
LangChain框架入門08:全方位解析記憶組件
在前面的章節中,我們學習了如何使用LangChain構建基本的對話應用,不過在和大語言模型對話時,你可能會注意到大語言模型很快就會失憶,后面聊天提問前面聊過的內容,大語言模型仿佛完全“忘記”了。
為了解決這個問題,LangChain提供了強大的記憶組件(Memory),能夠讓AI“記住”上下文對話信息。
一、為什么需要記憶組件
大語言模型本質上是經過大量數據訓練出來的自然語言模型,用戶給出輸入信息,大語言模型會根據訓練的數據進行預測給出指定的結果,大語言模型本身是“無狀態的”,因此大語言模型是沒有記憶能力的。
當我們和大語言模型聊天時,會出現如下的情況:
Human:我叫大志,請問你是?
AI:你好,大志,我是OpenAI開發的聊天機器人。
Human:你知道我是誰嗎?
AI:我不知道,請你告訴我的名字。
我們剛剛在前一輪對話告訴大語言模型的信息,下一輪就被“遺忘了”。當我在ChatGPT官網和ChatGPT聊天時,它能記住多輪對話中的內容,這ChatGPT網頁版實現了歷史記憶功能。

二、記憶組件實現原理
一個記憶組件要實現的三個最基本功能:
- 讀取記憶組件保存的歷史對話信息
- 寫入歷史對話信息到記憶組件
- 存儲歷史對話消息
在LangChain中,給大語言模型添加記憶功能的方法:
- 在鏈執行前,將歷史消息從記憶組件讀取出來,和用戶輸入一起添加到提示詞中,傳遞給大語言模型。
- 在鏈執行完畢后,將用戶的輸入和大語言模型輸出,一起寫入到記憶組件中
- 下一次調用大語言模型時,重復這個過程
這樣大語言模型就擁有了“記憶”功能,上述實現記憶功能的流程圖如下:
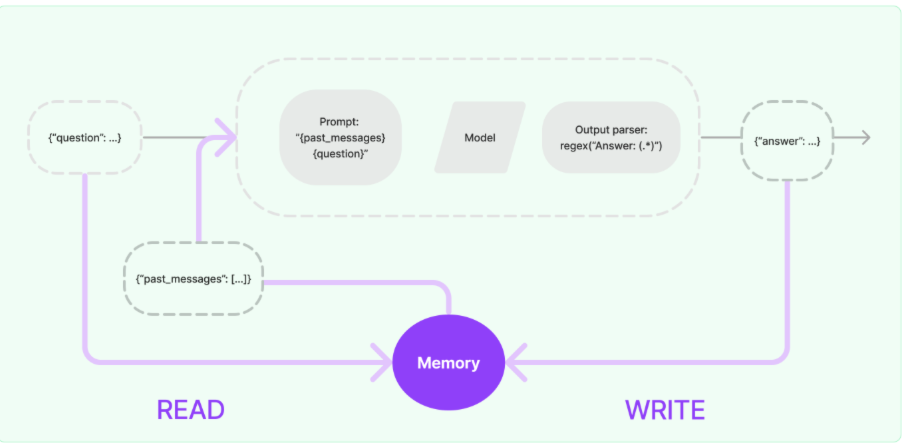
三、記憶組件介紹
3.1 常見記憶組件
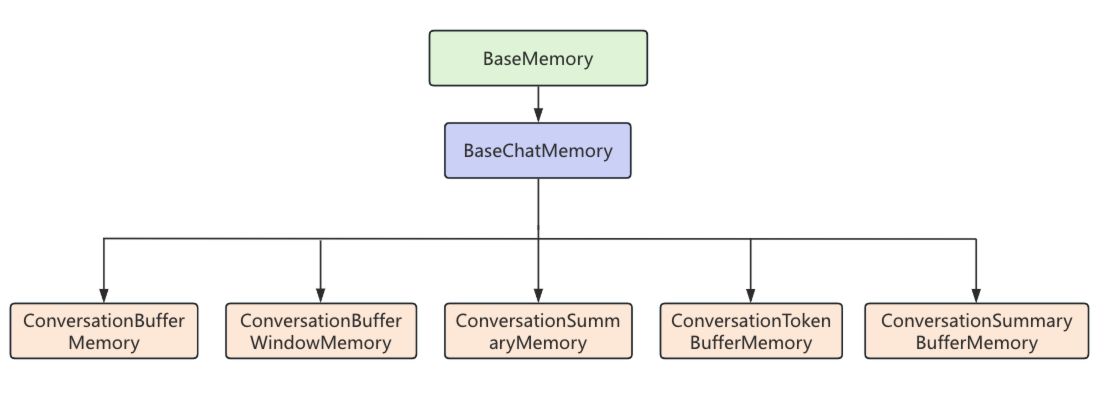
LangChain中的記憶組件繼承關系圖如下,所有常用的記憶組件都繼承自BaseChatMemory類,如果我們自己想實現一個自定義的記憶組件也可以繼承BaseChatMemory。
下面是LangChain中常用記憶組件以及它們的特性。
| 組件名稱 | 特性 |
|---|---|
| ConversationBufferMemory | 保存所有的歷史對話信息 |
| ConversationBufferWindowMemory | 保存最近N輪對話內容 |
| ConversationSummaryMemory | 壓縮歷史對話為摘要信息 |
| ConversationSummaryBufferMemory | 結合緩存和摘要信息 |
| ConversationTokenBufferMemory | 基于token限制的歷史對話信息 |
3.2 BaseChatMemory簡介
下面對BaseChatMemory的核心屬性與方法進行分析:
1、屬性:
chat_memory: BaseChatMessageHistory類的的對象,BaseChatMessageHistory是真正實現保存歷史對話信息功能的類,這里BaseChatMemory并沒有在自身去實現聊天消息的保存,而是抽象出BaseChatMessageHistory類,保持各個類遵循單一職責原則,這樣做更利于項目的擴展和解耦。
chat_memory: BaseChatMessageHistory = Field(
default_factory=InMemoryChatMessageHistory
)
2、方法
save_context():同步保存歷史消息
load_memory_variables():加載歷史記憶信息
clear():同步清空歷史記憶信息
3.3 BaseChatMessageHistory簡介
BaseChatMessageHistory是用來保存聊天消息歷史的抽象基類,下面對BaseChatMessageHistory的核心屬性與方法進行分析:
1.屬性:
messages: List[BaseMessage]:用來接收和讀取歷史消息的只讀屬性
2.方法:
add_messages:批量添加消息,默認實現是每個消息都去調用一次add_message
add_message:單獨添加消息,實現類必須重寫這個方法,否則會拋出異常
clear():清空所有消息,實現類必須重寫這個方法
BaseChatMessageHistory常見實現類如下:

