
Stream4Graph:動態圖上的增量計算

作者:張奇
眾所周知,當我們需要對數據做關聯性分析的時候,一般會采用表連接(SQL join)的方式完成。但是SQL join時的笛卡爾積計算需要維護大量的中間結果,從而對整體的數據分析性能帶來巨大影響。相比而言,基于圖的方式維護數據的關聯性,原本的關聯性分析可以轉換為圖上的遍歷操作,從而大幅降低數據分析的成本。
然而,隨著數據規模的不斷增長,以及對數據處理更強的實時性需求,如何高效地解決大規模圖數據上的實時計算問題,就變得越來越緊迫。傳統的計算引擎,如Spark、Flink對于圖數據的處理已經逐漸不能滿足業務日益增長的訴求,因此設計一套面向大規模圖數據的實時處理引擎,將會對大數據處理技術革新帶來巨大的幫助。
螞蟻圖計算團隊開源的流圖計算引擎GeaFlow,結合了圖處理和流處理的技術優勢,實現了動態圖上的增量計算能力,在高性能關聯性分析的基礎上,進一步提升了圖計算的實時性。接下來向大家介紹圖計算技術的特點,業內如何解決大規模實時圖計算問題,以及GeaFlow在動態圖上的計算性能表現。
1. 圖計算
圖是一種數學結構,由節點和邊組成。節點代表各種實體,比如人、地點、事物或概念,而邊則表示這些節點之間的關系。例如:
- 社交媒體:節點可以代表用戶,邊可以表示朋友關系。
- 網頁:節點代表網頁,邊代表超鏈接。
- 交通網絡:節點代表城市,邊代表道路或航線。
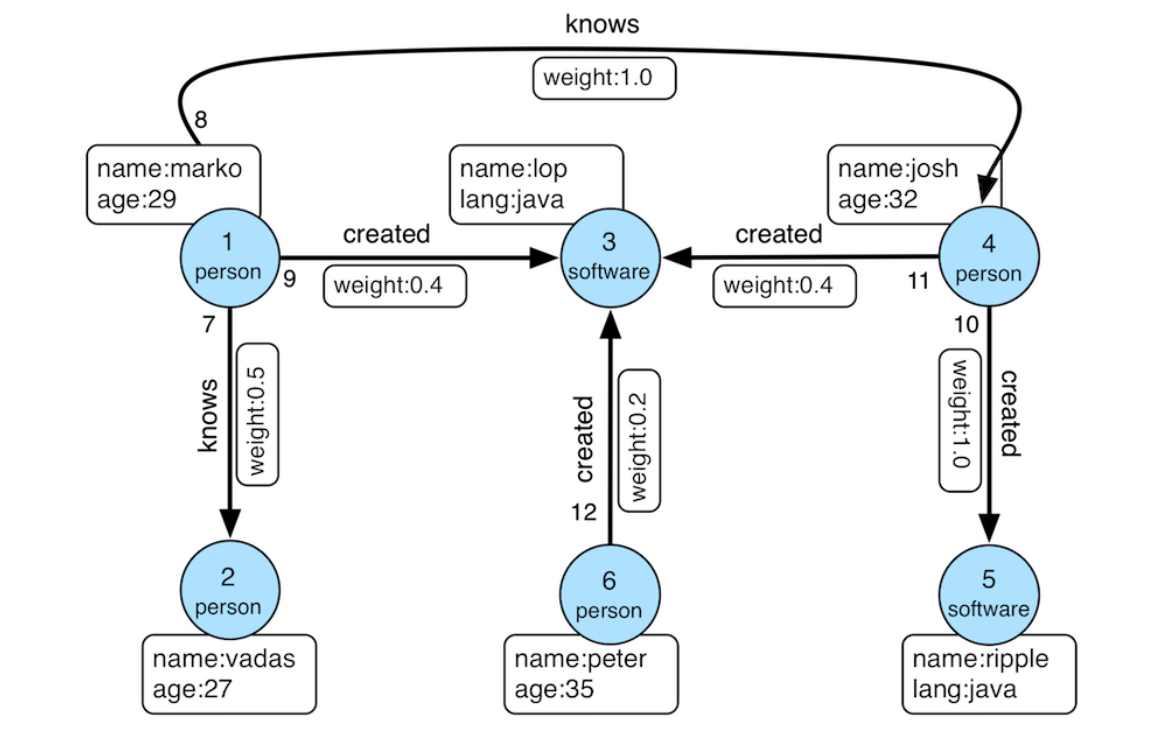
圖本身代表了節點與節點之間的鏈接關系,而針對這些關系,我們可以利用圖中的節點和邊來進行信息處理、分析和挖掘,幫助我們理解復雜系統中的關系和模式。在圖上開展的計算活動就是圖計算。圖計算有很多應用場景,比如通過社交網絡分析可以識別用戶之間的聯系,發現社群結構;通過分析網頁間的鏈接關系來計算網頁排名;通過用戶的行為和偏好構建關系圖,推薦相關內容和產品。
