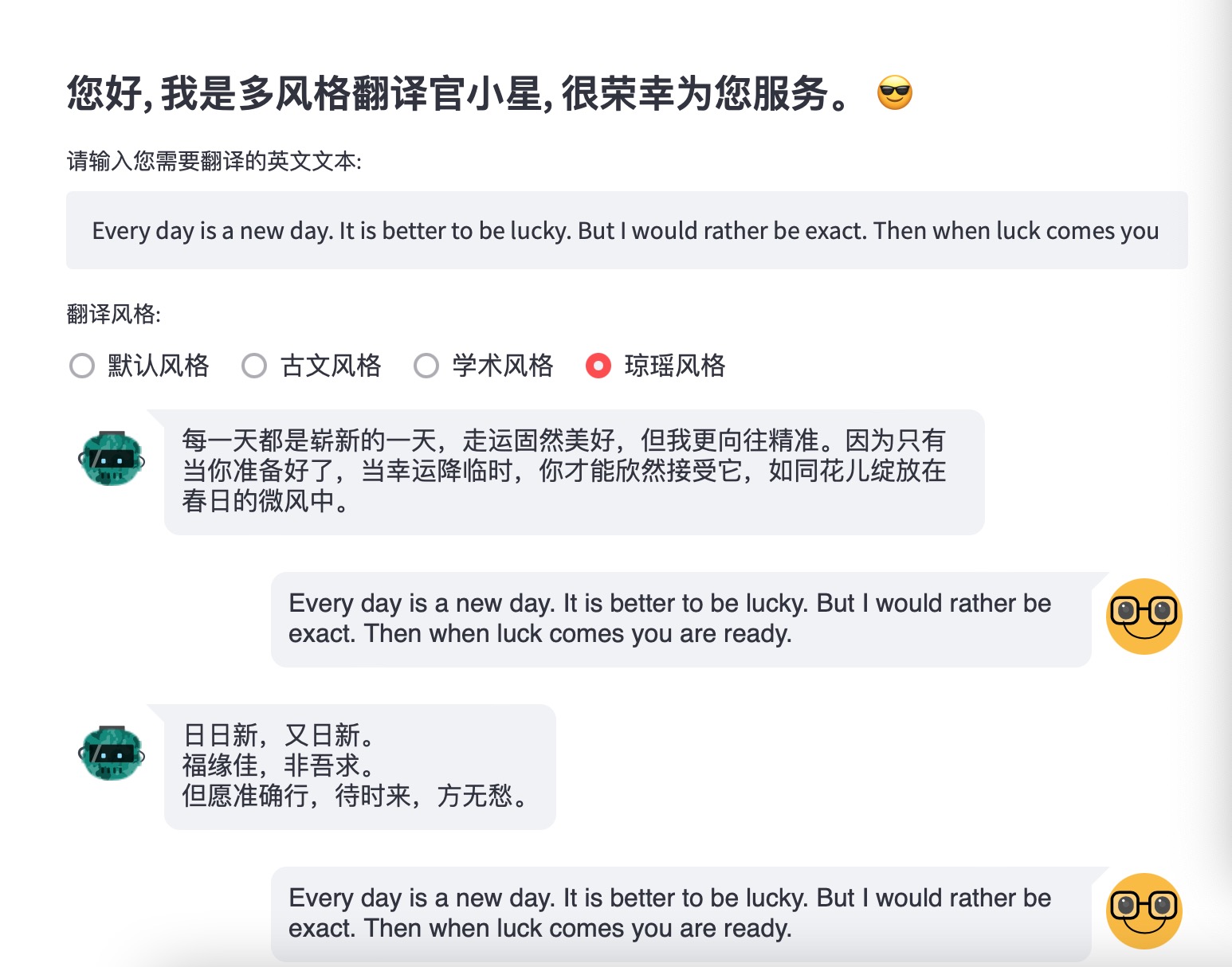
# 老人與海經(jīng)典原文 But a man is not made for defeat. A man can be destroyed but not defeated.- 輸入一段圣經(jīng)中的原文:
You are the salt of the earth,you are the light of the world,will shine before humanity.- streamlit run ./main_translate.py
4.1 大模型時代的風(fēng)起云涌
大模型時代的風(fēng)起云涌?
學(xué)習(xí)目標(biāo)?
- 了解當(dāng)前主流語言大模型的進(jìn)展.
- 了解當(dāng)前主流多模態(tài)大模型的進(jìn)展.
- 了解當(dāng)前主流AI搜索大模型的進(jìn)展.
語言大模型?
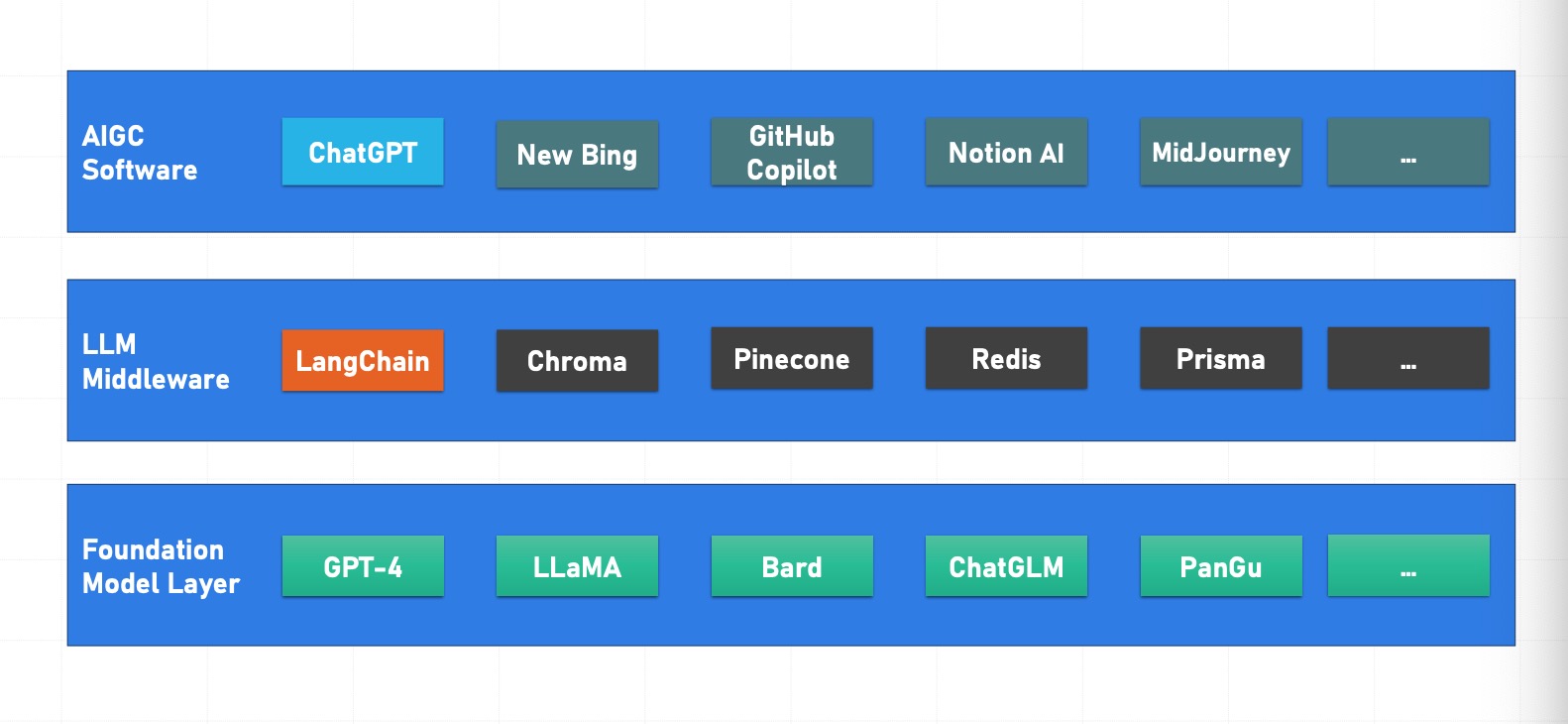
- ??基礎(chǔ)大模型底層 --->>> LLM中間層 --->>> AIGC軟件層
百度: 文心大模型?

阿里巴巴: 千問大模型?

騰訊: 混元大模型?
字節(jié)跳動: 云雀大模型?

科大訊飛: 星火大模型?

智譜清言: ChatGLM大模型?
Minimax: ABAB大模型?

階躍星辰: Step大模型?

深度求索: DeepSeek大模型?
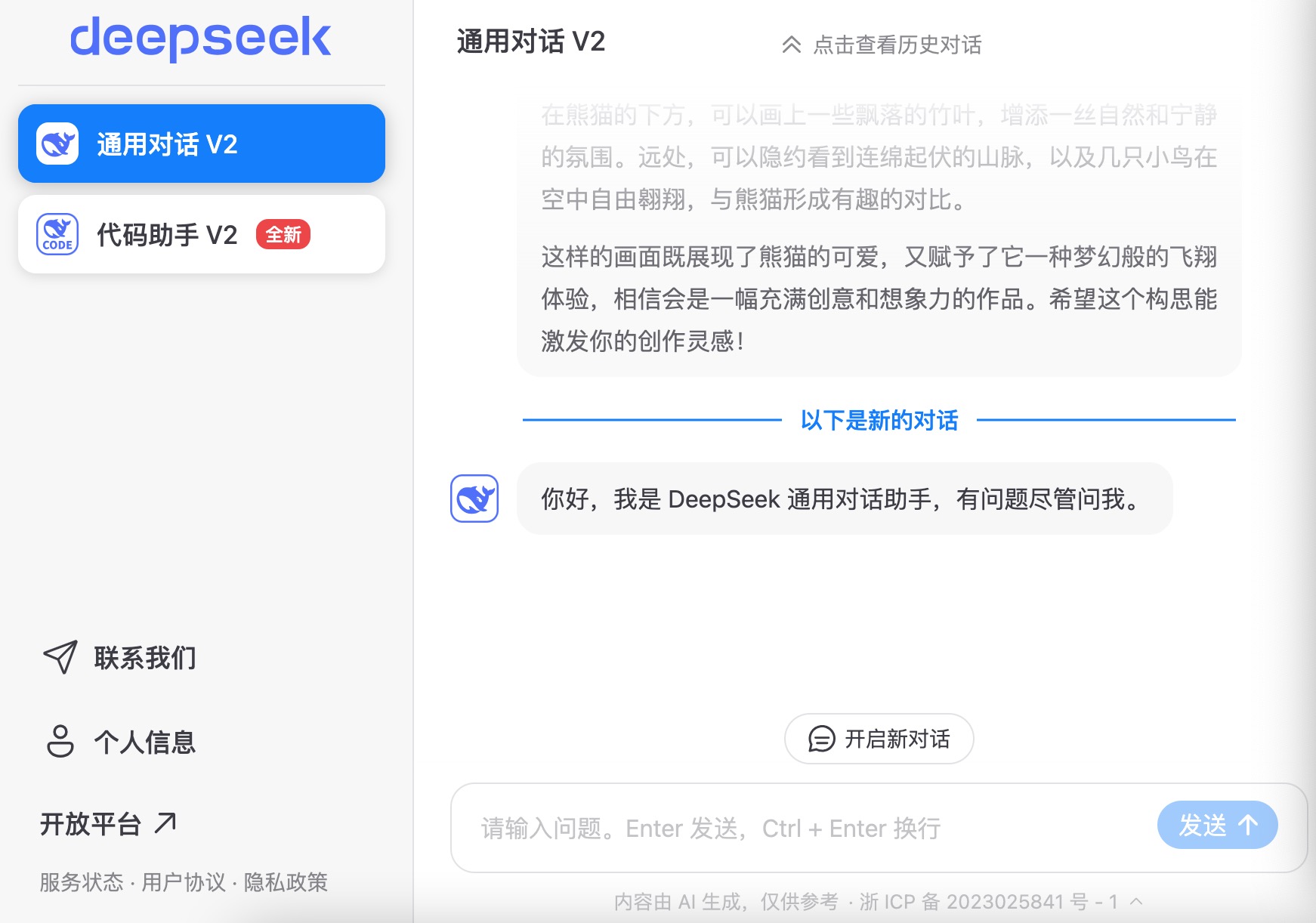
月之暗面: Kimi大模型?
