
RAG七十二式:2024年度RAG清單

回顧2024,大模型日新月異,智能體百家爭鳴。作為AI應(yīng)用的重要組成部分,RAG也是“群雄逐鹿,諸侯并起”。年初ModularRAG持續(xù)升溫、GraphRAG大放異彩,年中開源工具如火如荼、知識圖譜再創(chuàng)新機,年末圖表理解、多模態(tài)RAG又啟新征程,簡直“你方唱罷我登場”,奇技疊出,不勝枚舉!
我在這里遴選了2024年度典型的RAG系統(tǒng)和論文(含AI注解、來源、摘要信息),并于文末附上RAG綜述和測試基準材料,望執(zhí)此一文,計一萬六千言,助大家速通RAG。
全文共72篇,逐月為綱,強謂之“RAG七十二式”,以獻諸位。
備注:
文中所有內(nèi)容已托管到開源倉庫Awesome-RAG,歡迎提交PR查缺補漏。
2024.01
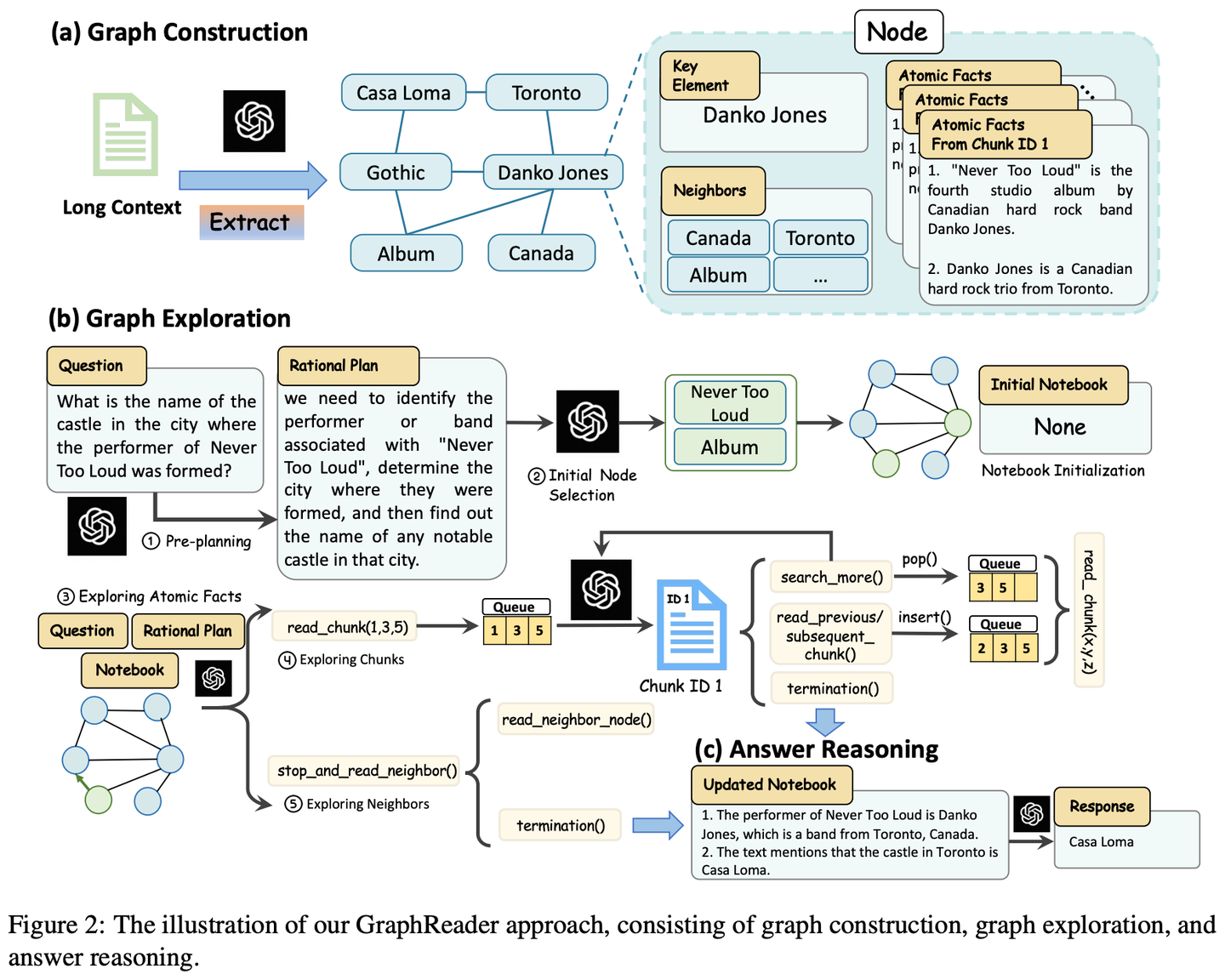
(01) GraphReader【圖解專家】
圖解專家:像個善于制作思維導(dǎo)圖的導(dǎo)師,將冗長的文本轉(zhuǎn)化為清晰的知識網(wǎng)絡(luò),讓AI能夠像沿著地圖探索一樣,輕松找到答案需要的各個關(guān)鍵點,有效克服了處理長文本時的"迷路"問題。
- 時間:01.20
- 論文:GraphReader: Building Graph-based Agent to Enhance Long-Context Abilities of Large Language Models
- 參考:https://mp.weixin.qq.com/s/eg3zIZ_3yhiJK83aTvQE2g
GraphReader是一種基于圖的智能體系統(tǒng),旨在通過將長文本構(gòu)建成圖并使用智能體自主探索該圖來處理長文本。在接收到問題后,智能體首先進行逐步分析并制定合理的計劃。然后,它調(diào)用一組預(yù)定義的函數(shù)來讀取節(jié)點內(nèi)容和鄰居,促進對圖進行從粗到細的探索。在整個探索過程中,智能體不斷記錄新的見解并反思當前情況以優(yōu)化過程,直到它收集到足夠的信息來生成答案。
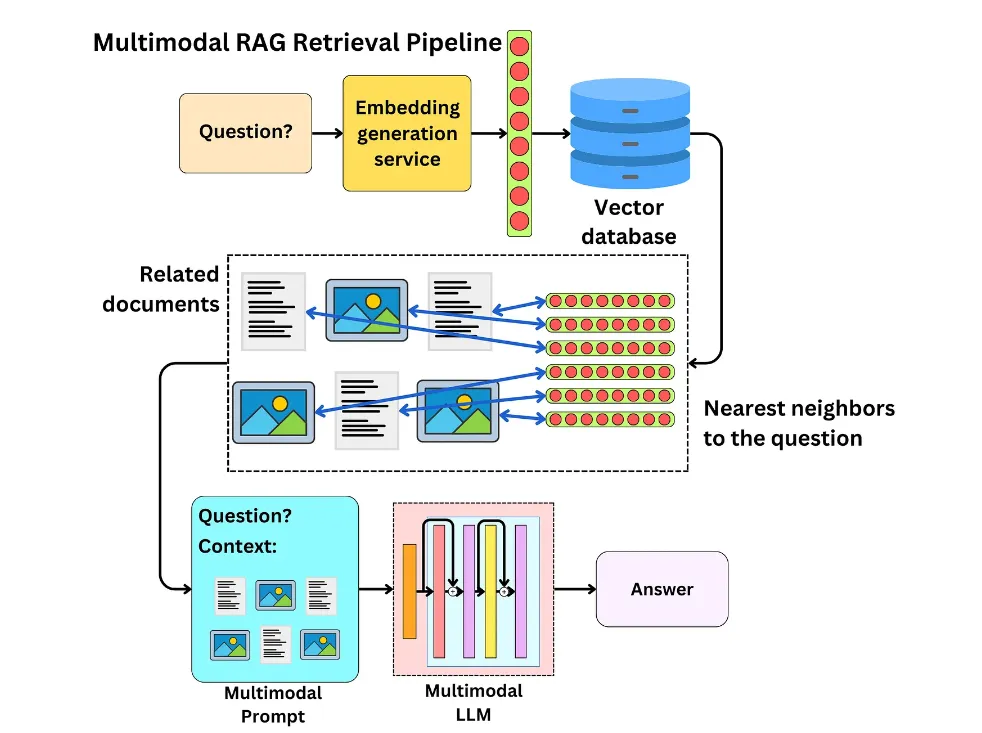
(02) MM-RAG【多面手】
多面手:就像一個能同時精通視覺、聽覺和語言的全能選手,不僅能理解不同形式的信息,還能在它們之間自如切換和關(guān)聯(lián)。通過對各種信息的綜合理解,它能在推薦、助手、媒體等多個領(lǐng)域提供更智能、更自然的服務(wù)。
介紹了多模態(tài)機器學(xué)習(xí)的發(fā)展,包括對比學(xué)習(xí)、多模態(tài)嵌入實現(xiàn)的任意模態(tài)搜索、多模態(tài)檢索增強生成(MM-RAG)以及如何使用向量數(shù)據(jù)庫構(gòu)建多模態(tài)生產(chǎn)系統(tǒng)等。同時還探討了多模態(tài)人工智能的未來發(fā)展趨勢,強調(diào)了其在推薦系統(tǒng)、虛擬助手、媒體和電子商務(wù)等領(lǐng)域的應(yīng)用前景。
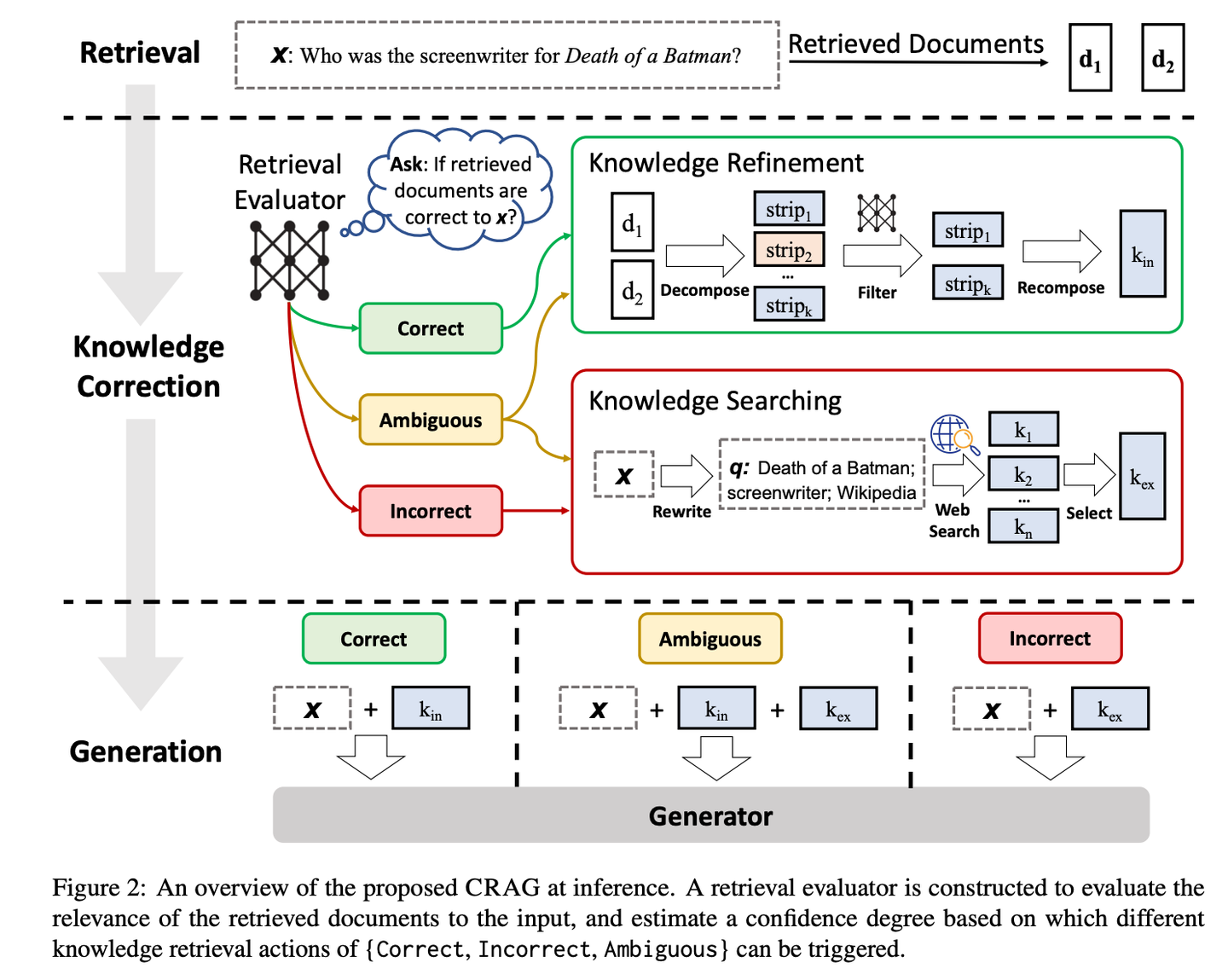
(03) CRAG【自我校正】
自我校正:像個經(jīng)驗豐富的編輯,先用簡單快速的方式篩選初步資料,再通過網(wǎng)絡(luò)搜索擴充信息,最后通過拆解重組的方式,確保最終呈現(xiàn)的內(nèi)容既準確又可靠。就像是給RAG裝上了一個質(zhì)量控制系統(tǒng),讓它產(chǎn)出的內(nèi)容更值得信賴。
- 時間:01.29
- 論文:Corrective Retrieval Augmented Generation
- 項目:https://github.com/HuskyInSalt/CRAG
- 參考:https://mp.weixin.qq.com/s/HTN66ca6OTF_2YcW0Mmsbw
CRAG通過設(shè)計輕量級的檢索評估器和引入大規(guī)模網(wǎng)絡(luò)搜索,來改進檢索文檔的質(zhì)量,并通過分解再重組算法進一步提煉檢索到的信息,從而提升生成文本的準確性和可靠性。CRAG是對現(xiàn)有RAG技術(shù)的有益補充和改進,它通過自我校正檢索結(jié)果,增強了生成文本的魯棒性。
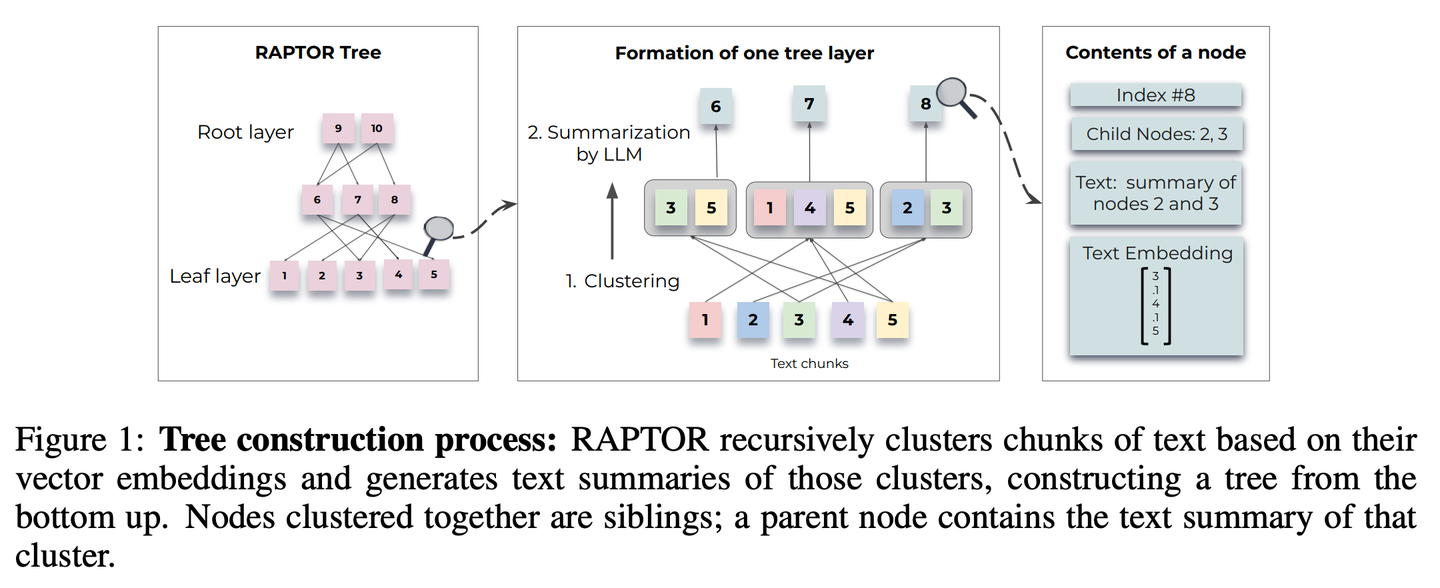
(04) RAPTOR【分層歸納】
分層歸納:像個善于組織的圖書管理員,將文檔內(nèi)容自下而上地整理成樹狀結(jié)構(gòu),讓信息檢索能在不同層級間靈活穿梭,既能看到整體概要,又能深入細節(jié)。
- 時間:01.31
- 論文:RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
- 項目:https://github.com/parthsarthi03/raptor
- 參考:https://mp.weixin.qq.com/s/8kt5qbHeTP1_ELY_YKwonA
RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)引入了一種新方法,即遞歸嵌入、聚類和總結(jié)文本塊,從下往上構(gòu)建具有不同總結(jié)級別的樹。在推理時,RAPTOR 模型從這棵樹中檢索,整合不同抽象級別的長文檔中的信息。
2024.02
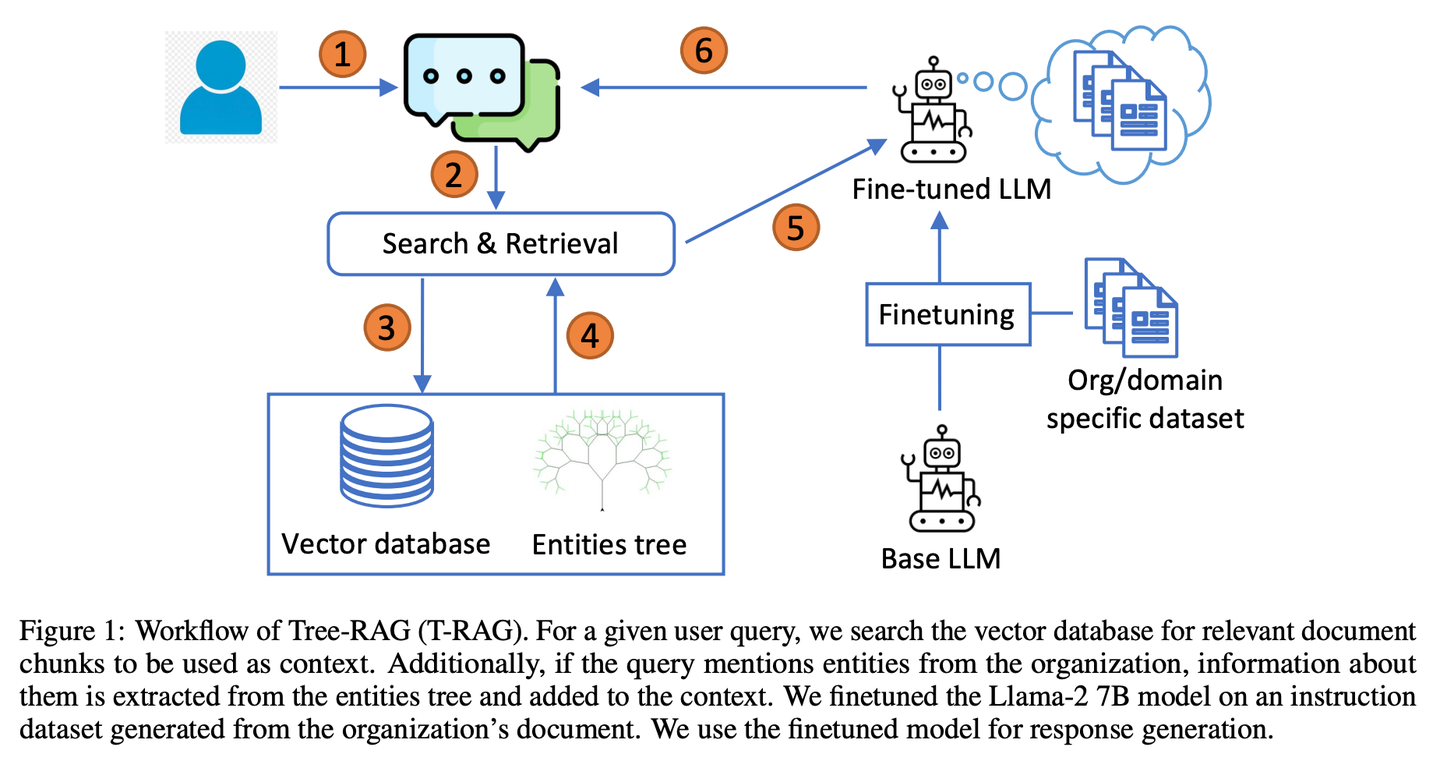
(05) T-RAG【私人顧問】
私人顧問:像個熟悉組織架構(gòu)的內(nèi)部顧問,善于利用樹狀結(jié)構(gòu)組織信息,在保護隱私的同時,高效且經(jīng)濟地提供本地化服務(wù)。
- 時間:02.12
- 論文:T-RAG: Lessons from the LLM Trenches
- 參考:https://mp.weixin.qq.com/s/ytEkDAuxK1tLecbFxa6vfA
T-RAG(樹狀檢索增強生成)結(jié)合RAG與微調(diào)的開源LLM,使用樹結(jié)構(gòu)來表示組織內(nèi)的實體層次結(jié)構(gòu)增強上下文,利用本地托管的開源模型來解決數(shù)據(jù)隱私問題,同時解決推理延遲、令牌使用成本以及區(qū)域和地理可用性問題。
