day000 ML串講
numpy模塊
- numpy模塊的主要作用:
- numpy表示一維或者多維的數組(容器),主要是用來存儲和運算數值型數據的。
- 常用屬性:
- shape:返回數組的形狀
- ndim:返回數組的維度
- size:返回數組元素的個數
- dtype:返回數組元素的數據類型。
- 只可存儲相同類型的數據。
- 數組元素類型的修改:
- arr.astype('float'),將arr這個數組的數組元素類型修改為float類型
- 數組級聯(concatnate函數):
- 可以將兩個或者兩個以上的數組進行橫向或者縱向的拼接。
- 變形(reshape函數):
- 可以將創建好的數組的形狀進行變換。
- 舉例:arr是一個3行4列的二維數組,通過reshape函數將arr數組變形成2行6列or1行12列...
- 注意:數組變形前和變形后數組的容量不可以發生變化。
- 統計函數:
- std():標準差
- var():方差
- median():中位數
- 。。。
- 索引和切片:
- 通過索引和切片的機制可以定位捕獲到數組中任意指定的相關元素。
- 索引操作:
- arr[index]:取出index表示的行
- arr[:,col]:取出col表示的列
- arr[index,col]:取出index行和col列對應的相關元素
- 切片操作:
- arr[index1:indexn]:切行
- arr[:,col1:coln]:切列
pandas模塊
- pandas模塊中兩個常用的類:
- Series:一維結構
- DataFrame:二維表格結構
- 多個Series可以組成一個DataFrame
- Series常用操作:
- isnull():可以判定Series中的每一個元素是否為空,如果為空則返回一個True,否則返回False
- notnull():可以判定Series中的每一個元素是否為非空,如果為非空則返回True,否則返回False
- 布爾值是可以作為Series的索引來使用的。True對應的元素會被保留,False對應的元素會被忽略
- s = Series([1,2,3])使用布爾值作為s的索引s[[True,False,True]]取出的元素為[1,3]
- unique():可以對Series中存儲的元素進行去重操作,返回去重后的結果。
- nunique():可以返回對Series元素進行去重后的元素個數
- value_counts():可以對Series中的每一個元素出現的次數進行統計。
- DataFrame常用操作:
- 索引操作:
- 索引取單列:df[col]取出col表示的一列數據
- 索引取多列:df[[col1,col2]]取出col1和col2兩列數據
- 索引取單行:df.iloc/loc[index]取出index表示的一行數據
- 索引取多行:df.iloc/loc[[index1,index2]]取出index1和index2兩行數據
- 索引取元素:df.iloc/loc[index,col]取出index行col列對應的相關元素
- 切片操作
- 切行:df[index1:indexn]
- 切列:df.iloc/loc[:,col1:coln]
- 時間類型的轉換:
- pd.to_datetime(df[col])可以將df的col列的數據類型轉換成時間類型
- 將指定的一列作為源數據的行索引
- df.set_index('col_name'):可以將df中的col_name這一列作為df的行索引來使用
- df的數據加載
- pd.read_xxx():read_csv(),read_sql(),read_excel()
- df的數據保存
- df.to_xxx():to_csv(),to_excel()
- 指定數據的刪除:
- df.drop(index,columns):可以將index表示的行或者columns表示的列在df表格中進行刪除
- 排序:
- sort_index():根據索引排序
- sort_values():根據值排序
- 級聯操作concat:對兩個或者多個df進行橫向或者縱向的拼接
- 可以將兩個或者df表格進行橫向或者縱向拼接
- 合并操作merge:對兩個df中的數據進行合并
- 替換操作replace:
- 可以將df表格中的指定元素進行替換操作
- map函數:只可以被Series調用
- 映射:df['name'].map(dic)可以使用dic表示的映射關系表對df的name列的每一個元素進行映射操作
- 充當運算工具:df['salary'].map(func)可以使用func這個自定義函數對df中salary列的每一個元素進行運算操作。
- 分組操作:groupby
- 高級分組聚合:
- 自定義分組后的聚合函數,可以通過apply函數在分組后使用自定義的函數對分組結果進行聚合操作
- agg:可以將分組結果進行多種不同形式的聚合操作
- df.groupby(by='item')['price'].agg(['max','sum'])
- 透視表:pivot_table
- index
- values
- aggfunc
- columns
- df.apply(func,axis):
- 可以對df這個表格中的行或者列進行func形式的處理和運算
- df.applymap(func):
- 可以對df這個表格中的每一個元素進行處理和運算
- 索引操作:
matplotlib
- 折線圖
- plt.plot(x,y)
- 柱狀圖
- plt.bar(x,hight)
- 直方圖
- plt.hist(x)
- 餅圖
- plt.pie(x)
- 散點圖
- ple.scanter(x,y)
深入理解機器學習:
-
算法模型對象:
- 一種特殊的對象,特殊之處在于,該對象內部集成/封裝了某種形式的算法/方程。該算法/方程用于找尋數據間的規律。假設某一個模型內部封裝的算法/方程如下:
- y = w * x + b,這是一個還沒有求出解的方程式。
- 一種特殊的對象,特殊之處在于,該對象內部集成/封裝了某種形式的算法/方程。該算法/方程用于找尋數據間的規律。假設某一個模型內部封裝的算法/方程如下:
-
樣本數據:
- 特征數據:自變量(一個樣本的描述信息)
- 標簽數據:因變量(一個樣本數據的結果)

