
別再說我不懂Node"流"了
Nodejs中包括4種類型的流:
Readable、Writable、Duplex和Transform.
Readable Stream
自定義Readable
自定義 Readable 流必須調用 new stream.Readable([options]) 構造函數并實現 readable._read() 方法。
import { Readable } from "node:stream";
const readable = new Readable();
readable.on("data", (chunk) => {
console.log(chunk.toString());
});
readable.on('end', () => {
console.log('end');
})
readable.on('error', (err) => {
console.log('error-> ', err);
})
此時會觸發error事件
error-> Error [ERR_METHOD_NOT_IMPLEMENTED]: The _read() method is not implemented
因此要創建一個正常工作的Readable,需要實現_read方法,有三種方式實現自定義Readable流(Node的4種流都可以通過下面三種形式實現)。
方式一、在Readable實例上掛載_read方法
const readable = new Readable();
readable._read = function(){
this.push("hello world"); //寫入readable的緩沖區
this.push(null)
}
方式二、Readable初始化給options參數傳遞read(這個相當于_read方法)
const readable = new Readable({
read(){
this.push("hello world");
this.push(null)
}
});
方式三、繼承時實現_read
class MyReadable extends Readable {
_read(){
this.push("hello world");
this.push(null)
}
}
const readable = new MyReadable();
解釋 _read 被調用的時機
在 Node.js 的流(Stream)API 中,_read 方法是 Readable 流的核心內部方法,它的調用時機主要有以下幾點:
- 當消費者調用
stream.read()方法時:當外部代碼通過read()方法請求數據時,如果內部緩沖區沒有足夠的數據,Node.js 會調用_read方法來獲取更多數據。 - 當消費者添加 'data' 事件監聽器時:當你為 Readable 流添加 'data' 事件監聽器時,流會自動切換到流動模式(flowing mode),此時會自動調用
_read方法開始獲取數據。 - 當流從暫停模式切換到流動模式時:例如通過調用
resume()方法時,會觸發_read的調用。 - 初始化流時:在某些情況下,當流被創建并進入流動模式時,
_read方法會被自動調用一次來填充初始數據。
_read 方法的工作原理是:
- 它負責從底層資源(如文件、網絡等)獲取數據
- 通過調用
this.push(chunk)將數據放入流的內部緩沖區 - 當沒有更多數據時,調用
this.push(null)表示流結束
Readable兩種模式和三種狀態
兩種模式
- 流動模式(flowing mode)。流會自動從內部緩沖區中讀取并觸發
'data'事件,當緩存中沒有數據時則調用_read把數據放入緩沖區。 - 暫停模式(paused mode)。流不會自動觸發
'data'事件,數據會留在內部緩沖區,通過顯示readable.read()獲取數據。
三種狀態
具體來說,在任何給定的時間點,每個
Readable都處于三種可能的狀態之一:
readable.readableFlowing === nullreadable.readableFlowing === falsereadable.readableFlowing === true
當
readable.readableFlowing為null時,則不提供消費流數據的機制。因此,流不會生成數據。在此狀態下,為'data'事件綁定監聽器、調用readable.pipe()方法、或調用readable.resume()方法會將readable.readableFlowing切換到true,從而使Readable在生成數據時開始主動觸發事件。
調用
readable.pause()、readable.unpipe()或接收背壓將導致readable.readableFlowing設置為false,暫時停止事件的流動但不會停止數據的生成。在此狀態下,為'data'事件綁定監聽器不會將readable.readableFlowing切換到true。
總結:
| 值 | 狀態描述 |
|---|---|
null |
暫停模式(默認),流既沒有開始自動流動數據,也沒有明確被暫停或恢復。數據會被緩存在內部緩沖區中,直到你明確開始消費。 |
true |
流動模式(flowing mode) 自動消費 |
false |
暫停模式(paused mode) 不會自動消費,需要顯式調用read()消費 |
流動模式示例:
const readable = Readable.from(['A', 'B', 'C']);
// 監聽了'data'事件,此時readableFlowing === true
readable.on('data', (chunk) => {
console.log('Got chunk:', chunk);
/*
Got chunk: A
Got chunk: B
Got chunk: C
*/
});
readable.on('end', () => {
console.log('end'); //end (流結束,不會再有新數據)
})
暫停模式示例:
const readable = Readable.from(['A', 'B', 'C']);
// ?? 此時 readableFlowing === null