多模態(tài)大模型?
GPT4?
快手: 可靈?

字節(jié)跳動: 即夢?

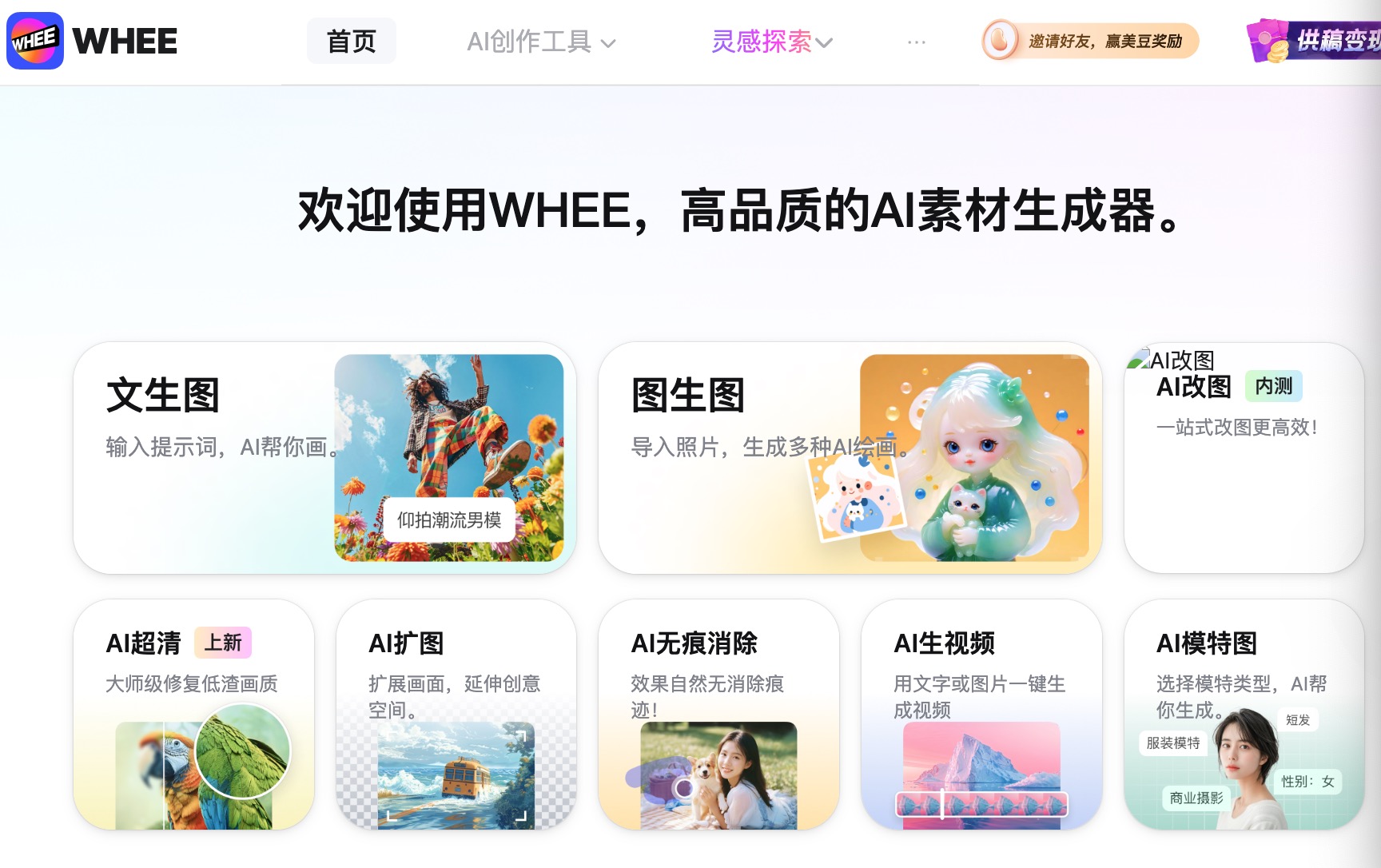
美圖: Whee?
AI搜索?
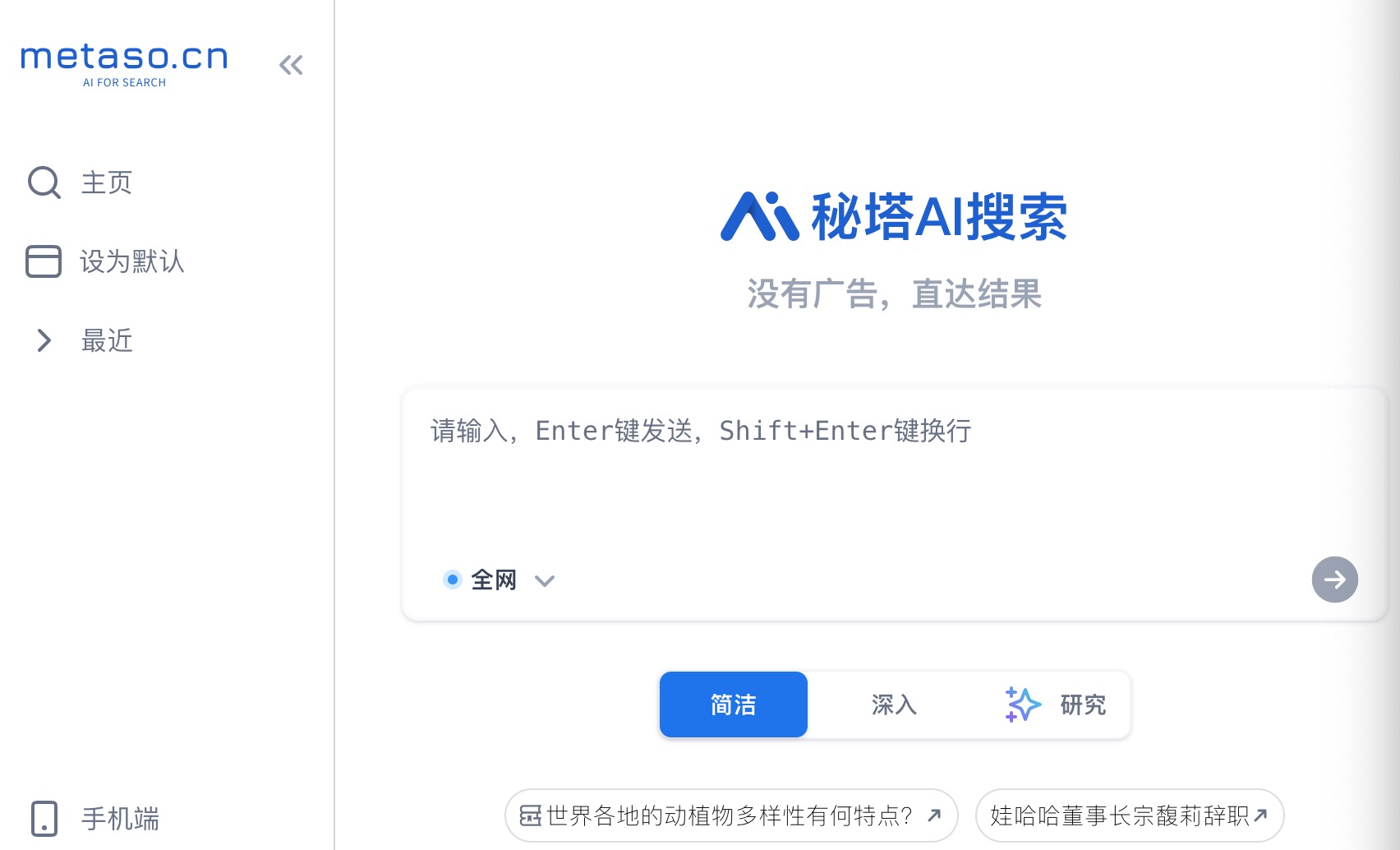
秘塔?
小節(jié)總結(jié)?
- 宏觀上了解了當(dāng)前學(xué)術(shù)圈和產(chǎn)業(yè)圈的AI大模型最新進(jìn)展.
5.1 AI生存法則
技術(shù)人員的AI生存法則?
學(xué)習(xí)目標(biāo)?
- 了解AI時代的新變化.
- 理解AI時代的變革原因.
- 理解AI時代的模式和開發(fā)框架.
AI時代生存法則?
- 搜索關(guān)鍵字的變化!
