瀏覽器渲染原理
渲染是指什么?
渲染 (render),是指將HTML代碼轉換為像素信息的過程。
當用戶在瀏覽器上輸入url之后,訪問的服務器返回html文件,本質上是html代碼,是字符串。渲染這個過程的任務就是:識別這段字符串,并且轉換為像素信息。
渲染時間點
用戶打開網頁的過程可以簡單概括為:
-
網絡:拿HTML。
這里概括為拿HTML,是因為在HTML文件中可以通過
<style>標簽和<script>標簽引入 CSS 和 JS 文件。事實上網絡的過程也很復雜, 但是不是這篇筆記的重點討論內容。
-
渲染:解析HTML代碼并最終轉換為像素信息。
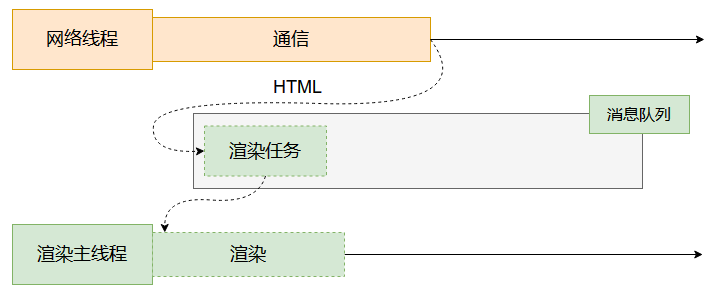
瀏覽器有很多進程,其中有網絡進程,而網絡進程又包含網絡線程。
網絡線程完成網絡請求任務之后,拿到了一個html文件,但是它沒有解析的能力,于是將html文件包裝成一個任務,通過消息隊列,轉交給渲染主線程。
渲染主線程拿到渲染任務之后,就開始了渲染流程,就是本篇筆記的重點內容。
渲染流程
解析HTML - Parse HTML
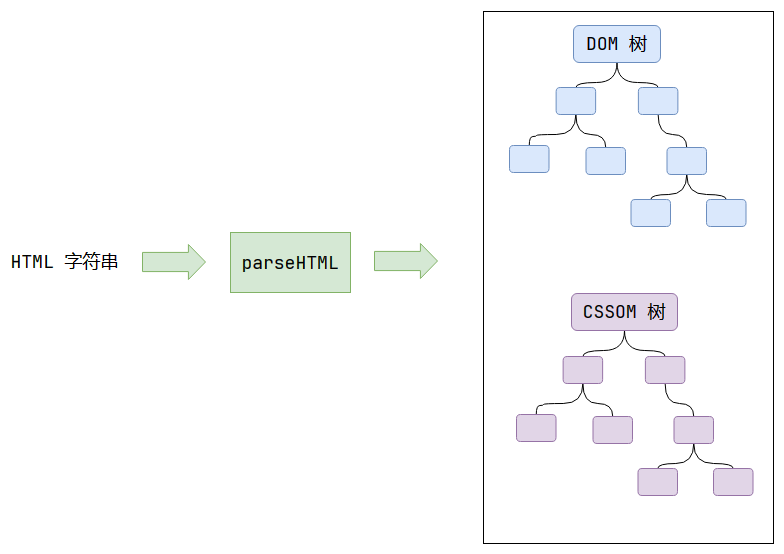
DOM樹(Document Object Model):頁面中的元素和文本,以樹形結構相關聯。
在 JS 代碼中,通過document對象可以訪問和修改DOM樹。而上圖中的DOM樹指的是瀏覽器底層由C++生成的DOM樹。
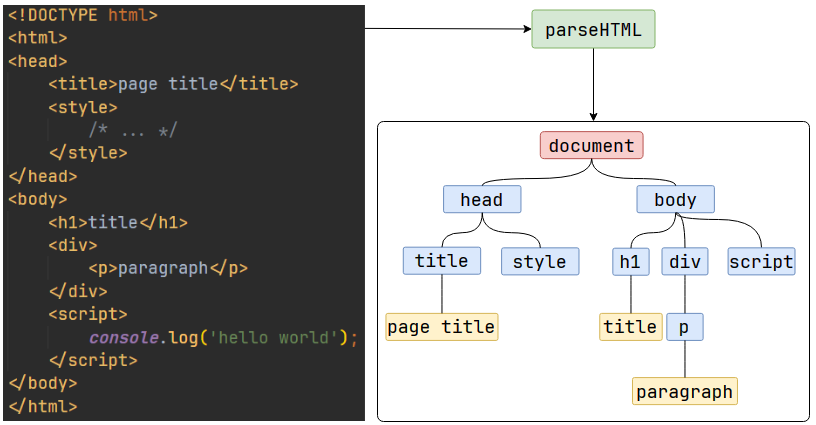
這一個轉換步驟是為后續步驟做準備的,因為字符串難處理,而對象結構容易處理。