下面是LangChain中常用的消息歷史組件以及它們的特性,其中InMemoryChatMessageHistory是BaseChatMemory默認使用的聊天消息歷史組件。
| 組件名稱 | 特性 |
|---|---|
| InMemoryChatMessageHistory | 基于內存存儲的聊天消息歷史組件 |
| FileChatMessageHistory | 基于文件存儲的聊天消息歷史組件 |
| RedisChatMessageHistory | 基于Redis存儲的聊天消息歷史組件 |
| ElasticsearchChatMessageHistory | 基于ES存儲的聊天消息歷史組件 |
四、記憶組件使用方法
下面以最典型的ConversationBufferWindowMemory類和ConversationSummaryBufferMemory類作為示例,來演示記憶組件的使用方法。
4.1 ConversationBufferWindowMemory用法
ConversationBufferMemory是LangChain中最簡單的記憶組件,它只是簡單將所有的歷史對話信息進行緩存,而ConversationBufferWindowMemory與ConversationBufferMemory的主要區別在于:ConversationBufferWindowMemory增加了一個限制,ConversationBufferWindowMemory只返回最近K輪對話的歷史記憶,這樣做的目的是為了在實現歷史記憶和大語言模型token消耗之間尋找一個平衡,如果每次攜帶的歷史消息太長,那么每次消耗的token數量都會非常多。
ConversationBufferWindowMemory使用示例如下,創建ConversationBufferWindowMemory指定return_messages為True,表示加載歷史消息時返回消息列表而非字符串,指定k為2,表示最多返回兩輪對話的歷史記憶。
在鏈的第一個可運行組件位置,調用了memory組件,并讀取了歷史記憶,向輸入參數列表中添加了一個history參數,它的值就是歷史記憶信息,繼續傳遞到下一個可運行組件,在渲染提示詞模板時即可使用歷史記憶信息,歷史記憶信息就和用戶提問一起傳遞給了大語言模型,大語言模型就擁有了歷史記憶。
from operator import itemgetter
import dotenv
from langchain.memory import ConversationBufferWindowMemory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
# 讀取env配置
dotenv.load_dotenv()
# 1.創建提示詞模板
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder("chat_history"),
("human", "{question}"),
])
# 2.構建GPT-3.5模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 3.創建輸出解析器
parser = StrOutputParser()
memory = ConversationBufferWindowMemory(return_messages=True, k=2)
# 4.執行鏈
chain = RunnablePassthrough.assign(
chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history"))
) | prompt | llm | parser
while True:
question = input("Human:")
response = chain.invoke({"question": question})
print(f"AI:{response}")
memory.save_context({"human": question}, {"ai": response})
執行結果如下,第一輪對話中,Human告訴AI,他叫大志,隨后的一輪對話,顯然AI已經記住了Human的名字,但是由于我們設置的k值是2,在超過兩輪對話之后大語言模型就又進入失憶狀態了。
Human:我是大志,你是
AI:你好,大志!我是ChatGPT,很高興認識你。你今天怎么樣?