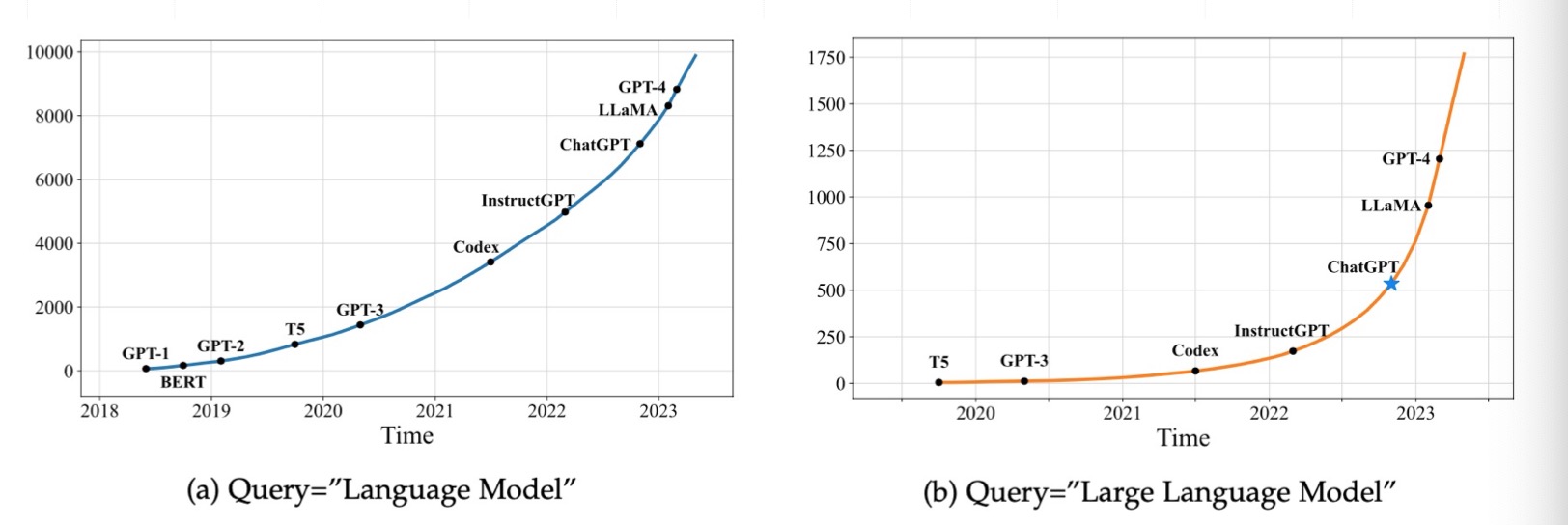
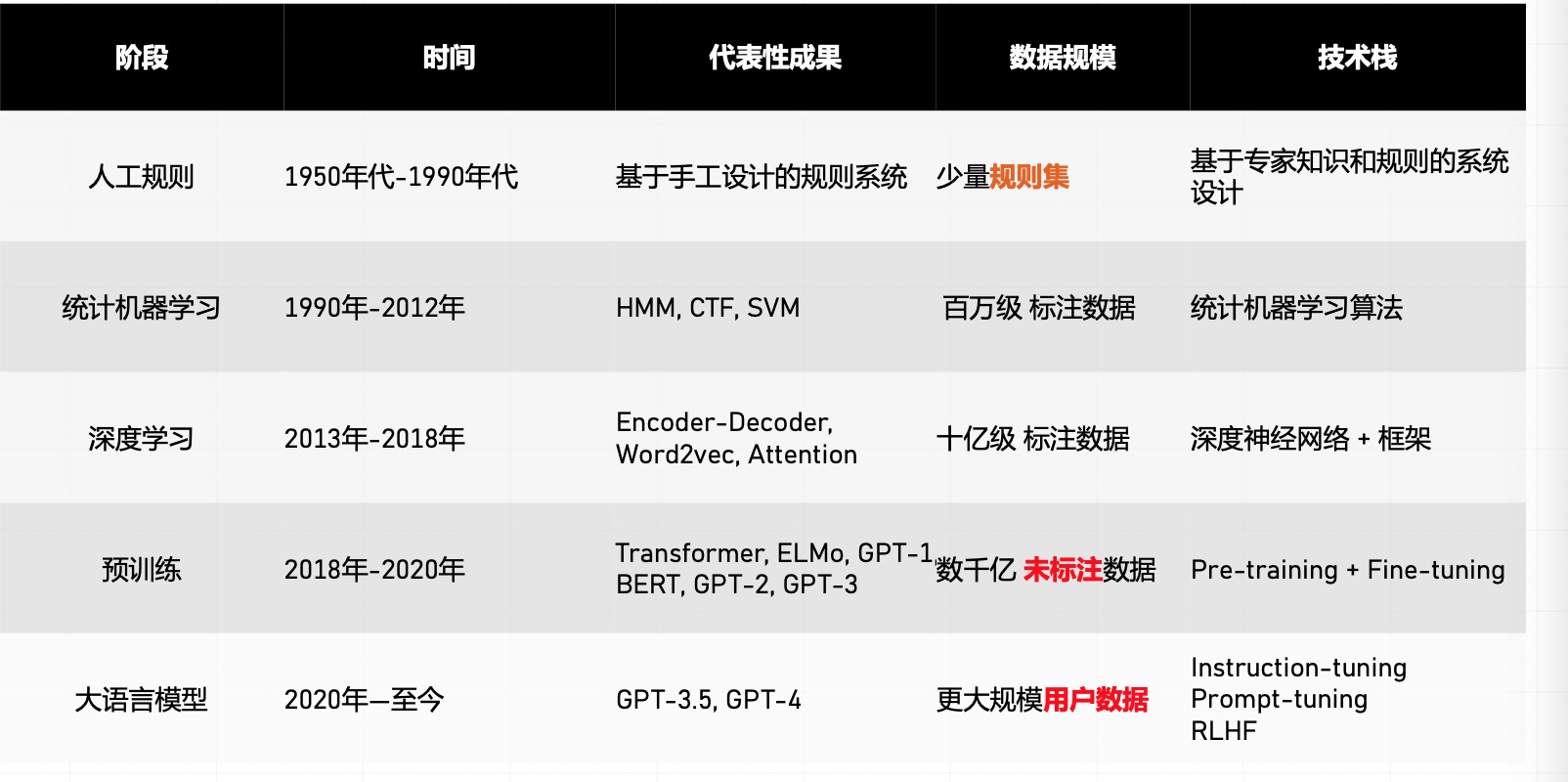
- 隨著時代的發(fā)展, 技術(shù)模式也在不斷遷移.

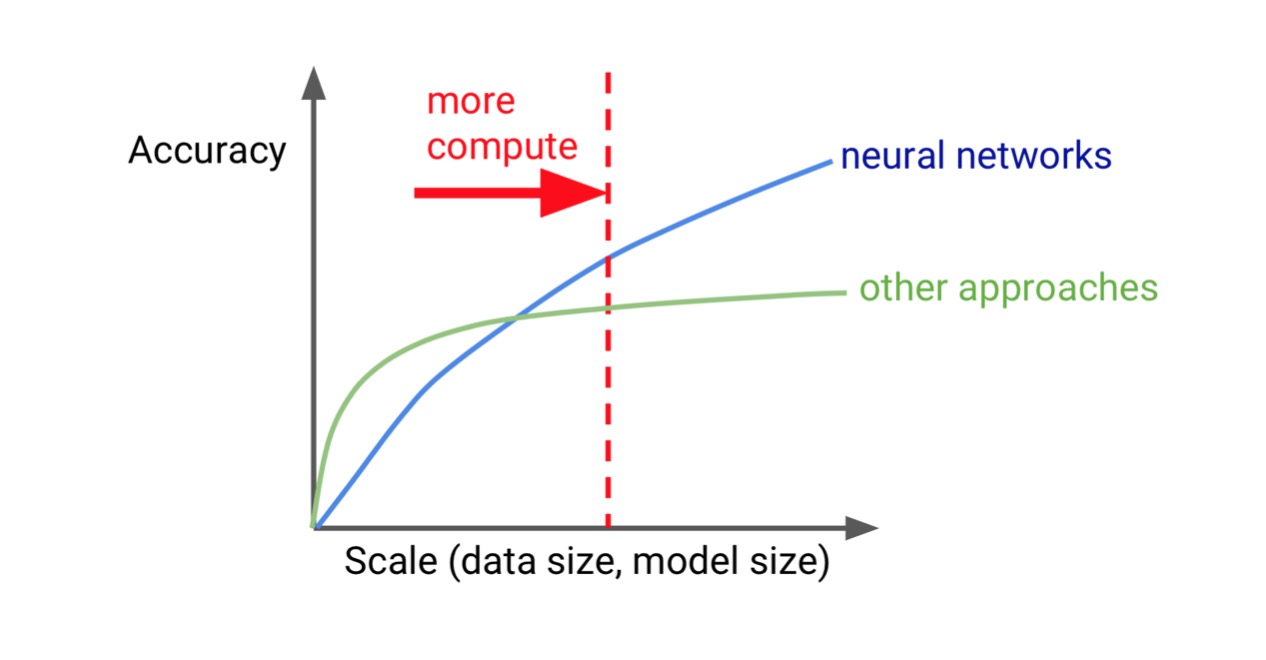
- 算力增長和AI效能:
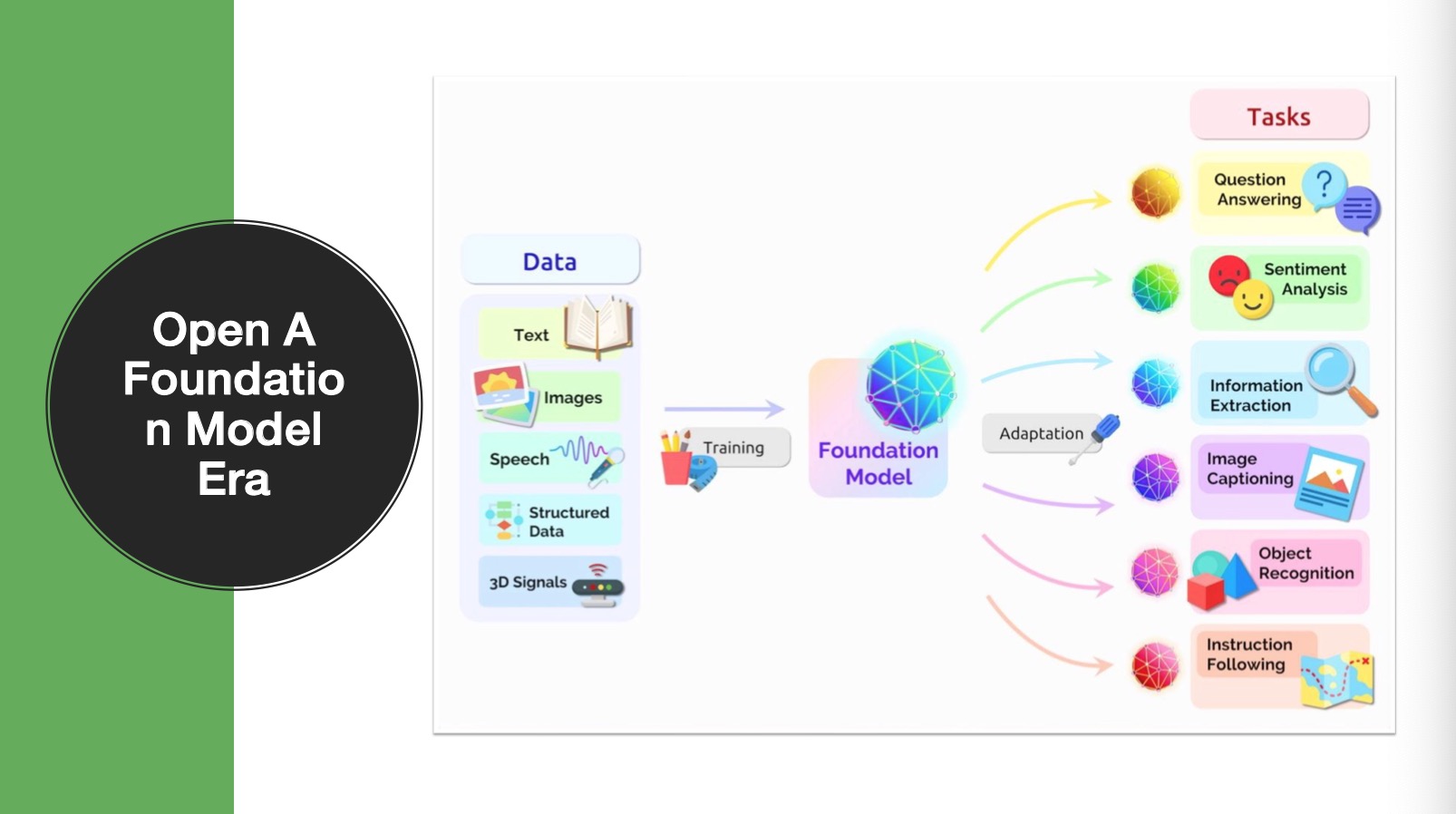
- AI大模型時代的開發(fā)模式
- AI大模型時代的技術(shù)棧

如何做一個職業(yè)程序員??