2024.03
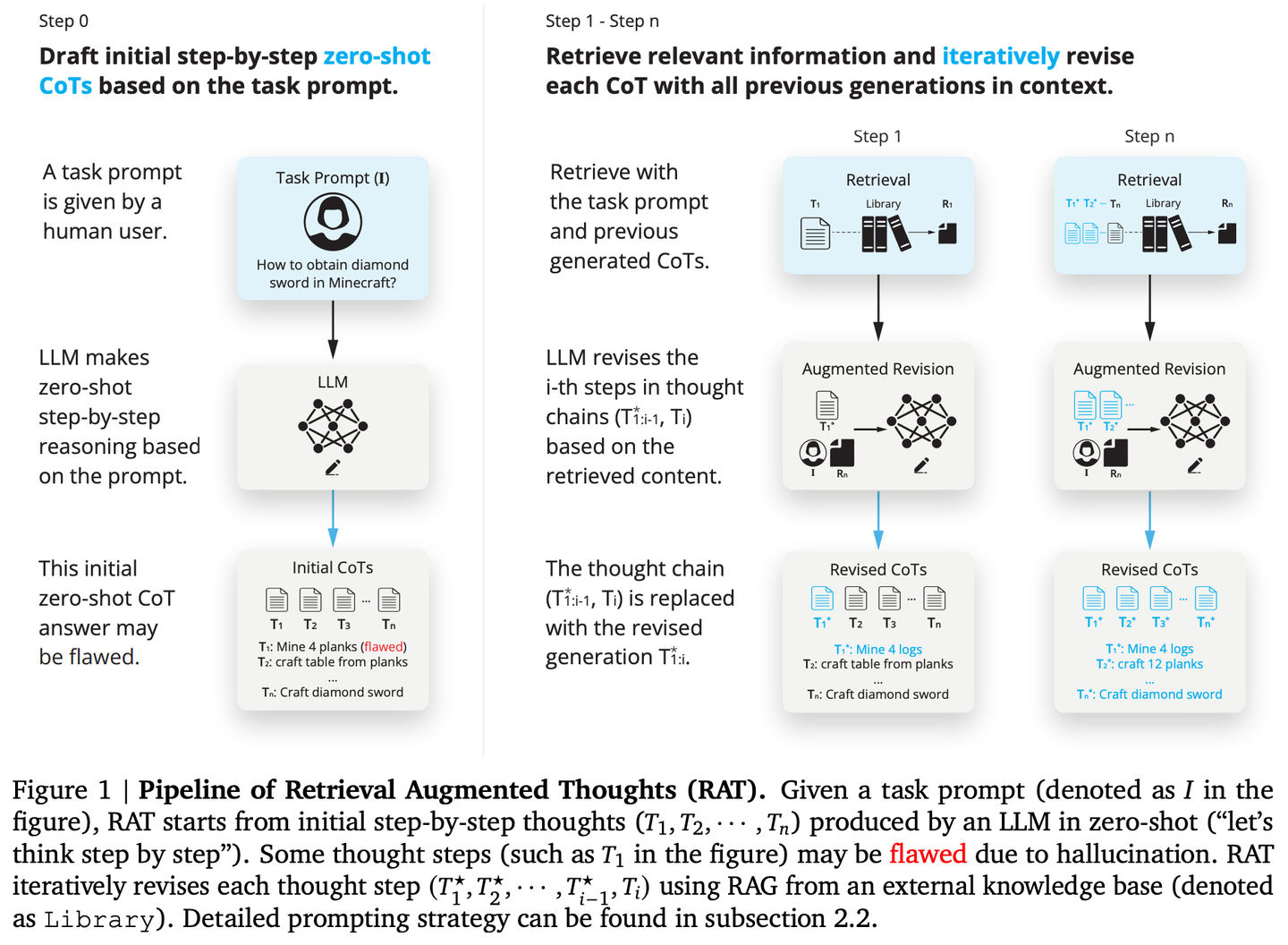
(06) RAT【思考者】
思考者:像個善于反思的導(dǎo)師,不是一次性得出結(jié)論,而是先有初步想法,然后利用檢索到的相關(guān)信息,不斷審視和完善每一步推理過程,讓思維鏈條更加嚴密可靠。
- 時間:03.08
- 論文:RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
- 項目:https://github.com/CraftJarvis/RAT
- 參考:https://mp.weixin.qq.com/s/TqmY4ouDuloE2v-iSJB_-Q
RAT(檢索增強思維)在生成初始零樣本思維鏈(CoT)后,利用與任務(wù)查詢、當前和過去思維步驟相關(guān)的檢索信息逐個修訂每個思維步驟,RAT可顯著提高各種長時生成任務(wù)上的性能。
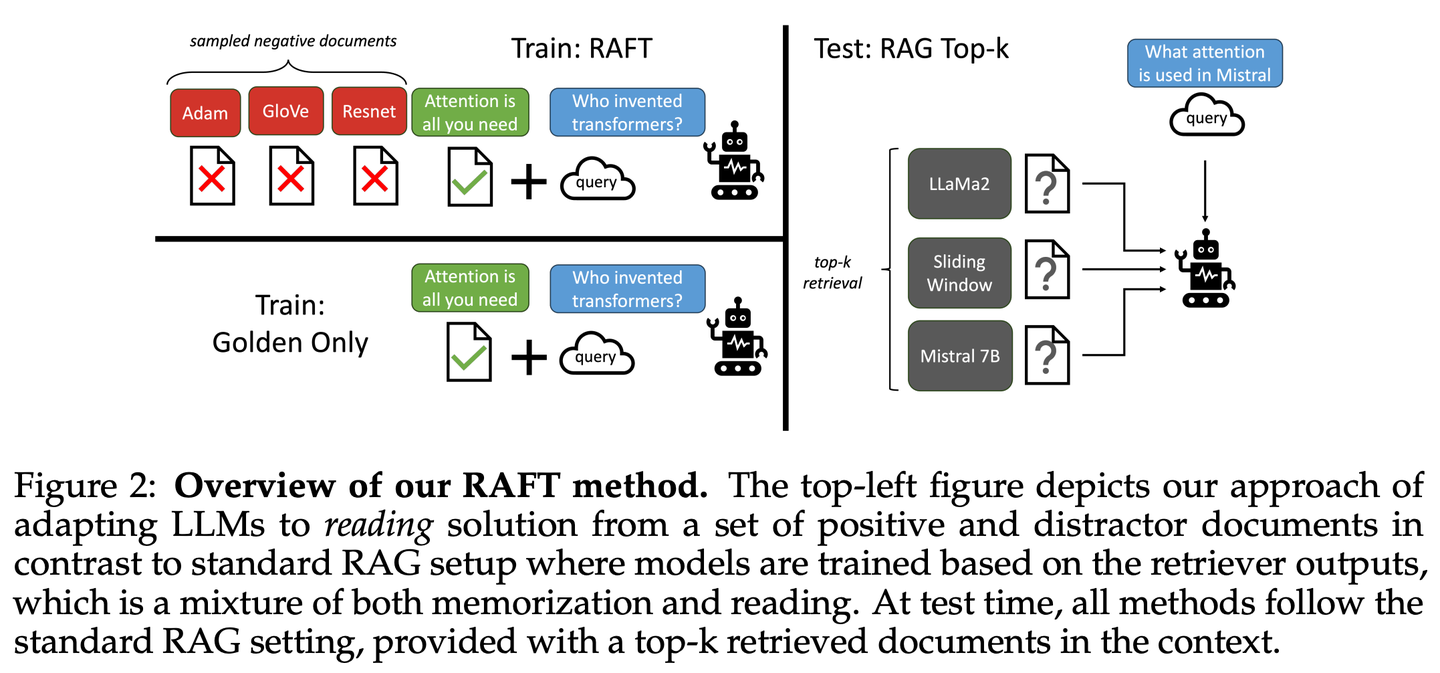
(07) RAFT【開卷高手】
開卷高手:像個優(yōu)秀的考生,不僅會找對參考資料,還能準確引用關(guān)鍵內(nèi)容,并清晰地解釋推理過程,讓答案既有據(jù)可循又合情合理。
- 時間:03.15
- 論文:RAFT: Adapting Language Model to Domain Specific RAG
- 參考:https://mp.weixin.qq.com/s/PPaviBpF8hdviqml3kPGIQ
RAFT旨在提高模型在特定領(lǐng)域內(nèi)的“開卷”環(huán)境中回答問題的能力,通過訓(xùn)練模型忽略無關(guān)文檔,并逐字引用相關(guān)文檔中的正確序列來回答問題,結(jié)合思維鏈式響應(yīng),顯著提升了模型的推理能力。
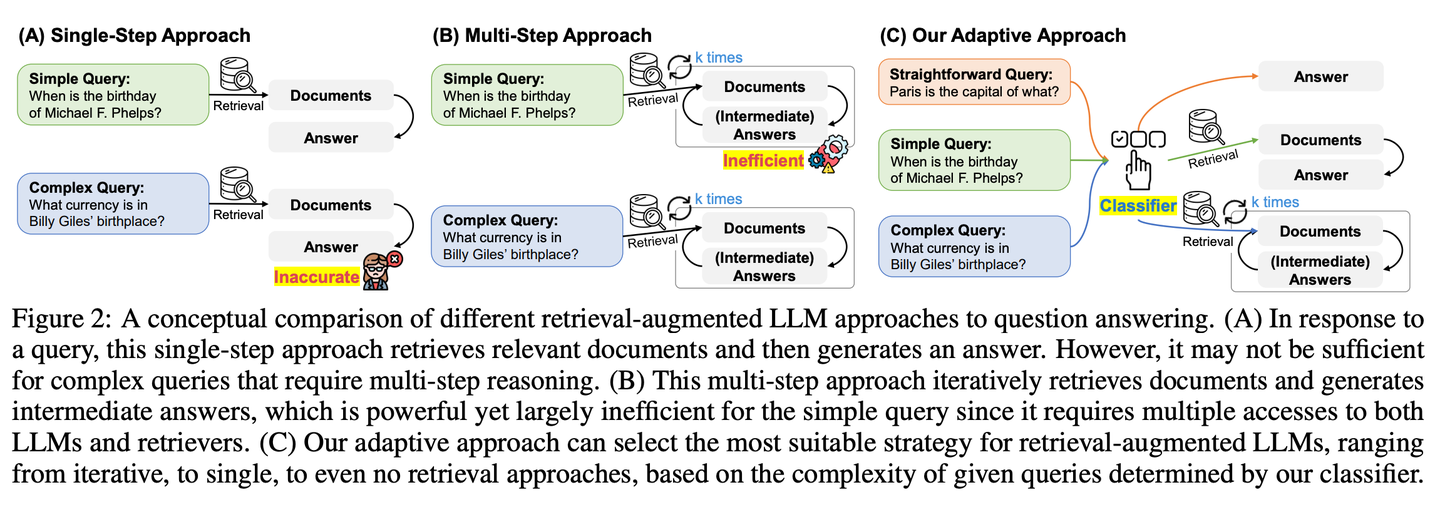
(08) Adaptive-RAG【因材施教】
因材施教:面對不同難度的問題,它會智能地選擇最合適的解答方式。簡單問題直接回答,復(fù)雜問題則會查閱更多資料或分步驟推理,就像一個經(jīng)驗豐富的老師,懂得根據(jù)學(xué)生的具體問題調(diào)整教學(xué)方法。
- 時間:03.21
- 論文:Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
- 項目:https://github.com/starsuzi/Adaptive-RAG
- 參考:https://mp.weixin.qq.com/s/sxAu8xahY-GthS--nfgmjg
Adaptive-RAG根據(jù)查詢的復(fù)雜程度動態(tài)選擇最適合的檢索增強策略,從最簡單到最復(fù)雜的策略中動態(tài)地為LLM選擇最合適的策略。這個選擇過程通過一個小語言模型分類器來實現(xiàn),預(yù)測查詢的復(fù)雜性并自動收集標簽以優(yōu)化選擇過程。這種方法提供了一種平衡的策略,能夠在迭代式和單步檢索增強型 LLMs 以及無檢索方法之間無縫適應(yīng),以應(yīng)對一系列查詢復(fù)雜度。
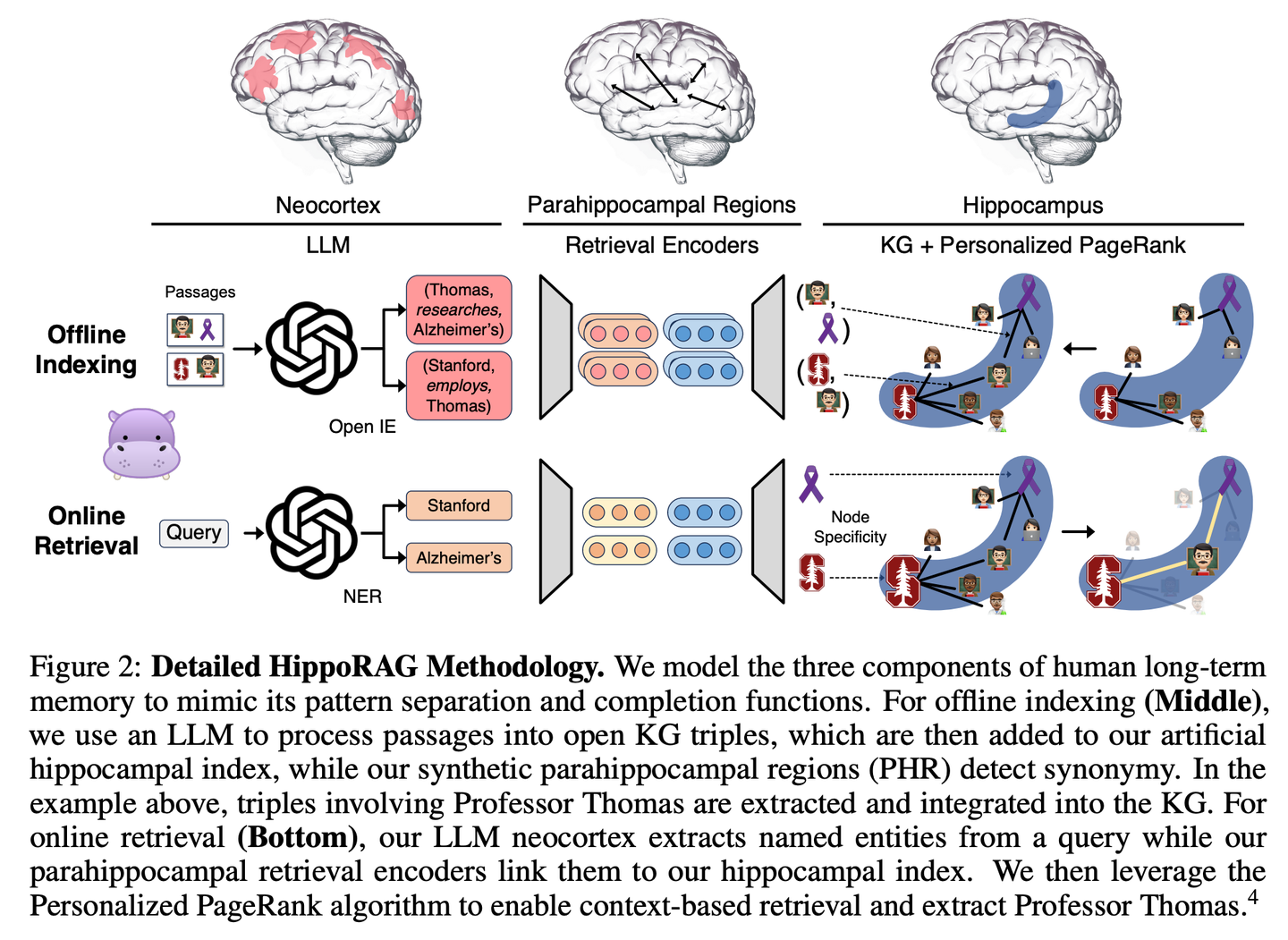
(09) HippoRAG【海馬體】
海馬體:像人腦海馬體一樣,把新舊知識巧妙編織成網(wǎng)。不是簡單地堆積信息,而是讓每條新知識都找到最恰當?shù)臍w屬。
- 時間:03.23
- 論文:HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
- 項目:https://github.com/OSU-NLP-Group/HippoRAG
- 參考:https://mp.weixin.qq.com/s/zhDw4SxX1UpnczEC3XyHGA
HippoRAG是一種新穎的檢索框架,其靈感來源于人類長期記憶的海馬體索引理論,旨在實現(xiàn)對新經(jīng)驗更深入、更高效的知識整合。HippoRAG協(xié)同編排 LLMs、知識圖譜和個性化PageRank算法,以模擬新皮層和海馬體在人類記憶中的不同角色。
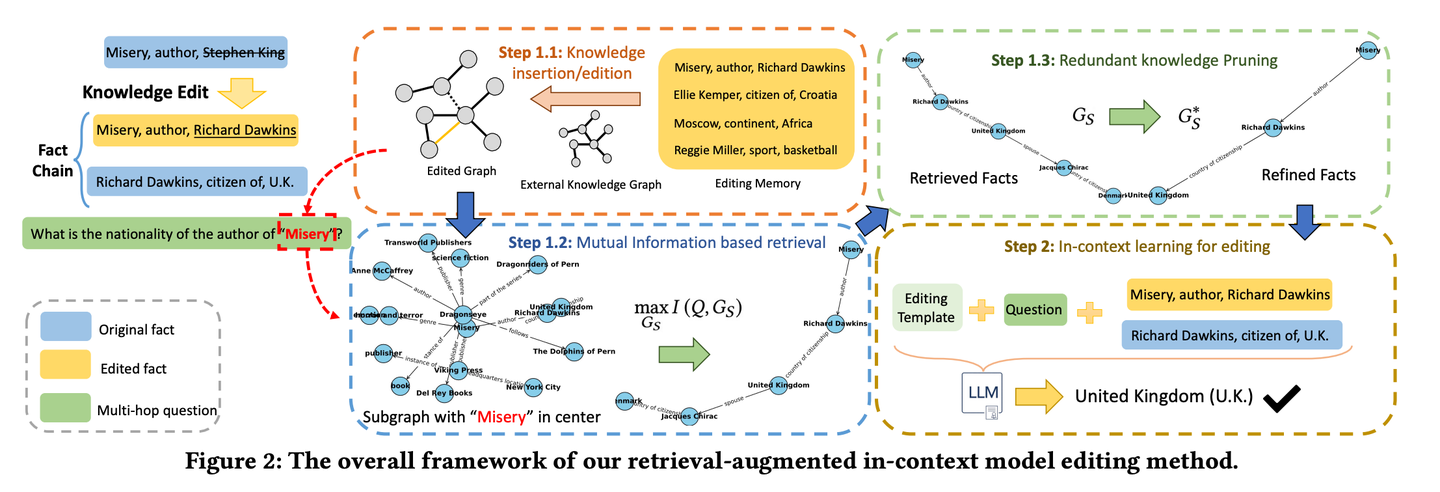
(10) RAE【智能編輯】
智能編輯:像個細心的新聞編輯,不僅會深入挖掘相關(guān)事實,還能通過連環(huán)推理找出容易被忽略的關(guān)鍵信息,同時懂得刪減冗余內(nèi)容,確保最終呈現(xiàn)的信息既準確又精煉,避免"說得天花亂墜卻不靠譜"的問題。
- 時間:03.28
- 論文:Retrieval-enhanced Knowledge Editing in Language Models for Multi-Hop Question Answering
- 項目:https://github.com/sycny/RAE
- 參考:https://mp.weixin.qq.com/s/R0N8yexAlXetFyCS-W2dvg
RAE(多跳問答檢索增強模型編輯框架)首先檢索經(jīng)過編輯的事實,然后通過上下文學(xué)習(xí)來優(yōu)化語言模型。基于互信息最大化的檢索方法利用大型語言模型的推理能力來識別傳統(tǒng)基于相似性的搜索可能會錯過的鏈式事實。此外框架包括一種修剪策略,以從檢索到的事實中消除冗余信息,這提高了編輯準確性并減輕了幻覺問題。
2024.04
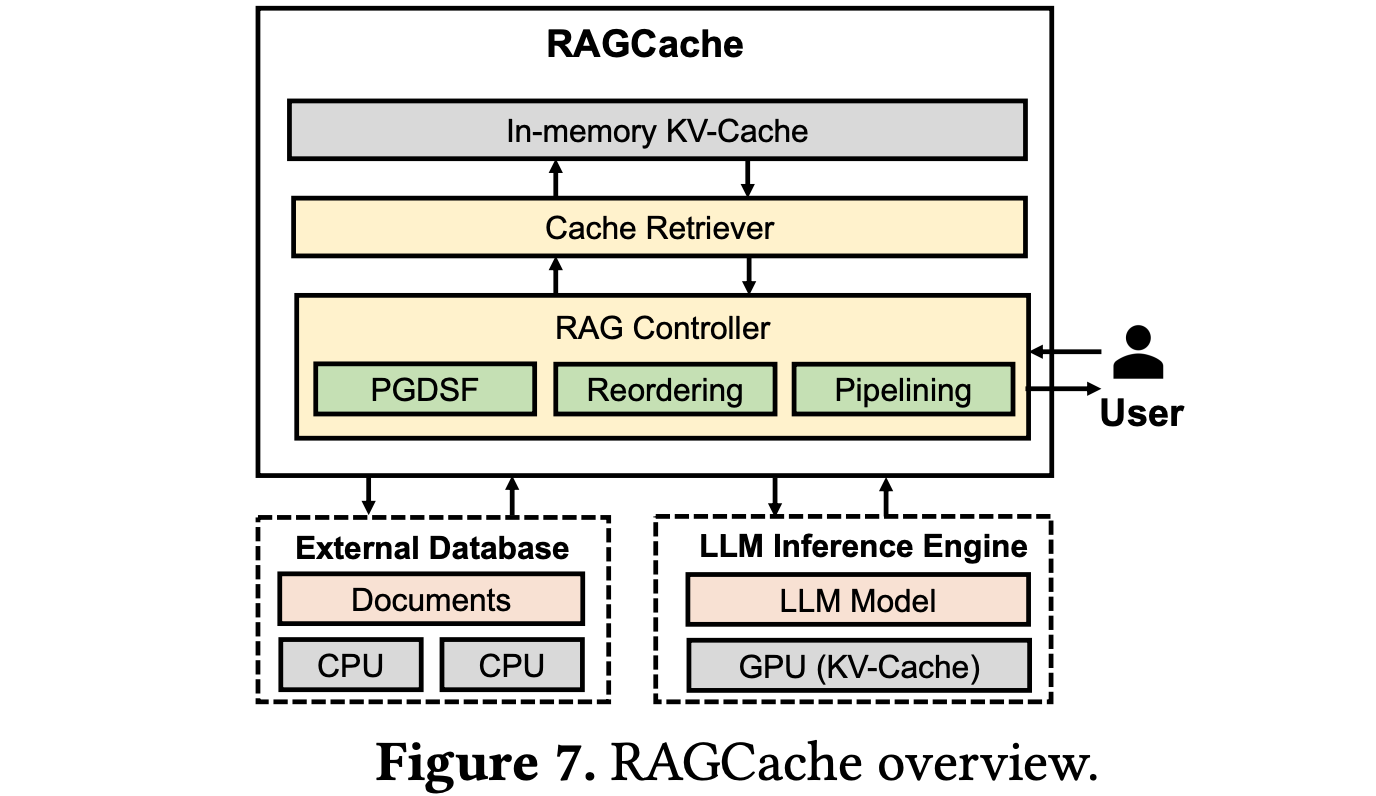
(11) RAGCache【倉儲員】
倉儲員:像大型物流中心一樣,把常用知識放在最容易取的貨架上。懂得把經(jīng)常用的包裹放在門口,把不常用的放在后倉,讓取貨效率最大化。
- 時間:04.18
- 論文:RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation
- 參考:https://mp.weixin.qq.com/s/EOf51zoycmUCKkIo8rPsZw