我們就以簡單的社交網絡分析算法,弱聯通分量(Weakly Connected Components, WCC)為例。弱聯通分量可以幫助我們識別用戶之間的“朋友圈”或“社區”,比如某個社交平臺上,一群用戶通過點贊、評論或關注形成一個大的弱聯通分量,而某些用戶可能沒有連接到這個大分量,形成更小的弱聯通分量。
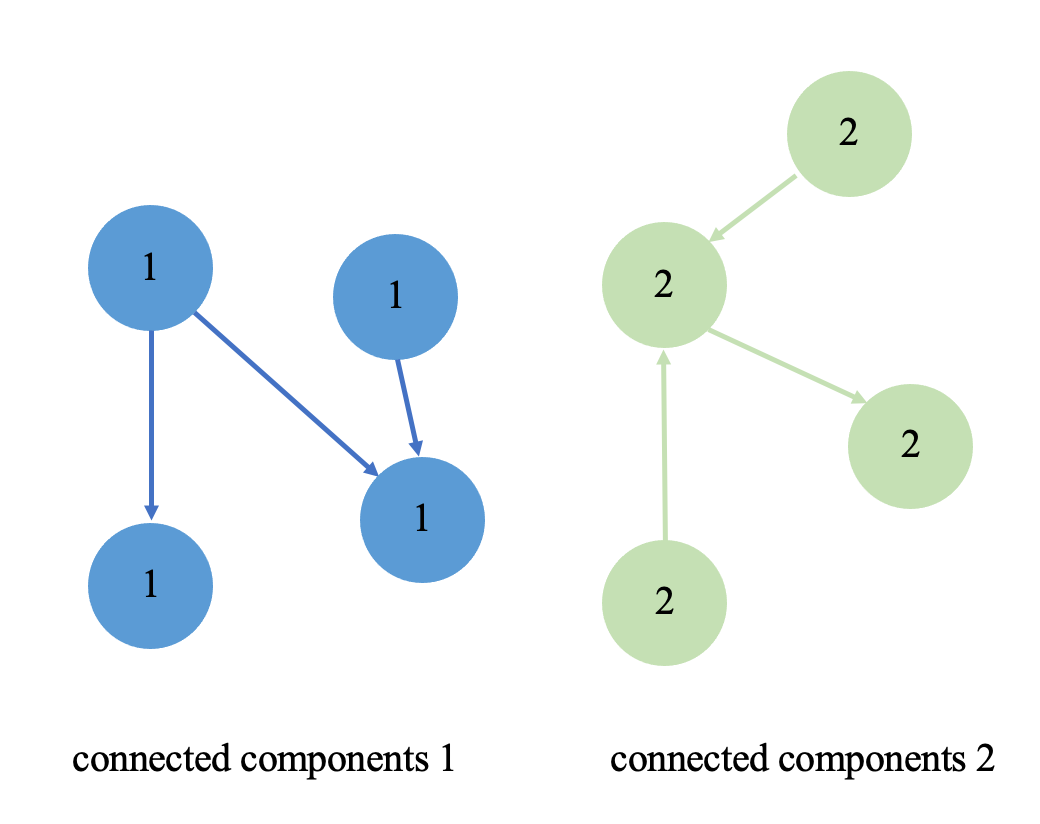
如果僅僅針對上面這張小圖來構建弱聯通分量算法,那么非常簡單,我們只需要在個人PC上構建簡單的點邊結構然后走圖遍歷即可。但如果圖的規模擴展的千億甚至萬億,這時就需要用到大規模分布式圖計算引擎來處理了。
2. 分布式圖計算:Spark GraphX
針對圖的處理一般有圖計算引擎和圖數據庫兩大類,圖數據庫有Neo4j?、TigerGraph?等,圖計算引擎有Spark GraphX、Pregel等。在本文我們主要討論圖計算引擎,以Spark GraphX為例,Spark GraphX是Apache Spark的一個組件,專門用于圖計算和圖分析。GraphX結合了Spark的強大數據處理能力與圖計算的靈活性,擴展了 Spark 的核心功能,為用戶提供了一個統一的API,便于處理圖數據。
那么在Spark GraphX上是如何處理圖算法的呢?GraphX通過引入一種點和邊都附帶屬性的有向多圖擴展了Spark RDD這種抽象數據結構,為用戶提供了一個類似于Pregel計算模型的以點為中心的并行抽象。用戶需要為GraphX提供原始圖graph、初始消息initialMsg、核心計算邏輯vprog、發送消息控制組件sendMsg、合并消息組件mergeMsg,計算開始時,GraphX初始階段會激活所有點進行初始化,然后按照用戶提供的發送消息組件確定接下來向那些點發送消息。在之后的迭代里,只有收到消息的點才會被激活,進行接下來的計算,如此循環往復直到鏈路中沒有被新激活的點或者到達最大迭代次數,最后輸出計算結果。
def apply[VD: ClassTag, ED: ClassTag, A: ClassTag]