- 1: 開發(fā)環(huán)境
- ??Linux優(yōu)先!!! Linux優(yōu)先!!! Linux優(yōu)先!!!
- 2: 開發(fā)IDE
- vim
- VSCode
- PyCharm
- Jupyter Notebook
- 3: 軟件版本
- anaconda
- Pytorch 1.6, 2.0, 2.1, 2.2
- transformers 3.6, 4.30, 4.32
- AutoDL: GPU
- https://www.autodl.com/
- 魔搭: GPU
- https://modelscope.cn/
- 趨動云: GPU
- https://www.virtaicloud.com/
- 青云:
- https://www.qingcloud.com/
- https://www.coreshub.cn/
- 提醒??: ??整個課程期間基本上每周都會提交一次作業(yè).
- 助教郵箱??: wanghao5276@163.com
- 小朱老師郵箱??: 348811083@qq.com
- 提交作業(yè)的截止時間, 在布置作業(yè)的時候會通知, 具體時間也會寫在每次課堂講義最下面.
- 每次作業(yè)評分A, B, C, D, 對同學(xué)們最后期末打分很重要, 加油??
- 問題1: 單詞Strawberry中有幾個字母r ?
- 如何理解大模型的"幻覺"問題?
- 通俗的講, 就是一本正經(jīng)的胡說八道.
- 如何理解大模型的"幻覺"問題?
- 問題2: 2025年春節(jié):1月28日(農(nóng)歷除夕,周二)至2月4日(農(nóng)歷正月初七, 周二)放假調(diào)休, 共8天。1月26日(周日),2月8日(周六)上班。請你計算真的假期, 請注意, 雙休日本來就是屬于打工牛馬的假期,請一步步思考。
- 作業(yè)1: 回去查查什么叫感知機(jī)? (傳統(tǒng)機(jī)器學(xué)習(xí)的領(lǐng)域, 深度學(xué)習(xí)中最最基礎(chǔ)的一個小概念)
- 問題3: Hinton大神認(rèn)識嗎?
- 2019年圖靈獎
- 2024年諾貝爾物理獎
- 全世界第一個同時拿圖靈獎 + 諾貝爾獎的大神!!!
- ??1989年的反向傳播算法!!!
- 2012年AlexNet勇拿競賽冠軍??, 才把這個算法發(fā)揚光大!!!
- 大牛: 很多顯而易見的事情, 是當(dāng)所有人都知道它顯而易見了, 它才顯而易見.
- 問題4: 到底啥是多模態(tài)? (不再猶豫)
- 語音
- 語言
- 圖片
- 視頻
- 上面兩個以上的模態(tài)放在一起就是多模態(tài).
- 文生圖
- 看圖說話
- 圖生視頻
- 問題5: 當(dāng)前學(xué)術(shù)圈 + 工業(yè)界, AI的最前沿的幾個方向?
- GPT-o1: 復(fù)雜推理
- 具身智能
- 多模態(tài)
- 問題6: 關(guān)于大模型時代的算力需求?
- 國內(nèi)最大的算力池: 字節(jié)跳動的火山引擎 --- 保守估計10萬塊.
- 3090, 4090: 5000元 ~ 10000元
- T4, V100: 2 ~ 3萬人民幣
- A100, A800: 10萬人民幣
- 2023年訓(xùn)練GPT-4模型, 大概用了5萬塊A100. (花了50億)
- 2023年春天, 2月份, 美團(tuán)聯(lián)合創(chuàng)始人. (出資5000萬, 6月份悄悄的跑了)
- H100, H800: 25萬人民幣
- 未來GPT-5模型需要10萬塊H100. (250億)
- B200: 60萬人民幣
- 問題7: 關(guān)于開發(fā) + 學(xué)習(xí)環(huán)境?
- 強(qiáng)烈建議在Linux環(huán)境下.
- ??利用工具: anaconda 創(chuàng)建同學(xué)們自己的虛擬環(huán)境 (作業(yè))
- 創(chuàng)建虛擬環(huán)境命令: conda create -n deeplearning python=3.10
- 激活環(huán)境: conda activate deeplearning
- 安裝包: pip install torch, pip install transformers
- 問題8: 大模型領(lǐng)域哪些需求大? 偏飽和?
- 整個大模型都屬于藍(lán)海.......
- 1: NLP, 搜廣推 ?
- 2: 語音, 多模態(tài) ?
- 3: CV, 強(qiáng)化學(xué)習(xí) ?
1 框架介紹與安裝?
- 本章節(jié)主要帶領(lǐng)大家學(xué)習(xí)使用深度學(xué)習(xí)框架 PyTorch:
PyTorch 介紹?

- 在2017年1月, Facebook的人工智能研究院 (FAIR) 向世界推出了PyTorch. 這個基于Torch的框架, 以其Python語言作為前端, 同時為深度學(xué)習(xí)研究者和開發(fā)者提供了兩大核心優(yōu)勢:
- 一是強(qiáng)大的GPU加速張量計算能力, 其并行計算能力在當(dāng)時與NumPy相媲美.
- 二是內(nèi)置的自動微分系統(tǒng), 使得構(gòu)建深度神經(jīng)網(wǎng)絡(luò)變得更加直觀和高效.
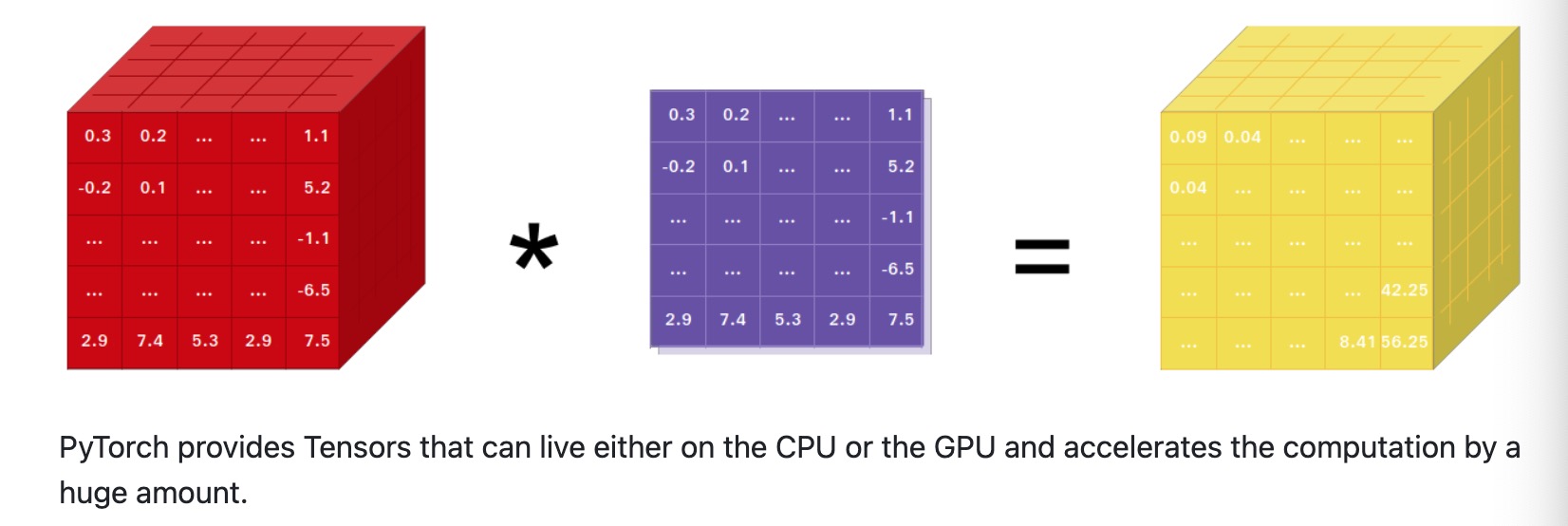
- 2018年10月, 在NeurIPS 2018會議上, Facebook宣布了PyTorch 1.0的發(fā)布. 這個版本的推出, 標(biāo)志著PyTorch在商業(yè)化進(jìn)程中取得了重要進(jìn)展.
- 在2019年前, Tensorflow一直作為深度學(xué)習(xí)系統(tǒng)中的領(lǐng)頭存在, 而以2019年為分界線, Pytorch異軍突起, 逐漸成為了開發(fā)者和研究人員最為喜愛的框架. 隨著Pytorch的不斷普及和完善, 其生態(tài)也越發(fā)蓬勃.
- 在AI領(lǐng)域, huggingface社區(qū)的開源的transformers庫使用pytorch實現(xiàn)了市面上絕大多數(shù)開源的預(yù)訓(xùn)練模型.
- 微軟的分布式訓(xùn)練框架deepspeed也支持Pytorch, 由于Pytorch備受研究人員的青睞, 近年來絕大多數(shù)開源神經(jīng)網(wǎng)絡(luò)架構(gòu)都采用Pytorch實現(xiàn).
PyTorch 安裝?
- https://github.com/pytorch/pytorch

- 安裝:
pip install torch==2.1.0- 通過本章節(jié)的學(xué)習(xí), 同學(xué)們將會了解Pytorch的發(fā)展歷史, 并掌握 PyTorch 深度學(xué)習(xí)框架的安裝.
1 張量的創(chuàng)建?
學(xué)習(xí)目標(biāo)?
- 掌握張量創(chuàng)建
PyTorch 是一個 Python 深度學(xué)習(xí)框架,它將數(shù)據(jù)封裝成張量(Tensor)來進(jìn)行運算。PyTorch 中的張量就是元素為同一種數(shù)據(jù)類型的多維矩陣。在 PyTorch 中,張量以 "類" 的形式封裝起來,對張量的一些運算、處理的方法被封裝在類中。
1. 基本創(chuàng)建方式?
