

Elasticsearch GC優(yōu)化實(shí)踐
近期業(yè)務(wù)查詢線上ES集群出現(xiàn)頻繁超時(shí)告警,尤其是早晨某個(gè)時(shí)間點(diǎn)固定的報(bào)一波超時(shí),從調(diào)用鏈監(jiān)控上很難看出是什么業(yè)務(wù)行為導(dǎo)致的。
初步猜測
查看Grafana上Elasticsaerch的基礎(chǔ)監(jiān)控,發(fā)現(xiàn)業(yè)務(wù)告警與ES的Old GC(老年代GC)卡頓時(shí)間基本吻合:

同時(shí)注意到,Old區(qū)的內(nèi)存持續(xù)增長,不到1小時(shí)就會(huì)將Old區(qū)填滿,經(jīng)過Old GC幾乎全部可以回收掉:
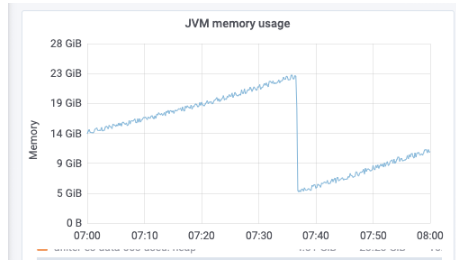
猜測:
是什么導(dǎo)致Old區(qū)快速增長?可能是內(nèi)存分配速率過高導(dǎo)致過早晉升?可能是分配很大的對(duì)象?
為什么Old GC這么慢?ES卡頓大概率與它有關(guān),早晨時(shí)間固定發(fā)生可能與業(yè)務(wù)某種行為有關(guān)。
查看GC配置
所以先用JVM工具從外圍查看一下GC配置與大概情況。

jmap查看ES堆情況:
MaxHeapSize:整個(gè)堆31GB。
MaxNewSize:Young區(qū)只有1GB。
OldSize:Old區(qū)有30GB。
NewRatio:取值2表示Young區(qū)應(yīng)該占整個(gè)堆的1/3,應(yīng)該是10GB才對(duì),而實(shí)際才1GB,這非常奇怪。
我們期望的默認(rèn)行為是Young=10GB,Old=20GB才對(duì),為什么變成了1GB和30GB這樣?
查看了一下JVM最終的啟動(dòng)參數(shù),竟然真的自行推斷Young區(qū)只占1GB空間,難道是JVM的BUG?
jinfo -flags 4413

把剩余的GC參數(shù)谷歌了一下,果然發(fā)現(xiàn)有人測試過JDK8的-XX:+UseConcMarkSweepGC會(huì)導(dǎo)致NewRatio參數(shù)失效,原因不明!

這么小的Young區(qū)肯定會(huì)導(dǎo)致頻繁Young GC (通過jstat -gc觀察YGC每秒1~2次) ,對(duì)ES性能肯定沒有好處, 雖然和Old GC慢沒啥直接關(guān)系 ,但也必須先修復(fù)一下再說了,通過-Xmn直接指定Young區(qū)10GB即可:
重啟ES觀察到Y(jié)oung區(qū)大小正確,觀察jstat -gc發(fā)現(xiàn)Young GC頻率顯著下降了6倍。
再次觀察grafana,發(fā)現(xiàn)YGC頻率的確下降(YGC之間有間隔了):
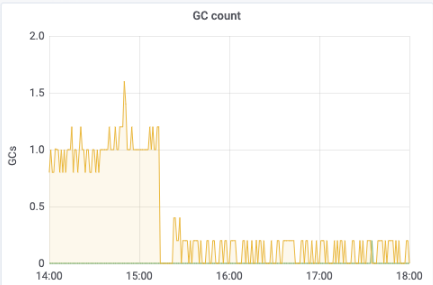
Old區(qū)仍舊保持高增速:

但是因?yàn)閅oung區(qū)從1GB調(diào)到10GB了,所以每次YGC對(duì)JVM heap的收縮振幅會(huì)更明顯,圖形上出現(xiàn)明顯的起落,但整個(gè)JVM heap持續(xù)走高的勢頭沒有改變,因?yàn)閷?duì)象仍舊在快速晉升到Old區(qū),直到Old區(qū)填滿后一次Old GC再大幅回落。
開啟GC日志
接下來要分析Old區(qū)快速增長的原因,另外要看一下為什么Old GC會(huì)卡頓1秒,能否優(yōu)化?
配置開啟GC日志,重啟ES:
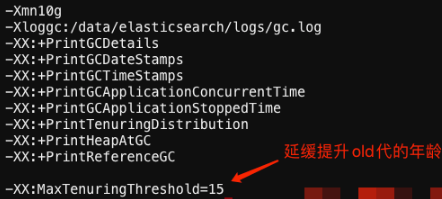
為了判斷是不是存在很多”中生命期”的對(duì)象存在而導(dǎo)致頻繁晉升到Old區(qū),所以需要打開 -XX:MaxTenuringThreshold=15 參數(shù),令Young區(qū)晉升條件提高為15代YGC,以便觀察Young區(qū)的對(duì)象年齡分布。
一開始我采用默認(rèn)參數(shù)是6代晉升,這是當(dāng)時(shí)的截圖:

圖中觀察到1~6歲的對(duì)象都有,每一代就幾十MB的空間占用,我們知道YGC后6歲的就會(huì)進(jìn)入Old區(qū),1~5歲的就會(huì)都漲1歲,所以我懷疑就是每次YGC會(huì)導(dǎo)致第6代幾十MB的”中生命期”對(duì)象晉升到Old區(qū),大概算了一下這個(gè)速度的確和Old GC的周期接近,看樣大概率是這個(gè)原因?qū)е翺ld區(qū)增長的。
如果我調(diào)高晉升年齡到15代,有可能活到10歲的”中生命期”對(duì)象就會(huì)最終在YGC被回收掉,可能會(huì)減緩Old區(qū)的增長速度,抱著這個(gè)想法我才將XX:MaxTenuringThreshold調(diào)到了15,想給”中生命期”對(duì)象多一些機(jī)會(huì)被YGC回收掉。

但實(shí)際情況是15代都均勻的分布著對(duì)象,可見”中生命期”的對(duì)象活的比想象的要久,能熬過15代YGC還不釋放,既然現(xiàn)實(shí)情況就是有很多”中生命期”對(duì)象存在,那減緩Old區(qū)增長的想法是比較難實(shí)現(xiàn)了, 索性繼續(xù)研究一下為什么Old GC那么卡的問題吧 。
優(yōu)化Old GC速度
根據(jù)打印到磁盤上gc日志,可以深入分析一下CMS Old GC的流程耗時(shí)在哪里,我們應(yīng)該重點(diǎn)關(guān)注會(huì)導(dǎo)致STW(stop the world)的階段耗時(shí)。
CMS垃圾回收算法是Old區(qū)的GC算法,它的開始以這樣的日志標(biāo)識(shí):
2022-03-12T13:19:54.273+0800: 96253.129: [GC (CMS Initial Mark) [1 CMS-initial-mark: 23554181K(31398336K)] 23611096K(32395136K), 0.0063801 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
初始化標(biāo)記階段,只會(huì)STW一丟丟的時(shí)間,基本可以忽略。
整個(gè)CMS的經(jīng)歷如下階段:
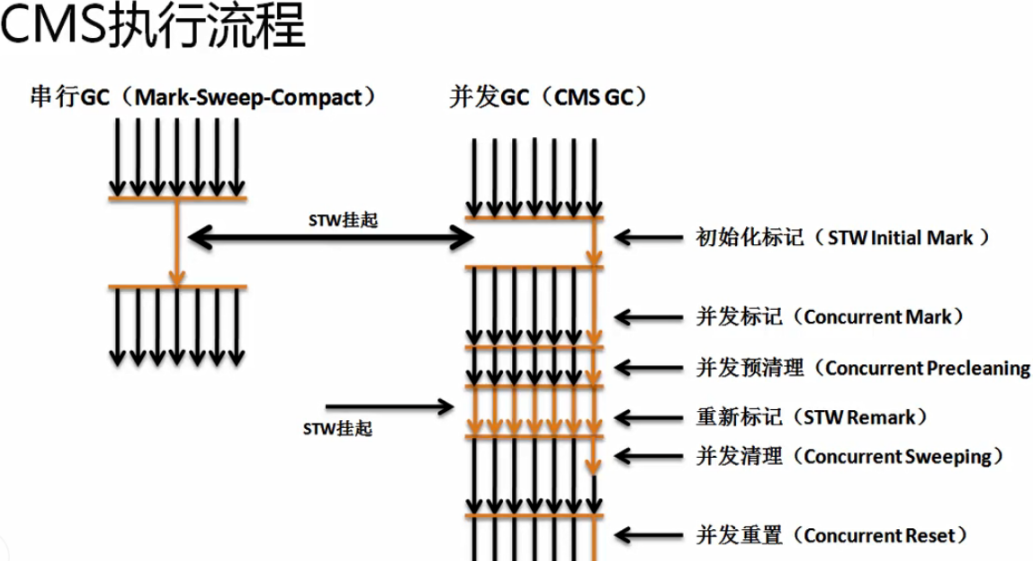
在Remark階段會(huì)有明顯的STW,知乎上是這樣描述的:

因?yàn)镺ld GC全流程比較漫長,期間Young區(qū)會(huì)快速填充,等到Remark階段要掃全堆的時(shí)候Young區(qū)也填滿了很多對(duì)象,此時(shí)強(qiáng)制配置一波YGC(本身又很快),應(yīng)該可以減少Remark的STW耗時(shí)。
目前觀察到Remark階段耗時(shí):

STW長達(dá)0.8秒,的確很慘,我們加上這個(gè)選項(xiàng):
-XX:+CMSScavengeBeforeRemark
添加上述配置后,可以看到Remark階段時(shí)間STW耗時(shí)縮短了7倍左右:
優(yōu)化效果
紅色為原線上配置的對(duì)照實(shí)例,其他機(jī)器均已生效新配置:

可見,GC頻率與耗時(shí)均明顯下降,新的Old GC耗時(shí)已經(jīng)降低到原先的Young GC耗時(shí)的水平,早晨超時(shí)報(bào)警的情況也消失了。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)