-
模型的訓練:
- 將樣本數據帶入到算法模型對象內部的算法/方程中,對算法/方程進行求解操作。
- 在該算法/方程中 y = w * x + b,如果求出了w和b則方程就可有解。
- 模型訓練就是在使用算法/方程找尋樣本數據之間的規律。
-
模型的作用:
- 對未知樣本實現預測、分類或者決策。
- 算法/方程的解就是模型實現分類或者預測的結果。
-
算法模型的分類:
- 有監督類別:
- 有監督學習是指使用帶有標簽的樣本數據來訓練模型
- 無監督類別:
- 無監督學習是指使用沒有標簽的樣本的數據訓練模型
- 有監督類別:
KNN分類算法原理
簡單地說,KNN算法是采用測量不同特征值之間的距離方法進行分類。大家可以類別:近朱者赤近墨者黑這句話進行理解。
下面,我們就詳細來理解下KNN的分類原理,先看下圖:w1(貓)、w2(狗)和w3(兔子)是三個已知類群,X則是一個未知類別的圖片樣本,現在要基于KNN算法將X樣本分到w1、w2和w3其中的一個類別中,以確定X圖片中的動物到底是貓、狗還是兔子。

根據我們的直接感受,應該是衡量X樣本距離w1、w2和w3哪個類群最近,則X樣本就應該被分到哪個類別中。這個是不是就好比與:近朱者赤近墨者黑呢。那么,KNN究竟是如何實現的分類呢?
實現步驟:
- 算距離:KNN算法會計算X樣本到其余所有樣本之間的距離。(有幾個其余樣本就會計算幾次距離)
- 找近鄰:定義一個k值,找出離X最近的k個樣本最為X最近的k個鄰居。注意,k值是需要認為定義的一個數值。
- 投票:根據k個最近的鄰居樣本的類別標簽進行投票,哪個類別的標簽得票最多(在k個樣本中哪個類別樣本數量最多),則X樣本就歸屬到該類別中。
注意:不同的k,可能會造成不同的分類結果
在下圖中,如果k為3則小球的分類結果為三角形,k為5則分類結果為正方形。因此,k值的最優選擇在KNN中是比較重要的一個環節,稍后會詳細進行講解說明。