- torch.tensor 根據(jù)指定數(shù)據(jù)創(chuàng)建張量
- torch.Tensor 根據(jù)形狀創(chuàng)建張量, 其也可用來創(chuàng)建指定數(shù)據(jù)的張量
- torch.IntTensor、torch.FloatTensor、torch.DoubleTensor 創(chuàng)建指定類型的張量
import torch
import numpy as np
import random
# 1. 根據(jù)已有數(shù)據(jù)創(chuàng)建張量
def test01():
# 1. 創(chuàng)建張量標(biāo)量
data = torch.tensor(10)
print(data)
# 2. numpy 數(shù)組, 由于 data 為 float64, 下面代碼也使用該類型
data = np.random.randn(2, 3)
data = torch.tensor(data)
print(data)
# 3. 列表, 下面代碼使用默認(rèn)元素類型 float32
data = [[10., 20., 30.], [40., 50., 60.]]
data = torch.tensor(data)
print(data)
# 2. 創(chuàng)建指定形狀的張量
def test02():
# 1. 創(chuàng)建2行3列的張量, 默認(rèn) dtype 為 float32
data = torch.Tensor(2, 3)
print(data)
# 2. 注意: 如果傳遞列表, 則創(chuàng)建包含指定元素的張量
data = torch.Tensor([10])
print(data)
data = torch.Tensor([10, 20])
print(data)
# 3. 使用具體類型的張量
def test03():
# 1. 創(chuàng)建2行3列, dtype 為 int32 的張量
data = torch.IntTensor(2, 3)
print(data)
# 2. 注意: 如果傳遞的元素類型不正確, 則會進(jìn)行類型轉(zhuǎn)換
data = torch.IntTensor([2.5, 3.3])
print(data)
# 3. 其他的類型
data = torch.ShortTensor() # int16
data = torch.LongTensor() # int64
data = torch.FloatTensor() # float32
data = torch.DoubleTensor() # float64
if __name__ == '__main__':
test02()
程序輸出結(jié)果:
tensor(10)
tensor([[ 0.1345, 0.1149, 0.2435],
[ 0.8026, -0.6744, -1.0918]], dtype=torch.float64)
tensor([[10., 20., 30.],
[40., 50., 60.]])
tensor([[0.0000e+00, 3.6893e+19, 2.2018e+05],
[4.6577e-10, 2.4158e-12, 1.1625e+33]])
tensor([10.])
tensor([10., 20.])
tensor([[ 0, 1610612736, 1213662609],
[ 805308409, 156041223, 1]], dtype=torch.int32)
tensor([2, 3], dtype=torch.int32)
2. 創(chuàng)建線性和隨機(jī)張量?
- torch.arange 和 torch.linspace 創(chuàng)建線性張量
- torch.random.init_seed 和 torch.random.manual_seed 隨機(jī)種子設(shè)置
- torch.randn 創(chuàng)建隨機(jī)張量
import torch
# 1. 創(chuàng)建線性空間的張量
def test01():
# 1. 在指定區(qū)間按照步長生成元素 [start, end, step)
data = torch.arange(0, 10, 2)
print(data)
# 2. 在指定區(qū)間按照元素個數(shù)生成
data = torch.linspace(0, 11, 10)
print(data)
# 2. 創(chuàng)建隨機(jī)張量
def test02():
# 1. 創(chuàng)建隨機(jī)張量
data = torch.randn(2, 3) # 創(chuàng)建2行3列張量
print(data)
# 2. 隨機(jī)數(shù)種子設(shè)置
print('隨機(jī)數(shù)種子:', torch.random.initial_seed())
torch.random.manual_seed(100)
print('隨機(jī)數(shù)種子:', torch.random.initial_seed())
if __name__ == '__main__':
test02()
程序輸出結(jié)果:
tensor([0, 2, 4, 6, 8])
tensor([ 0.0000, 1.2222, 2.4444, 3.6667, 4.8889, 6.1111, 7.3333, 8.5556,
9.7778, 11.0000])
tensor([[-0.5209, -0.2439, -1.1780],
[ 0.8133, 1.1442, 0.6790]])
隨機(jī)數(shù)種子: 4508475192273306739
隨機(jī)數(shù)種子: 100
3. 創(chuàng)建01張量?
- torch.ones 和 torch.ones_like 創(chuàng)建全1張量
- torch.zeros 和 torch.zeros_like 創(chuàng)建全0張量
- torch.full 和 torch.full_like 創(chuàng)建全為指定值張量
import torch
# 1. 創(chuàng)建全0張量
def test01():
# 1. 創(chuàng)建指定形狀全0張量
data = torch.zeros(2, 3)
print(data)
# 2. 根據(jù)張量形狀創(chuàng)建全0張量
data = torch.zeros_like(data)
print(data)
# 2. 創(chuàng)建全1張量
def test02():
# 1. 創(chuàng)建指定形狀全0張量
data = torch.ones(2, 3)
print(data)
# 2. 根據(jù)張量形狀創(chuàng)建全0張量
data = torch.ones_like(data)
print(data)
# 3. 創(chuàng)建全為指定值的張量
def test03():
# 1. 創(chuàng)建指定形狀指定值的張量
data = torch.full([2, 3], 10)
print(data)
# 2. 根據(jù)張量形狀創(chuàng)建指定值的張量
data = torch.full_like(data, 20)
print(data)
if __name__ == '__main__':
test01()
test02()
test03()
程序輸出結(jié)果:
tensor([[0., 0., 0.],
[0., 0., 0.]])
tensor([[0., 0., 0.],
[0., 0., 0.]])
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[10, 10, 10],
[10, 10, 10]])
tensor([[20, 20, 20],
[20, 20, 20]])
4. 張量元素類型轉(zhuǎn)換?
- tensor.type(torch.DoubleTensor)
- torch.double()
import torch
def test():
data = torch.full([2, 3], 10)
print(data.dtype)
# 將 data 元素類型轉(zhuǎn)換為 float64 類型
# 1. 第一種方法
data = data.type(torch.DoubleTensor)
print(data.dtype)
# 轉(zhuǎn)換為其他類型
# data = data.type(torch.ShortTensor)
# data = data.type(torch.IntTensor)
# data = data.type(torch.LongTensor)
# data = data.type(torch.FloatTensor)
# 2. 第二種方法
data = data.double()
print(data.dtype)
# 轉(zhuǎn)換為其他類型
# data = data.short()
# data = data.int()
# data = data.long()
# data = data.float()
if __name__ == '__main__':
test()
程序輸出結(jié)果:
torch.int64
torch.float64
torch.float64
5. 小節(jié)?
在本小節(jié)中,我們主要學(xué)習(xí)了以下內(nèi)容:
1. 創(chuàng)建張量的方式
1. torch.tensor 根據(jù)指定數(shù)據(jù)創(chuàng)建張量
2. torch.Tensor 根據(jù)形狀創(chuàng)建張量, 其也可用來創(chuàng)建指定數(shù)據(jù)的張量
3. torch.IntTensor、torch.FloatTensor、torch.DoubleTensor 創(chuàng)建指定類型的張量
- 創(chuàng)建線性和隨機(jī)張量 - torch.arange 和 torch.linspace 創(chuàng)建線性張量
- torch.random.init_seed 和 torch.random.manual_seed 隨機(jī)種子設(shè)置
- torch.randn 創(chuàng)建隨機(jī)張量
- 創(chuàng)建01張量 - torch.ones 和 torch.ones_like 創(chuàng)建全1張量
- torch.zeros 和 torch.zeros_like 創(chuàng)建全0張量
- torch.full 和 torch.full_like 創(chuàng)建全為指定值張量
- 張量元素類型轉(zhuǎn)換 - tensor.type(torch.DoubleTensor)
- torch.double()
2 張量數(shù)值計算?
學(xué)習(xí)目標(biāo)?
- 掌握張量基本運算
- 掌握阿達(dá)瑪積、點積運算
- 掌握PyTorch指定運算設(shè)備
PyTorch 計算的數(shù)據(jù)都是以張量形式存在, 我們需要掌握張量各種運算. 并且, 我們可以在 CPU 中運算, 也可以在 GPU 中運算.
1. 張量基本運算?
基本運算中,包括 add、sub、mul、div、neg 等函數(shù), 以及這些函數(shù)的帶下劃線的版本 add_、sub_、mul_、div_、neg_,其中帶下劃線的版本為修改原數(shù)據(jù)。
import numpy as np
import torch
def test():
data = torch.randint(0, 10, [2, 3])
print(data)
print('-' * 50)
# 1. 不修改原數(shù)據(jù)
new_data = data.add(10) # 等價 new_data = data + 10
print(new_data)
print('-' * 50)
# 2. 直接修改原數(shù)據(jù)
# 注意: 帶下劃線的函數(shù)為修改原數(shù)據(jù)本身
data.add_(10) # 等價 data += 10
print(data)
# 3. 其他函數(shù)
print(data.sub(100))
print(data.mul(100))
print(data.div(100))
print(data.neg())
if __name__ == '__main__':
test()
程序輸出結(jié)果:
tensor([[3, 7, 4],
[0, 0, 6]])
--------------------------------------------------
tensor([[13, 17, 14],
[10, 10, 16]])
--------------------------------------------------
tensor([[13, 17, 14],
[10, 10, 16]])
tensor([[-87, -83, -86],
[-90, -90, -84]])
tensor([[1300, 1700, 1400],
[1000, 1000, 1600]])
tensor([[0.1300, 0.1700, 0.1400],
[0.1000, 0.1000, 0.1600]])
tensor([[-13, -17, -14],
[-10, -10, -16]])
2. 阿達(dá)瑪積?
阿達(dá)瑪積指的是矩陣對應(yīng)位置的元素相乘.
import numpy as np
import torch
def test():
data1 = torch.tensor([[1, 2], [3, 4]])
data2 = torch.tensor([[5, 6], [7, 8]])
# 第一種方式
data = torch.mul(data1, data2)
print(data)
print('-' * 50)
# 第二種方式
data = data1 * data2
print(data)
print('-' * 50)
if __name__ == '__main__':
test()
程序輸出結(jié)果:
tensor([[ 5, 12],
[21, 32]])
--------------------------------------------------
tensor([[ 5, 12],
[21, 32]])
--------------------------------------------------
3. 點積運算?
點積運算要求第一個矩陣 shape: (n, m),第二個矩陣 shape: (m, p), 兩個矩陣點積運算 shape 為: (n, p)。
- 運算符 @ 用于進(jìn)行兩個矩陣的點乘運算
- torch.mm 用于進(jìn)行兩個矩陣點乘運算, 要求輸入的矩陣為2維
- torch.bmm 用于批量進(jìn)行矩陣點乘運算, 要求輸入的矩陣為3維
- torch.matmul 對進(jìn)行點乘運算的兩矩陣形狀沒有限定. - 對于輸入都是二維的張量相當(dāng)于 mm 運算.