CSS也會被解析成CSSOM(CSS Object Model),也是樹形結構,根節點(StyleSheetList)是網頁中所有的樣式表,二級子節點可能包含內部樣式表、外部樣式表、內聯樣式表和瀏覽器默認樣式表(取決于代碼中是否有這些內容),如果有兩個<link>,則會出現兩個外部樣式表節點。
可以在github上的chromium源碼找到瀏覽器默認樣式表的內容。
除了瀏覽器默認樣式表,內部樣式表、外部樣式表、內聯樣式表都可以通過 JS 訪問到。
- 內部樣式表和外部樣式表:使用
document.styleSheets可以訪問到一個數組,元素是樣式表對象。
- 使用
document.styleSheets[0].addRule("div", "border: 1px solid red important")可以讓頁面上的所有div標簽的邊框變成紅色,這種做法與傳統的“獲取所有div標簽,再設置其style”的做法不同。- 內聯樣式表:使用
dom.style訪問
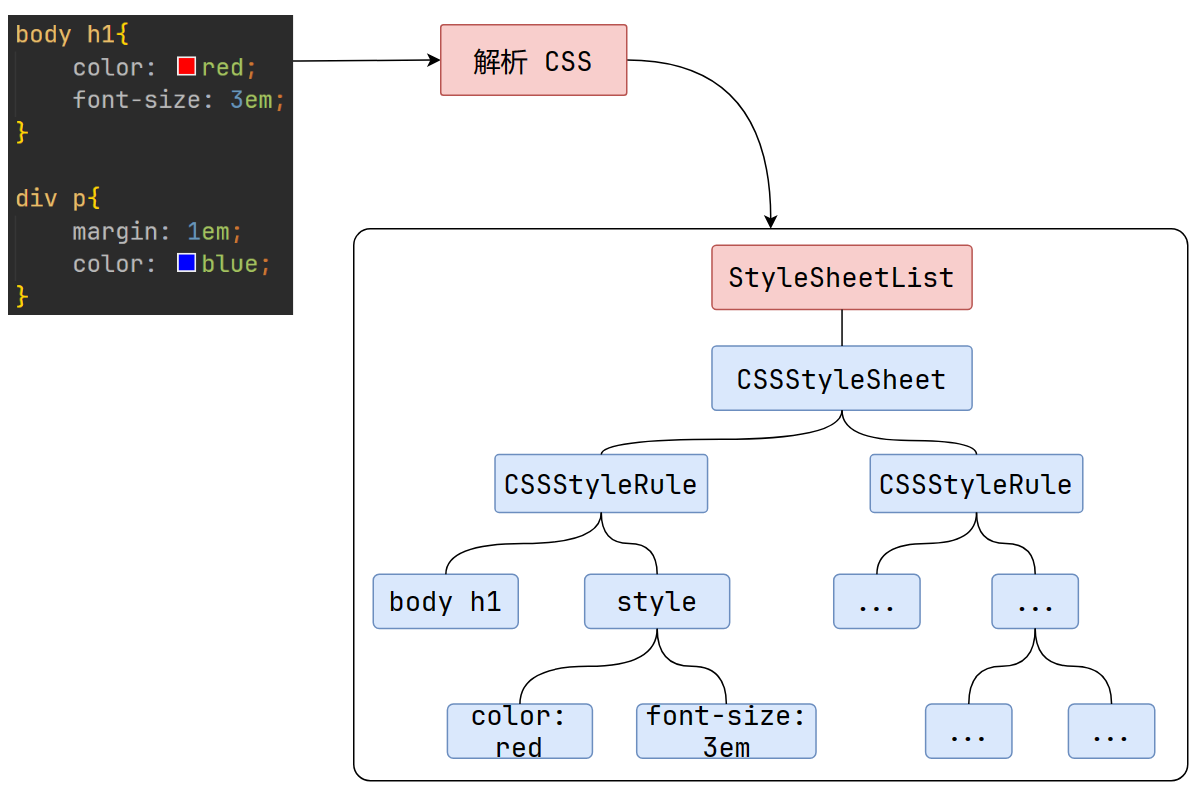
HTML解析過程遇到CSS怎么辦?
為了提高解析效率,瀏覽器會啟動一個預解析器率先下載和解析CSS。
渲染主線程在解析HTML的時候,會關注每一個標簽;而預解析線程只關注外部樣式表的標簽<link>,盡快地完成CSS的下載與解析。
這樣做的目的是防止CSS的解析阻塞了HTML的解析。
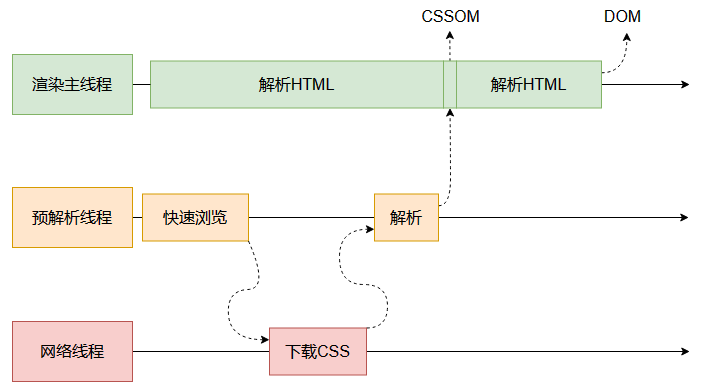
HTML解析過程遇到JS怎么辦?