(graph: Graph[VD, ED],
initialMsg: A,
maxIterations: Int = Int.MaxValue,
activeDirection: EdgeDirection = EdgeDirection.Either)
(vprog: (VertexId, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED]
{
var g = graph.mapVertices((vid, vdata) => vprog(vid, vdata, initialMsg))
// compute the messages
var messages = GraphXUtils.mapReduceTriplets(g, sendMsg, mergeMsg)
// Loop
var prevG: Graph[VD, ED] = null
var i = 0
while (isActiveMessagesNonEmpty && i < maxIterations) {
// Receive the messages and update the vertices.
prevG = g
g = g.joinVertices(messages)(vprog)
graphCheckpointer.update(g)
// Send new messages, skipping edges where neither side received
// a message.
messages = GraphXUtils.mapReduceTriplets(
g, sendMsg, mergeMsg, Some((oldMessages, activeDirection)))
}
}
總的來說,用戶首先需要將存儲介質中原始的表結構數據轉換為GraphX中的點邊數據類型,然后交給Spark進行處理,這是針對靜態圖進行離線處理。但是我們知道,現實世界中,圖數據的規模和數據內節點之間的關系都不是一成不變的,并且在大數據時代其變化非常快。如何實時高效的處理不斷變化的圖數據(動態圖),是一個值得深思的問題。
3. 動態圖計算:Spark Streaming
針對動態圖的處理,常見的解決方案是Spark Streaming框架,它可以從很多數據源消費數據并對數據進行處理。它是是Spark核心API的一個擴展,可以實現高吞吐量的、具備容錯機制的實時流數據的處理。
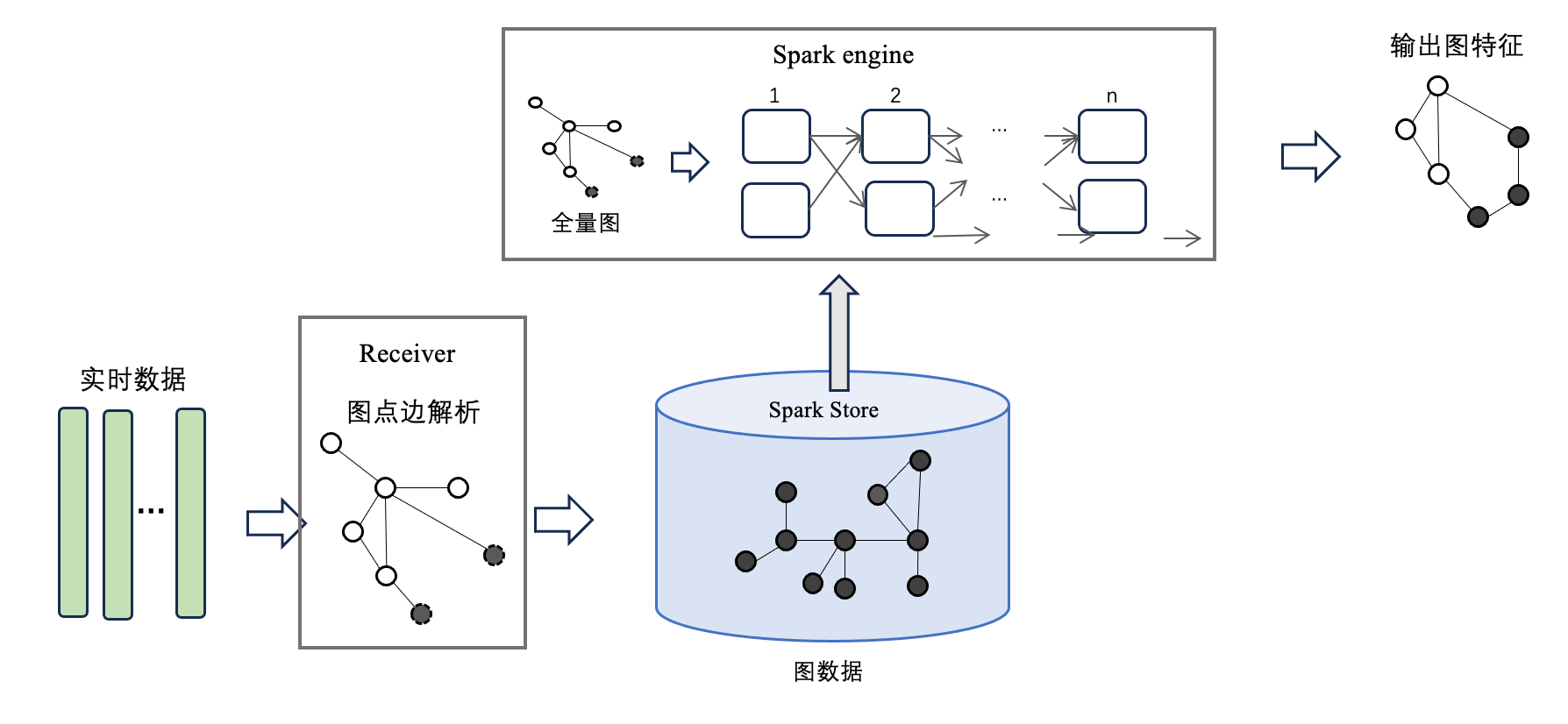
如上圖所示是Spark Streaming對實時數據進行處理的流程。首先Spark中的每個Receiver接收到實時消息流后,對實時消息進行解析和切分,之后將生成的圖數據存儲在每個Executor中。每當數據累積到一定的批次,就會觸發一次全量計算,最后將計算出的結果輸出給用戶,這也稱之為基于快照的圖計算方案。
但這種方案有一個比較大的缺點,就是它存在著重復計算的問題,假如我們需要以1小時一個窗口做一次計算,那么在使用Spark進行計算時,不僅要將當前窗口的數據計算進去,歷史所有數據也需要進行回溯,存在大量重復計算,這樣做效率不高,因此我們需要一套能夠進行增量計算的圖計算方案。
4. 動態圖增量計算:GeaFlow
我們知道在傳統的流計算引擎中,如Flink,其處理模型允許系統能夠處理不斷流入的數據事件。處理每個事件時,Flink 可以評估變化并僅針對變化的部分執行計算。這意味著在增量計算過程中,Flink 會關注最新到達的數據,而不是整個數據集。于是受到Flink增量計算的啟發,我們自研了增量圖計算系統GeaFlow(也叫流圖計算引擎),能夠很好的支持增量圖迭代計算。
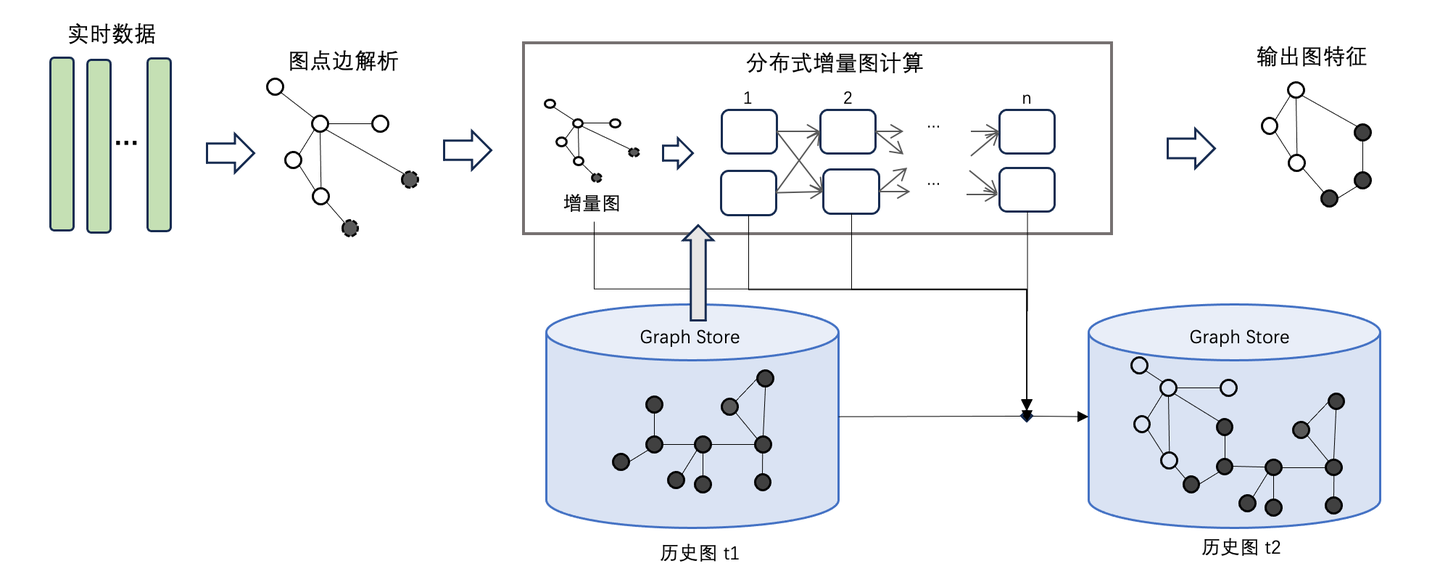
那么GeaFlow是如何實現增量圖計算的呢?首先,實時數據通過connector消息源輸入的GeaFlow中,GeaFlow依據實時數據,生成內部的點邊結構數據,并且將點邊數據插入進底圖中。當前窗口的實時數據涉及到的點會被激活,觸發圖迭代計算。