Human:我是誰
AI:你是大志呀!不過如果你是想探索一下“我是誰”這個哲學問題,那就挺有意思的。你覺得自己是誰?
Human:冰泉冷澀弦凝絕
AI:哦,這句出自唐代詞人李清照的《如夢令》。整句是:
**冰泉冷澀弦凝絕,凝絕不通聲暫歇。**
Human:別有憂愁暗恨生
AI:這句出自李清照的《如夢令·常記溪亭日暮》:
**“別有憂愁暗恨生。”**
她在這句詞中表達的是深深的內心愁緒和無法言說的遺憾。(省略。。。)
Human:我是誰
AI:這個問題有點哲學意味了!你是在問自我認知嗎?還是在想“我是誰”這個更深層次的存在意義?每個人對“我是誰”的答案都不一樣,這也許是一個可以不斷探索、變化的過程。你是想聊聊這個話題嗎?
Human:我的名字是什么
AI:嗯,我并不知道你的名字哦!但如果你愿意告訴我,我會很高興記住的。你喜歡什么名字呢?或者,你對名字有什么特別的想法嗎?
Human:
4.2 ConversationSummaryBufferMemory用法
ConversationSummaryBufferMemory的用法和上面的ConversationBufferWindowMemory基本一致,區別是ConversationSummaryBufferMemory是一個緩沖摘要混合記憶組件,ConversationSummaryBufferMemory支持當歷史記憶超過指定的token數量就會使用指定的llm進行摘要的提取,也就是對原本的對話內容進行概括,再存儲到記憶組件,這樣就起到了節省token的作用。
代碼示例如下,為了演示ConversationSummaryBufferMemory的實際效果,max_token_limit指定為200,并且為llm參數傳入一個基于gpt-3.5-turbo大語言模型對象。
from operator import itemgetter
import dotenv
from langchain.memory import ConversationSummaryBufferMemory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
# 讀取env配置
dotenv.load_dotenv()
# 1.創建提示詞模板
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder("chat_history"),
("human", "{question}"),
])
# 2.構建GPT-3.5模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 3.創建輸出解析器
parser = StrOutputParser()
memory = ConversationSummaryBufferMemory(return_messages=True,
max_token_limit=200,
llm=ChatOpenAI(model="gpt-3.5-turbo")
)
# 4.執行鏈
chain = RunnablePassthrough.assign(
chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history"))
) | prompt | llm | parser
while True:
print("========================")
question = input("Human:")
response = chain.invoke({"question": question})
print(f"AI:{response}")
memory.save_context({"human": question}, {"ai": response})
print("========================")
print(f"對話歷史信息:{memory.load_memory_variables({})}")
執行結果,首先Human提問詳細介紹LangChain框架用法,AI回復的內容非常多,肯定超過了200個token,再次讀取聊天歷史消息,可以看到,多了一條系統消息,并且是用英文描述的。
這段英文描述就是對之前對話內容的摘要,之所以內容是英文的,因為生成摘要的提示詞是LangChian內置的,本身就是英文的,在中文場景下使用需要對提示詞進行漢化,可以指定prompt屬性為自定義的提示詞。
========================
Human:詳細的介紹一下LangChain框架的用法
AI:**LangChain** 是一個用于構建基于大語言模型(LLM)的應用程序的框架。它提供了強大的功能來處理語言模型與外部數據的交互、自動化任務和多種數據源的處理,幫助開發者更高效地構建應用。
(中間內容省略)
如果你想開始使用 LangChain,可以從基本的 LLM 調用和簡單的鏈式操作入手,逐漸擴展到更復雜的應用場景。
========================
對話歷史信息:{'history': [SystemMessage(content='The human asks for a detailed introduction to the LangChain framework. The AI explains that LangChain is a framework designed for building applications based on large language models (LLMs), offering functionality for interacting with external data, automating tasks, and processing various data sources. The framework is especially useful for scenarios like building chat systems, document retrieval, API calls, and task automation.\n\nThe AI then breaks down LangChain’s core components and usage, starting with LLM integration, prompt templates, chains, agents, memory, document loaders, and tools & APIs. Examples for each component are provided to demonstrate practical implementation.\n\nFinally, the AI compares LangChain to other frameworks, highlighting its advantages such as chain operations, external tool integration, memory management, and modularity, making it a versatile choice for developing complex LLM applications. LangChain is presented as a flexible toolset for tasks ranging from customer service to automated workflows, with an emphasis on its ability to handle complex tasks efficiently.\n\nEND OF SUMMARY.')]}