渲染主線程遇到 JS 的script標簽時必須暫停一切行為,等待下載 JS 文件,并且啟用V8引擎解析執行 JS 代碼,然后才能繼續解析 HTML。
原因:JS 代碼可能修改 DOM 樹。
預解析線程可以分擔一點下載 JS 的任務。
樣式計算 - Recalculate Style
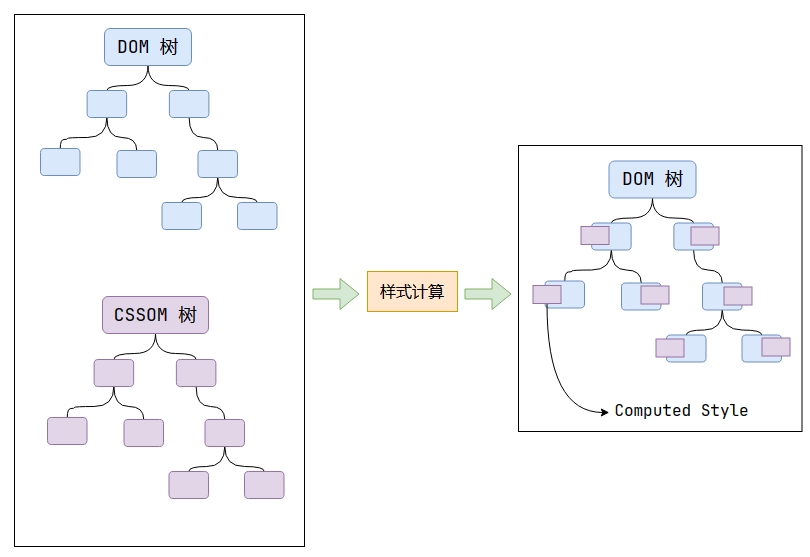
樣式計算過程計算每一個DOM節點的最終樣式(Computed Style)。
計算樣式如何查看:在瀏覽器上打開開發者工具,查看“計算樣式”,并選擇“全部顯示”。
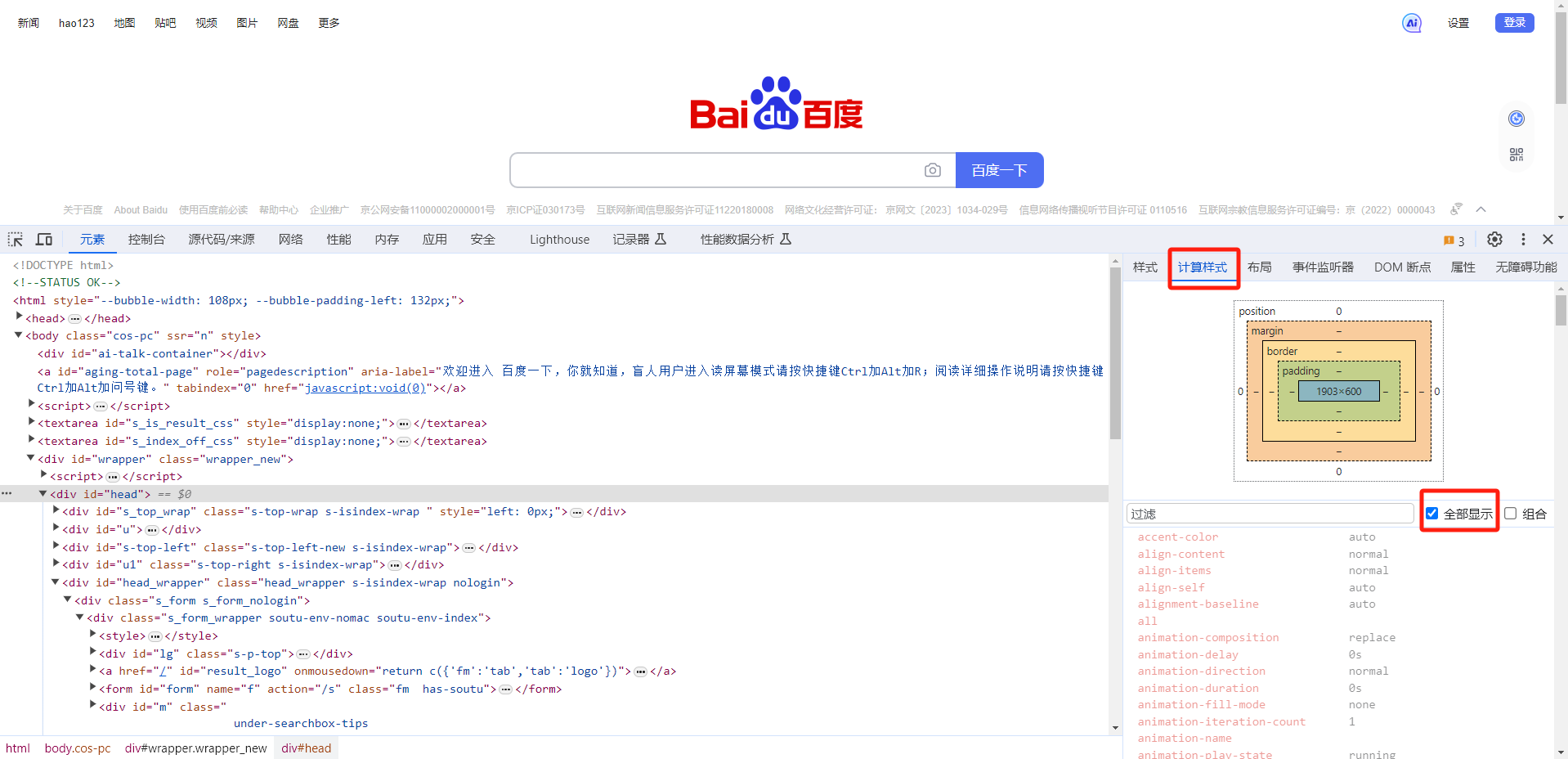
通過上一過程,得到的 DOM 樹和 CSSOM 樹。通過遍歷 DOM 樹,為每一個 DOM 節點,計算它的所有 CSS 屬性。
屬性值的計算過程,分為如下4個步驟:
- 確定聲明值;
- 層疊沖突;
- 使用繼承;
- 使用默認值。
確定聲明值
如果先不考慮沖突的話,那么通過 頁面作者書寫的CSS樣式 和 用戶代理樣式表(瀏覽器內置的樣式表) 的聲明值相加得到全部的聲明值,并且將部分值進行轉換。
例如,將color: red;轉換為color: rgb(255, 0, 0);,將font-size: 2em;轉換為font-size: 14px;。
層疊沖突
在確定聲明值時,可能出現一種情況,那就是聲明的樣式規則發生了沖突。
此時會進入解決層疊沖突的流程。而這一步又可以細分為下面這三個步驟:
- 比較源的重要性
- 比較優先級
- 比較次序
比較源的重要性
樣式有三種來源:
- 瀏覽器會有一個基本的樣式表來給任何網頁設置默認樣式。這些樣式統稱用戶代理樣式。
- 網頁的作者可以定義文檔的樣式,這是最常見的樣式表,稱之為頁面作者樣式。
- 瀏覽器的用戶,可以使用自定義樣式表定制使用體驗,稱之為用戶樣式。
對應的重要性順序依次為:頁面作者樣式 > 用戶樣式 > 用戶代理樣式。
可以在 MDN 中找到更詳細的說明:CSS 層疊 - CSS:層疊樣式表 | MDN (mozilla.org)
比較優先級
如果在同一源中出現了樣式聲明沖突,則比較其優先級。
簡單來說就是:ID選擇器 > 類名選擇器 > 標簽選擇器。