RAGCache是一種為RAG量身定制的新型多級動態(tài)緩存系統(tǒng),它將檢索到的知識的中間狀態(tài)組織在知識樹中,并在GPU和主機內(nèi)存層次結(jié)構(gòu)中進行緩存。RAGCache提出了一種考慮到LLM推理特征和RAG檢索模式的替換策略。它還動態(tài)地重疊檢索和推理步驟,以最小化端到端延遲。
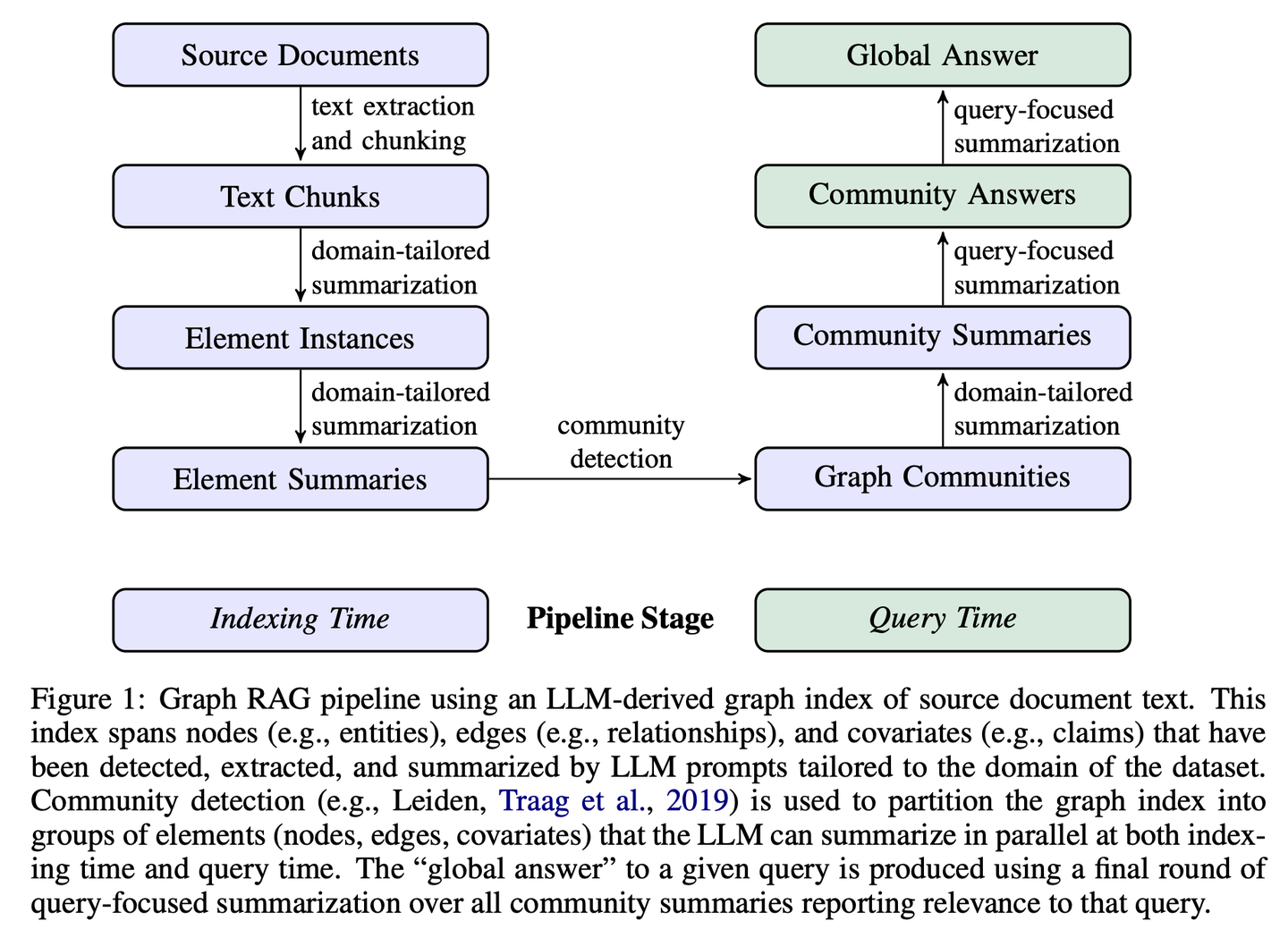
(12) GraphRAG【社區(qū)摘要】
社區(qū)摘要:先把小區(qū)居民的關(guān)系網(wǎng)理清楚,再給每個鄰里圈做個簡介。有人問路時,各個鄰里圈提供線索,最后整合成最完整的答案。
- 時間:04.24
- 論文:From Local to Global: A Graph RAG Approach to Query-Focused Summarization
- 項目:https://github.com/microsoft/graphrag
- 參考:https://mp.weixin.qq.com/s/I_-rpMNVoQz-KvUlgQH-2w
GraphRAG分兩個階段構(gòu)建基于圖的文本索引:首先從源文檔中推導(dǎo)出實體知識圖,然后為所有緊密相關(guān)實體的組預(yù)生成社區(qū)摘要。給定一個問題,每個社區(qū)摘要用于生成部分響應(yīng),然后在向用戶的最終響應(yīng)中再次總結(jié)所有部分響應(yīng)。
2024.05
(13) R4【編排大師】
編排大師:像個排版高手,通過優(yōu)化材料的順序和呈現(xiàn)方式來提升輸出質(zhì)量,無需改動核心模型就能讓內(nèi)容更有條理,重點更突出。
- 時間:05.04
- 論文:R4: Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models
- 參考:https://mp.weixin.qq.com/s/Lsom93jtIr4Pv7DjpQuiDQ
R4 (Reinforced Retriever-Reorder-Responder)用于為檢索增強型大語言模型學(xué)習(xí)文檔排序,從而在大語言模型的大量參數(shù)保持凍結(jié)的情況下進一步增強其生成能力。重排序?qū)W習(xí)過程根據(jù)生成響應(yīng)的質(zhì)量分為兩個步驟:文檔順序調(diào)整和文檔表示增強。具體來說,文檔順序調(diào)整旨在基于圖注意力學(xué)習(xí)將檢索到的文檔排序組織到開頭、中間和結(jié)尾位置,以最大化響應(yīng)質(zhì)量的強化獎勵。文檔表示增強通過文檔級梯度對抗學(xué)習(xí)進一步細化質(zhì)量較差的響應(yīng)的檢索文檔表示。
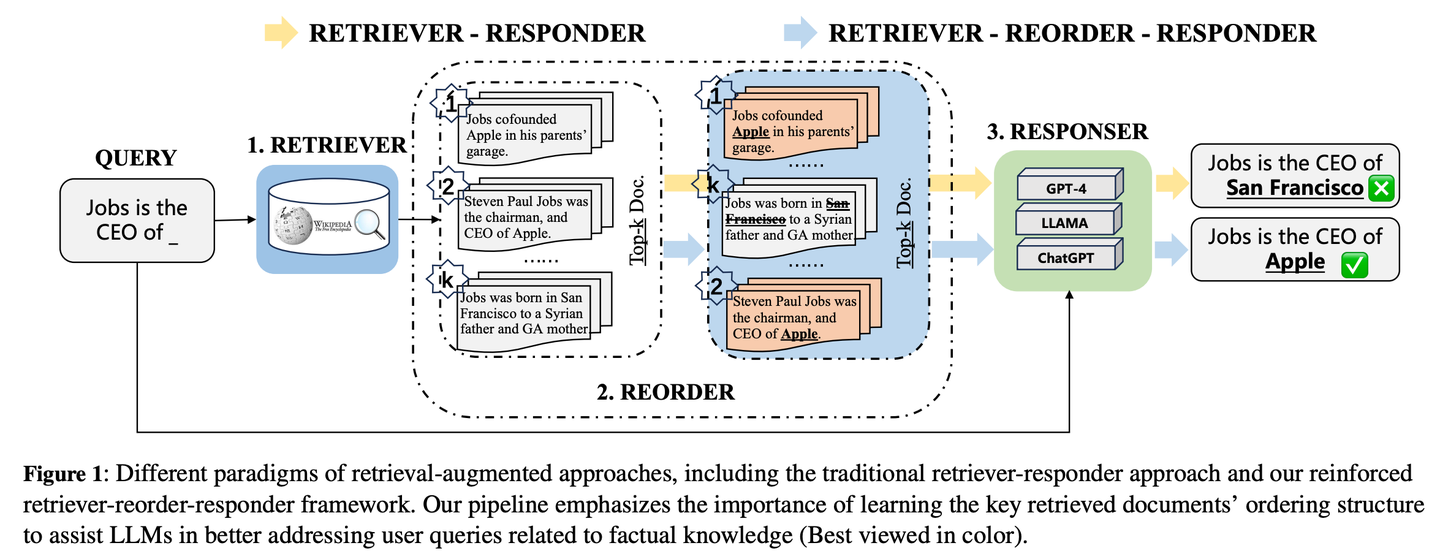
(14) IM-RAG【自言自語】
自言自語:遇到問題時會在心里盤算"我需要查什么資料"、"這個信息夠不夠",通過不斷的內(nèi)心對話來完善答案,這種"獨白"能力像人類專家一樣,能夠逐步深入思考并解決復(fù)雜問題。
- 時間:05.15
- 論文:IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
- 參考:https://mp.weixin.qq.com/s/O6cNeBAT5f_nQM5hRaQUnw
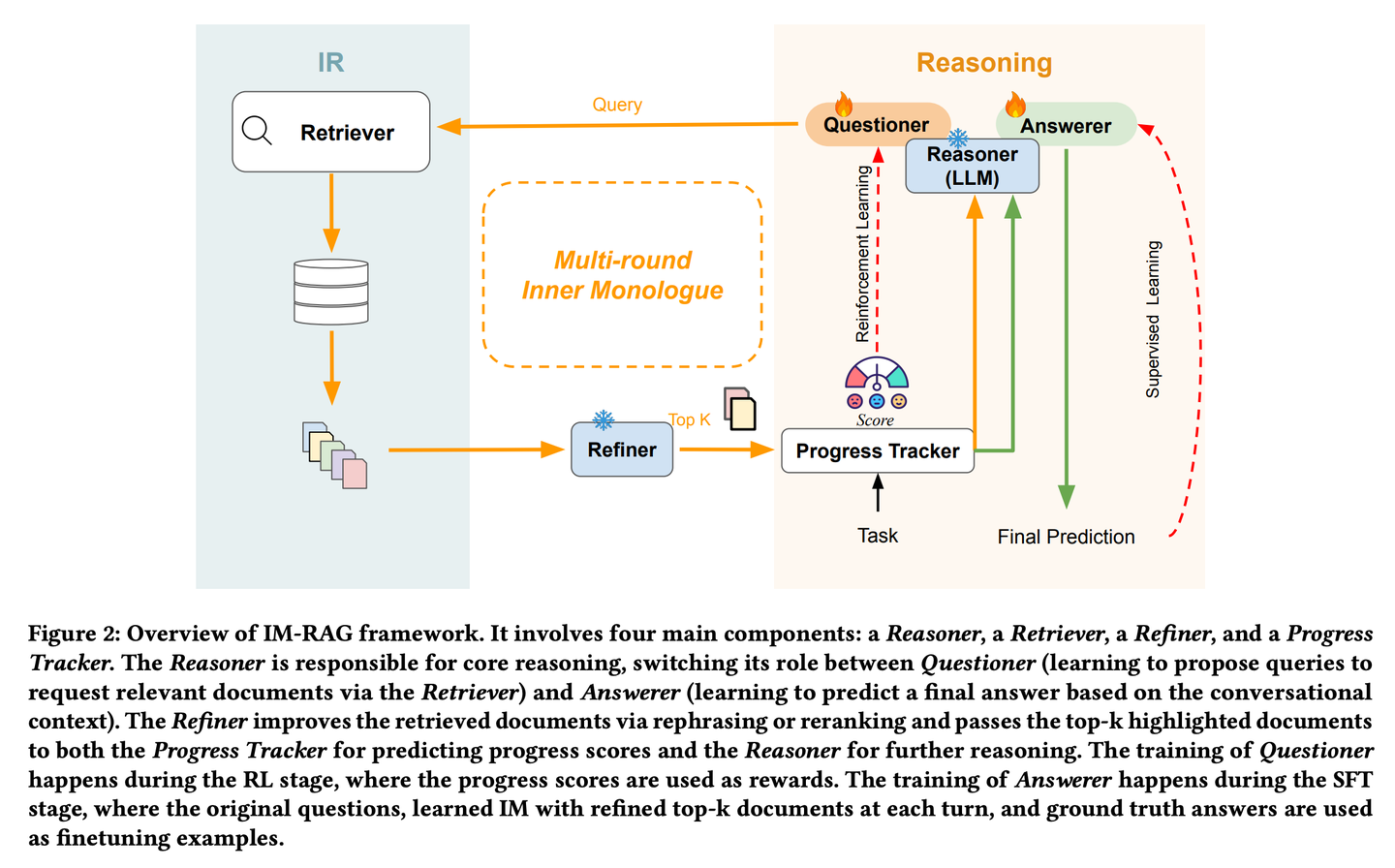
IM-RAG通過學(xué)習(xí)內(nèi)部獨白(Inner Monologues)來連接IR系統(tǒng)與LLMs,從而支持多輪檢索增強生成。該方法將信息檢索系統(tǒng)與大型語言模型相整合,通過學(xué)習(xí)內(nèi)心獨白來支持多輪檢索增強生成。在內(nèi)心獨白過程中,大型語言模型充當核心推理模型,它既可以通過檢索器提出查詢以收集更多信息,也可以基于對話上下文提供最終答案。我們還引入了一個優(yōu)化器,它能對檢索器的輸出進行改進,有效地彌合推理器與能力各異的信息檢索模塊之間的差距,并促進多輪通信。整個內(nèi)心獨白過程通過強化學(xué)習(xí)(RL)進行優(yōu)化,在此過程中還引入了一個進展跟蹤器來提供中間步驟獎勵,并且答案預(yù)測會通過監(jiān)督微調(diào)(SFT)進一步單獨優(yōu)化。
(15) AntGroup-GraphRAG【百家之長】
百家之長:匯集行業(yè)百家之長,擅用多種方式快速定位信息,既能提供精準檢索,又能理解自然語言查詢,讓復(fù)雜的知識檢索變得既經(jīng)濟又高效。
- 時間:05.16
- 項目:https://github.com/eosphoros-ai/DB-GPT
- 參考:https://mp.weixin.qq.com/s/LfhAY91JejRm_A6sY6akNA
螞蟻TuGraph團隊基于DB-GPT構(gòu)建的開源GraphRAG框架,兼容了向量、圖譜、全文等多種知識庫索引底座,支持低成本的知識抽取、文檔結(jié)構(gòu)圖譜、圖社區(qū)摘要與混合檢索以解決QFS問答問題。另外也提供了關(guān)鍵詞、向量和自然語言等多樣化的檢索能力支持。
(16) Kotaemon【樂高】
樂高:一套現(xiàn)成的問答積木套裝,既能直接拿來用,又能自由拆裝改造。用戶要用就用,開發(fā)要改就改,隨心所欲不失章法。
- 時間:05.15
- 項目:https://github.com/Cinnamon/kotaemon
- 參考:https://mp.weixin.qq.com/s/SzoE2Hb82a6yUU7EcfF5Hg
一個開源的干凈且可定制的RAG UI,用于構(gòu)建和定制自己的文檔問答系統(tǒng)。既考慮了最終用戶的需求,也考慮了開發(fā)者的需求。

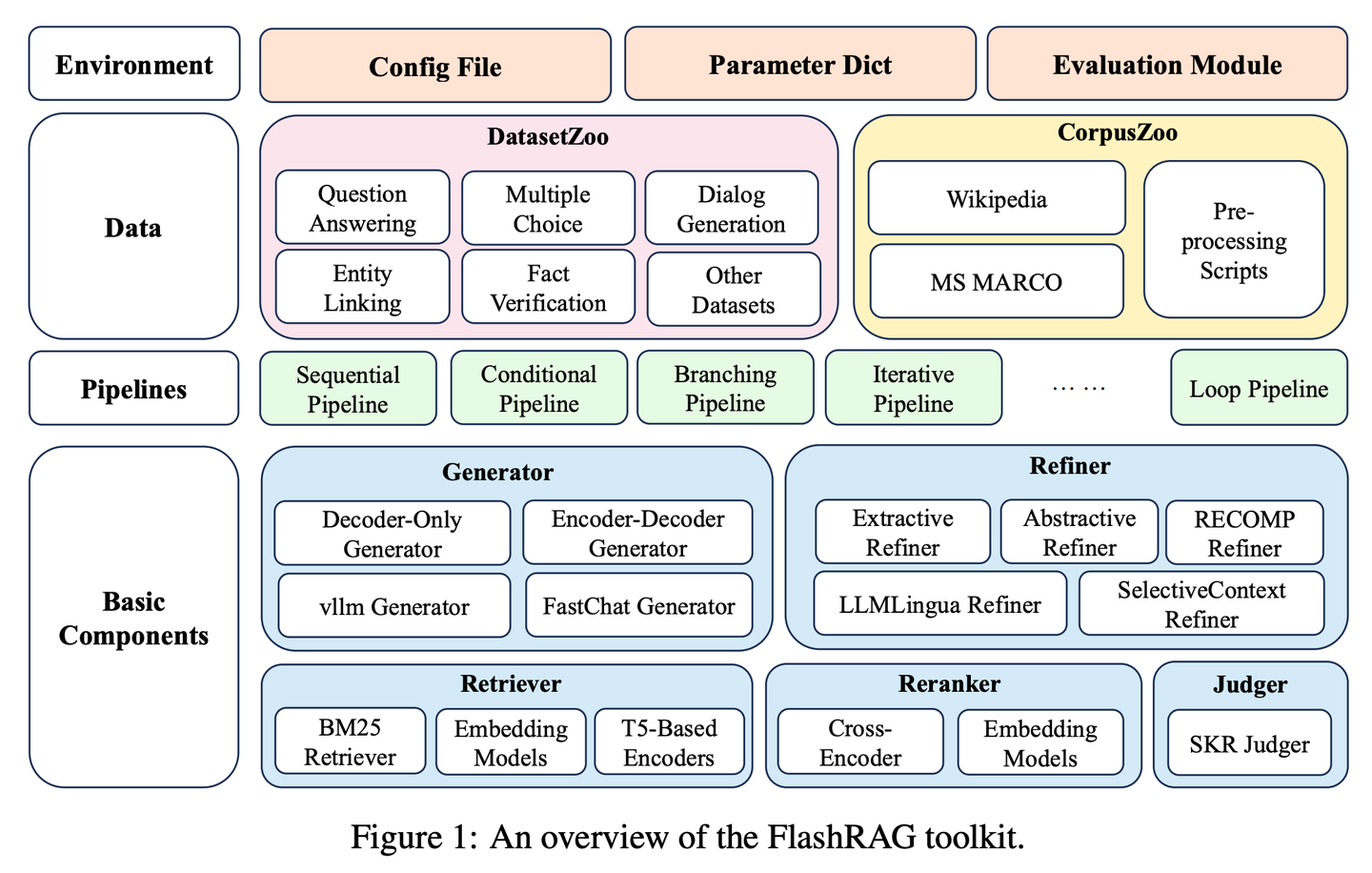
(17) FlashRAG【百寶箱】
百寶箱:把各路RAG神器打包成一個工具包,讓研究者像挑選積木一樣,隨心所欲地搭建自己的檢索模型。
- 時間:05.22
- 論文:FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research
- 項目:https://github.com/RUC-NLPIR/FlashRAG