readable.on('readable', () => {
let chunk;
while (null !== (chunk = readable.read())) {
console.log('Got chunk:', chunk);
}
/*
Got chunk: A
Got chunk: B
Got chunk: C
*/
});
readable.on('end', () => {
console.log('end'); //end (流結束,不會再有新數據)
})
P.S. readable.read()需要在'readable'事件中讀取數據,因為在外面調用可能返回 null :如果在 'readable' 事件觸發之前或者當內部緩沖區為空時調用 read() ,它會返回 null ,表示當前沒有數據可讀。
Readable的事件和方法
事件
'data': 接受數據chunk(非對象模式下是Buffer或String), 數據在可用時會立即觸發該事件。'end': 當流中沒有更多數據了(比如this.push(null)),可由readable.end()觸發。close: 當流及其任何底層資源(例如文件描述符)已關閉時,則會觸發'close'事件。該事件表明將不再觸發更多事件,并且不會發生進一步的計算。默認情況下readable.destroy()會觸發close事件。'error': 低層流由于低層內部故障導致無法生成或者推送無效數據時,觸發。'readable': 當有數據可從流中讀取時,將觸發'readable'事件。'pause': 當調用readable.pause()并且readableFlowing不是false時,則會觸發'pause'事件。
方法
| 方法 | 說明 |
|---|---|
read([size]) |
從可讀緩沖區中取出數據 |
pipe(dest) / unpipe() |
管道傳輸 |
pause() / resume() |
控制流動模式 |
unshift(chunk) |
將數據重新放回可讀緩沖 |
push(chunk) |
向可讀端推送數據(用于自定義實現) |
from(iterable[, options]) |
從迭代對象中創建流 |
下面著重介紹下pipe和from
1.Readable.pipe(destination[, options]) 第一個參數destination是一個寫入流(或者Duplex/Transform,對應到其寫入流部分),這個方法將使Readable自動切換到流動模式并將其所有數據推送到綁定的 Writable`。
示例:
const fs = require('node:fs');
const readable = getReadableStreamSomehow();
const writable = fs.createWriteStream('file.txt');
// readable的數據自動寫入writable
readable.pipe(writable);
2.Readable.from(iterable[, options])
第一個參數是實現 Symbol.asyncIterator 或 Symbol.iterator 可迭代協議的對象。如果傳遞空值,則觸發 'error' 事件。默認情況下,Readable.from() 會將 options.objectMode 設置為 true,這意味著每次讀取數據都是一個Javascript值。
import { Readable } from 'node:stream';
async function * generate() {
yield 'hello';
yield {name: 'streams'};
}
const readable = Readable.from(generate());
readable.on('data', (chunk) => {
console.log(chunk);
/*
hello
{ name: 'streams' }
*/
});
繼承了Readable的Node API
Readable 流的示例包括:
- 客戶端上的 HTTP 響應
- 服務器上的 HTTP 請求
- 文件系統讀取流
- TCP 套接字
- 子進程標準輸出和標準錯誤
- process.stdin
文件系統讀取流示例:
首先使用readFile一次性讀取數據,這個時候如果是大文件,那么會占用非常大的內存。
// 方式一
fs.readFile(path.resolve(__dirname, './bigdata.txt'), 'utf8', (err, data) => {
if (err) {
console.error('讀取文件時出錯:', err);
return;
}
console.log('文件內容:');
console.log(data)
});
接下來我們創建一個流來讀數據,分批次讀取數據。
const readStream = fs.createReadStream(path.resolve(__dirname, './bigdata.txt'), {
encoding: 'utf8',
highWaterMark: 4, // 每次讀取4個字節 (故意設置很小,方便觀察)
});
readStream.on('data', (chunk) => {
console.log('讀取到的數據:', chunk);
});
readStream.on('end', () => {
console.log('文件讀取完成');
});
readStream.on('error', (err) => {
console.error('讀取文件時出錯:', err);
});
如下圖所示,流的方式讀取數據是分批次的。
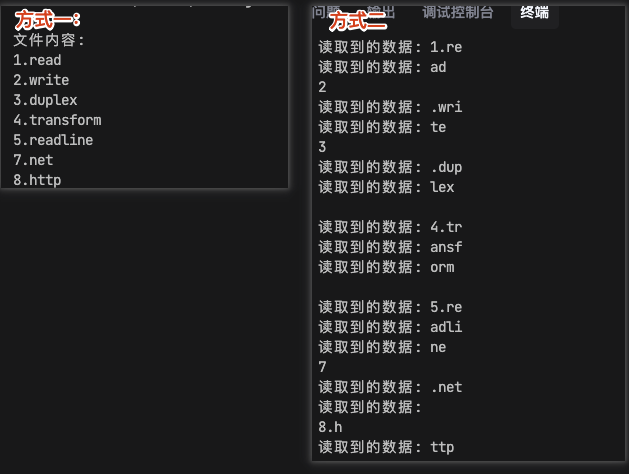
但上述做法并不能真正解決大文件占用大內存,因為面臨流的背壓問題(大意就是讀的快,寫的慢導致讀入的數據積壓在輸入緩沖區,后面「緩沖區、高壓線和背壓問題」一小節會探究這個問題)。
可以用pipe來處理,代碼如下:
const readStream = fs.createReadStream(path.resolve(__dirname, './bigdata.txt'), {