更詳細的說明可以查閱 MDN 的文章:優先級 - CSS:層疊樣式表 | MDN (mozilla.org)
比較次序
如果出現同源同權重的情況,則比較樣式的聲明次序。
后聲明的樣式會覆蓋先聲明的樣式。
p{
/* 會被覆蓋 */
color: red;
}
p{
/* 生效 */
color: green;
}
顯然,不存在次序相同的情況。至此,樣式聲明中存在沖突的所有情況都解決了。
使用繼承
上文提到了,對于每一個 DOM 節點,都會去計算它的所有 CSS 屬性。
層疊沖突這一步驟完成之后,聲明值已全部確定。
而對于未聲明的屬性,并不是直接使用默認值,而是使用繼承值。
例如:
<div>
<p>hello world</p>
</div>
div{
color: red;
}
這里<p>標簽會繼承來自<div>的color: red樣式。
繼承原則:
-
繼承誰的?答:就近原則,誰近就繼承誰的,與權重無關。
-
哪些屬性能夠繼承?答:大部分字體相關的屬性都是可繼承的,可以在MDN上查找屬性是否可繼承。

使用默認值
如果經過上述過程仍不能確定屬性值,則使用默認值。
布局 - Layout
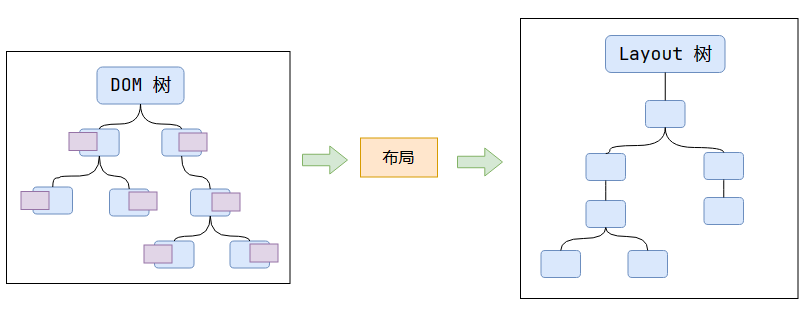
根據 DOM 樹里每個節點的樣式,計算出每個節點的尺寸和位置。
有一些數值,例如:百分比,或者
auto,在上一步驟無法算出來,在布局這個過程才能算出來。
對于一個元素來說,它的尺寸和位置經常與它的包含塊(containing block)有關。
這里簡單地記錄包含塊的知識,更詳細的說明可以查閱 MDN 文檔:??布局和包含塊
盒模型:每一個盒子被劃分為4個區域,即內容區,內邊距區,邊框區和外邊距區。
對于一個元素而言,大部分時候,它的包含塊就是它父元素的內容區。但在一些情況下并不如此。
包含塊影響這些內容的計算:
width,height,margin,padding,偏移量(position為absolute或fixed的時候),以及使用百分比的時候,是依照其包含塊數值為基準計算的。如何確定包含塊:確定一個元素的包含塊的過程完全依賴于這個元素的
position屬性。