- 參考:https://mp.weixin.qq.com/s/vvOdcARaU1LD6KgcdShhoA
FlashRAG是一個高效且模塊化的開源工具包,旨在幫助研究人員在統(tǒng)一框架內(nèi)重現(xiàn)現(xiàn)有的RAG方法并開發(fā)他們自己的RAG算法。我們的工具包實現(xiàn)了12種先進的RAG方法,并收集和整理了32個基準數(shù)據(jù)集。
(18) GRAG【偵探】
偵探:不滿足于表面線索,深入挖掘文本之間的關(guān)聯(lián)網(wǎng)絡(luò),像破案一樣追蹤每條信息背后的真相,讓答案更準確。
- 時間:05.26
- 論文:GRAG: Graph Retrieval-Augmented Generation
- 項目:https://github.com/HuieL/GRAG
- 參考:https://mp.weixin.qq.com/s/xLVaFVr7rnYJq0WZLsFVMw
傳統(tǒng)RAG模型在處理復(fù)雜的圖結(jié)構(gòu)數(shù)據(jù)時忽視了文本之間的聯(lián)系和數(shù)據(jù)庫的拓撲信息,從而導(dǎo)致了性能瓶頸。GRAG通過強調(diào)子圖結(jié)構(gòu)的重要性,顯著提升了檢索和生成過程的性能并降低幻覺。
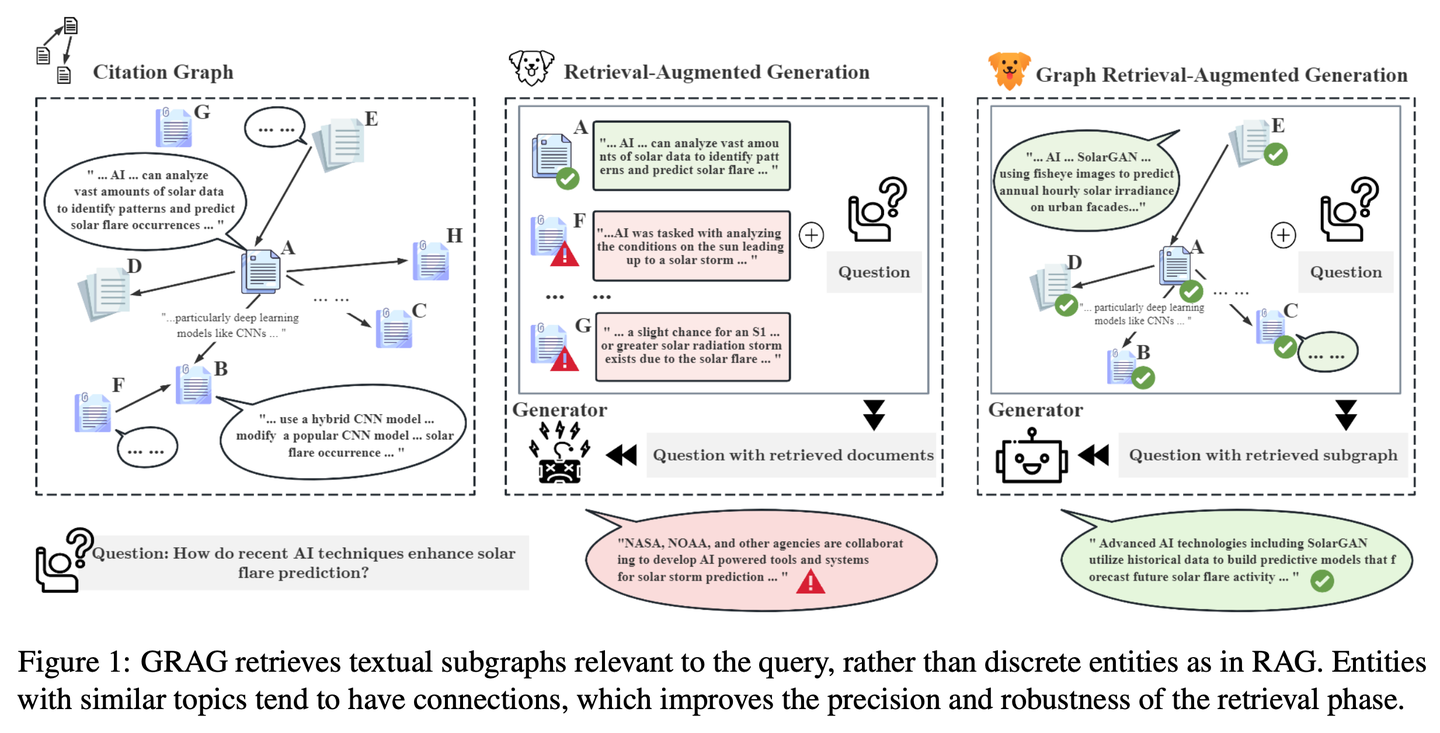
(19) Camel-GraphRAG【左右開弓】
左右開弓:一只眼睛用Mistral掃描文本提取情報,另只眼睛用Neo4j編織關(guān)系網(wǎng)。查找時左右眼配合,既能找相似的,又能順著線索圖追蹤,讓搜索更全面精準。
Camel-GraphRAG依托Mistral模型提供支持,從給定的內(nèi)容中提取知識并構(gòu)建知識結(jié)構(gòu),然后將這些信息存儲在 Neo4j圖數(shù)據(jù)庫中。隨后采用一種混合方法,將向量檢索與知識圖譜檢索相結(jié)合,來查詢和探索所存儲的知識。
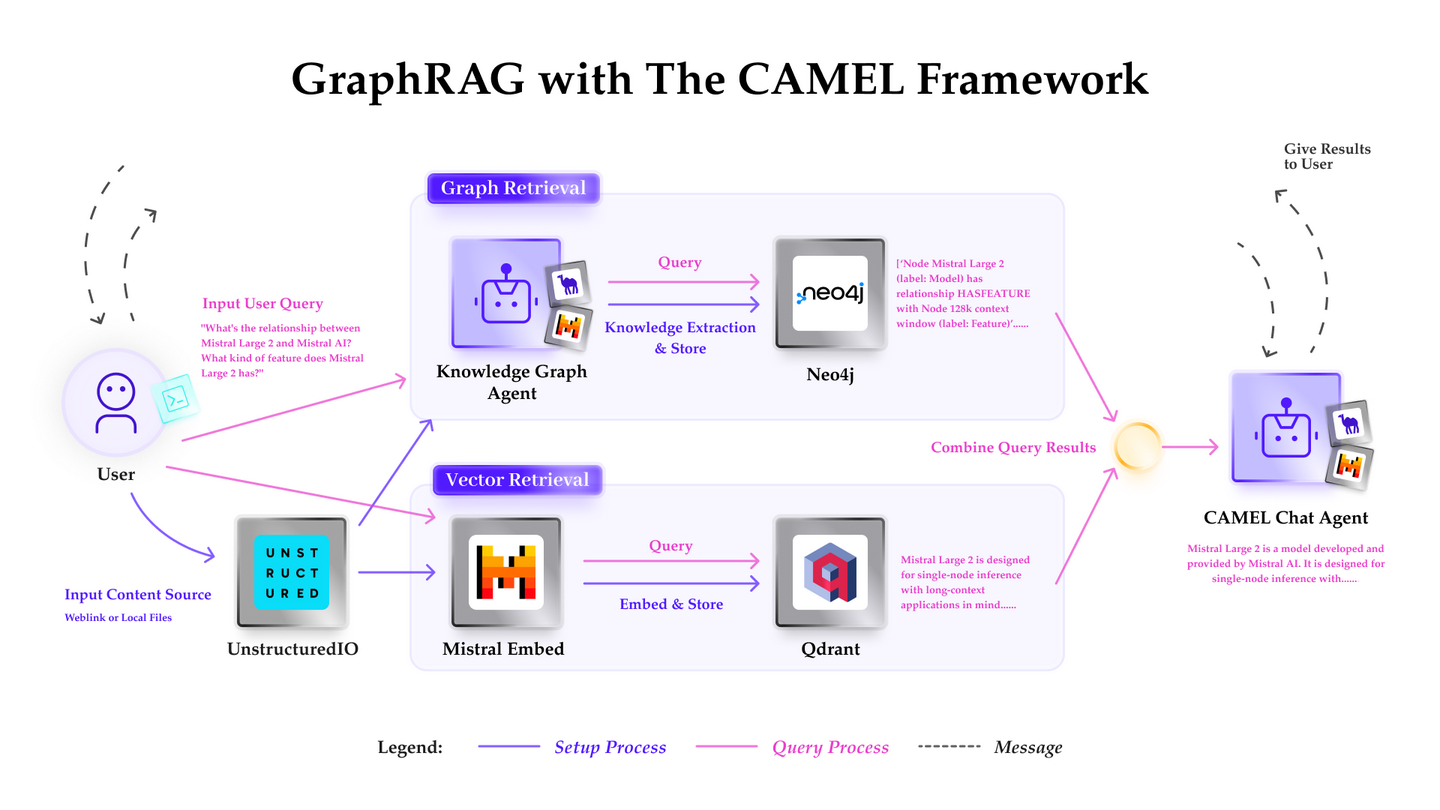
(20) G-RAG【串門神器】
串門神器:不再是單打獨斗地查資料,而是給每個知識點都建立人際關(guān)系網(wǎng)。像個社交達人,不僅知道每個朋友的特長,還清楚誰和誰是酒肉朋友,找答案時直接順藤摸瓜。
- 時間:05.28
- 論文:Don't Forget to Connect! Improving RAG with Graph-based Reranking
- 參考:https://mp.weixin.qq.com/s/e6sRpYFDTQ7w7ituIjyovQ
RAG 在處理文檔與問題上下文的關(guān)系時仍存在挑戰(zhàn),當文檔與問題的關(guān)聯(lián)性不明顯或僅包含部分信息時,模型可能無法有效利用這些文檔。此外,如何合理推斷文檔之間的關(guān)聯(lián)也是一個重要問題。 G-RAG實現(xiàn)了RAG檢索器和閱讀器之間基于圖神經(jīng)網(wǎng)絡(luò)(GNN)的重排器。該方法結(jié)合了文檔之間的連接信息和語義信息(通過抽象語義表示圖),為 RAG 提供了基于上下文的排序器。
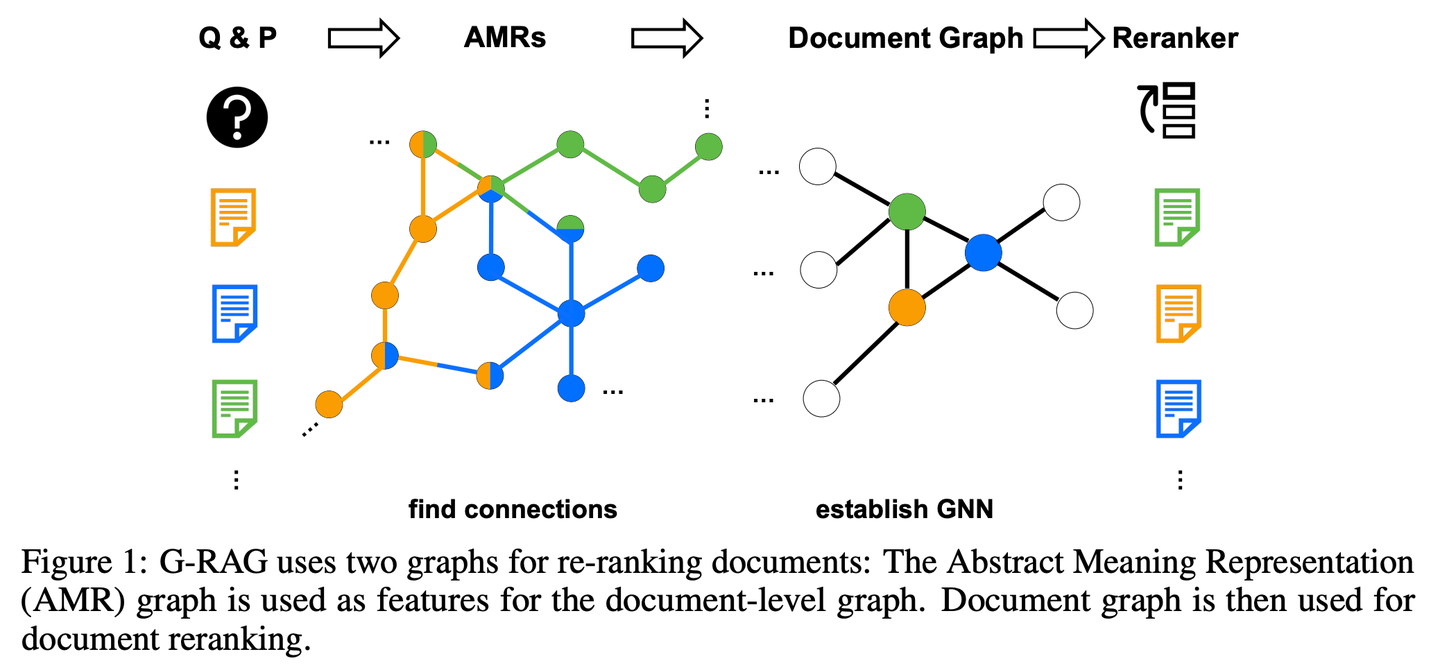
(21) LLM-Graph-Builder【搬運工】
搬運工:給混亂的文字安個明白的家。不是簡單地搬運,而是像個強迫癥患者,把每個知識點都貼上標簽,畫上關(guān)系線,最后在Neo4j的數(shù)據(jù)庫里蓋起一座井井有序的知識大廈。
- 時間:05.29
- 項目:https://github.com/neo4j-labs/llm-graph-builder
- 參考:https://mp.weixin.qq.com/s/9Jy11WH7UgrW37281XopiA
Neo4j開源的基于LLM提取知識圖譜的生成器,可以把非結(jié)構(gòu)化數(shù)據(jù)轉(zhuǎn)換成Neo4j中的知識圖譜。利用大模型從非結(jié)構(gòu)化數(shù)據(jù)中提取節(jié)點、關(guān)系及其屬性。
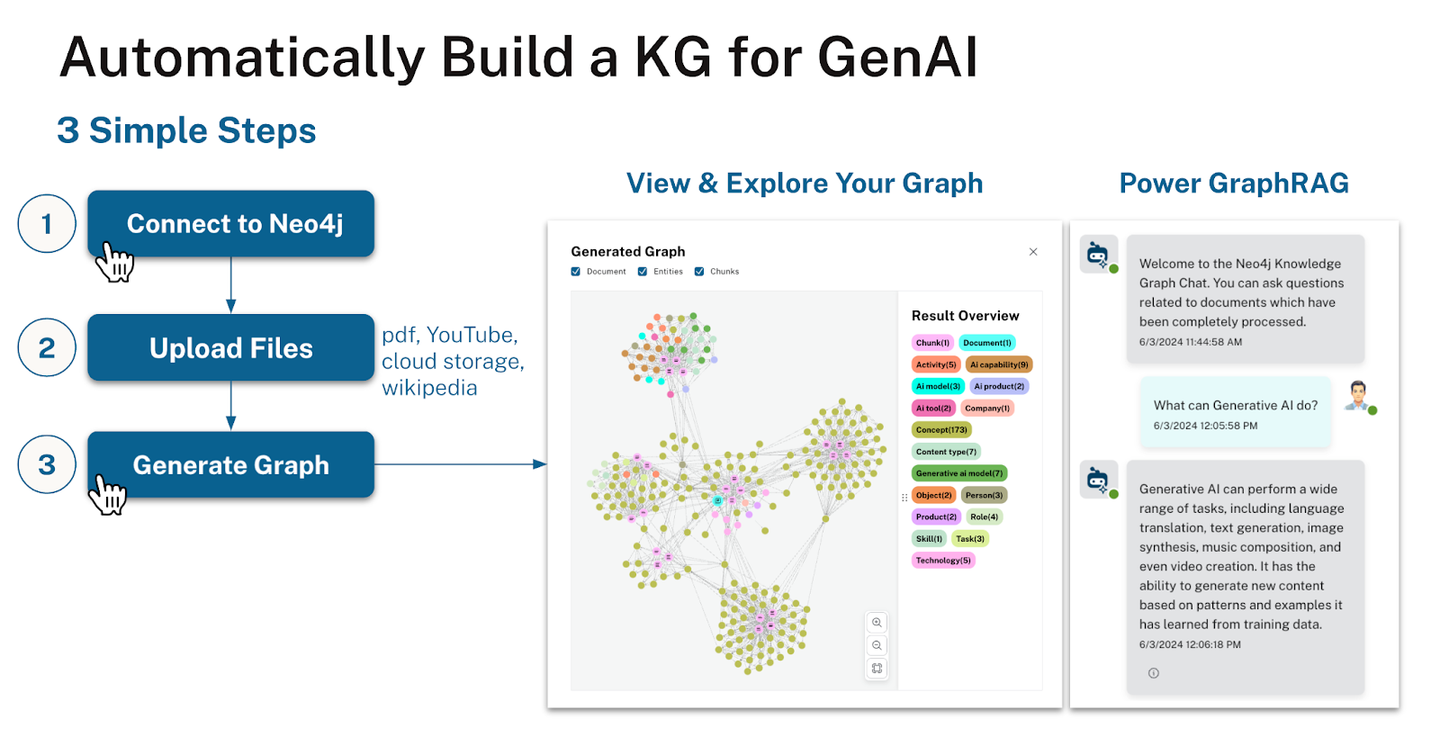
2024.06
(22) MRAG【八爪魚】
八爪魚:不是只長一個腦袋死磕問題,而是像章魚一樣長出多個觸角,每個觸角負責抓取一個角度。簡單說,這就是AI版的"一心多用"。
- 時間:06.07
- 論文:Multi-Head RAG: Solving Multi-Aspect Problems with LLMs
- 項目:https://github.com/spcl/MRAG
- 參考:https://mp.weixin.qq.com/s/WFYnF5UDlmwYsWz_BMtIYA
現(xiàn)有的 RAG 解決方案并未專注于可能需要獲取內(nèi)容差異顯著的多個文檔的查詢。此類查詢經(jīng)常出現(xiàn),但具有挑戰(zhàn)性,因為這些文檔的嵌入在嵌入空間中可能相距較遠,使得難以全部檢索到它們。本文介紹了多頭 RAG(MRAG),這是一種新穎的方案,旨在通過一個簡單而強大的想法來填補這一空白:利用 Transformer 多頭注意力層的激活,而非解碼器層,作為獲取多方面文檔的鍵。其驅(qū)動動機是不同的注意力頭可以學(xué)習(xí)捕獲不同的數(shù)據(jù)方面。利用相應(yīng)的激活會產(chǎn)生代表數(shù)據(jù)項和查詢各個層面的嵌入,從而提高復(fù)雜查詢的檢索準確性。
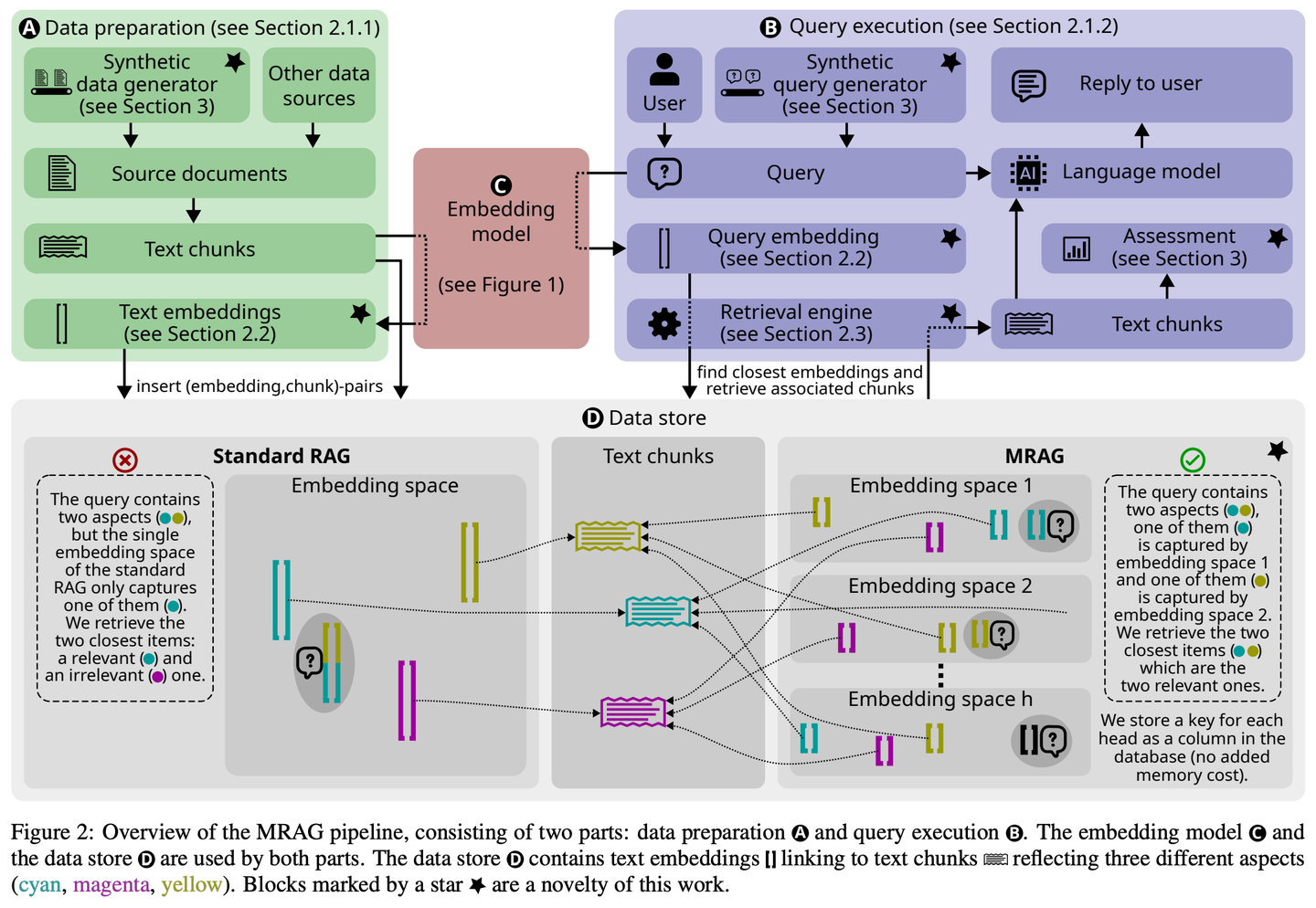
(23) PlanRAG【戰(zhàn)略家】
戰(zhàn)略家:先制定完整作戰(zhàn)計劃,再根據(jù)規(guī)則和數(shù)據(jù)分析局勢,最后做出最佳戰(zhàn)術(shù)決策。
- 時間:06.18
- 論文:PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers
- 項目:https://github.com/myeon9h/PlanRAG