距離計算方式:
可以是歐式距離、曼卡頓距離或者閔可夫斯基距離等方式。

電影分類
眾所周知,電影可以按照題材分類,然而題材本身是如何定義的?由誰來判定某部電影屬于哪個題材?也就是說同一題材的電影具有哪些公共特征?這些都是在進行電影分類時必須要考慮的問題。下面我們就一起來探究下電影如何實現分類?
| 電影名稱 | 打斗鏡頭 | 接吻鏡頭 | 電影類型 |
|---|---|---|---|
| California Man | 3 | 104 | 愛情片 |
| He Not Really into Dudes | 2 | 100 | 愛情片 |
| Beautiful Woman | 1 | 81 | 愛情片 |
| Kevin Longblade | 101 | 10 | 動作片 |
| Robo Slayer 3000 | 99 | 5 | 動作片 |
| Amped 2 | 98 | 2 | 動作片 |
| ? | 18 | 90 | 未知 |
采集到了一組電影的樣本數據,每一個電影樣本有兩個特征維度:打斗鏡頭和接吻鏡頭,電影類型為目標數據,有愛情和動作兩種類別。其中有一部未知類別的電影"?",并且提取到了該電影的打斗和接吻鏡頭的數量。接下來,使用KNN來計算電影 “?” 的特征到其他已知類型電影特征之間的距離。
下面可以,觀測下具體的距離顯示:

根據歐式距離,進行距離計算結果如下:
| 電影名稱 | 與未知類型電影“?”的距離 |
|---|---|
| California Man | 20.5 |
| He Not Really into Dudes | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped 2 | 118.9 |
制定k的值,找到電影 “ ?”周圍最近的k個鄰居,假定k的值為3,則離其最近的3個鄰居是:
| 電影名稱 | 電影類型 |
|---|---|
| California Man | 愛情片 |
| He Not Really into Dudes | 愛情片 |
| Beautiful Woman | 愛情片 |
投票:最近的3個鄰居種,愛情類別的得票最多,因此 “ ?”電影的類別被KNN劃分到了愛情片類別。
何為回歸?
- 回歸問題判定:
- 回歸問題對應的樣本數據的標簽數據是連續性的值,而分類問題對應的是離散型的值。
- 在社會中產生的數據必然是離散型或者是連續型的數據,那么企業針對數據所產生的需求也無非是分類問題或者回歸問題。
- 常見的回歸問題:
- 預測房價
- 銷售額的預測
- 貸款額度指定
- ......
線性回歸在生活中的映射
- 學生期末成績制定
- 總成績 = 0.7 * 考試成績 + 0.3 * 平時成績
- 則該例子中,特征值為考試成績和平時成績,目標值為總成績。從此案例中大概可以感受到
- 回歸算法預測出來的結果其實就是經過相關的算法計算出來的結果值!
- 每一個特征需要有一個權重的占比,這個權重的占比明確后,則就可以得到最終的計算結果,也就是獲取了最終預測的結果了。
- 那么這個特征對應的權重如何獲取或者如何制定呢?
現在有一組售房數據:
| 面積 | 售價 |
|---|---|
| 55 | 110 |
| 76 | 152 |
| 80 | 160 |
| 100 | 200 |
| 120 | 240 |
| 150 | 300 |
對售房數據的分布情況進行展示