encoding: 'utf8',
highWaterMark: 4, // 每次讀取4個字節
});
// 使用pipe連接可讀流和可寫流
readStream.pipe(process.stdout);
依舊是每次讀4個字節寫入可寫流,但pipe會自動處理背壓問題。
Writable Stream
自定義Writable
和實現Readable類似,自定義實現Writable,需要實現_write方法。
import {Writable} from 'node:stream';
class MyWritable extends Writable {
_write(chunk:any, encoding:BufferEncoding, next:()=>void) {
console.log('Got chunk:', chunk.toString());
setTimeout(()=>{
next();
}, 1000)
}
}
const writable = new MyWritable();
writable.write('hello writable'); //寫入writable的緩沖區
解釋 _write 被調用的時機
Writable通過調用內部方法_write 實際處理寫入數據。它接受三個參數:
chunk是any,encoding的編碼模式決定了chunk具體是什么(Buffer還是字符串等)encoding是BufferEncoding類型,包括"ascii" | "utf8" | "utf-8" | "utf16le" | "utf-16le" | "ucs2" | "ucs-2" | "base64" | "base64url" | "latin1" | "binary" | "hex"。還有可能是'buffer'(下面會介紹到)。next函數是一個回調函數,它在_write方法中扮演著非常重要的角色- 信號作用 :調用 next() 表示當前數據塊已經處理完成,流可以繼續處理下一個數據塊
- 流控制 :如果不調用 next() ,流會認為數據還在處理中,不會繼續處理緩沖區中的其他數據
- 錯誤處理 :如果處理過程中出現錯誤,可以調用 next(error) 來通知流發生了錯誤
writable.write(data) 僅是將數據寫入內部緩沖區(此時不一定調用_write方法),當數據從內部緩沖區被消費時才會調用_write方法。
writable.write可以快速寫入多個,但是當_write需要next被調用后才能處理緩沖區的下一個數據,所以有部分是會存入內部緩沖區中,只有當上一個數據處理完成才會對下一個數據調用_write方法。
區分:
write是將數據寫入內部緩沖區。_write是將數據從內部緩沖區寫入目的地(比如磁盤、網絡等)。
關于write API和編碼問題
write方法的其中的一種重載形式:writable.write(data, encoding,callback),在默認情況下encoding參數是不會起作用的。
class MyWritable extends Writable {
_write(chunk:any, encoding:string, next:()=>void) {
console.log('encoding:', encoding); // encoding: buffer
console.log('Got chunk:', chunk); // Got chunk: <Buffer 68 65 6c 6c 6f 20 77 72 69 74 61 62 6c 65>
setTimeout(()=>{
next();
}, 1000)
}
}
const writable = new MyWritable({
decodeStrings: true, //默認,這個參數會被設置為true
});
writable.write('hello writable', 'utf-8'); //此時encoding參數不生效, data還是是轉換成Buffer處理的(默認)。
class MyWritable extends Writable {
_write(chunk:any, encoding:string, next:()=>void) {
console.log('encoding:', encoding); // encoding: utf-8
console.log('Got chunk:', chunk); // Got chunk: hello writable
setTimeout(()=>{
next();
}, 1000)
}
}
const writable = new MyWritable({
decodeStrings: false, //設為false
});
writable.write('hello writable', 'utf-8');
//decodeStrings: false時,data才是按encoding='utf-8'處理。此時在內部_write可以發現第二參數encoding會是'utf-8', 第一個參數chunk則是一個字符串。
Writable的事件和方法
事件
'close': 當流及其任何底層資源(例如文件描述符)已關閉時,觸發。'error': 如果在寫入或管道數據時發生錯誤,觸發。'drain': 當寫入流內部的寫入緩沖區被清空(目的地已接收這部分數據,緩沖區長度降為0),典型地,這發生在之前調用?writable.write()??返回了??false??(表示緩沖達到或超過??highWaterMark??)之后,一旦緩沖被完全“排空”,就會發出?'drain'?,表示可以安全繼續寫入。
// 一次性批量寫入大量數據,大小達到highWaterMark,令write方法返回false
function writeOneMillionTimes(writer, data, encoding, callback) {
let i = 1000000;
write();
function write() {
let ok = true;
do {
i--;
if (i === 0) {
// Last time!