- 參考:https://mp.weixin.qq.com/s/q3x2jOFFibyMXHA57sGx3w
PlanRAG研究如何利用大型語言模型解決復(fù)雜數(shù)據(jù)分析決策問題的方案,通過定義決策問答(Decision QA)任務(wù),即根據(jù)決策問題Q、業(yè)務(wù)規(guī)則R和數(shù)據(jù)庫D,確定最佳決策d。PlanRAG首先生成決策計劃,然后檢索器生成數(shù)據(jù)分析的查詢。
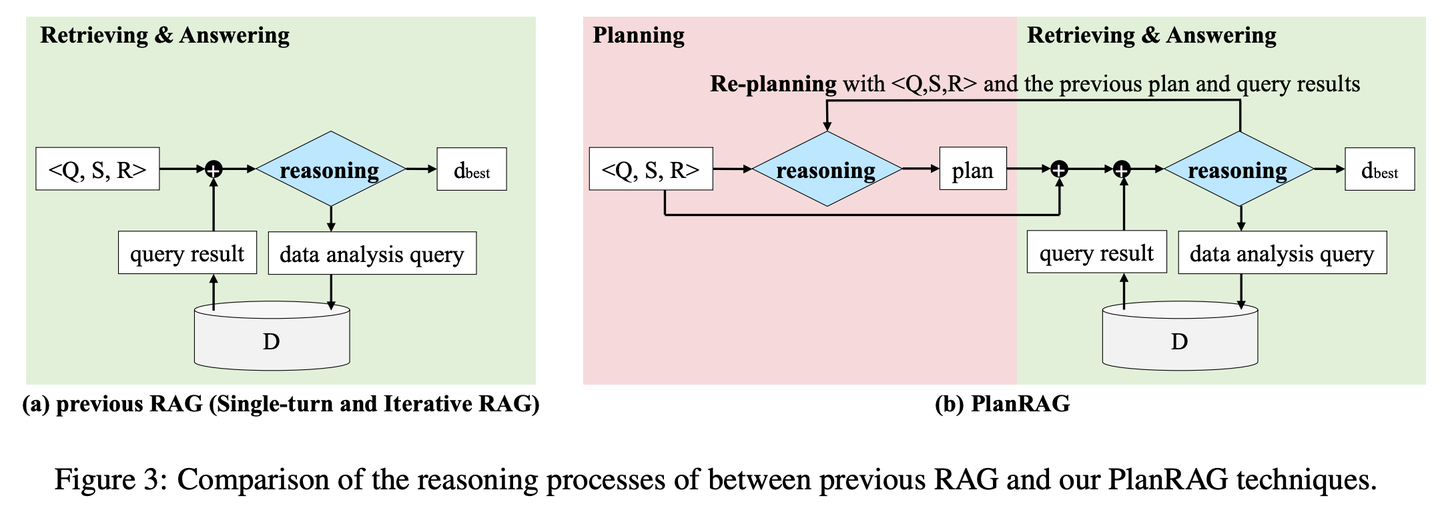
(24) FoRAG【作家】
作家:先列寫作大綱構(gòu)思文章框架,再逐段擴充完善內(nèi)容。同時還配備了一個"編輯",通過仔細的事實核查和修改建議,幫助完善每個細節(jié),確保作品的質(zhì)量。
- 時間:06.19
- 論文:FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
- 參考:https://mp.weixin.qq.com/s/7uqZ5U10Ec2Pa7akCLCJEA
FoRAG提出了一種新穎的大綱增強生成器,在第一階段生成器使用大綱模板,根據(jù)用戶查詢和上下文草擬答案大綱,第二階段基于生成的大綱擴展每個觀點,構(gòu)建最終答案。同時提出一種基于精心設(shè)計的雙精細粒度RLHF框架的事實性優(yōu)化方法,通過在事實性評估和獎勵建模兩個核心步驟中引入細粒度設(shè)計,提供了更密集的獎勵信號。
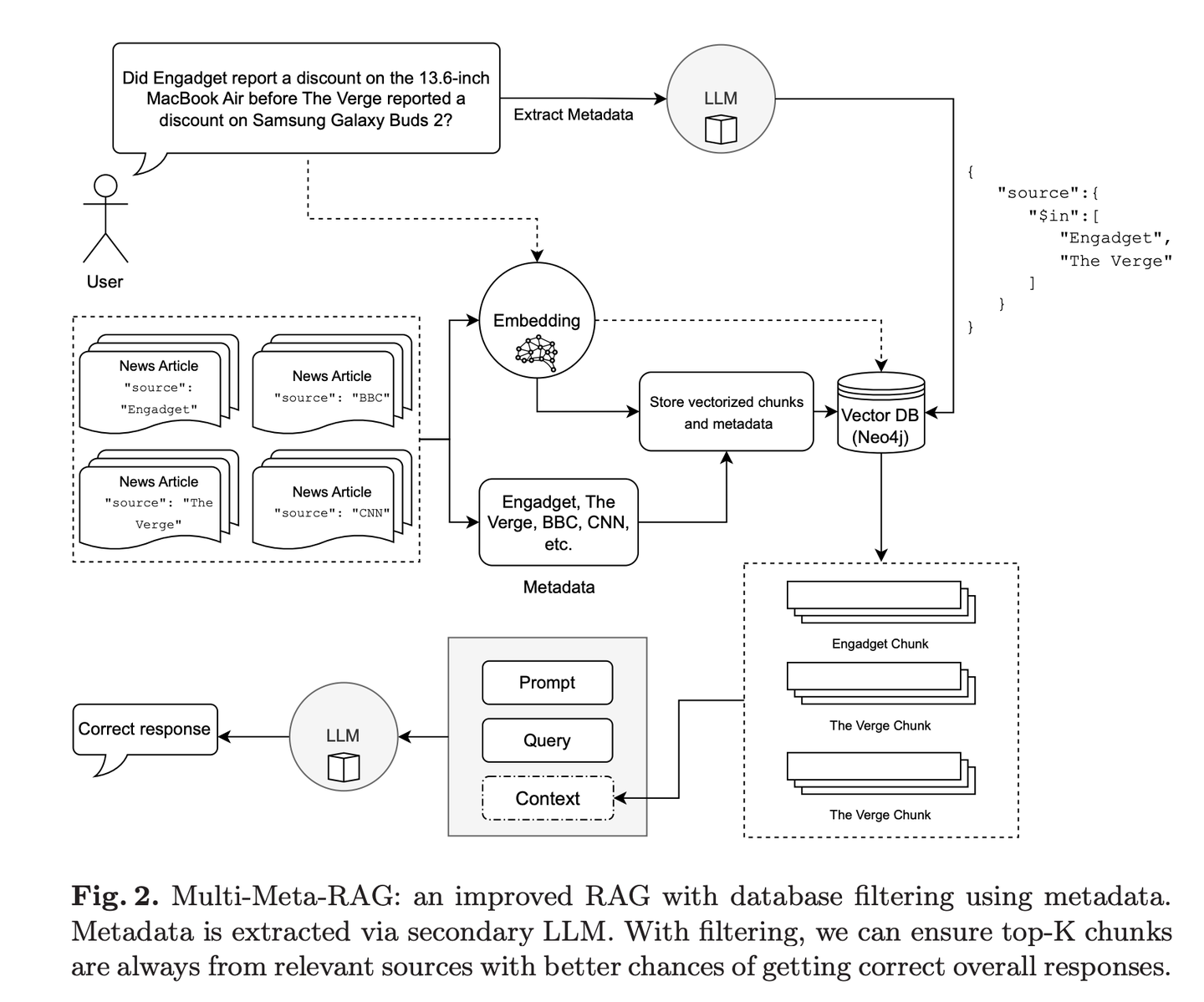
(25) Multi-Meta-RAG【元篩選器】
元篩選器:像個經(jīng)驗豐富的資料管理員,通過多重篩選機制,從海量信息中精準定位最相關(guān)的內(nèi)容。它不只看表面,還會深入分析文檔的"身份標簽"(元數(shù)據(jù)),確保找到的每份資料都真正對題。
- 時間:06.19
- 論文:Multi-Meta-RAG: Improving RAG for Multi-Hop Queries using Database Filtering with LLM-Extracted Metadata
- 項目:https://github.com/mxpoliakov/multi-meta-rag
- 參考:https://mp.weixin.qq.com/s/Jf3qdFR-o_A4FXwmOOZ3pg
Multi-Meta-RAG使用數(shù)據(jù)庫過濾和LLM提取的元數(shù)據(jù)來改進RAG從各種來源中選擇與問題相關(guān)的相關(guān)文檔。
2024.07
(26) RankRAG【全能選手】
全能選手:通過一點特訓(xùn)就能當好"評委"和"選手"雙重角色。像個天賦異稟的運動員,只需要少量指導(dǎo)就能在多個項目上超越專業(yè)選手,還能把看家本領(lǐng)都融會貫通。
- 時間:07.02
- 論文:RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
- 參考:https://mp.weixin.qq.com/s/BZDXCTKSKLOwDv1j8_75_Q
RankRAG的通過指令微調(diào)單一的LLM,使其同時具備上下文排名和答案生成的雙重功能。通過在訓(xùn)練數(shù)據(jù)中加入少量排序數(shù)據(jù),經(jīng)過指令微調(diào)的大語言模型效果出奇地好,甚至超過了現(xiàn)有的專家排序模型,包括在大量排序數(shù)據(jù)上專門微調(diào)的相同大語言模型。這種設(shè)計不僅簡化了傳統(tǒng)RAG系統(tǒng)中多模型的復(fù)雜性,還通過共享模型參數(shù)增強了上下文的相關(guān)性判斷和信息的利用效率。
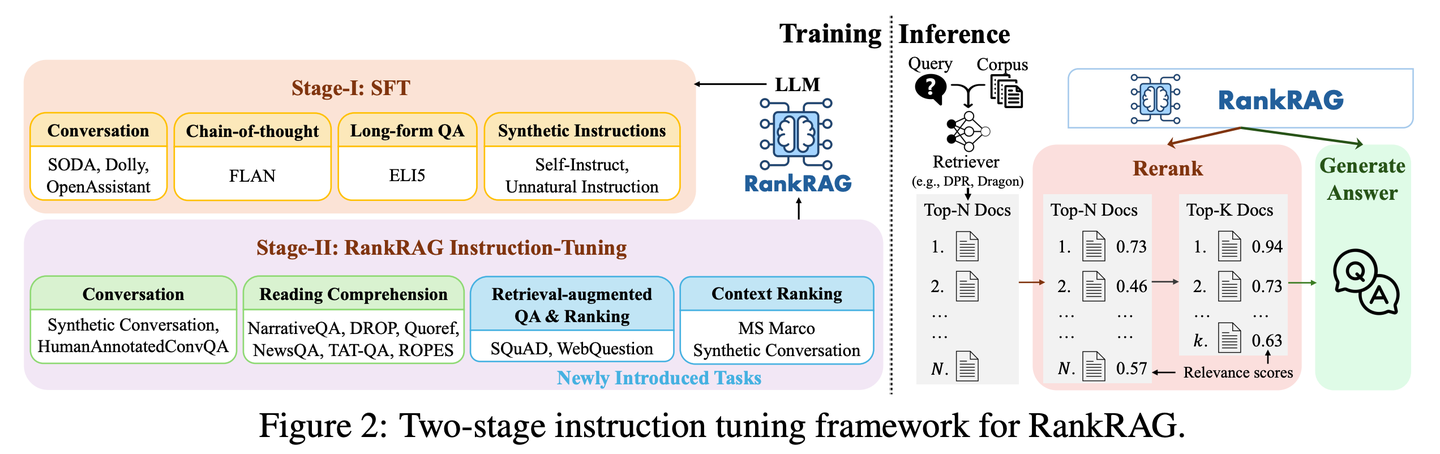
(27) GraphRAG-Local-UI【改裝師】
改裝師:把跑車改裝成適合本地道路的實用車,加裝了友好的儀表盤,讓人人都能輕松駕駛。
- 時間:07.14
- 項目:https://github.com/severian42/GraphRAG-Local-UI
- 參考:https://mp.weixin.qq.com/s/DLvF7YpU3IfWvnu9ZyiBIA
GraphRAG-Local-UI是基于Microsoft的GraphRAG的本地模型適配版本,具有豐富的交互式用戶界面生態(tài)系統(tǒng)。
(28) ThinkRAG【小秘書】
小秘書:把龐大的知識體系濃縮成口袋版,像個隨身攜帶的小秘書,不用大型設(shè)備就能隨時幫你查找解答。
- 時間:07.15
- 項目:https://github.com/wzdavid/ThinkRAG
- 參考:https://mp.weixin.qq.com/s/VmnVwDyi0i6qkBEzLZlERQ
ThinkRAG大模型檢索增強生成系統(tǒng),可以輕松部署在筆記本電腦上,實現(xiàn)本地知識庫智能問答。
(29) Nano-GraphRAG【輕裝上陣】
輕裝上陣:像個輕裝上陣的運動員,把繁復(fù)的裝備都簡化了,但保留了核心能力。
- 時間:07.25
- 項目:https://github.com/gusye1234/nano-graphrag
- 參考:https://mp.weixin.qq.com/s/pnyhz0jA4jgLndMUM9IU1g
Nano-GraphRAG是一個更小、更快、更簡潔的 GraphRAG,同時保留了核心功能。
2024.08
(30) RAGFlow-GraphRAG【導(dǎo)航員】
導(dǎo)航員:在問答的迷宮里開辟捷徑,先畫張地圖把知識點都標好,重復(fù)的路標合并掉,還特地給地圖瘦身,讓問路的人不會繞遠路。
- 時間:08.02
- 項目:https://github.com/infiniflow/ragflow
- 參考:https://mp.weixin.qq.com/s/c5-0dCWI0bIa2zHagM1w0w
RAGFlow借鑒了GraphRAG的實現(xiàn),在文檔預(yù)處理階段,引入知識圖譜構(gòu)建作為可選項,服務(wù)于QFS問答場景,并引入了實體去重、Token優(yōu)化等改進。