- 對于輸入都是三維的張量相當(dāng)于 bmm 運算
- 對數(shù)輸入的 shape 不同的張量, 對應(yīng)的最后幾個維度必須符合矩陣運算規(guī)則
import numpy as np
import torch
# 1. 點積運算
def test01():
data1 = torch.tensor([[1, 2], [3, 4], [5, 6]])
data2 = torch.tensor([[5, 6], [7, 8]])
# 第一種方式
data = data1 @ data2
print(data)
print('-' * 50)
# 第二種方式
data = torch.mm(data1, data2)
print(data)
print('-' * 50)
# 第三種方式
data = torch.matmul(data1, data2)
print(data)
print('-' * 50)
# 2. torch.mm 和 torch.matmull 的區(qū)別
def test02():
# matmul 可以兩個維度可以不同
# 第一個張量: (3, 4, 5)
# 第二個張量: (5, 4)
# torch.mm 不可以相乘,而 matmul 則可以相乘
print(torch.matmul(torch.randn(3, 4, 5), torch.randn(5, 4)).shape)
print(torch.matmul(torch.randn(5, 4), torch.randn(3, 4, 5)).shape)
# 3. torch.mm 函數(shù)的用法
def test03():
# 批量點積運算
# 第一個維度為 batch_size
# 矩陣的二三維要滿足矩陣乘法規(guī)則
data1 = torch.randn(3, 4, 5)
data2 = torch.randn(3, 5, 8)
data = torch.bmm(data1, data2)
print(data.shape)
if __name__ == '__main__':
test01()
test02()
test03()
程序輸出結(jié)果:
tensor([[19, 22],
[43, 50],
[67, 78]])
--------------------------------------------------
tensor([[19, 22],
[43, 50],
[67, 78]])
--------------------------------------------------
tensor([[19, 22],
[43, 50],
[67, 78]])
--------------------------------------------------
torch.Size([3, 4, 4])
torch.Size([3, 5, 5])
torch.Size([3, 4, 8])
4. 指定運算設(shè)備?
PyTorch 默認(rèn)會將張量創(chuàng)建在 CPU 控制的內(nèi)存中, 即: 默認(rèn)的運算設(shè)備為 CPU。我們也可以將張量創(chuàng)建在 GPU 上, 能夠利用對于矩陣計算的優(yōu)勢加快模型訓(xùn)練。將張量移動到 GPU 上有兩種方法:
- 使用 cuda 方法
- 直接在 GPU 上創(chuàng)建張量
- 使用 to 方法指定設(shè)備
import torch
# 1. 使用 cuda 方法
def test01():
data = torch.tensor([10, 20 ,30])
print('存儲設(shè)備:', data.device)
# 如果安裝的不是 gpu 版本的 PyTorch
# 或電腦本身沒有 NVIDIA 卡的計算環(huán)境
# 下面代碼可能會報錯
data = data.cuda()
print('存儲設(shè)備:', data.device)
# 使用 cpu 函數(shù)將張量移動到 cpu 上
data = data.cpu()
print('存儲設(shè)備:', data.device)
# 輸出結(jié)果:
# 存儲設(shè)備: cpu
# 存儲設(shè)備: cuda:0
# 存儲設(shè)備: cpu
# 2. 直接將張量創(chuàng)建在 GPU 上
def test02():
data = torch.tensor([10, 20, 30], device='cuda:0')
print('存儲設(shè)備:', data.device)
# 使用 cpu 函數(shù)將張量移動到 cpu 上
data = data.cpu()
print('存儲設(shè)備:', data.device)
# 輸出結(jié)果:
# 存儲設(shè)備: cuda:0
# 存儲設(shè)備: cpu
# 3. 使用 to 方法
def test03():
data = torch.tensor([10, 20, 30])
print('存儲設(shè)備:', data.device)
data = data.to('cuda:0')
print('存儲設(shè)備:', data.device)
# 輸出結(jié)果:
# 存儲設(shè)備: cpu
# 存儲設(shè)備: cuda:0
# 4. 存儲在不同設(shè)備的張量不能運算
def test04():
data1 = torch.tensor([10, 20, 30], device='cuda:0')
data2 = torch.tensor([10, 20, 30])
print(data1.device, data2.device)
# RuntimeError: Expected all tensors to be on the same device,
# but found at least two devices, cuda:0 and cpu!
data = data1 + data2
print(data)
if __name__ == '__main__':
test04()
程序輸出結(jié)果:
存儲設(shè)備: cpu
存儲設(shè)備: cuda:0
存儲設(shè)備: cpu
存儲設(shè)備: cuda:0
存儲設(shè)備: cpu
存儲設(shè)備: cpu
存儲設(shè)備: cuda:0
cuda:0 cpu
5. 小節(jié)?
在本小節(jié)中,我們主要學(xué)習(xí)的主要內(nèi)容如下:
- 張量基本運算函數(shù) add、sub、mul、div、neg 等函數(shù), add_、sub_、mul_、div_、neg_ 等 inplace 函數(shù)
- 張量的阿達(dá)瑪積運算 mul 和運算符 * 的用法
- 點積運算: - 運算符 @ 用于進(jìn)行兩個矩陣的點乘運算
- torch.mm 用于進(jìn)行兩個矩陣點乘運算, 要求輸入的矩陣為2維
- torch.bmm 用于批量進(jìn)行矩陣點乘運算, 要求輸入的矩陣為3維
- torch.matmul 對進(jìn)行點乘運算的兩矩陣形狀沒有限定. - 對于輸入都是二維的張量相當(dāng)于 mm 運算.
- 對于輸入都是三維的張量相當(dāng)于 bmm 運算
- 對數(shù)輸入的 shape 不同的張量, 對應(yīng)的最后幾個維度必須符合矩陣運算規(guī)則
- 將變量移動到 GPU 設(shè)備的方法,例如: cuda 方法、直接在 GPU 上創(chuàng)建張量、使用 to 方法指定設(shè)備
3 張量類型轉(zhuǎn)換?
學(xué)習(xí)目標(biāo)?
- 掌握張量類型轉(zhuǎn)換方法
張量的類型轉(zhuǎn)換也是經(jīng)常使用的一種操作,是必須掌握的知識點。在本小節(jié),我們主要學(xué)習(xí)如何將 numpy 數(shù)組和 PyTorch Tensor 的轉(zhuǎn)化方法.
1. 張量轉(zhuǎn)換為 numpy 數(shù)組?
使用 Tensor.numpy 函數(shù)可以將張量轉(zhuǎn)換為 ndarray 數(shù)組,但是共享內(nèi)存,可以使用 copy 函數(shù)避免共享。
# 1. 將張量轉(zhuǎn)換為 numpy 數(shù)組
def test01():
data_tensor = torch.tensor([2, 3, 4])
# 使用張量對象中的 numpy 函數(shù)進(jìn)行轉(zhuǎn)換
data_numpy = data_tensor.numpy()
print(type(data_tensor))
print(type(data_numpy))
# 注意: data_tensor 和 data_numpy 共享內(nèi)存
# 修改其中的一個,另外一個也會發(fā)生改變
# data_tensor[0] = 100
data_numpy[0] = 100
print(data_tensor)
print(data_numpy)
if __name__ == '__main__':
test01()
2. numpy 轉(zhuǎn)換為張量?
- 使用 from_numpy 可以將 ndarray 數(shù)組轉(zhuǎn)換為 Tensor,默認(rèn)共享內(nèi)存,使用 copy 函數(shù)避免共享。
- 使用 torch.tensor 可以將 ndarray 數(shù)組轉(zhuǎn)換為 Tensor,默認(rèn)不共享內(nèi)存。
# 1. 使用 from_numpy 函數(shù)
def test01():
data_numpy = np.array([2, 3, 4])
# 將 numpy 數(shù)組轉(zhuǎn)換為張量類型
# 1. from_numpy
# 2. torch.tensor(ndarray)
# 淺拷貝
data_tensor = torch.from_numpy(data_numpy)
# nunpy 和 tensor 共享內(nèi)存
# data_numpy[0] = 100
data_tensor[0] = 100
print(data_tensor)
print(data_numpy)
# 2. 使用 torch.tensor 函數(shù)
def test02():
data_numpy = np.array([2, 3, 4])
data_tensor = torch.tensor(data_numpy)
# nunpy 和 tensor 不共享內(nèi)存
# data_numpy[0] = 100
data_tensor[0] = 100
print(data_tensor)
print(data_numpy)
if __name__ == '__main__':
test01()
test02()
3. 標(biāo)量張量和數(shù)字的轉(zhuǎn)換?
對于只有一個元素的張量,使用 item 方法將該值從張量中提取出來。
# 3. 標(biāo)量張量和數(shù)字的轉(zhuǎn)換
def test03():
# 當(dāng)張量只包含一個元素時, 可以通過 item 函數(shù)提取出該值
data = torch.tensor([30,])
print(data.item())
data = torch.tensor(30)
print(data.item())
if __name__ == '__main__':
test03()
程序輸出結(jié)果:
30
30
小節(jié)?
在本小節(jié)中, 我們主要學(xué)習(xí)了 numpy 和 tensor 互相轉(zhuǎn)換的規(guī)則, 以及標(biāo)量張量與數(shù)值之間的轉(zhuǎn)換規(guī)則。
4 張量拼接操作?
學(xué)習(xí)目標(biāo)?
- 掌握torch.cat torch.stack使用
張量的拼接操作在神經(jīng)網(wǎng)絡(luò)搭建過程中是非常常用的方法,例如: 在后面將要學(xué)習(xí)到的殘差網(wǎng)絡(luò)、注意力機(jī)制中都使用到了張量拼接。
1. torch.cat 函數(shù)的使用?
torch.cat 函數(shù)可以將兩個張量根據(jù)指定的維度拼接起來.
import torch
def test():
data1 = torch.randint(0, 10, [3, 5, 4])
data2 = torch.randint(0, 10, [3, 5, 4])
print(data1)
print(data2)
print('-' * 50)
# 1. 按0維度拼接
new_data = torch.cat([data1, data2], dim=0)
print(new_data.shape)
print('-' * 50)
# 2. 按1維度拼接
new_data = torch.cat([data1, data2], dim=1)
print(new_data.shape)
print('-' * 50)
# 3. 按2維度拼接
new_data = torch.cat([data1, data2], dim=2)
print(new_data.shape)
if __name__ == '__main__':
test()
程序輸出結(jié)果:
tensor([[[6, 8, 3, 5],
[1, 1, 3, 8],
[9, 0, 4, 4],
[1, 4, 7, 0],
[5, 1, 4, 8]],
[[0, 1, 4, 4],
[4, 1, 8, 7],
[5, 2, 6, 6],
[2, 6, 1, 6],
[0, 7, 8, 9]],
[[0, 6, 8, 8],
[5, 4, 5, 8],
[3, 5, 5, 9],
[3, 5, 2, 4],
[3, 8, 1, 1]]])
tensor([[[4, 6, 8, 1],
[0, 1, 8, 2],
[4, 9, 9, 8],
[5, 1, 5, 9],
[9, 4, 3, 0]],
[[7, 6, 3, 3],
[4, 3, 3, 2],
[2, 1, 1, 1],
[3, 0, 8, 2],
[8, 6, 6, 5]],
[[0, 7, 2, 4],
[4, 3, 8, 3],
[4, 2, 1, 9],
[4, 2, 8, 9],
[3, 7, 0, 8]]])
--------------------------------------------------
torch.Size([6, 5, 4])
--------------------------------------------------
torch.Size([3, 10, 4])
tensor([[[6, 8, 3, 5, 4, 6, 8, 1],
[1, 1, 3, 8, 0, 1, 8, 2],
[9, 0, 4, 4, 4, 9, 9, 8],
[1, 4, 7, 0, 5, 1, 5, 9],
[5, 1, 4, 8, 9, 4, 3, 0]],
[[0, 1, 4, 4, 7, 6, 3, 3],
[4, 1, 8, 7, 4, 3, 3, 2],
[5, 2, 6, 6, 2, 1, 1, 1],
[2, 6, 1, 6, 3, 0, 8, 2],
[0, 7, 8, 9, 8, 6, 6, 5]],
[[0, 6, 8, 8, 0, 7, 2, 4],
[5, 4, 5, 8, 4, 3, 8, 3],
[3, 5, 5, 9, 4, 2, 1, 9],
[3, 5, 2, 4, 4, 2, 8, 9],
[3, 8, 1, 1, 3, 7, 0, 8]]])
2. torch.stack 函數(shù)的使用?
torch.stack 函數(shù)可以將兩個張量根據(jù)指定的維度疊加起來.
import torch
def test():
data1= torch.randint(0, 10, [2, 3])
data2= torch.randint(0, 10, [2, 3])
print(data1)
print(data2)
new_data = torch.stack([data1, data2], dim=0)
print(new_data.shape)
new_data = torch.stack([data1, data2], dim=1)
print(new_data.shape)
new_data = torch.stack([data1, data2], dim=2)
print(new_data.shape)
if __name__ == '__main__':
test()
程序輸出結(jié)果:
tensor([[5, 8, 7],
[6, 0, 6]])
tensor([[5, 8, 0],
[9, 0, 1]])
torch.Size([2, 2, 3])
torch.Size([2, 2, 3])
torch.Size([2, 3, 2])
3. 小節(jié)?