writer.write(data, encoding, callback);
} else {
// 當緩沖區滿了,ok=false
ok = writer.write(data, encoding);
}
} while (i > 0 && ok);
if (i > 0) {
// 當drain了(即緩沖區被清空了),可以繼續寫入
writer.once('drain', write);
}
}
}
'finish': 在調用stream.end()方法之后,并且所有數據都已刷新到底層系統,觸發。
const writer = getWritableStreamSomehow();
for (let i = 0; i < 100; i++) {
writer.write(`hello, #${i}!\n`);
}
writer.on('finish', () => {
console.log('All writes are now complete.');
});
writer.end('This is the end\n');
'pipe': Readable Stream上調用readable.pipe(writable)將數據傳輸到Writable Stream上時,觸發。
const writer = getWritableStreamSomehow();
const reader = getReadableStreamSomehow();
writer.on('pipe', (src) => {
console.log('Something is piping into the writer.');
assert.equal(src, reader);
});
reader.pipe(writer); //當流開始傳輸時觸發writer的'pipe'事件
方法
| 方法 | 說明 |
|---|---|
write(chunk[, encoding][, callback]) |
寫入數據 |
end([chunk][, encoding][, callback]) |
結束寫入 |
cork() / uncork() |
批量寫入優化 |
setDefaultEncoding(encoding) |
設置默認編碼 |
destroy([error]) |
銷毀流 |
繼承了Writable的Node API
- 客戶端的HTTP請求
- 服務端的HTTP響應
- 文件系統的寫入流
- 子進程標準輸入
- process.stdout
服務端HTTP響應示例
import http from 'node:http';
import { Readable } from 'node:stream';
// 創建一個自定義的可讀流,用于分批生成數據
class BatchDataStream extends Readable {
constructor(options = {}) {
super(options);
this.dataSize = options.dataSize || 5; // 數據批次數量
this.currentBatch = 0;
this.interval = options.interval || 1000; // 每批數據的間隔時間(毫秒)
}
_read() {
// 如果已經發送完所有批次,結束流
if (this.currentBatch >= this.dataSize) {
this.push(null); // 表示流結束
return;
}
// 使用setTimeout模擬異步數據生成
setTimeout(() => {
const batchNumber = this.currentBatch + 1;
const data = `這是第 ${batchNumber} 批數據,時間戳: ${new Date().toISOString()}\n`;
console.log(`正在發送第 ${batchNumber} 批數據`);
// 將數據推送到流中
this.push(data);
this.currentBatch++;
}, this.interval);
}
}
// 創建HTTP服務器
const server = http.createServer((req, res) => {
// 設置響應頭
res.setHeader('Content-Type', 'text/plain; charset=utf-8');
// res.setHeader('Transfer-Encoding', 'chunked'); //但使用pipe傳輸數據,會自動設置Transfer-Encoding為chunked,所以這里不需要設置
console.log('收到新的請求,開始流式傳輸數據...');
// 創建數據流實例
const dataStream = new BatchDataStream({
dataSize: 10, // 總共發送10批數據
interval: 1000 // 每批數據間隔1秒