這里以WCC算法為例,對聯通分量算法而言,在一個時間窗口內每條邊對應的src id和tar id對應的頂點會被激活,第一次迭代需要將其id信息通知其鄰居節點。如果鄰居節點收到消息后,發現需要更新自己的信息,那么它需要繼續將更新消息通知給它的鄰居節點;如果說鄰居節點不需要更新自己的信息,那么它就不需要通知其鄰居節點,它對應的迭代終止。
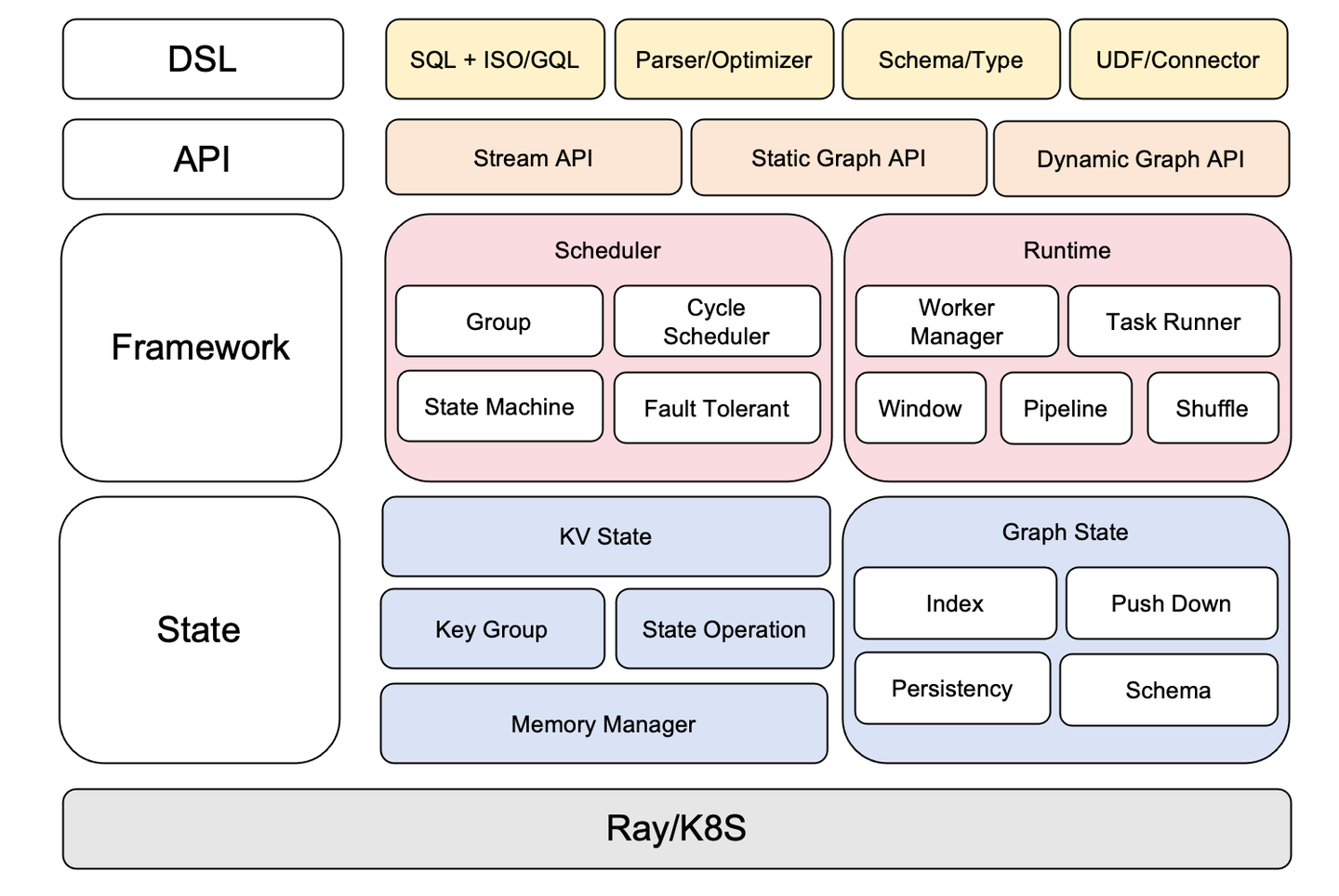
5. GeaFlow架構簡析
GeaFlow引擎主要由三大主要部分組成,DSL、Framework和State,同時向上為用戶提供了Stream API、靜態圖API和動態圖API。DSL主要負責圖查詢語言SQL+ISO/GQL的解析和執行計劃的優化,同時負責schema的推導,也向外部承接了多種Connector,比如hive、hudi、kafka、odps等。Framework層負責運行時的調度和容災,shuffle以及框架內各個組件的管理協調。State層負責存儲底層圖數據和數據的持久化,同時也負責索引、下推等眾多性能優化工作。
6. GeaFlow性能測試
為了驗證GeaFlow的增量圖計算性能,我們設計了這樣的實驗。一批數據按照固定時間窗口實時輸入到計算引擎中,我們分別用Spark和GeaFlow對全圖做聯通分量算法計算,比較兩者計算耗時。實驗在3臺24核內存128G的機器上開展,使用的數據集是公開數據集soc-Livejournal,測試的圖算法是弱聯通分量算法。我們以50w條數據作為一個計算窗口,每輸入到引擎中50w條數據,就觸發一次圖計算。
Spark作為批處理引擎,對于每一批窗口來的數據,不管窗口規模是大是小,都需要對增量圖數據連同歷史圖數據進行全量計算。在Spark上,可以直接調用Spark GraphX內部內置的WCC算法進行計算。
object SparkTest {