(31) Medical-Graph-RAG【數(shù)字醫(yī)生】
數(shù)字醫(yī)生:像個經(jīng)驗豐富的醫(yī)學(xué)顧問,用圖譜把復(fù)雜的醫(yī)療知識整理得清清楚楚,診斷建議不是憑空想象,而是有理有據(jù),讓醫(yī)生和患者都能看明白每個診斷背后的依據(jù)。
- 時間:08.08
- 論文:Medical Graph RAG: Towards Safe Medical Large Language Model via Graph Retrieval-Augmented Generation
- 項目:https://github.com/SuperMedIntel/Medical-Graph-RAG
- 參考:https://mp.weixin.qq.com/s/5mX-hCyFdve98H01x153Eg
MedGraphRAG 是一個框架,旨在解決在醫(yī)學(xué)中應(yīng)用 LLM 的挑戰(zhàn)。它使用基于圖譜的方法來提高診斷準確性、透明度并集成到臨床工作流程中。該系統(tǒng)通過生成由可靠來源支持的響應(yīng)來提高診斷準確性,解決了在大量醫(yī)療數(shù)據(jù)中維護上下文的困難。
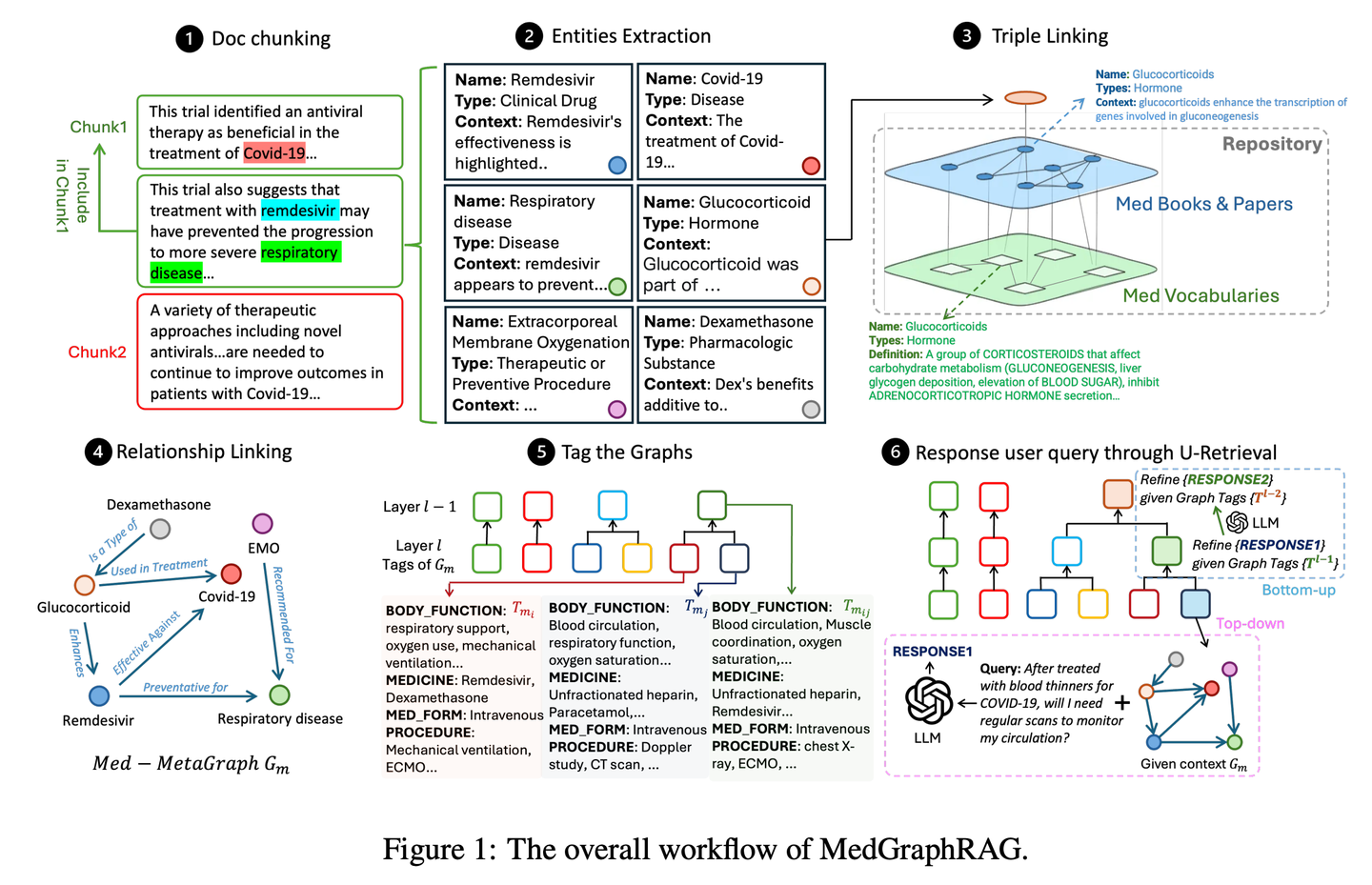
(32) HybridRAG【中醫(yī)合方】
中醫(yī)合方:就像中醫(yī)講究的"合方",單味藥不如幾味藥合在一起效果好。向量數(shù)據(jù)庫負責快速檢索,知識圖譜補充關(guān)系邏輯,兩者優(yōu)勢互補。
- 時間:08.09
- 論文:HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction
- 參考:https://mp.weixin.qq.com/s/59e_bEcxGkM4N0GeCTTF4w
一種基于知識圖譜RAG技術(shù)(GraphRAG)和VectorRAG技術(shù)相結(jié)合的新方法,稱為HybridRAG,以增強從金融文檔中提取信息的問答系統(tǒng),該方法被證明能夠生成準確且與上下文相關(guān)的答案。在檢索和生成階段,就檢索準確性和答案生成而言,從向量數(shù)據(jù)庫和知識圖譜中檢索上下文的HybridRAG優(yōu)于傳統(tǒng)的VectorRAG和GraphRAG。
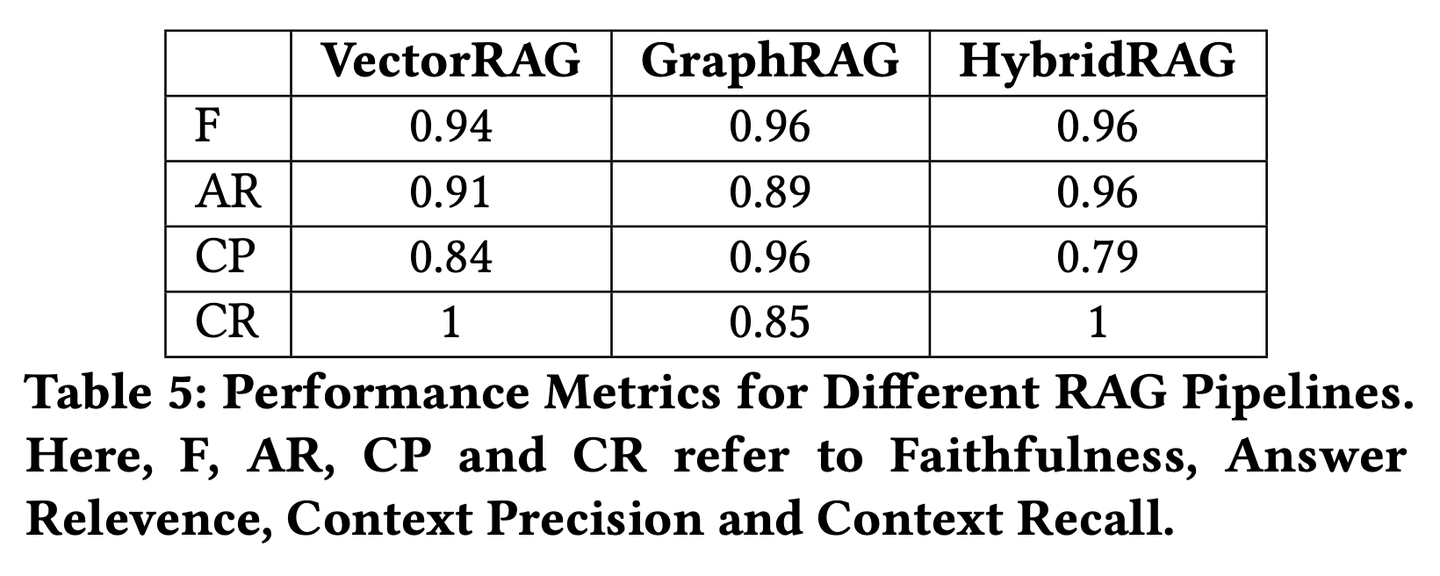
(33) W-RAG【進化搜索】
進化搜索:像個善于自我進化的搜索引擎,通過大模型對文章段落的評分來學(xué)習(xí)什么是好答案,逐步提升自己找到關(guān)鍵信息的能力。
- 時間:08.15
- 論文:W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering
- 項目:https://github.com/jmnian/weak_label_for_rag
- 參考:https://mp.weixin.qq.com/s/JqT1wteHC43h2cPlXmPOFg
開放域問答中的弱監(jiān)督密集檢索技術(shù),利用大型語言模型的排序能力為訓(xùn)練密集檢索器創(chuàng)建弱標注數(shù)據(jù)。通過評估大型語言模型基于問題和每個段落生成正確答案的概率,對通過 BM25 檢索到的前 K 個段落進行重新排序。排名最高的段落隨后被用作密集檢索的正訓(xùn)練示例。
(34) RAGChecker【質(zhì)檢員】
質(zhì)檢員:不只簡單地判斷答案對錯,而是會深入檢查整個回答過程中的每個環(huán)節(jié),從資料查找到最終答案生成,就像一個嚴格的考官,既給出詳細的評分報告,還會指出具體哪里需要改進。
- 時間:08.15
- 論文:RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
- 項目:https://github.com/amazon-science/RAGChecker
- 參考:https://mp.weixin.qq.com/s/x4o7BinnwvTsOa2_hegcrQ
RAGChecker 的診斷工具為 RAG 系統(tǒng)提供細粒度、全面、可靠的診斷報告,并為進一步提升性能,提供可操作的方向。它不僅能評估系統(tǒng)的整體表現(xiàn),還能深入分析檢索和生成兩大核心模塊的性能。
(35) Meta-Knowledge-RAG【學(xué)者】
學(xué)者:像個學(xué)術(shù)界的資深研究員,不僅收集資料,還會主動思考問題,為每份文檔做批注和總結(jié),甚至預(yù)先設(shè)想可能的問題。它會把相關(guān)的知識點串聯(lián)起來,形成知識網(wǎng)絡(luò),讓查詢變得更有深度和廣度,就像有一個學(xué)者在幫你做研究綜述。
- 時間:08.16
- 論文:Meta Knowledge for Retrieval Augmented Large Language Models
- 參考:https://mp.weixin.qq.com/s/twFVKQDTRZTGvDeYA8-c0A
Meta-Knowledge-RAG(MK Summary)引入了一種新穎的以數(shù)據(jù)為中心的 RAG 工作流程,將傳統(tǒng)的 “檢索-讀取” 系統(tǒng)轉(zhuǎn)變?yōu)楦冗M的 “準備-重寫-檢索-讀取” 框架,以實現(xiàn)對知識庫的更高領(lǐng)域?qū)<壹壚斫狻N覀兊姆椒ㄒ蕾囉跒槊總€文檔生成元數(shù)據(jù)和合成的問題與答案以及為基于元數(shù)據(jù)的文檔集群引入元知識摘要的新概念。所提出的創(chuàng)新實現(xiàn)了個性化的用戶查詢增強和跨知識庫的深度信息檢索。
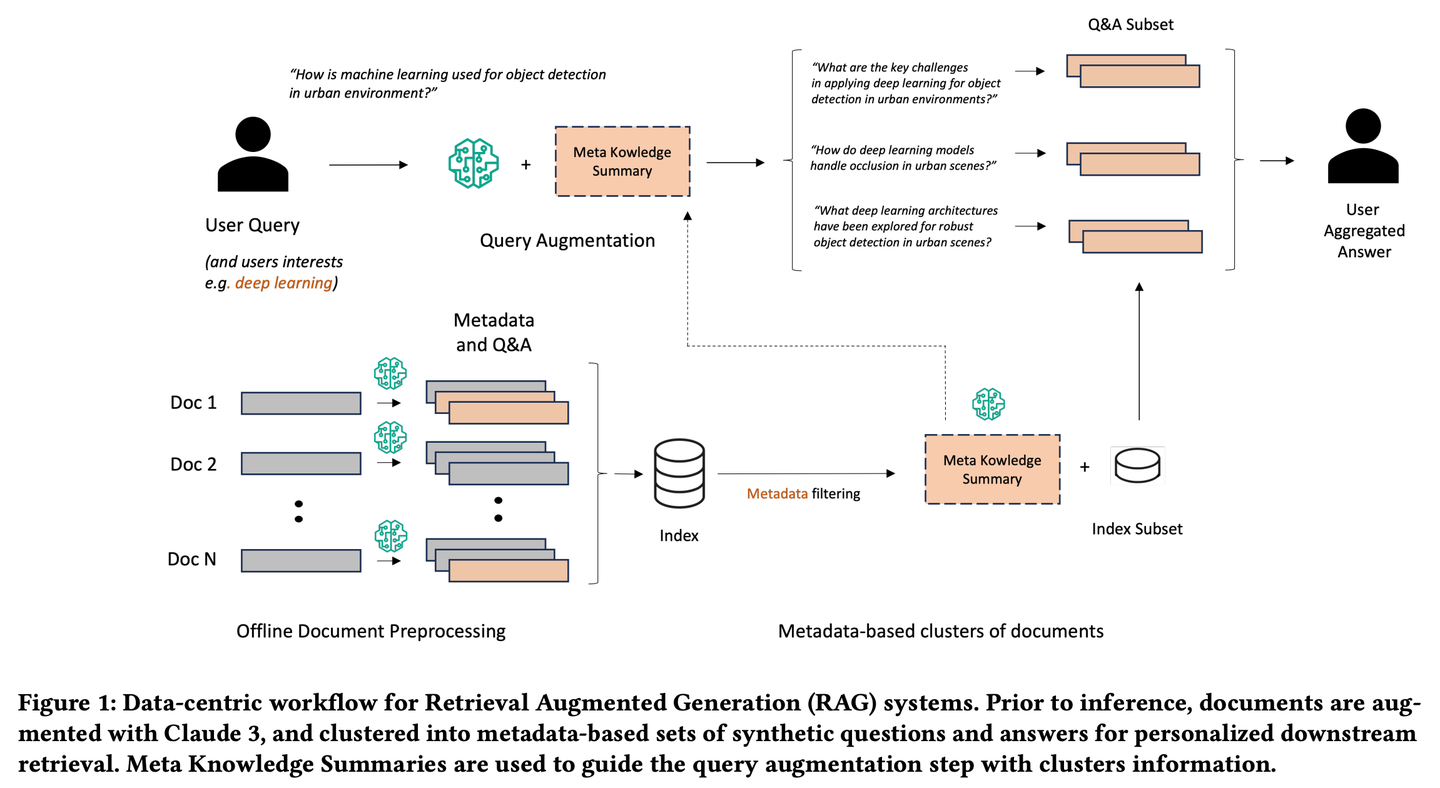
(36) CommunityKG-RAG【社群探索】
社群探索:像個熟悉社區(qū)關(guān)系網(wǎng)絡(luò)的向?qū)В朴诶弥R間的關(guān)聯(lián)和群組特征,在不需要特別學(xué)習(xí)的情況下,就能準確地找到相關(guān)信息,并驗證其可靠性。