});
// 使用pipe將數據流直接連接到響應對象
dataStream.pipe(res);
// 當流結束時記錄日志
dataStream.on('end', () => {
console.log('數據傳輸完成');
});
});
// 啟動服務器
const PORT = 3000;
server.listen(PORT, () => {
console.log(`服務器運行在 http://localhost:${PORT}`);
console.log('請在瀏覽器中訪問此地址,或使用 curl http://localhost:3000 查看流式數據傳輸');
});
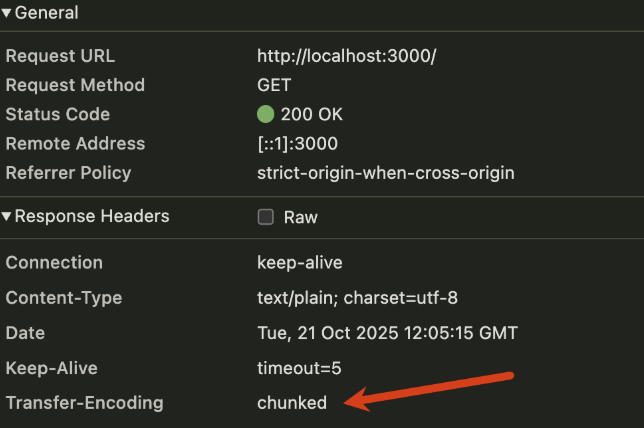
運行curl http://localhost:3000可以看到每個1s鐘接受一批數據。如下圖:
在網頁上也可以查看這個請求對應的響應頭的Transfer-Encoding被設置為chunked.(使用pipe會自動設置chunked)
拓展知識: Transfer-Encoding
Chunked傳輸編碼是HTTP中的一種傳輸編碼方式,它允許服務器將響應數據分成一系列小塊(chunks)來傳輸。每個chunk都有一個頭部,用于指示其大小,然后是一個回車換行(CRLF)分隔符,接著是chunk的實際數據,最后再加上一個CRLF分隔符。這個過程一直持續到最后一個chunk,它的大小為0,表示響應數據的結束。
以下是一個示例HTTP響應使用chunked傳輸編碼的樣本:
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
4\r\n
This\r\n
7\r\n
is a \r\n
9\r\n
chunked \r\n
6\r\n
message\r\n
0\r\n
\r\n
大多數情況下,響應頭會帶上Content-Length字段(表示響應正文的長度),頭Transfer-Encoding: chunked和Content-Length是互斥的,不會同時出現在響應頭(如果同時出現Transfer-Encoding優先級是大于Content-Length的)
Chunked傳輸的使用場景:大文件下載、API響應流(逐漸加載數據)、AI生成內容(文本圖像)
Duplex 雙工流
自定義Duplex雙工流
自定義Duplex需要同時實現_read和_write方法。因為 Duplex 流包含了 Readable 和 Writable兩個流,所以要維護兩個獨立的內部緩沖區,用于讀取和寫入,允許每一方獨立于另一方操作,同時保持適當和高效的數據流。
自定義一個XxxDuplex,可以互相寫入數據。
import { Duplex } from 'node:stream';
class XxxDuplex extends Duplex {
constructor(peer = null, options = {}) {
super(options);
this.peer = peer; // 另一端的 Duplex
}
// 當可寫端接收到數據時
_write(chunk, encoding, callback) {
const data = chunk.toString();
console.log(`[${this.label}] 寫入數據:`, data);
// 把數據發給對端
if (this.peer) {
this.peer.push(data);
}
callback(); // 通知寫操作完成
}
// 當可讀端被調用時(通常由 .read() 或流消費觸發)
_read(size) {
// 不做額外操作,等待對端 push()
}
// 結束時
_final(callback) {
if (this.peer) this.peer.push(null); // 通知對端結束
callback();
}
}
// 創建兩個互為對端的 Duplex 流
const duplexA = new XxxDuplex();
const duplexB = new XxxDuplex(duplexA);
duplexA.peer = duplexB;
// 加上標識
duplexA.label = 'A';
duplexB.label = 'B';
// 監聽 B 的讀取
duplexB.on('data', chunk => {
console.log(`[${duplexB.label}] 收到數據:`, chunk.toString());
});
duplexB.on('end', () => {
console.log(`[${duplexB.label}] 流結束`);
});
// A 向 B 發送數據
duplexA.write('你好,B!');
duplexA.write('這是一條測試消息');
duplexA.end();
/*
[A] 寫入數據: 你好,B!
[A] 寫入數據: 這是一條測試消息
[B] 收到數據: 你好,B!