static、relative、sticky:包含塊可能由它的最近的祖先塊元素(比如說 inline-block, block 或 list-item 元素)的內容區的邊緣組成;absolute:由它的最近的position的值不是static的祖先元素的內邊距區的邊緣組成;fixed:在連續媒體的情況下包含塊是viewport;absolute或fixed:包含塊也可能是由滿足以下條件的最近父級元素的內邊距區的邊緣組成的。
transform或perspective的值不是none。will-change的值是transform或perspective。filter的值不是none或will-change的值是filter(只在 Firefox 下生效)。contain的值是paint(例如:contain: paint;)。backdrop-filter的值不是none(例如:backdrop-filter: blur(10px);)。
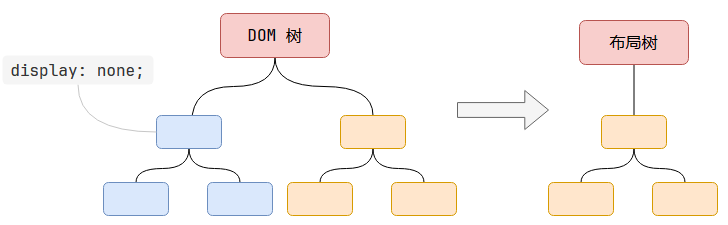
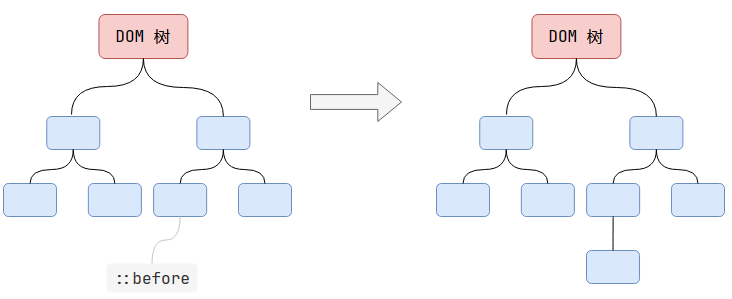
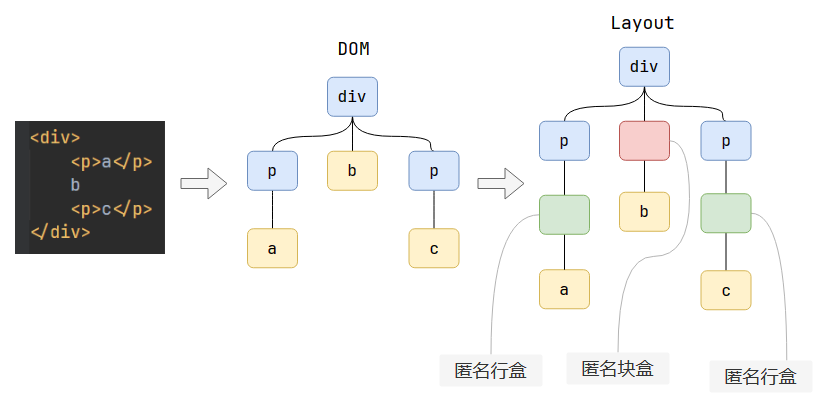
如上圖所示,Layout樹和DOM樹不一定是一一對應的。
原因是:
-
布局樹是記錄節點的幾何信息(尺寸和位置)的,如果設置了
display: none;,則節點失去幾何信息,不會被添加到布局樹中。 -
偽元素節點不存在于DOM樹中,但是有幾何信息,因此會被生成到布局樹中。
-
布局過程存在兩個規則(w3c規定):
- 內容必須在行盒中
- 行盒和塊盒不能相鄰
如果在塊盒中直接寫入內容,則會在中間生成一個匿名行盒;如果塊盒和行盒相鄰,則為行盒外部生成一個匿名塊盒。(參考上圖)
??插播小知識:
html標簽只表明語義,不區分行盒或塊盒,css決定元素是行盒還是塊盒。
通常理解的
<p>, <div>是塊盒,是因為瀏覽器默認樣式給它們設置了display: block;。
<head>,<meta>等標簽都是隱藏的,是因為瀏覽器默認樣式表給它們設置了display: none;。可以在github上chromium的源代碼中找到這些默認樣式。
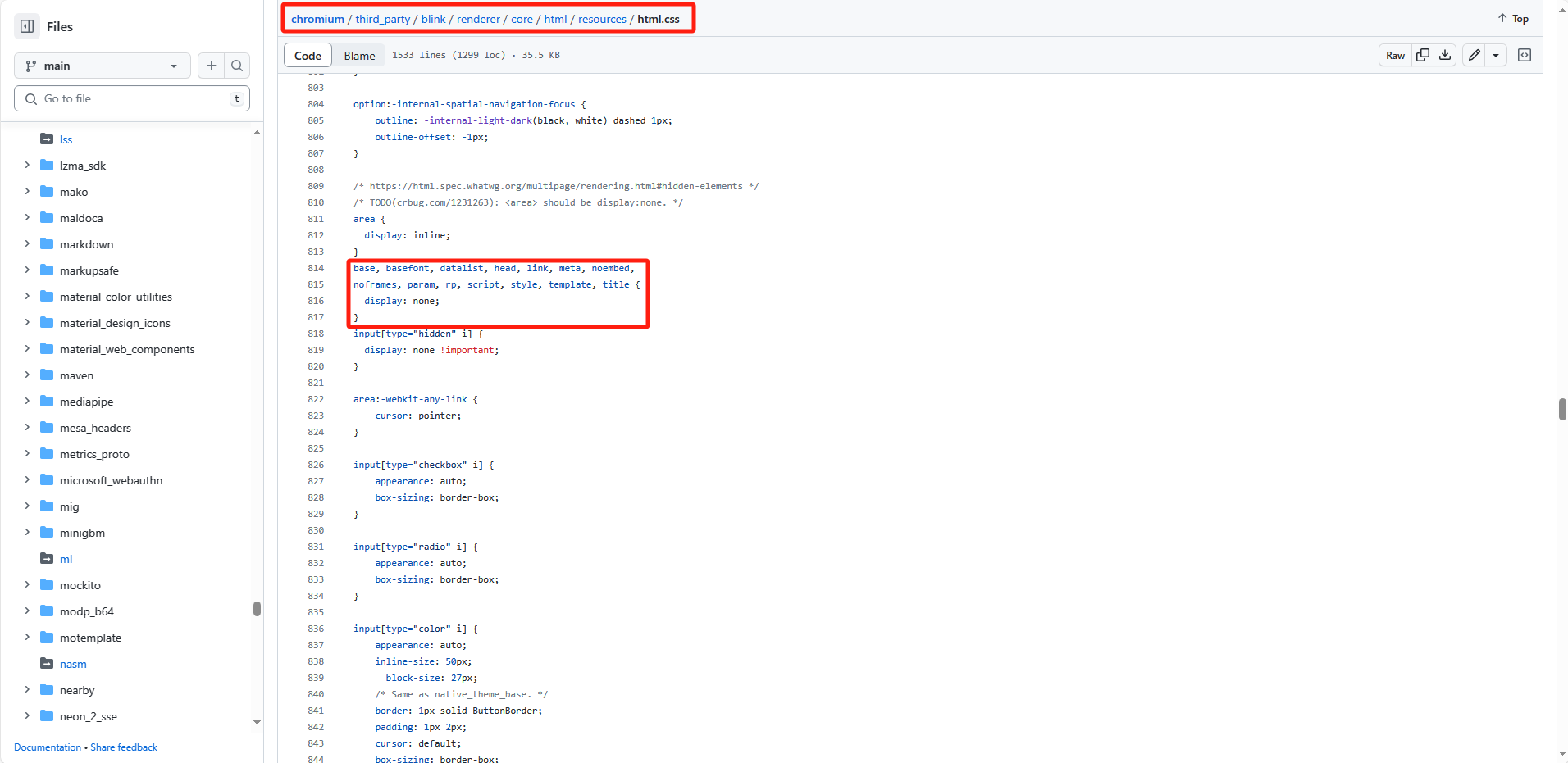
上述的DOM樹和布局樹都是指瀏覽器底層的C++對象,它們以不同程度暴露到JS中。