張量的拼接操作也是在后面我們經(jīng)常使用一種操作。cat 函數(shù)可以將張量按照指定的維度拼接起來,stack 函數(shù)可以將張量按照指定的維度疊加起來。
5 張量索引操作?
學(xué)習(xí)目標(biāo)?
- 掌握張量不同索引操作
我們在操作張量時,經(jīng)常需要去進(jìn)行獲取或者修改操作,掌握張量的花式索引操作是必須的一項能力。
1. 簡單行、列索引?
準(zhǔn)備數(shù)據(jù)
import torch
data = torch.randint(0, 10, [4, 5])
print(data)
print('-' * 50)
程序輸出結(jié)果:
tensor([[0, 7, 6, 5, 9],
[6, 8, 3, 1, 0],
[6, 3, 8, 7, 3],
[4, 9, 5, 3, 1]])
--------------------------------------------------
# 1. 簡單行、列索引
def test01():
print(data[0])
print(data[:, 0])
print('-' * 50)
if __name__ == '__main__':
test01()
程序輸出結(jié)果:
tensor([0, 7, 6, 5, 9])
tensor([0, 6, 6, 4])
--------------------------------------------------
2. 列表索引?
# 2. 列表索引
def test02():
# 返回 (0, 1)、(1, 2) 兩個位置的元素
print(data[[0, 1], [1, 2]])
print('-' * 50)
# 返回 0、1 行的 1、2 列共4個元素
print(data[[[0], [1]], [1, 2]])
if __name__ == '__main__':
test02()
程序輸出結(jié)果:
tensor([7, 3])
--------------------------------------------------
tensor([[7, 6],
[8, 3]])
3. 范圍索引?
# 3. 范圍索引
def test03():
# 前3行的前2列數(shù)據(jù)
print(data[:3, :2])
# 第2行到最后的前2列數(shù)據(jù)
print(data[2:, :2])
if __name__ == '__main__':
test03()
程序輸出結(jié)果:
tensor([[0, 7],
[6, 8],
[6, 3]])
tensor([[6, 3],
[4, 9]])
4. 布爾索引?
# 布爾索引
def test():
# 第2列大于5的行數(shù)據(jù)
print(data[data[:, 2] > 5])
# 第1行大于5的列數(shù)據(jù)
print(data[:, data[1] > 5])
if __name__ == '__main__':
test04()
程序輸出結(jié)果:
tensor([[0, 7, 6, 5, 9],
[6, 3, 8, 7, 3]])
tensor([[0, 7],
[6, 8],
[6, 3],
[4, 9]])
5. 多維索引?
# 多維索引
def test05():
data = torch.randint(0, 10, [3, 4, 5])
print(data)
print('-' * 50)
print(data[0, :, :])
print(data[:, 0, :])
print(data[:, :, 0])
if __name__ == '__main__':
test05()
程序輸出結(jié)果:
tensor([[[2, 4, 1, 2, 3],
[5, 5, 1, 5, 0],
[1, 4, 5, 3, 8],
[7, 1, 1, 9, 9]],
[[9, 7, 5, 3, 1],
[8, 8, 6, 0, 1],
[6, 9, 0, 2, 1],
[9, 7, 0, 4, 0]],
[[0, 7, 3, 5, 6],
[2, 4, 6, 4, 3],
[2, 0, 3, 7, 9],
[9, 6, 4, 4, 4]]])
--------------------------------------------------
tensor([[2, 4, 1, 2, 3],
[5, 5, 1, 5, 0],
[1, 4, 5, 3, 8],
[7, 1, 1, 9, 9]])
tensor([[2, 4, 1, 2, 3],
[9, 7, 5, 3, 1],
[0, 7, 3, 5, 6]])
tensor([[2, 5, 1, 7],
[9, 8, 6, 9],
[0, 2, 2, 9]])
6 張量形狀操作?
學(xué)習(xí)目標(biāo)?
- 掌握reshape, transpose, permute, view, contigous, squeeze, unsqueeze等函數(shù)使用
在我們后面搭建網(wǎng)絡(luò)模型時,數(shù)據(jù)都是基于張量形式的表示,網(wǎng)絡(luò)層與層之間很多都是以不同的 shape 的方式進(jìn)行表現(xiàn)和運算,我們需要掌握對張量形狀的操作,以便能夠更好處理網(wǎng)絡(luò)各層之間的數(shù)據(jù)連接。
1. reshape 函數(shù)的用法?
reshape 函數(shù)可以在保證張量數(shù)據(jù)不變的前提下改變數(shù)據(jù)的維度,將其轉(zhuǎn)換成指定的形狀,在后面的神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)時,會經(jīng)常使用該函數(shù)來調(diào)節(jié)數(shù)據(jù)的形狀,以適配不同網(wǎng)絡(luò)層之間的數(shù)據(jù)傳遞。
import torch
import numpy as np
def test():
data = torch.tensor([[10, 20, 30], [40, 50, 60]])
# 1. 使用 shape 屬性或者 size 方法都可以獲得張量的形狀
print(data.shape, data.shape[0], data.shape[1])
print(data.size(), data.size(0), data.size(1))
# 2. 使用 reshape 函數(shù)修改張量形狀
new_data = data.reshape(1, 6)
print(new_data.shape)
if __name__ == '__main__':
test()
程序運行結(jié)果:
torch.Size([2, 3]) 2 3
torch.Size([2, 3]) 2 3
torch.Size([1, 6])
2. transpose 和 permute 函數(shù)的使用?
transpose 函數(shù)可以實現(xiàn)交換張量形狀的指定維度, 例如: 一個張量的形狀為 (2, 3, 4) 可以通過 transpose 函數(shù)把 3 和 4 進(jìn)行交換, 將張量的形狀變?yōu)?(2, 4, 3)
permute 函數(shù)可以一次交換更多的維度。
import torch
import numpy as np
def test():
data = torch.tensor(np.random.randint(0, 10, [3, 4, 5]))
print('data shape:', data.size())
# 1. 交換1和2維度
new_data = torch.transpose(data, 1, 2)
print('data shape:', new_data.size())
# 2. 將 data 的形狀修改為 (4, 5, 3)
new_data = torch.transpose(data, 0, 1)
new_data = torch.transpose(new_data, 1, 2)
print('new_data shape:', new_data.size())
# 3. 使用 permute 函數(shù)將形狀修改為 (4, 5, 3)
new_data = torch.permute(data, [1, 2, 0])
print('new_data shape:', new_data.size())
if __name__ == '__main__':
test()
程序運行結(jié)果:
data shape: torch.Size([3, 4, 5])
data shape: torch.Size([3, 5, 4])
new_data shape: torch.Size([4, 5, 3])
new_data shape: torch.Size([4, 5, 3])
3. view 和 contigous 函數(shù)的用法?
view 函數(shù)也可以用于修改張量的形狀,但是其用法比較局限,只能用于存儲在整塊內(nèi)存中的張量。在 PyTorch 中,有些張量是由不同的數(shù)據(jù)塊組成的,它們并沒有存儲在整塊的內(nèi)存中,view 函數(shù)無法對這樣的張量進(jìn)行變形處理,例如: 一個張量經(jīng)過了 transpose 或者 permute 函數(shù)的處理之后,就無法使用 view 函數(shù)進(jìn)行形狀操作。
import torch
import numpy as np
def test():
data = torch.tensor([[10, 20, 30], [40, 50, 60]])
print('data shape:', data.size())
# 1. 使用 view 函數(shù)修改形狀
new_data = data.view(3, 2)
print('new_data shape:', new_data.shape)
# 2. 判斷張量是否使用整塊內(nèi)存
print('data:', data.is_contiguous()) # True
# 3. 使用 transpose 函數(shù)修改形狀
new_data = torch.transpose(data, 0, 1)
print('new_data:', new_data.is_contiguous()) # False
# new_data = new_data.view(2, 3) # RuntimeError
# 需要先使用 contiguous 函數(shù)轉(zhuǎn)換為整塊內(nèi)存的張量,再使用 view 函數(shù)
print(new_data.contiguous().is_contiguous())
new_data = new_data.contiguous().view(2, 3)
print('new_data shape:', new_data.shape)
if __name__ == '__main__':
test()
程序運行結(jié)果:
data shape: torch.Size([2, 3])
new_data shape: torch.Size([3, 2])
data: True
new_data: False
True
new_data shape: torch.Size([2, 3])
4. squeeze 和 unsqueeze 函數(shù)的用法?
squeeze 函數(shù)用刪除 shape 為 1 的維度,unsqueeze 在每個維度添加 1, 以增加數(shù)據(jù)的形狀。
import torch
import numpy as np
def test():
data = torch.tensor(np.random.randint(0, 10, [1, 3, 1, 5]))
print('data shape:', data.size())
# 1. 去掉值為1的維度
new_data = data.squeeze()
print('new_data shape:', new_data.size()) # torch.Size([3, 5])
# 2. 去掉指定位置為1的維度,注意: 如果指定位置不是1則不刪除
new_data = data.squeeze(2)
print('new_data shape:', new_data.size()) # torch.Size([3, 5])
# 3. 在2維度增加一個維度
new_data = data.unsqueeze(-1)
print('new_data shape:', new_data.size()) # torch.Size([3, 1, 5, 1])
if __name__ == '__main__':
test()
程序運行結(jié)果:
data shape: torch.Size([1, 3, 1, 5])
new_data shape: torch.Size([3, 5])
new_data shape: torch.Size([1, 3, 5])
new_data shape: torch.Size([1, 3, 1, 5, 1])
5. 小節(jié)?