[B] 收到數據: 這是一條測試消息
[B] 流結束
*/
Duplex和readable&writable相互轉換
Duplex和readable&writable互相轉換
使用stream.Duplex.fromWeb(pair[, options])將readable和writable轉為duplex。
import { Duplex } from 'node:stream';
import {
ReadableStream,
WritableStream,
} from 'node:stream/web';
const readable = new ReadableStream({
start(controller) {
controller.enqueue('world'); //設置readable buffer的初始數據
},
});
const writable = new WritableStream({
write(chunk) {
console.log('writable', chunk); //writable hello
},
});
const pair = {
readable,
writable,
};
//encoding: 'utf8'表示以utf8編碼工作,objectMode:true表示以對象模式工作
const duplex = Duplex.fromWeb(pair, { encoding: 'utf8', objectMode: true });
duplex.write('hello');
duplex.on('data', (chunk) => {
console.log('readable', chunk); //readable world
});
使用stream.Duplex.toWeb(streamDuplex)將duplex拆分成兩個流
import { Duplex } from 'node:stream';
const duplex = Duplex({
objectMode: true,
read() {
this.push('world');
this.push(null);
},
write(chunk, encoding, callback) {
console.log('writable', chunk);
callback();
},
});
const { readable, writable } = Duplex.toWeb(duplex);
writable.getWriter().write('hello');
const { value } = await readable.getReader().read();
console.log('readable', value);
屬于Duplex流的Node API
- TCP套接字
- zlib 流
- 加密流
TCP套接字示例:
import net from 'node:net';
/** 服務端 */
const server = net.createServer(function(clientSocket){
// clientSocket 就是一個 duplex 流
console.log('新的客戶端 socket 連接');
clientSocket.on('data', function(data){
console.log(`服務端收到數據: ${data.toString()}`);
clientSocket.write('world!');
});
clientSocket.on('end', function(){
console.log('連接中斷');
});
});
server.listen(6666, 'localhost', function(){
const address = server.address();
console.log('服務端啟動,地址為:%j', address);
});
/** 客戶端 */
// socket 就是一個 duplex 流
const socket = net.createConnection({
host: 'localhost',
port: 6666
}, () => {
console.log('連接到了服務端!');
socket.write('hello');
setTimeout(()=> {
socket.end();
}, 2000);
});
socket.on('data', (data) => {
console.log(`客戶端收到數據: ${data.toString()}`);
});
socket.on('end', () => {
console.log('斷開連接');
});
Transform 轉換流
自定義Transform流
Transform 流是一種雙工流的特殊子類(和Duplex 雙工流一樣同時實現 Readable 和 Writable 接口)。那么Transform流和Duplex流的關聯和區別?
關聯:stream.Transform繼承了stream.Duplex,并實現了自己的_read和_write方法。
區別:
| 類型 | 特點(區別) | 用途 | 關鍵方法 |
|---|---|---|---|
| Duplex 流 | 讀寫互相獨立,輸入和輸出沒有直接關系 | 雙向通信 | 數據處理 |
| Transform 流 | 輸入和輸出相關:寫入的數據經過處理后再輸出 | read() / write() |
transform(chunk, encoding, callback) |
也就是說,Duplex是輸入輸出流兩部分獨立(不干擾,同時進行);而Transform同樣有輸入和輸出流兩部分,但是Node會自動將輸出流緩沖區的內容寫入輸入流緩沖區。
Writable Buffer
↓ (消費)
transform(chunk)
↓ (push)
Readable Buffer
實現自定義的Transfrom流則需要實現_transfrom方法,舉個例子:
import {Transform} from 'node:stream'
class UpTransform extends Transform {
constructor() {
super();
}
_transform(chunk, enc, next) {
console.log('enc', enc); // enc buffer