對于DOM樹,JS提供了document對象可以訪問;而布局樹,只暴露出了很少的內容,例如:clientWidth,offsetWidth等屬性。
分層 - Layer
現在的頁面大多都十分復雜,并且交互效果很多。如果不分層,用戶的一個簡單交互將導致整個頁面的重新渲染,效率低下。
分層的好處在于可以局部的渲染,提高性能。
老舊的瀏覽器沒有分層概念,現代瀏覽器都有分層這個內容了。

以Edge瀏覽器打開百度為例,開發者工具中切換到3D視圖(不同瀏覽器或者因為語言不同可能是不同選項),左側可以看到多個分層。
通常來說不會太多層,因為分層雖然可以提高渲染效率,但是占用很大內存空間。
分層與部分CSS屬性有關,通常頁面越復雜則層越多,但是也不一定,因為不同瀏覽器的分層策略可能不同。
總結:與堆疊上下文有關的屬性,會影響分層的決策,最后依據不同瀏覽器的具體實現,生成分層的結果。
與堆疊上下文有關的屬性:
z-index,opacity,transform......
引用自MDN
繪制可以將布局樹中的元素分解為多個層。將內容提升到 GPU 上的層(而不是 CPU 上的主線程)可以提高繪制和重新繪制性能。有一些特定的屬性和元素可以實例化一個層,包括
video和canvas,任何 CSS 屬性為opacity、3Dtransform、will-change的元素,還有一些其他元素。這些節點將與子節點一起繪制到它們自己的層上,除非子節點由于上述一個(或多個)原因需要自己的層。分層確實可以提高性能,但是它以內存管理為代價,因此不應作為 web 性能優化策略的一部分過度使用。
??插播小知識
will-change:通常大多數元素例如
<div>不會單獨分為一層,但是如果它的內容經常需要更新、需要重新渲染,可以添加一個屬性:will-change。如果這個元素的
transform屬性需要經常發生變化,那么可以聲明will-change: transform;,告知瀏覽器其需要經常更新,但是最后是否決定分層依然是瀏覽器的具體實現決定的。
繪制 - Paint
首先需要生成繪制的指令,為每個層生成繪制指令集,用于描述這一層的內容該如何畫出來。
繪制指令類似于canvas的操作方法:
- 移動畫筆到xxx
- 繪制寬為x,高為y的矩形
- ......