問題:假如現在有一套房子,面積為76.8平米,那么這套房子應該賣多少錢呢?也就是如何預測該套房子的價錢呢?上圖中散點的分布情況就是面積和價錢這兩個值之間的關系,那么如果該關系可以用一種分布趨勢來表示的話,那么是不是就可以通過這分布趨勢預測出新房子的價格呢?
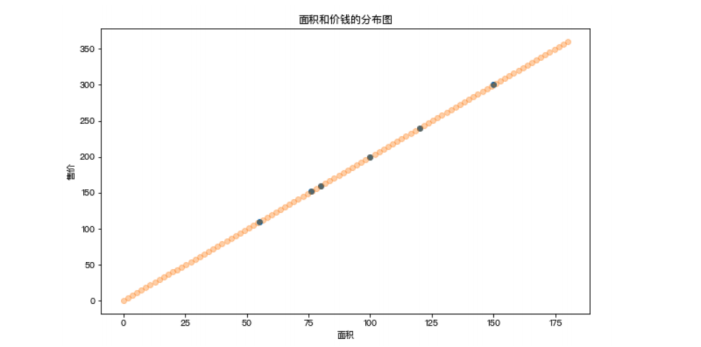
在上圖中使用了一條直線來表示了房子的價格和面積對應的分布趨勢,那么該趨勢找到后,就可以基于該趨勢根據新房子的面積預測出新房子的價格。
線性回歸的作用:找出特征和目標之間存在的某種趨勢,在二維平面中,該種趨勢可以用一條線段來表示,該條線段用一元一次線性方程來表示:y = w * x + b。
將上述的售房數據,帶入到線性方程中,經過求解,w和b變為了已知,現在方程為:y = 2 * x + 0。則發現,在上述售房數據中,面積和價格之間的關系是二倍的關系,其實就可以映射成:價格 = 2 * 面積 ,這個方程就是價格和面積的分布趨勢,也就是說根據該方程就可以進行新房子價格的預測。
損失函數
如果在房價預測案例中,房子的面積和價格的分布規律如下圖所示(非線性的分布),那是否還可以使用一條直線表示特征和目標之間的趨勢呢?

可以,只要保證直線距離所有的散點距離最近,則該直線還是可以在一定程度上表示非線性分布散點之間的分布規律。但是該規律進行的預測會存在一定的誤差/損失!
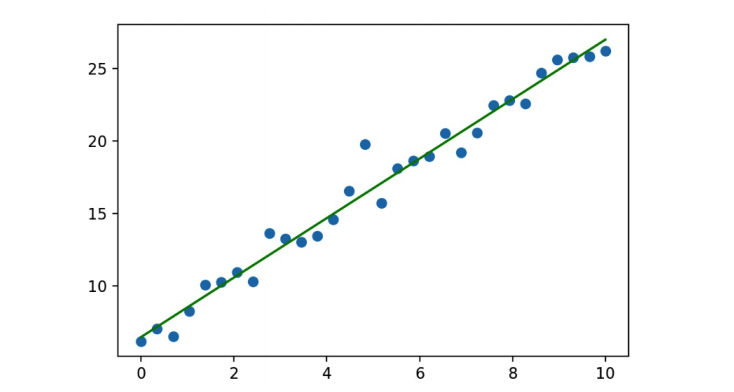
在多數的預測場景中,預測結果和真實結果之間都會存在一定的誤差,那么誤差存在,我們應該如何處理損失/誤差呢?
量化損失/損失函數:真實結果y和預測結果(xw)差異平方的累加和(誤差平方和/殘差平方和):
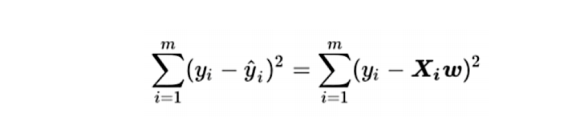
提問:損失函數公式中,誤差的大小和哪個系數有直系的關聯呢?
答案:和權重系數w是有直系關聯。也就是說w的不同會導致誤差大小的不同,那么線性回歸算法迭代訓練過程中最終的問題就轉化成了如何去求解線性方程中的w使得誤差可以最小。
無監督學習與聚類算法
-
概述
- 在此之前我們所學習到的算法模型都是屬于有監督學習的模型算法,即模型需要的樣本數據既需要有特征矩陣X,也需要有真實的標簽y。那么在機器學習中也有一部分的算法模型是屬于無監督學習分類的,所謂的無監督學習是指模型只需要使用特征矩陣X即可,不需要真實的標簽y。那么聚類算法就是無監督學習中的代表之一。
-
聚類算法
-
聚類算法其目的是將數據劃分成有意義或有用的組(或簇)。這種劃分可以基于我們的業務 需求或建模需求來完成,也可以單純地幫助我們探索數據的自然結構和分布。比如在商業中,如果我們手頭有大量 的當前和潛在客戶的信息,我們可以使用聚類將客戶劃分為若干組,以便進一步分析和開展營銷活動。