this.push(chunk.toString().toUpperCase());
next();
}
}
const t = new UpTransform();
t.write('abc'); // 寫入 writable buffer
t.end();
// 從 readable buffer 讀取數據
t.on('data', (chunk) => console.log('Read:', chunk.toString()));
也用Transform初始化傳參的方式創建一個自定的Transfrom實例:
const t = new Transform({
transform(chunk, enc, next) {
console.log('enc', enc); // enc buffer
this.push(chunk.toString().toUpperCase());
next();
}
});
_transform調用的時機
當使用Transform流往輸入緩存區寫入數據時,會調用_transform方法進行轉換。
比如上面UpTransform那個例子,當t.write('abc');時就會觸發_transform。
在pipe方法中使用Transform流,會調用_transform方法進行轉換。
屬于Transfrom流的Node API
- zlib 流
- 加密流
zlib流示例:
const fs = require('node:fs');
const zlib = require('node:zlib');
const r = fs.createReadStream('file.txt');
const z = zlib.createGzip(); //z是一個Transform流
const w = fs.createWriteStream('file.txt.gz');
r.pipe(z).pipe(w);
緩沖區、高壓線和背壓問題
緩沖區、高壓線
首先介紹下緩沖區,Readable/Writable內部維護了一個隊列數據叫緩沖區。
高壓線(highWaterMark)是Readable/Writable內部的一個閾值(可在初始化時修改)。用來告訴流緩沖區的數據大小不應該超過這個值。
背壓問題解釋
背壓問題:當內部緩沖區的大小超過highWaterMark閾值,然后持續擴大,占用原來越多內存,甚至最后出現內存溢出。大白話來說就是緩存積壓問題。
一旦內部讀取緩沖區的總大小達到
highWaterMark指定的閾值,則流將暫時停止從底層資源讀取數據,直到可以消費當前緩沖的數據(也就是,流將停止調用內部的用于填充讀取緩沖區readable._read()方法)。
這里我們會有一個疑問就是:readable流不是會停止讀數據到緩沖區嗎,怎么還有背壓問題?
以下是GPT的解釋,我消化總結下:
- Readable 流有兩種操作模式:flowing 和 paused,flowing模式下無法有效處理背壓問題,因為不能暫停流的讀(不能停止調用
_read)。所以on('data')這種方式是無法處理背壓問題的,它會持續不斷的把數據積壓到緩沖區。 - 在paused模式下,可以調用
pause()方法暫停流的讀(pipe就是這個原理),從而可以做到處理背壓問題,但是也只能是緩解。像文件流這種是可控制的,能立即停止從文件讀取數據;但像Socket流,則不能立即停止數據的接受,但會:暫停從內核socket緩沖區中讀取 & 在TCP層通過窗口機制通知發送端"別發那么快"。
pipe() 如何處理 Readable 流的背壓?
readable.pipe(writable):
- 如果 Writable 流的緩沖區滿了(返回 false),pipe() 會自動調用 Readable.pause()
- 當 Writable 流排空緩沖區并發出 'drain' 事件時,pipe() 會調用 Readable.resume()
- 這樣就在兩個流之間建立了一個自動的背壓處理機制
總結來說,雖然 Readable 流確實會在緩沖區達到 highWaterMark 時嘗試暫停底層讀取,但這只是背壓處理的一部分。完整的背壓處理需要整個流管道中的所有組件協同工作,而 pipe() 方法正是為了簡化這種協同而設計的。
當重復調用
writable.write(chunk)方法時,數據會緩存在Writable流中。雖然內部的寫入緩沖區的總大小低于highWaterMark設置的閾值,但對writable.write()的調用將返回true。一旦內部緩沖區的大小達到或超過highWaterMark,則將返回false。
下面這個例子就是Writable的背壓問題解決(「Writable Stream」這節出現過的例子,來自官方文檔)
// 一次性批量寫入大量數據,大小達到highWaterMark,令write方法返回false
function writeOneMillionTimes(writer, data, encoding, callback) {
let i = 1000000;
write();
function write() {
let ok = true;
do {
i--;
if (i === 0) {
// Last time!
writer.write(data, encoding, callback);
} else {
// 當緩沖區滿了,ok=false
ok = writer.write(data, encoding);
}
} while (i > 0 && ok);
if (i > 0) {
// 當drain了(即緩沖區被清空了),可以繼續寫入
writer.once('drain', write);
}
}
}
如何解決背壓問題
方式一:手動拉數據來控制
readable.on('readable', () => {
let chunk;
while (null !== (chunk = readable.read())) {
processChunk(chunk);
}
});
方式二:使用 pipe()(自動處理)
readable.pipe(writable);
方式三:使用 await 迭代(自動處理)
for await (const chunk of readable) {
await processChunk(chunk); // 每次 await 都自然暫停上游讀取
}

 浙公網安備 33010602011771號
浙公網安備 33010602011771號