事實上,canvas是瀏覽器將繪制過程封裝后提供給開發者的工具。
分塊 - Tiling
分塊將每一層分為多個小的區域。
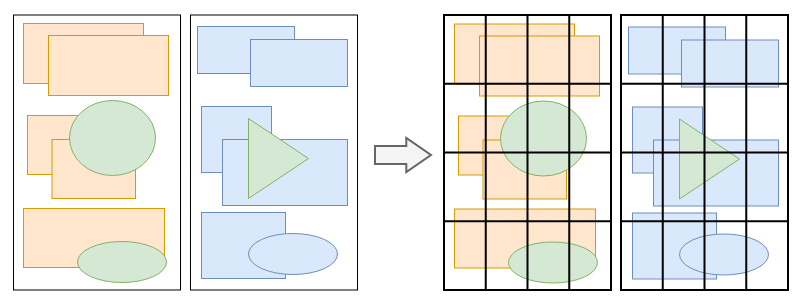
這一步的目的是,優先畫出視口內以及接近視口的內容。
想象一個很長的、需要滾動很久才能到底的頁面。
頁面很大,但是接近視口的內容優先級最高,因為我們希望用戶能盡早的看到頁面的內容。于是分塊,接近視口的塊優先級高,優先顯示出來。
可以將其視為更底層的“懶加載”。
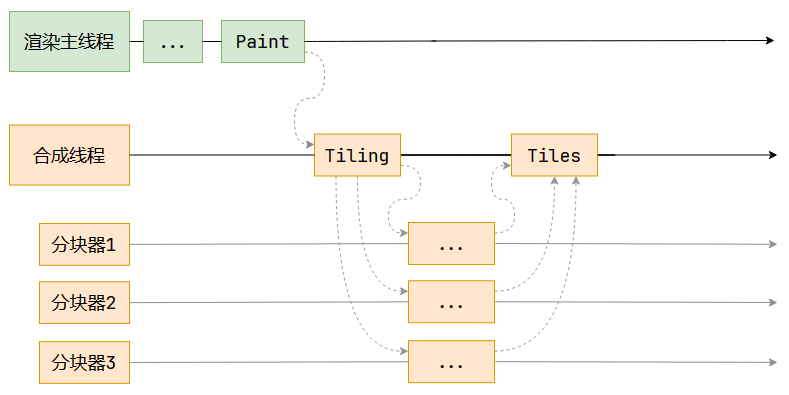
分塊的工作是交給多個線程同時進行的。
渲染主線程先將分塊任務交給合成線程,合成線程會從線程池中拿取多個線程來完成分塊工作。
其中的合成線程和渲染主線程都位于渲染進程里。
目前大多數瀏覽器的策略是每個標簽頁都對應一個渲染進程,渲染進程里面包含多個線程。
光柵化 - Raster
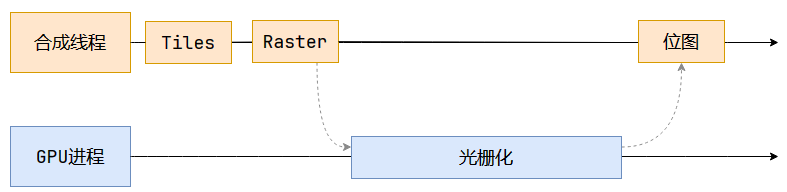
光柵化將每個塊變成位圖,既然上一步已經分塊了,這一步自然是優先處理接近視口的塊。
位圖:可以簡單理解成用二維數組存儲的像素信息。
像素信息:例如(red, green, blue, alpha)。
合成線程會將塊信息交給GPU進程完成光柵化,而GPU進程內部又會開啟多個線程完成光柵化,優先處理靠近視口區域的塊。
畫 - Draw
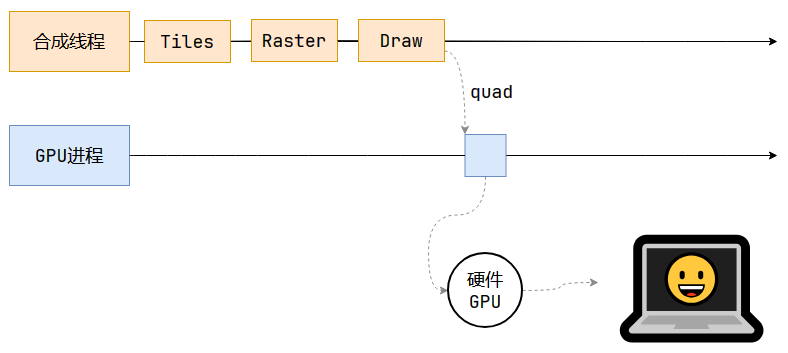
合成線程計算出每個位圖在屏幕上的位置,交給GPU進行最終呈現。
其中的quad稱為“指引信息”,指明位圖信息位于屏幕上的哪一個像素點。
為什么合成線程不直接將結果交給硬件,而要先轉交給GPU?
答:
合成線程和渲染主線程都是隸屬于渲染進程的,渲染進程處于沙盒中,無法進行系統調度,即無法直接與硬件GPU通信。
沙盒是一種瀏覽器安全策略,使得渲染進程無法直接與操作系統、硬件通信,可以避免一些網絡病毒的攻擊。
綜上,合成線程將計算結果先轉交給瀏覽器的GPU進程,再由其發送給硬件GPU,最終將內容顯示到屏幕上。
??CSS中的transform是在這一步確定的,只需要對位圖進行矩陣變換。
這也是transform效率高的主要原因,因為它與渲染主線程無關,這個過程發生在合成線程中。
相關面試題
瀏覽器是如何渲染頁面的?