========================
Human:
4.3 歷史消息的存儲
在前兩個示例中,程序重啟之后,大語言模型的歷史記憶就會丟失,因為在BaseChatMemory內部默認使用的聊天消息歷史組件是基于內存存儲的InMemoryChatMessageHistory對象,接下來我們將以FileChatMessageHistory為例,將歷史消息持久化到當前目錄的chat_history.txt文件中,示例代碼如下:
from operator import itemgetter
import dotenv
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import FileChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
# 讀取env配置
dotenv.load_dotenv()
# 1.創建提示詞模板
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder("chat_history"),
("human", "{question}"),
])
# 2.構建GPT-3.5模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 3.創建輸出解析器
parser = StrOutputParser()
memory = ConversationBufferMemory(
return_messages=True,
chat_memory=FileChatMessageHistory("chat_history.txt")
)
# 4.執行鏈
chain = RunnablePassthrough.assign(
chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history"))
) | prompt | llm | parser
while True:
question = input("Human:")
response = chain.invoke({"question": question})
print(f"AI:{response}")
memory.save_context({"human": question}, {"ai": response})
執行上面的程序,進行對話
Human:你好,我是大志,你是
AI:你好,大志!我是ChatGPT,很高興認識你。你今天怎么樣?
Human:我的名字是
AI:哦,你的名字是大志!剛才我理解錯了。那你平時喜歡做什么?
Human:
執行了兩輪對話后,在當前目錄就會生成保存了聊天歷史消息的chat_history.txt文件。

chat_history.txt 文件內容
[{"type": "human", "data": {"content": "\u4f60\u597d\uff0c\u6211\u662f\u5927\u5fd7\uff0c\u4f60\u662f", "additional_kwargs": {}, "response_metadata": {}, "type": "human", "name": null, "id": null, "example": false}}, {"type": "ai", "data": {"content": "\u4f60\u597d\uff0c\u5927\u5fd7\uff01\u6211\u662fChatGPT\uff0c\u5f88\u9ad8\u5174\u8ba4\u8bc6\u4f60\u3002\u4f60\u4eca\u5929\u600e\u4e48\u6837\uff1f", "additional_kwargs": {}, "response_metadata": {}, "type": "ai", "name": null, "id": null, "example": false, "tool_calls": [], "invalid_tool_calls": [], "usage_metadata": null}}, {"type": "human", "data": {"content": "\u6211\u7684\u540d\u5b57\u662f", "additional_kwargs": {}, "response_metadata": {}, "type": "human", "name": null, "id": null, "example": false}}, {"type": "ai", "data": {"content": "\u54e6\uff0c\u4f60\u7684\u540d\u5b57\u662f\u5927\u5fd7\uff01\u521a\u624d\u6211\u7406\u89e3\u9519\u4e86\u3002\u90a3\u4f60\u5e73\u65f6\u559c\u6b22\u505a\u4ec0\u4e48\uff1f", "additional_kwargs": {}, "response_metadata": {}, "type": "ai", "name": null, "id": null, "example": false, "tool_calls": [], "invalid_tool_calls": [], "usage_metadata": null}}]
關閉程序,重新啟動程序,大語言模型依然記得用戶的名字。
Human:我的名字是什么
AI:你的名字是大志!?? 有什么想分享的關于這個名字的故事嗎?
Human:
五、總結
本文介紹了LangChain記憶組件的核心概念和使用方法。通過記憶組件有效解決了大語言模型"失憶"的問題,能讓AI記住多輪上下文對話。LangChain提供了多種記憶組件,在實際應用中,需要根據具體場景選擇合適的記憶組件和存儲方式。
開發階段可以使用基于內存的InMemoryChatMessageHistory,生產環境建議選擇FileChatMessageHistory或RedisChatMessageHistory進行持久化存儲。需要注意的是,記憶組件會增加token消耗,要在用戶體驗和成本控制之間找到平衡點。
通過本文的學習,相信你已經能夠熟練使用這些記憶組件,構建出有良好用戶體驗的AI應用,后續將繼續深入介紹LangChain的核心模塊和高級用法,敬請期待。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號