def main(args: Array[String]): Unit = {
val iter_num: Int = args(0).toInt
val parallel: Int = args(1).toInt
val spark = SparkSession.builder.appName("HDFS Data Load").config("spark.default.parallelism", args(1)).getOrCreate
val sc = new JavaSparkContext(spark.sparkContext)
val graph = GraphLoader.edgeListFile(sc, "hdfs://rayagsecurity-42-033147014062:9000/" + args(2), numEdgePartitions = parallel)
val result = graph.connectedComponents(10)
handleResult(result)
print("finish")
}
def handleResult[VD, ED](graph: Graph[VD, ED]): Unit = {
graph.vertices.foreachPartition(_.foreach(tuple => {
}))
}
}
GeaFlow上支持SQL+ISO/GQL的圖查詢語言,我們使用圖查詢語言調用GeaFlow內置的增量聯通分量圖算法進行測試,圖查詢語言代碼如下:
CREATE TABLE IF NOT EXISTS tables (
f1 bigint,
f2 bigint
) WITH (
type='file',
geaflow.dsl.window.size='16000',
geaflow.dsl.column.separator='\t',
test.source.parallel = '32',
geaflow.dsl.file.path = 'hdfs://xxxx:9000/com-friendster.ungraph.txt'
);
CREATE GRAPH modern (
Vertex v1 (
id int ID
),
Edge e1 (
srcId int SOURCE ID,
targetId int DESTINATION ID
)
) WITH (
storeType='memory',
shardCount = 256
);
INSERT INTO modern(v1.id, e1.srcId, e1.targetId)
(
SELECT f1, f1, f2
FROM tables
);
INSERT INTO modern(v1.id)
(
SELECT f2
FROM tables
);
CREATE TABLE IF NOT EXISTS tbl_result (
vid bigint,
component bigint
) WITH (
ignore='true',
type ='file'
);
use GRAPH modern;
INSERT INTO tbl_result
CALL inc_wcc(10) YIELD (vid, component)
RETURN vid, component
;
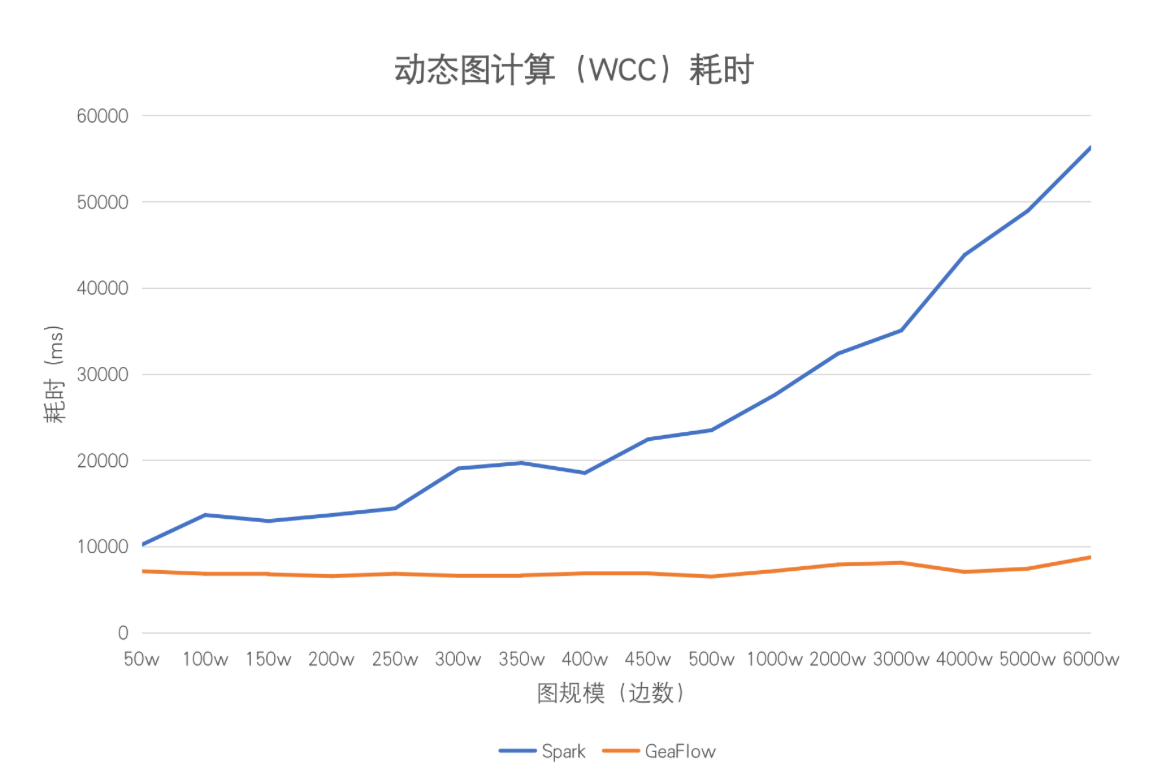
下圖是對兩者進行聯通分量算法實驗時得到的實驗結果。以50w條數據為一個窗口進行迭代計算,Spark中存在大量的重復計算,因為其還要回溯全量的歷史數據進行計算。而GeaFlow只會激活當前窗口中涉及到的點邊進行增量計算,計算可在秒級別完成,每個窗口的計算時間基本穩定。隨著數據量的不斷增大,Spark進行計算時所需要回溯的歷史數據就越多,在其機器容量沒有達到上限的情況下,其計算時延和數據量呈正相關分布。相同情況下GeaFlow的計算時間也會略微增大,但基本可以在秒級別完成。
7. 總結