- 時間:08.16
- 論文:CommunityKG-RAG: Leveraging Community Structures in Knowledge Graphs for Advanced Retrieval-Augmented Generation in Fact-Checking
- 參考:https://mp.weixin.qq.com/s/ixKV-PKf8ohqZDCTN9jLZQ
CommunityKG-RAG是一種新穎的零樣本框架,它將知識圖譜中的社區(qū)結(jié)構(gòu)與RAG系統(tǒng)相結(jié)合,以增強事實核查過程。CommunityKG-RAG能夠在無需額外訓(xùn)練的情況下適應(yīng)新的領(lǐng)域和查詢,它利用知識圖譜中社區(qū)結(jié)構(gòu)的多跳性質(zhì),顯著提高信息檢索的準確性和相關(guān)性。
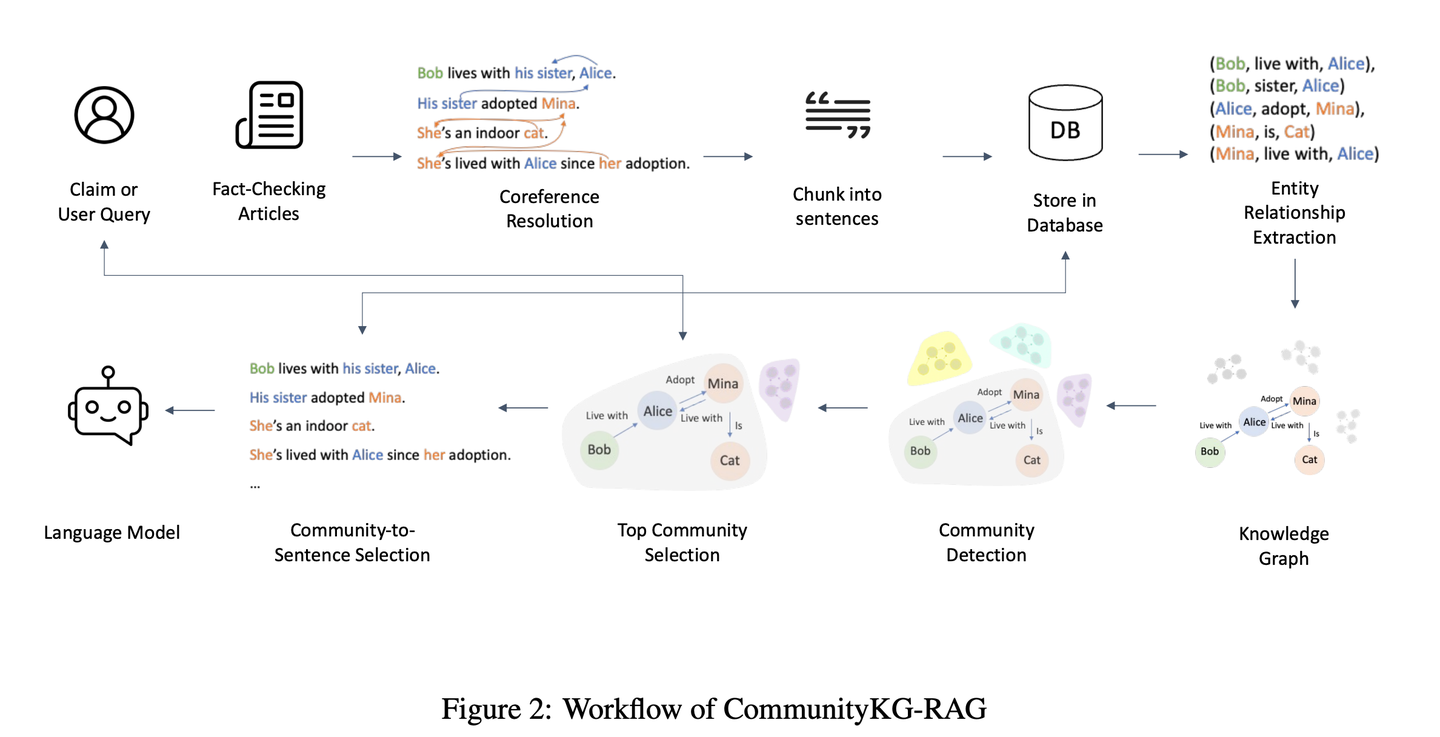
(37) TC-RAG【記憶術(shù)士】
記憶術(shù)士:給LLM裝了個帶自動清理功能的大腦。就像我們解題,會把重要步驟寫在草稿紙上,做完就劃掉。它不是死記硬背,該記的記住,該忘的及時清空,像個會收拾房間的學(xué)霸。
- 時間:08.17
- 論文:TC-RAG: Turing-Complete RAG's Case study on Medical LLM Systems
- 項目:https://github.com/Artessay/TC-RAG
- 參考:https://mp.weixin.qq.com/s/9VhIC5sJP_6nh_Ppfsb6UQ
通過引入圖靈完備的系統(tǒng)來管理狀態(tài)變量,從而實現(xiàn)更高效、準確的知識檢索。通過利用具有自適應(yīng)檢索、推理和規(guī)劃能力的記憶堆棧系統(tǒng),TC-RAG不僅確保了檢索過程的受控停止,還通過Push和Pop操作減輕了錯誤知識的積累。
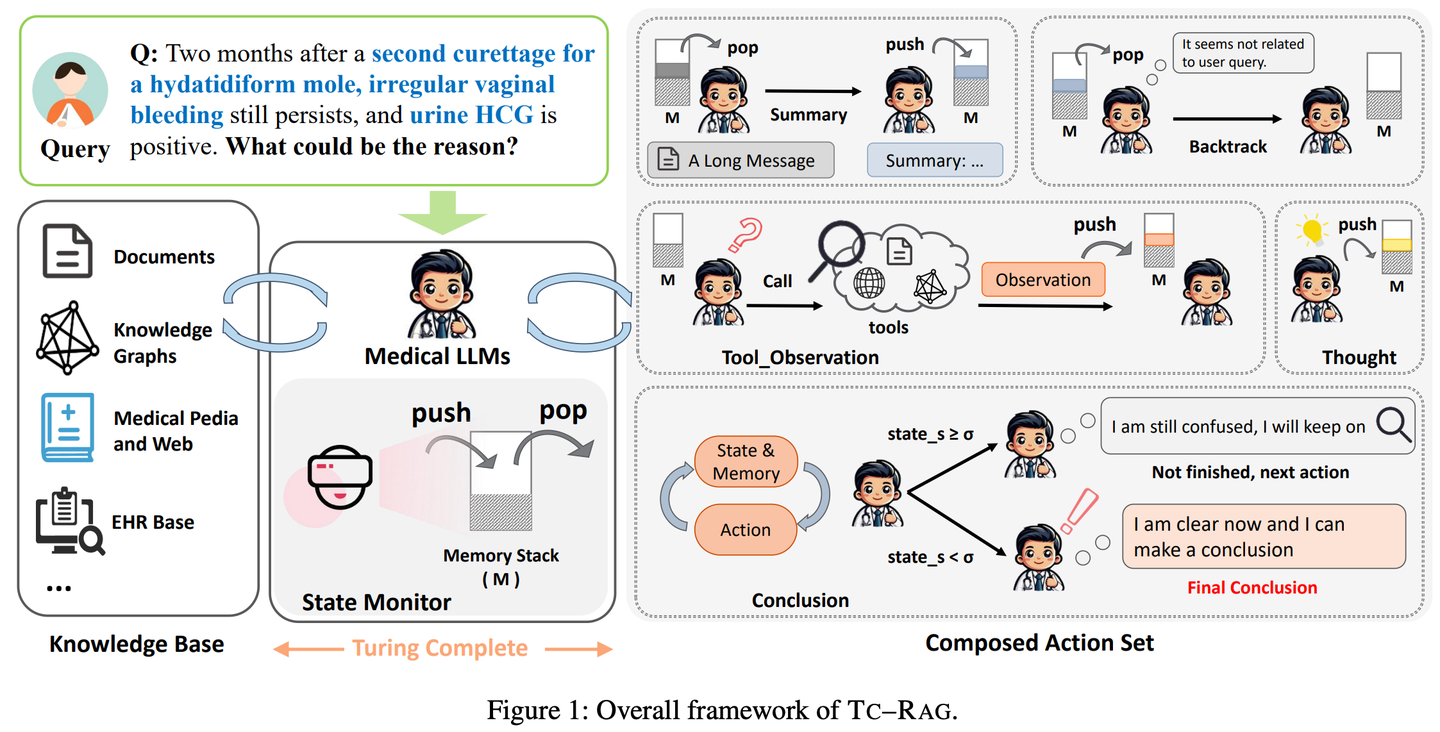
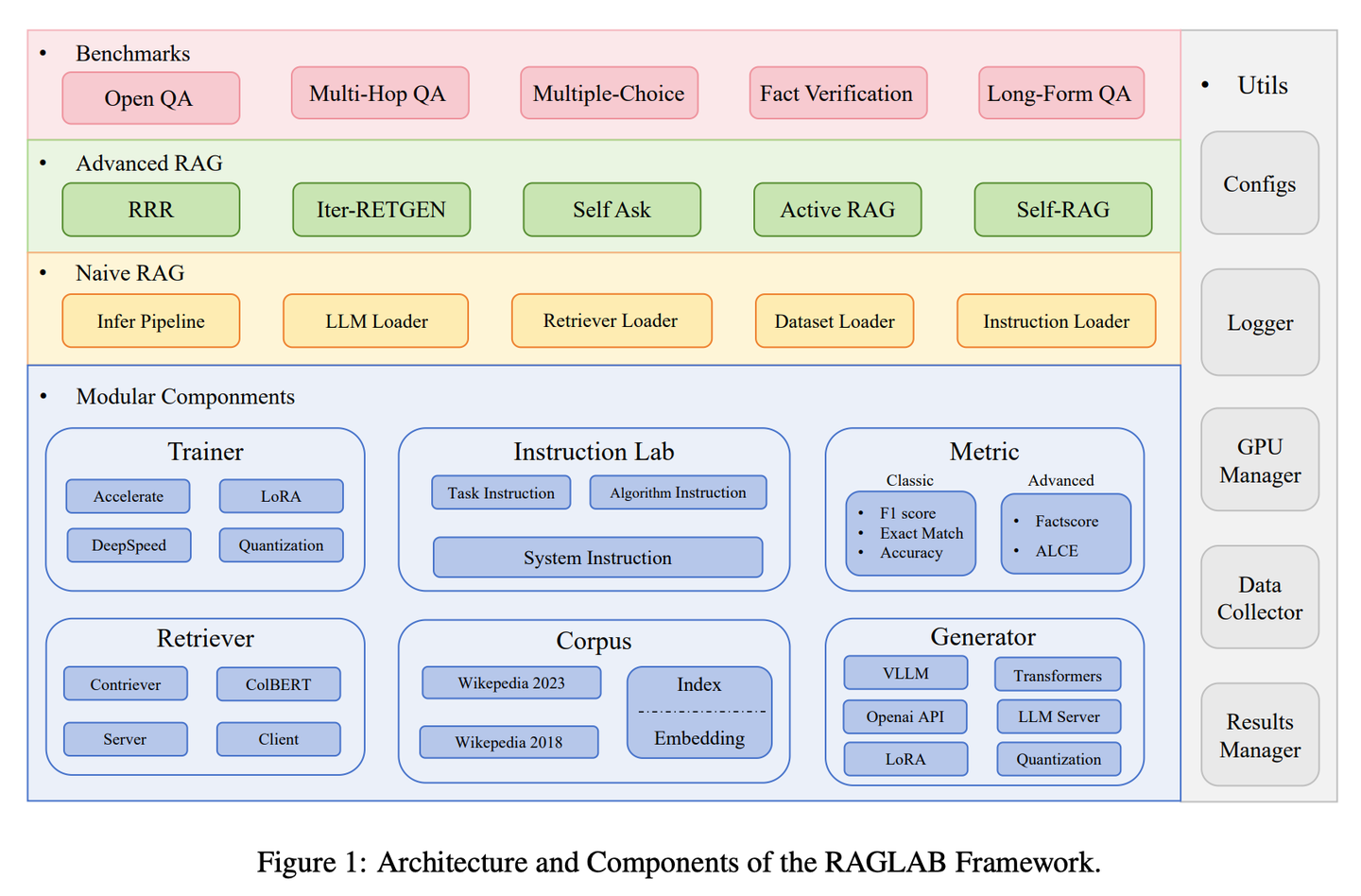
(38) RAGLAB【競技場】
競技場:讓各種算法可以在相同的規(guī)則下進行公平競爭和比較,就像科學(xué)實驗室里的標準化測試流程,確保每個新方法都能得到客觀透明的評估。
- 時間:08.21
- 論文:RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
- 項目:https://github.com/fate-ubw/RAGLab
- 參考:https://mp.weixin.qq.com/s/WSk0zdWZRXMVvm4-_HiFRw
新型RAG算法之間越來越缺乏全面和公平的比較,開源工具的高級抽象導(dǎo)致缺乏透明度,并限制了開發(fā)新算法和評估指標的能力。RAGLAB是一個模塊化、研究導(dǎo)向的開源庫,重現(xiàn)6種算法并構(gòu)建全面研究生態(tài)。借助RAGLAB,我們在10個基準上公平對比6種算法,助力研究人員高效評估和創(chuàng)新算法。
2024.09
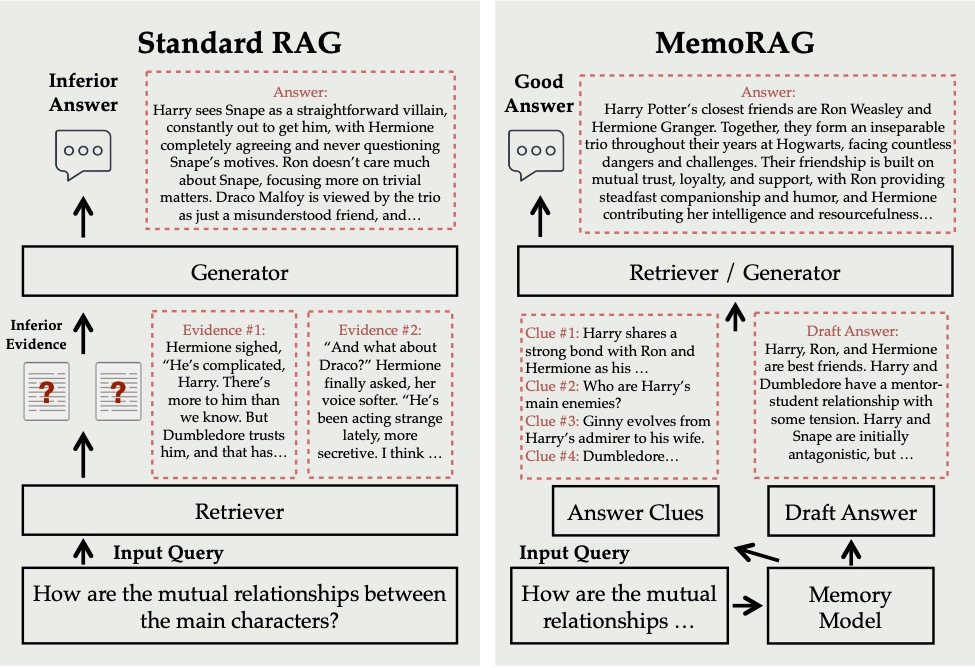
(39) MemoRAG【過目不忘】
過目不忘:它不只是按需查找資料,而是已經(jīng)把整個知識庫都深入理解并記在心里。當你問問題時,它能快速從這個"超級大腦"中調(diào)取相關(guān)記憶,給出既準確又富有見地的答案,就像一個博學(xué)多識的專家。
- 時間:09.01
- 項目:https://github.com/qhjqhj00/MemoRAG
- 參考:https://mp.weixin.qq.com/s/88FTElcYf5PIgHN0J8R7DA
MemoRAG是一個創(chuàng)新的檢索增強生成(RAG)框架,構(gòu)建在一個高效的超長記憶模型之上。與主要處理具有明確信息需求查詢的標準RAG不同,MemoRAG利用其記憶模型實現(xiàn)對整個數(shù)據(jù)庫的全局理解。通過從記憶中召回特定于查詢的線索,MemoRAG增強了證據(jù)檢索,從而產(chǎn)生更準確且具有豐富上下文的響應(yīng)生成。
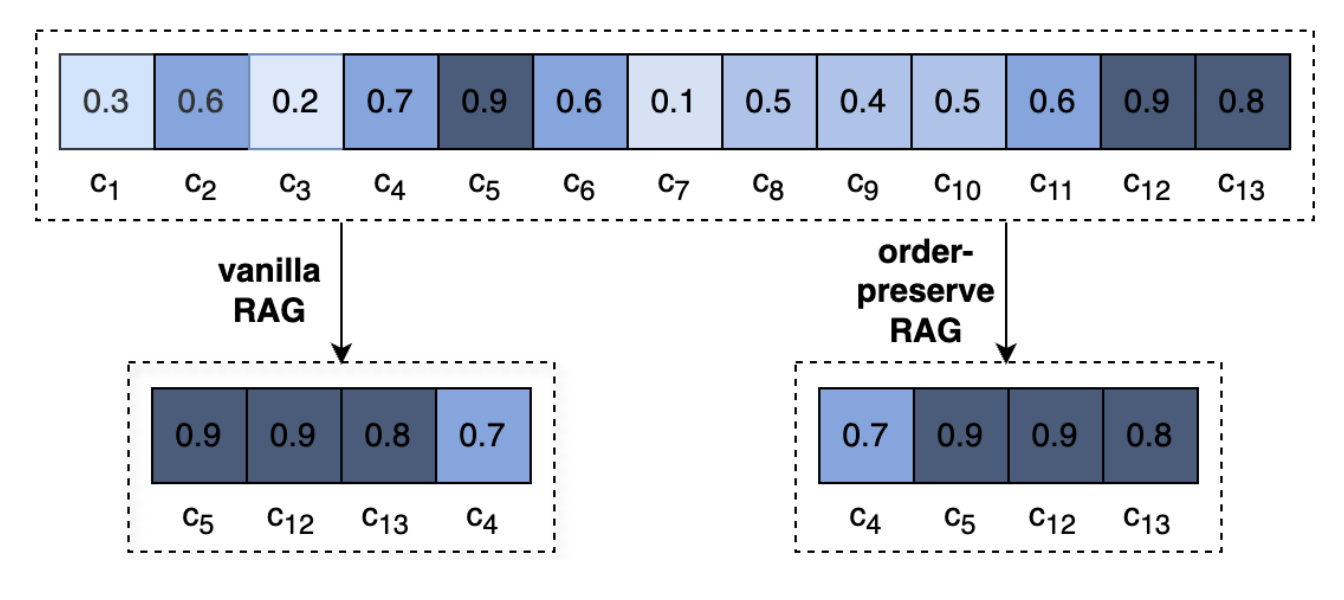
(40) OP-RAG【注意力管理】
注意力管理:就像看一本特別厚的書,你不可能把每個細節(jié)都記住,但懂得在關(guān)鍵章節(jié)做好標記的人才是高手。它不是漫無目的地看,而是像個資深讀書人,邊讀邊在重點處畫下重點,需要的時候直接翻到標記頁。
- 時間:09.03
- 論文:In Defense of RAG in the Era of Long-Context Language Models
- 參考:https://mp.weixin.qq.com/s/WLaaniD7RRgN0h2OCztDcQ
LLM中的極長語境會導(dǎo)致對相關(guān)信息的關(guān)注度降低,并導(dǎo)致答案質(zhì)量的潛在下降。重新審視長上下文答案生成中的RAG。我們提出了一種順序保留檢索增強生成機制OP-RAG,顯著提高了RAG在長上下文問答應(yīng)用中的性能。
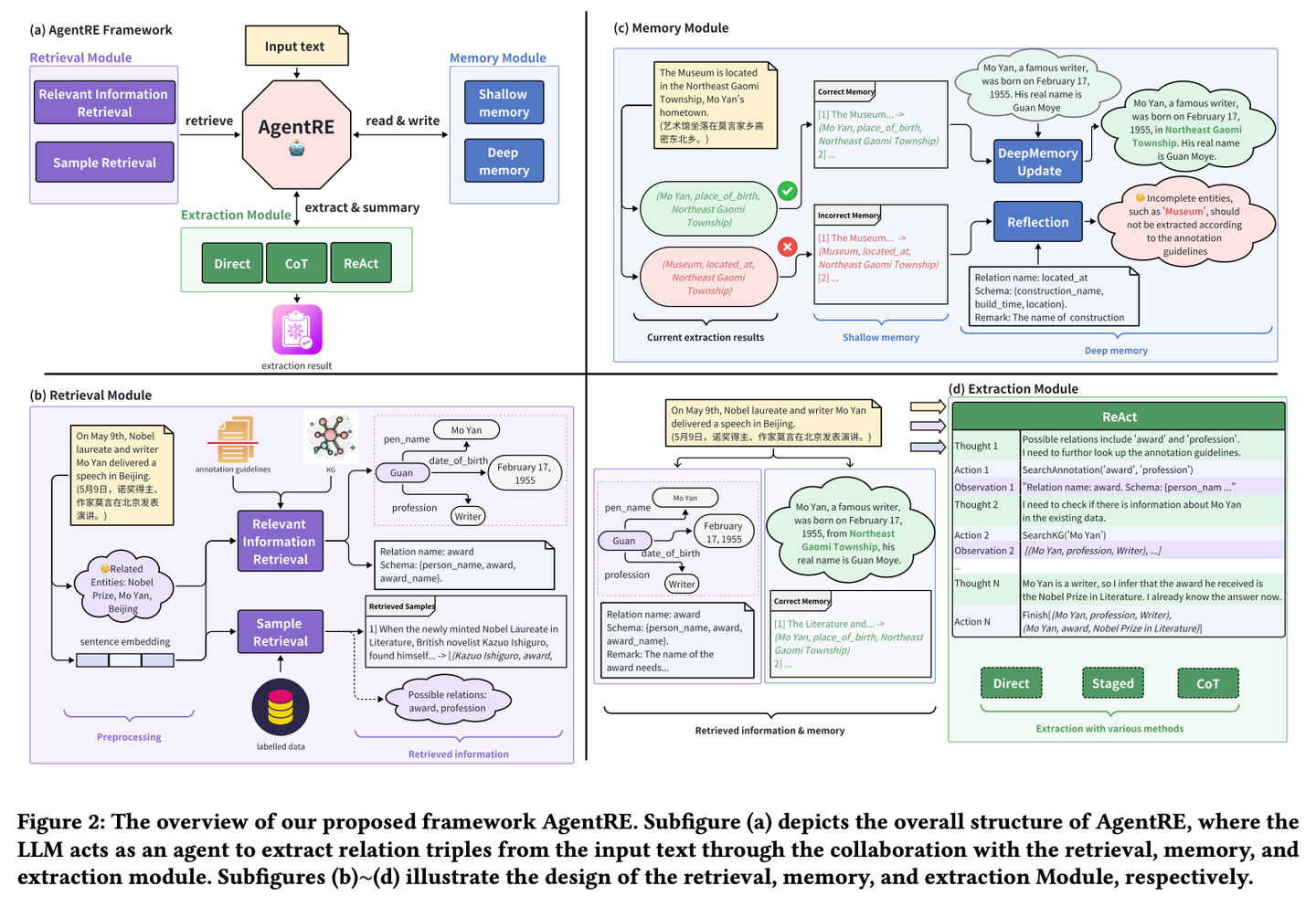
(41) AgentRE【智能抽取】
智能抽取:像個善于觀察人際關(guān)系的社會學(xué)家,不僅能記住關(guān)鍵信息,還會主動查證并深入思考,從而準確理解復(fù)雜的關(guān)系網(wǎng)絡(luò)。即使面對錯綜復(fù)雜的關(guān)系,也能通過多角度分析,理清其中的脈絡(luò),避免望文生義。
- 時間:09.03
- 論文:AgentRE: An Agent-Based Framework for Navigating Complex Information Landscapes in Relation Extraction
- 項目:https://github.com/Lightblues/AgentRE