-
KMeans算法原理闡述
-
簇與質心:
- 簇:KMeans算法將一組N個樣本的特征矩陣X劃分為K個無交集的簇,直觀上來看是簇是一個又一個聚集在一起的數 據,在一個簇中的數據就認為是同一類。簇就是聚類的結果表現。
- 質心:簇中所有數據的均值u通常被稱為這個簇的“質心”(centroids)。
- 在一個二維平面中,一簇數據點的質心的橫坐標就是這一簇數據點的橫坐標的均值,質心的縱坐標就是這一簇數據點的縱坐標的均值。同理可推廣至高維空間。
- 質心的個數也聚類后的類別數是一致的
-
在KMeans算法中,簇的個數K是一個超參數,需要我們人為輸入來確定。KMeans的核心任務就是根據我們設定好的K,找出K個最優的質心,并將離這些質心最近的數據分別分配到這些質心代表的簇中去。具體過程可以總結如下:

- 那什么情況下,質心的位置會不再變化呢?當我們找到一個質心,在每次迭代中被分配到這個質心上的樣本都是一致的,即每次新生成的簇都是一致的,所有的樣本點都不會再從一個簇轉移到另一個簇,質心就不會變化了。
-
這個過程在可以由下圖來顯示,我們規定,將數據分為4簇(K=4),其中白色X代表質心的位置:

-
聚類算法聚出的類有什么含義呢?這些類有什么樣的性質?
- 我們認為,被分在同一個簇中的數據是有相似性的,而不同簇中的數據是不同的,當聚類完畢之后,我們就要分別去研究每個簇中的樣本都有什么樣的性質,從而根據業務需求制定不同的商業或者科技策略。
- 聚類算法追求“簇內差異小,簇外差異 大”:
- 而這個“差異“,由樣本點到其所在簇的質心的距離來衡量。
-
對于一個簇來說,所有樣本點到質心的距離之和越小,我們就認為這個簇中的樣本越相似,簇內差異就越小。而距離的衡量方法有多種,令x表示簇中的一個樣本點,u表示該簇中的質心,n表示每個樣本點中的特征數目,i表示組成點的每個特征,則該樣本點到質心的距離可以由以下距離來度量:

輪廓系數
-
在99%的情況下,我們是對沒有真實標簽的數據進行探索,也就是對不知道真正答案的數據進行聚類。這樣的聚 類,是完全依賴于評價簇內的稠密程度(簇內差異小)和簇間的離散程度(簇外差異大)來評估聚類的效果。其中 輪廓系數是最常用的聚類算法的評價指標。它是對每個樣本來定義的,它能夠同時衡量:
- 1)樣本與其自身所在的簇中的其他樣本的相似度a,等于樣本與同一簇中所有其他點之間的平均距離
- 2)樣本與其他簇中的樣本的相似度b,等于樣本與下一個最近的簇中的所有點之間的平均距離 根據聚類的要求”簇內差異小,簇外差異大“,我們希望b永遠大于a,并且大得越多越好。
- 單個樣本的輪廓系數計算為:
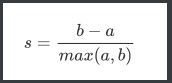
-
很容易理解輪廓系數范圍是(-1,1):
- 其中值越接近1表示樣本與自己所在的簇中的樣本很相似,并且與其他簇中的樣本不相似,當樣本點與簇外的樣本更相似的時候,輪廓系數就為負。
- 當輪廓系數為0時,則代表兩個簇中的樣本相似度一致,兩個簇本應該是一個簇。可以總結為輪廓系數越接近于1越好,負數則表示聚類效果非常差。
-
如果一個簇中的大多數樣本具有比較高的輪廓系數,則簇會有較高的總輪廓系數,則整個數據集的平均輪廓系數越高,則聚類是合適的:
- 如果許多樣本點具有低輪廓系數甚至負值,則聚類是不合適的,聚類的超參數K可能設定得 太大或者太小。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號