答:
當瀏覽器的網絡線程收到 HTML 文檔后,會產生一個渲染任務,并將其傳遞給渲染主線程的消息隊列。
在事件循環機制的作用下,渲染主線程取出消息隊列中的渲染任務,開啟渲染流程。
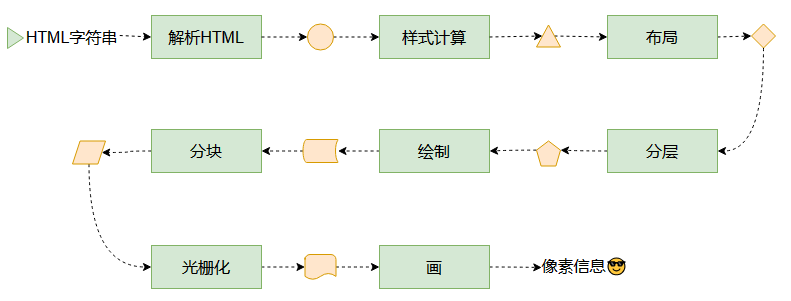
整個渲染流程分為多個階段,分別是:HTML解析、樣式計算、布局、分層、繪制、分塊、光柵化、畫。
每個階段都有明確的輸入輸出,上一個階段的輸出會成為下一個階段的輸入。
這樣,整個渲染流程就形成了一套組織嚴密的生產流水線。
渲染的第一步是解析HTML。
解析過程中遇到 CSS 解析 CSS,遇到 JS 執行 JS。為了提高解析效率,瀏覽器在開始解析前,會啟動一個預解析的線程,率先下載HTML中的外部CSS文件和外部的JS文件。
如果主線程解析到
link位置,此時外部的CSS文件還沒有下載解析好,主線程不會等待,繼續解析后續的HTML。這是因為下載和解析CSS的工作是在預解析線程中進行的。這就是CSS不會阻塞HTML解析的根本原因。如果主線程解析到
script位置,會停止解析HTML,轉而等待 JS 文件下載好,并將全局代碼解析執行完成后,才能繼續解析HTML。這是因為 JS 代碼的執行過程可能會修改當前的 DOM 樹,所以 DOM 樹的生成必須暫停。這就是 JS 會阻塞 HTML 解析的根本原因。第一步完成后,會得到 DOM 樹和 CSSOM 樹,瀏覽器的默認樣式、內部樣式、外部樣式、行內樣式均會包含在 CSSOM 樹中。
渲染的下一步是樣式計算。
主線程會遍歷得到的 DOM 樹,依次為樹中的每個節點計算出它最終的樣式,稱之為 Computed Style。
在這一過程中,很多預設值會變成絕對值,比如
red會變成rgb(255,0,0);相對單位會變成絕對單位,比如em會變成px這一步完成后,會得到一棵帶有樣式的 DOM 樹。
接下來是布局,布局完成后會得到布局樹。
布局階段會依次遍歷 DOM 樹的每一個節點,計算每個節點的幾何信息。例如節點的寬高、相對包含塊的位置。
大部分時候,DOM 樹和布局樹并非一一對應。
比如
display:none的節點沒有幾何信息,因此不會生成到布局樹;又比如使用了偽元素選擇器,雖然 DOM 樹中不存在這些偽元素節點,但它們擁有幾何信息,所以會生成到布局樹中。還有匿名行盒、匿名塊盒等等都會導致 DOM 樹和布局樹無法一一對應。
下一步是分層
主線程會使用一套復雜的策略對整個布局樹中進行分層。
分層的好處在于,將來某一個層改變后,僅會對該層進行后續處理,從而提升效率。
滾動條、堆疊上下文、transform、opacity 等樣式都會或多或少的影響分層結果,也可以通過
will-change屬性更大程度的影響分層結果。
再下一步是繪制
主線程會為每個層單獨產生繪制指令集,用于描述這一層的內容該如何畫出來。
完成繪制后,主線程將每個圖層的繪制信息提交給合成線程,剩余工作將由合成線程完成。
合成線程首先對每個圖層進行分塊,將其劃分為更多的小區域。
它會從線程池中拿取多個線程來完成分塊工作。
分塊完成后,進入光柵化階段。
合成線程會將塊信息交給 GPU 進程,以極高的速度完成光柵化。
GPU 進程會開啟多個線程來完成光柵化,并且優先處理靠近視口區域的塊。
光柵化的結果,就是一塊一塊的位圖
最后一個階段就是畫了
合成線程拿到每個層、每個塊的位圖后,生成一個個「指引(quad)」信息。
指引會標識出每個位圖應該畫到屏幕的哪個位置,以及會考慮到旋轉、縮放等變形。
變形發生在合成線程,與渲染主線程無關,這就是
transform效率高的本質原因。合成線程會把 quad 提交給 GPU 進程,由 GPU 進程產生系統調用,提交給 GPU 硬件,完成最終的屏幕成像。
什么是 reflow?
reflow 的本質就是重新計算 layout 樹。
當進行了會影響布局樹的操作后,需要重新計算布局樹,會引發 layout。
為了避免連續的多次操作導致布局樹反復計算,瀏覽器會合并這些操作,當 JS 代碼全部完成后再進行統一計算。所以,改動屬性造成的 reflow 是異步完成的。
也同樣因為如此,當 JS 獲取布局屬性時,就可能造成無法獲取到最新的布局信息。
瀏覽器在反復權衡下,最終決定獲取屬性立即 reflow。
什么是 repaint?
repaint 的本質就是重新根據分層信息計算了繪制指令。
當改動了可見樣式后,就需要重新計算,會引發 repaint。
由于元素的布局信息也屬于可見樣式,所以 reflow 一定會引起 repaint。
為什么 transform 的效率高?
因為 transform 既不會影響布局也不會影響繪制指令,它影響的只是渲染流程的最后一個「draw」階段
由于 draw 階段在合成線程中,所以 transform 的變化幾乎不會影響渲染主線程。反之,渲染主線程無論如何忙碌,也不會影響 transform 的變化。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號