本小節(jié)帶著同學(xué)們學(xué)習(xí)了經(jīng)常使用的關(guān)于張量形狀的操作,我們用到的主要函數(shù)有:
- reshape 函數(shù)可以在保證張量數(shù)據(jù)不變的前提下改變數(shù)據(jù)的維度.
- transpose 函數(shù)可以實現(xiàn)交換張量形狀的指定維度, permute 可以一次交換更多的維度.
- view 函數(shù)也可以用于修改張量的形狀, 但是它要求被轉(zhuǎn)換的張量內(nèi)存必須連續(xù),所以一般配合 contiguous 函數(shù)使用.
- squeeze 和 unsqueeze 函數(shù)可以用來增加或者減少維度.
7 張量運算函數(shù)?
學(xué)習(xí)目標(biāo)?
- 掌握張量相關(guān)運算函數(shù)
1. 常見運算函數(shù)?
PyTorch 為每個張量封裝很多實用的計算函數(shù),例如計算均值、平方根、求和等等
import torch
def test():
data = torch.randint(0, 10, [2, 3], dtype=torch.float64)
print(data)
print('-' * 50)
# 1. 計算均值
# 注意: tensor 必須為 Float 或者 Double 類型
print(data.mean())
print(data.mean(dim=0)) # 按列計算均值
print(data.mean(dim=1)) # 按行計算均值
print('-' * 50)
# 2. 計算總和
print(data.sum())
print(data.sum(dim=0))
print(data.sum(dim=1))
print('-' * 50)
# 3. 計算平方
print(data.pow(2))
print('-' * 50)
# 4. 計算平方根
print(data.sqrt())
print('-' * 50)
# 5. 指數(shù)計算, e^n 次方
print(data.exp())
print('-' * 50)
# 6. 對數(shù)計算
print(data.log()) # 以 e 為底
print(data.log2())
print(data.log10())
if __name__ == '__main__':
test()
程序運行結(jié)果:
tensor([[4., 0., 7.],
[6., 3., 5.]], dtype=torch.float64)
--------------------------------------------------
tensor(4.1667, dtype=torch.float64)
tensor([5.0000, 1.5000, 6.0000], dtype=torch.float64)
tensor([3.6667, 4.6667], dtype=torch.float64)
--------------------------------------------------
tensor(25., dtype=torch.float64)
tensor([10., 3., 12.], dtype=torch.float64)
tensor([11., 14.], dtype=torch.float64)
--------------------------------------------------
tensor([[16., 0., 49.],
[36., 9., 25.]], dtype=torch.float64)
--------------------------------------------------
tensor([[2.0000, 0.0000, 2.6458],
[2.4495, 1.7321, 2.2361]], dtype=torch.float64)
--------------------------------------------------
tensor([[5.4598e+01, 1.0000e+00, 1.0966e+03],
[4.0343e+02, 2.0086e+01, 1.4841e+02]], dtype=torch.float64)
--------------------------------------------------
tensor([[1.3863, -inf, 1.9459],
[1.7918, 1.0986, 1.6094]], dtype=torch.float64)
tensor([[2.0000, -inf, 2.8074],
[2.5850, 1.5850, 2.3219]], dtype=torch.float64)
tensor([[0.6021, -inf, 0.8451],
[0.7782, 0.4771, 0.6990]], dtype=torch.float64)
8 自動微分模塊?
學(xué)習(xí)目標(biāo)?
- 掌握梯度計算
自動微分(Autograd)模塊對張量做了進(jìn)一步的封裝,具有自動求導(dǎo)功能。自動微分模塊是構(gòu)成神經(jīng)網(wǎng)絡(luò)訓(xùn)練的必要模塊,在神經(jīng)網(wǎng)絡(luò)的反向傳播過程中,Autograd 模塊基于正向計算的結(jié)果對當(dāng)前的參數(shù)進(jìn)行微分計算,從而實現(xiàn)網(wǎng)絡(luò)權(quán)重參數(shù)的更新。
1. 梯度基本計算?
我們使用 backward 方法、grad 屬性來實現(xiàn)梯度的計算和訪問.
import torch
# 1. 單標(biāo)量梯度的計算
# y = x**2 + 20
def test01():
# 定義需要求導(dǎo)的張量
# 張量的值類型必須是浮點類型
x = torch.tensor(10, requires_grad=True, dtype=torch.float64)
# 變量經(jīng)過中間運算
f = x ** 2 + 20
# 自動微分
f.backward()
# 打印 x 變量的梯度
# backward 函數(shù)計算的梯度值會存儲在張量的 grad 變量中
print(x.grad)
# 2. 單向量梯度的計算
# y = x**2 + 20
def test02():
# 定義需要求導(dǎo)張量
x = torch.tensor([10, 20, 30, 40], requires_grad=True, dtype=torch.float64)
# 變量經(jīng)過中間計算
f1 = x ** 2 + 20
# 注意:
# 由于求導(dǎo)的結(jié)果必須是標(biāo)量
# 而 f 的結(jié)果是: tensor([120., 420.])
# 所以, 不能直接自動微分
# 需要將結(jié)果計算為標(biāo)量才能進(jìn)行計算
f2 = f1.mean() # f2 = 1/2 * x
# 自動微分
f2.backward()
# 打印 x 變量的梯度
print(x.grad)
if __name__ == '__main__':
test01()
程序運行結(jié)果:
tensor(20., dtype=torch.float64)
tensor([ 5., 10., 15., 20.], dtype=torch.float64)
2. 控制梯度計算?
我們可以通過一些方法使得在 requires_grad=True 的張量在某些時候計算不進(jìn)行梯度計算。
import torch
# 1. 控制不計算梯度
def test01():
x = torch.tensor(10, requires_grad=True, dtype=torch.float64)
print(x.requires_grad)
# 第一種方式: 對代碼進(jìn)行裝飾
with torch.no_grad():
y = x ** 2
print(y.requires_grad)
# 第二種方式: 對函數(shù)進(jìn)行裝飾
@torch.no_grad()
def my_func(x):
return x ** 2
print(my_func(x).requires_grad)
# 第三種方式
torch.set_grad_enabled(False)
y = x ** 2
print(y.requires_grad)
# 2. 注意: 累計梯度
def test02():
# 定義需要求導(dǎo)張量
x = torch.tensor([10, 20, 30, 40], requires_grad=True, dtype=torch.float64)
for _ in range(3):
f1 = x ** 2 + 20
f2 = f1.mean()
# 默認(rèn)張量的 grad 屬性會累計歷史梯度值
# 所以, 需要我們每次手動清理上次的梯度
# 注意: 一開始梯度不存在, 需要做判斷
if x.grad is not None:
x.grad.data.zero_()
f2.backward()
print(x.grad)
# 3. 梯度下降優(yōu)化最優(yōu)解
def test03():
# y = x**2
x = torch.tensor(10, requires_grad=True, dtype=torch.float64)
for _ in range(5000):
# 正向計算
f = x ** 2
# 梯度清零
if x.grad is not None:
x.grad.data.zero_()
# 反向傳播計算梯度
f.backward()
# 更新參數(shù)
x.data = x.data - 0.001 * x.grad
print('%.10f' % x.data)
if __name__ == '__main__':
test01()
print('--------------------')
test02()
print('--------------------')
test03()
程序運行結(jié)果:
True
False
False
False
tensor([ 5., 10., 15., 20.], dtype=torch.float64)
tensor([ 5., 10., 15., 20.], dtype=torch.float64)
tensor([ 5., 10., 15., 20.], dtype=torch.float64)
3. 梯度計算注意?
當(dāng)對設(shè)置 requires_grad=True 的張量使用 numpy 函數(shù)進(jìn)行轉(zhuǎn)換時, 會出現(xiàn)如下報錯:
Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
此時, 需要先使用 detach 函數(shù)將張量進(jìn)行分離, 再使用 numpy 函數(shù).
注意: detach 之后會產(chǎn)生一個新的張量, 新的張量作為葉子結(jié)點,并且該張量和原來的張量共享數(shù)據(jù), 但是分離后的張量不需要計算梯度。
import torch
# 1. detach 函數(shù)用法
def test01():
x = torch.tensor([10, 20], requires_grad=True, dtype=torch.float64)
# Can't call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead.
# print(x.numpy()) # 錯誤
print(x.detach().numpy()) # 正確
# 2. detach 前后張量共享內(nèi)存
def test02():
x1 = torch.tensor([10, 20], requires_grad=True, dtype=torch.float64)
# x2 作為葉子結(jié)點
x2 = x1.detach()
# 兩個張量的值一樣: 140421811165776 140421811165776
print(id(x1.data), id(x2.data))
x2.data = torch.tensor([100, 200])
print(x1)
print(x2)
# x2 不會自動計算梯度: False
print(x2.requires_grad)
if __name__ == '__main__':
test01()
test02()
程序運行結(jié)果:
10. 20.]
140495634222288 140495634222288
tensor([10., 20.], dtype=torch.float64, requires_grad=True)
tensor([100, 200])
False
4. 小節(jié)?
本小節(jié)主要講解了 PyTorch 中非常重要的自動微分模塊的使用和理解。我們對需要計算梯度的張量需要設(shè)置 requires_grad=True 屬性,并且需要注意的是梯度是累計的,在每次計算梯度前需要先進(jìn)行梯度清零。
10 模型的保存加載?
學(xué)習(xí)目標(biāo)?
- 掌握PyTorch保存模型的方法
- 神經(jīng)網(wǎng)絡(luò)的訓(xùn)練有時需要幾天, 幾周, 甚至幾個月, 為了在每次使用模型時避免高代價的重復(fù)訓(xùn)練, 我們就需要將模型序列化到磁盤中, 使用的時候反序列化到內(nèi)存中.
1: 保存模型參數(shù)?
import torch
import torch.nn as nn
# 假設(shè)我們有一個模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
model = SimpleModel()
# 保存模型的參數(shù)
torch.save(model.state_dict(), 'model_weights.pth')
?
2: 保存全部模型?
import torch
import torch.nn as nn
# 假設(shè)我們有一個模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
model = SimpleModel()
# 保存全部模型
torch.save(model, 'model.pth')
3: 加載模型參數(shù)?
# 創(chuàng)建一個與保存時相同結(jié)構(gòu)的模型
model = SimpleModel()
# 加載模型的參數(shù)
model.load_state_dict(torch.load('model_weights.pth'))
print(model)
4: 加載全部模型?
model = torch.load('model.pth')
print(model)
- 注意??:
- 模型結(jié)構(gòu): 如果你只保存了模型的參數(shù), 那么在加載時需要確保你有與保存時相同的模型結(jié)構(gòu).
- 設(shè)備兼容性: 如果你在一個設(shè)備上保存了模型(例如GPU), 而在另一個設(shè)備上加載(例如CPU), 你可能需要使用
map_location參數(shù)來指定設(shè)備. device = torch.device('cpu') model.load_state_dict(torch.load('model_weights.pth', map_location=device))

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號