傳統的圖計算方案(如Spark GraphX)在近實時場景中存在重復計算問題,受Flink流處理模型和傳統圖計算的啟發,我們給出了一套能夠支持增量圖計算的方案。總的來說GeaFlow主要有以下幾個方面的優勢:
- GeaFlow在處理增量實時計算時,性能優于Spark Streaming + GraphX方案,尤其是在大規模數據集上。
- GeaFlow通過增量計算避免了全量數據的重復處理,計算效率更高,計算時間更短性能不明顯下降。
- GeaFlow支持SQL+GQL混合處理語言,更適合開發復雜的圖數據處理任務。
GeaFlow項目代碼已全部開源,我們完成了部分流圖引擎基礎能力的構建,未來希望基于GeaFlow構建面向圖數據的統一湖倉處理引擎,以解決多樣化的大數據關聯性分析訴求。同時我們也在積極籌備加入Apache基金會,豐富大數據開源生態,因此非常歡迎對圖技術有濃厚興趣同學加入社區共建。
社區中有諸多有趣的工作尚待完成,你可以從如下簡單的「Good First Issue」開始,期待你加入同行。
- 支持Paimon Connector插件,連接數據湖生態。(Issue 361)
- 優化GQL match語句性能。(Issue 363)
- 新增ISO/GQL語法,支持same謂詞。(Issue 368)
- ...
參考鏈接
- GeaFlow項目地址:https://github.com/TuGraph-family/tugraph-analytics
- soc-Livejournal數據集地址:https://snap.stanford.edu/data/soc-LiveJournal1.html
- GeaFlow Issues:https://github.com/TuGraph-family/tugraph-analytics/issues
若本文對你有所幫助,您的 關注 和 推薦 是我分享知識的動力!

 浙公網安備 33010602011771號
浙公網安備 33010602011771號