- 參考:https://mp.weixin.qq.com/s/_P_3H3uyIWjgaCF_FczsDg
AgentRE通過整合大型語言模型的記憶、檢索和反思能力,有效應(yīng)對復(fù)雜場景關(guān)系抽取中關(guān)系類型多樣以及單個句子中實體之間關(guān)系模糊的挑戰(zhàn)。AgentRE 包含三大模塊,助力代理高效獲取并處理信息,顯著提升 RE 性能。
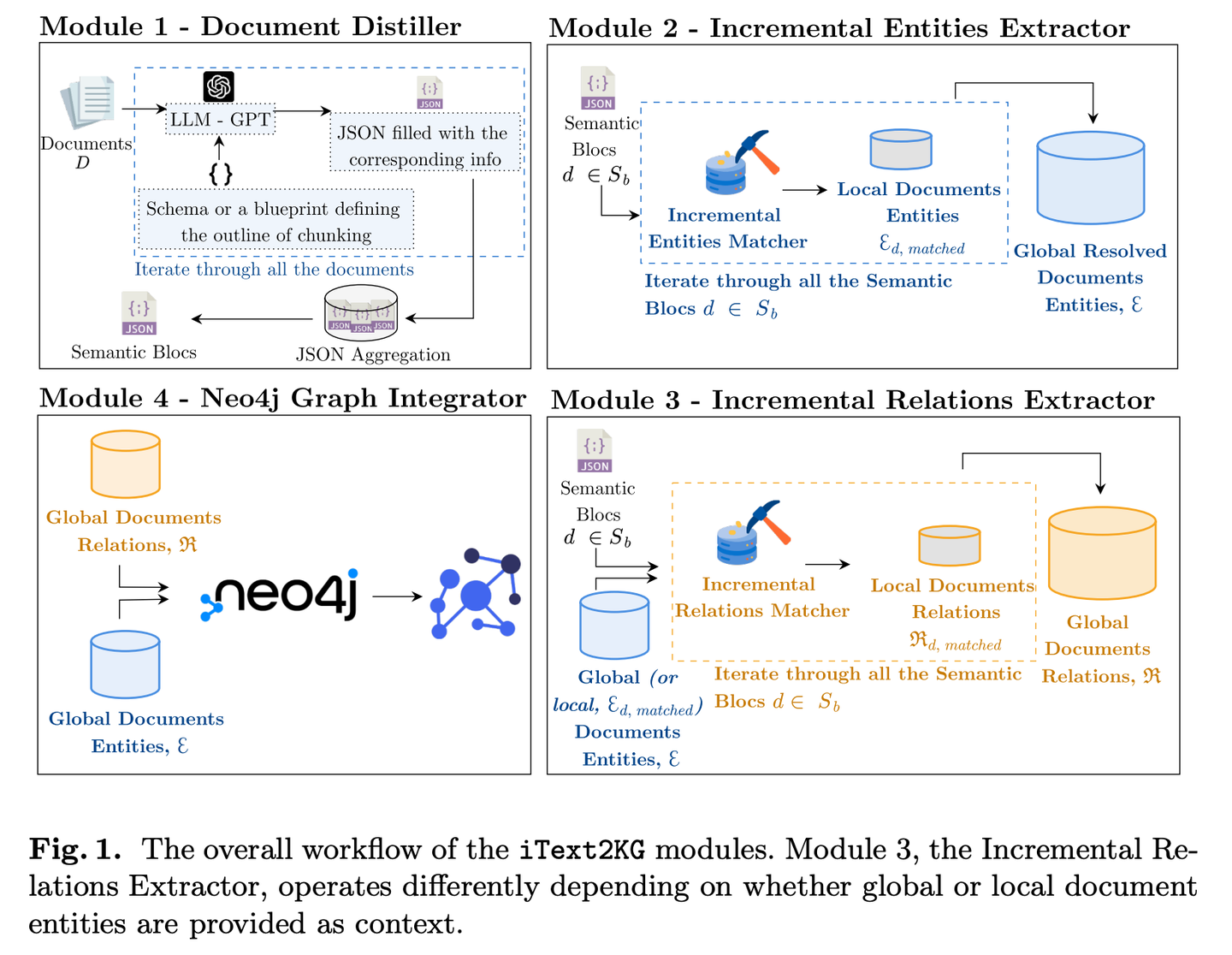
(42) iText2KG【建筑師】
建筑師:像個有條理的工程師,通過分步驟提煉、提取和整合信息,逐步將零散文檔轉(zhuǎn)化為系統(tǒng)的知識網(wǎng)絡(luò),而且不需要事先準備詳細的建筑圖紙,可以根據(jù)需要靈活地擴建和完善。
- 時間:09.05
- 論文:iText2KG: Incremental Knowledge Graphs Construction Using Large Language Models
- 項目:https://github.com/AuvaLab/itext2kg
- 參考:https://mp.weixin.qq.com/s/oiDffH1_0JiGpVGw83-guQ
iText2KG(增量式知識圖譜構(gòu)建)利用大型語言模型 (LLM) 從原始文檔中構(gòu)建知識圖譜,并通過四個模塊(文檔提煉器、增量實體提取器、增量關(guān)系提取器和圖譜集成器)實現(xiàn)增量式知識圖譜構(gòu)建,無需事先定義本體或進行大量的監(jiān)督訓(xùn)練。
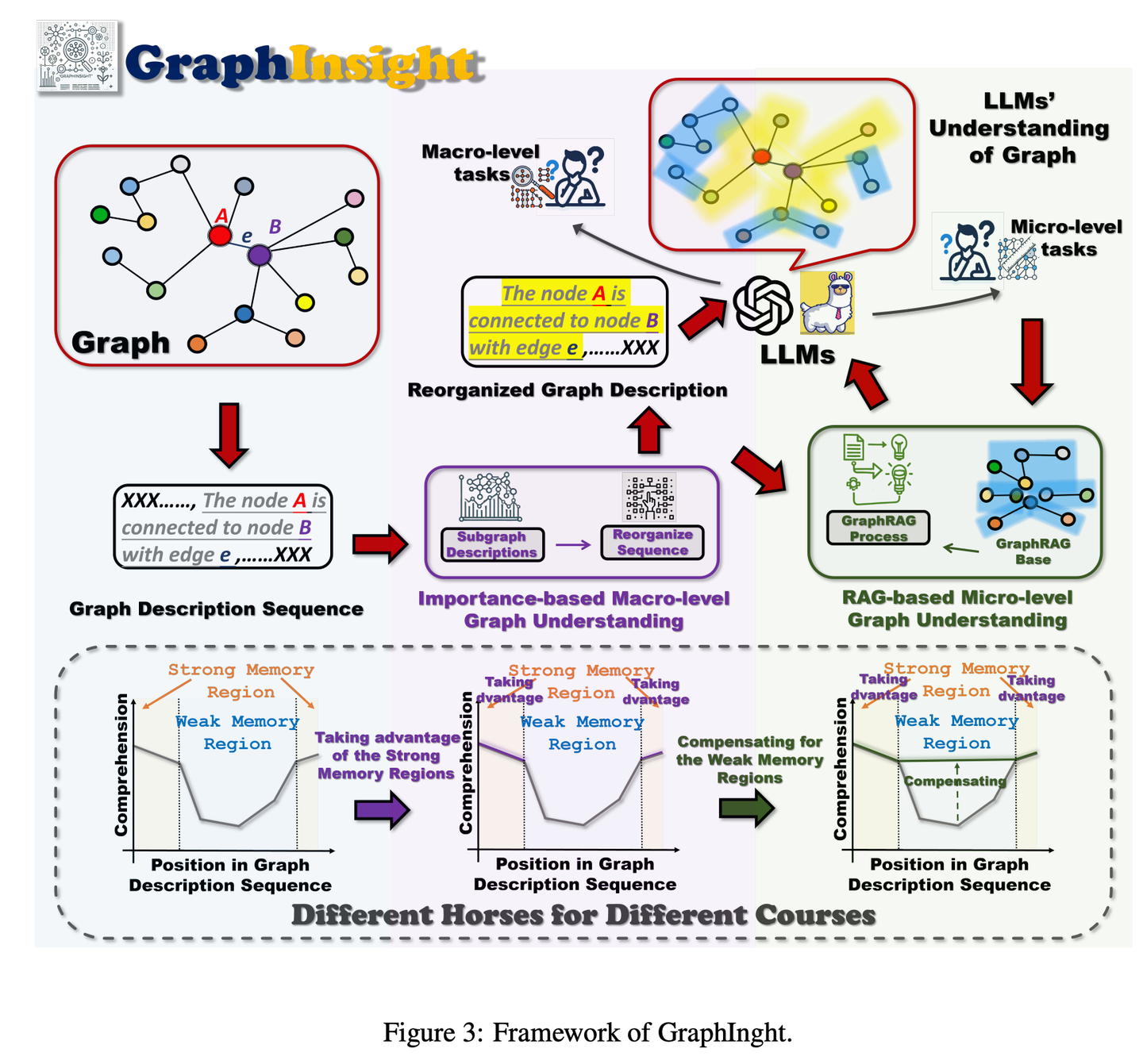
(43) GraphInsight【圖譜解讀】
圖譜解讀:像個擅長信息圖表分析的專家,知道把重要信息放在最顯眼的位置,同時在需要時查閱參考資料來補充細節(jié),并能step by step地推理復(fù)雜圖表,讓AI既能把握全局又不遺漏細節(jié)。
- 時間:09.05
- 論文:GraphInsight: Unlocking Insights in Large Language Models for Graph Structure Understanding
- 參考:https://mp.weixin.qq.com/s/xDKTBtso3ONCGyskvmfAcg
GraphInsight旨在提升LLMs對宏觀和微觀層面圖形信息理解的新框架。GraphInsight基于兩大關(guān)鍵策略:1)將關(guān)鍵圖形信息置于LLMs記憶性能較強的位置;2)借鑒檢索增強生成(RAG)的思想,對記憶性能較弱的區(qū)域引入輕量級外部知識庫。此外,GraphInsight探索將這兩種策略整合到LLM代理過程中,以應(yīng)對需要多步推理的復(fù)合圖任務(wù)。
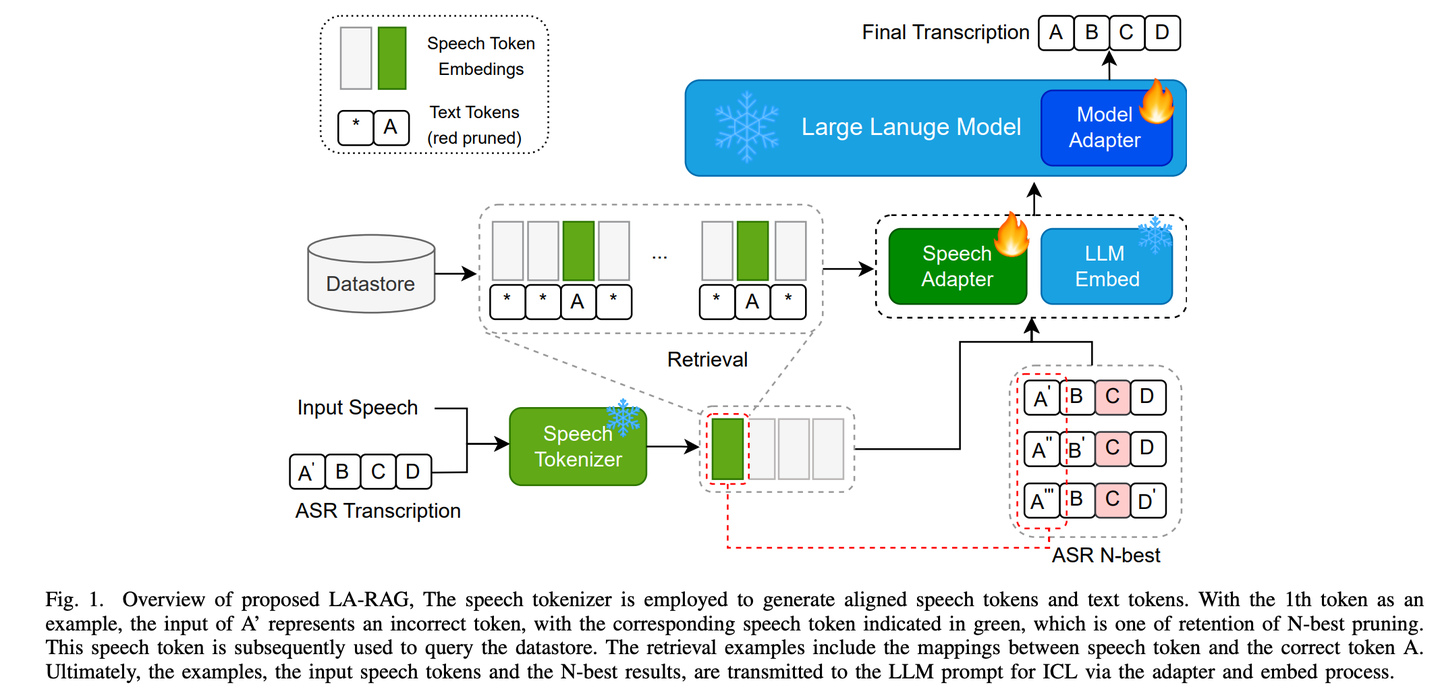
(44) LA-RAG【方言通】
方言通:像個精通各地方言的語言專家,通過細致的語音分析和上下文理解,不僅能準確識別標準普通話,還能聽懂帶有地方特色的口音,讓AI與不同地區(qū)的人都能無障礙交流。
- 時間:09.13
- 論文:LA-RAG:Enhancing LLM-based ASR Accuracy with Retrieval-Augmented Generation
- 參考:https://mp.weixin.qq.com/s/yrmtBqP4bmQ2wYZM7F24Yg
LA-RAG,是一種基于LLM的ASR的新型檢索增強生成(RAG)范例。LA-RAG 利用細粒度標記級語音數(shù)據(jù)存儲和語音到語音檢索機制,通過 LLM 上下文學(xué)習(xí) (ICL) 功能提高 ASR 準確性。
(45) SFR-RAG【精簡檢索】
精簡檢索:像個精練的參考顧問,體積雖小但功能精準,既能理解需求又懂得尋求外部幫助,保證回答既準確又高效。
- 時間:09.16
- 論文:SFR-RAG: Towards Contextually Faithful LLMs
- 參考:https://mp.weixin.qq.com/s/rArOICbHpkmFPR5UoBIi5A
SFR-RAG是一個經(jīng)過指令微調(diào)的小型語言模型,重點是基于上下文的生成和最小化幻覺。通過專注于在保持高性能的同時減少參數(shù)數(shù)量,SFR-RAG模型包含函數(shù)調(diào)用功能,使其能夠與外部工具動態(tài)交互以檢索高質(zhì)量的上下文信息。

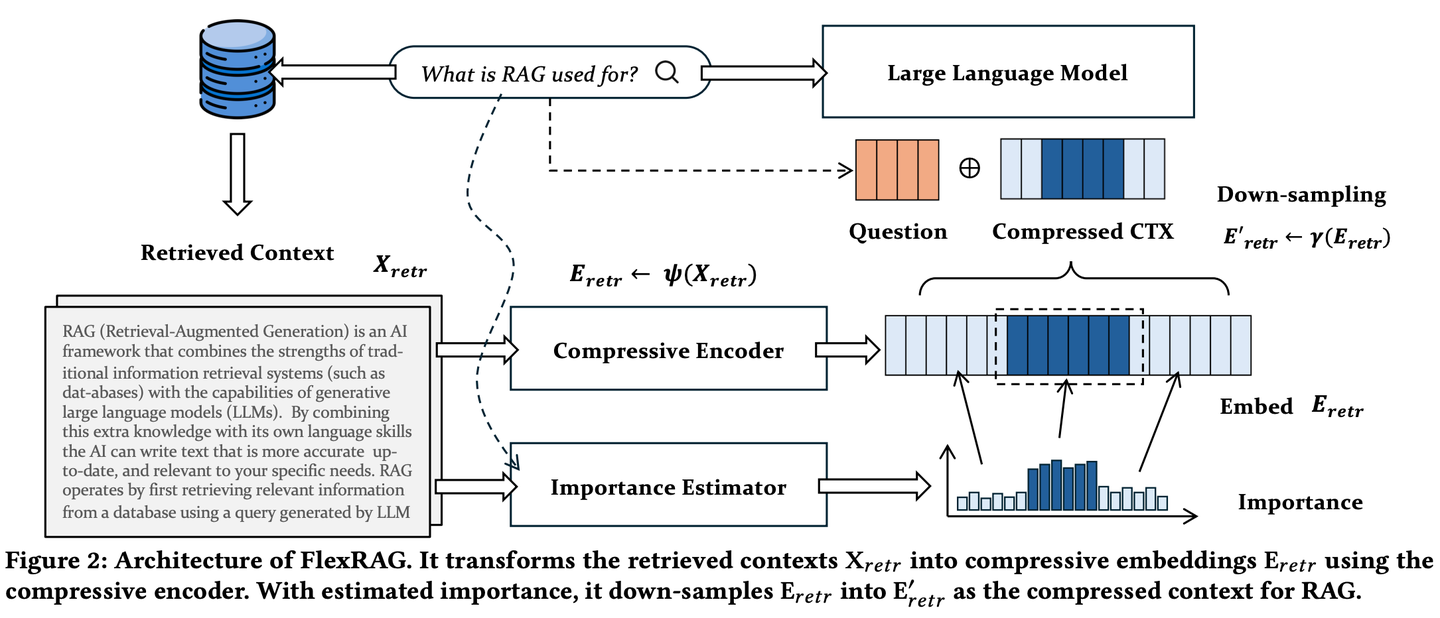
(46) FlexRAG【壓縮專家】
壓縮專家:把長篇大論濃縮成精華摘要,而且壓縮比例可以根據(jù)需要靈活調(diào)整,既不丟失關(guān)鍵信息,又能節(jié)省存儲和處理成本。就像把一本厚書精煉成一份簡明扼要的讀書筆記。
- 時間:09.24
- 論文:Lighter And Better: Towards Flexible Context Adaptation For Retrieval Augmented Generation
- 參考:https://mp.weixin.qq.com/s/heYbLVQHeykD1EbqH8PSZw
FlexRAG檢索到的上下文在被LLMs編碼之前被壓縮為緊湊的嵌入。同時這些壓縮后的嵌入經(jīng)過優(yōu)化以提升下游RAG的性能。FlexRAG的一個關(guān)鍵特性是其靈活性,它能夠有效支持不同的壓縮比,并選擇性地保留重要上下文。得益于這些技術(shù)設(shè)計,F(xiàn)lexRAG在顯著降低運行成本的同時實現(xiàn)了卓越的生成質(zhì)量。在各種問答數(shù)據(jù)集上進行的全面實驗驗證了我們的方法是RAG系統(tǒng)的一種具有成本效益且靈活的解決方案。
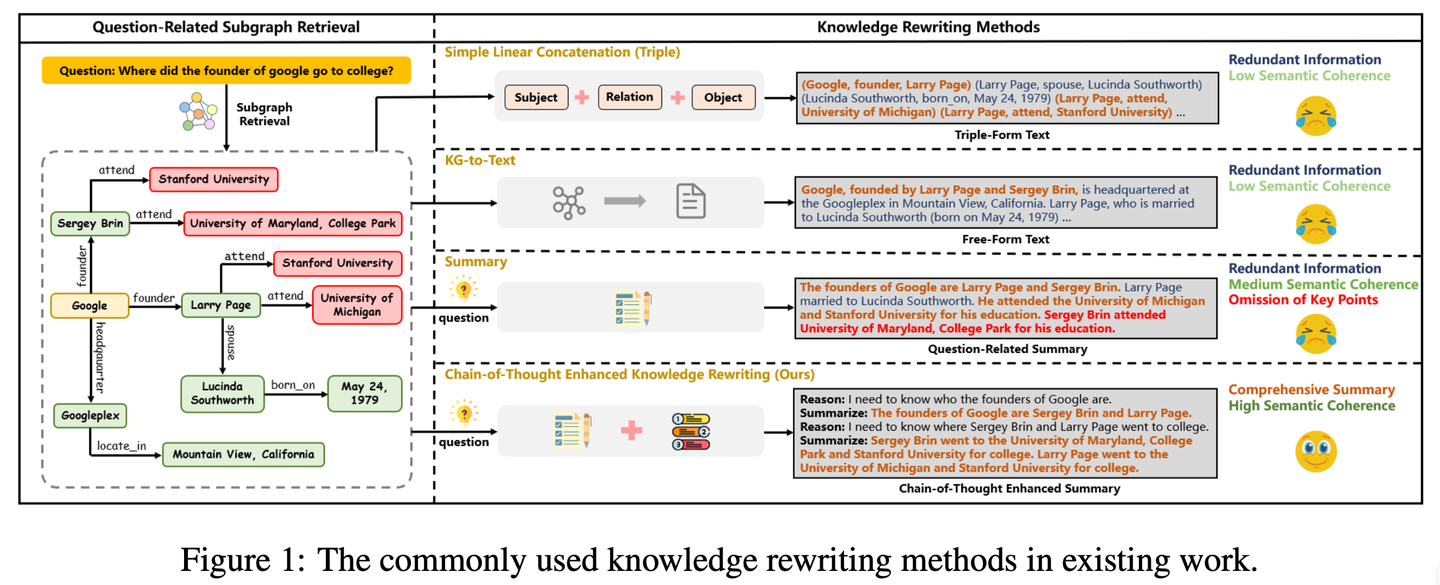
(47) CoTKR【圖譜翻譯】
圖譜翻譯:像個耐心的老師,先理解知識的來龍去脈,再一步步講解,不是簡單復(fù)述而是深入淺出地轉(zhuǎn)述。同時通過不斷收集"學(xué)生"的反饋來改進自己的講解方式,讓知識傳遞更加清晰有效。
- 時間:09.29
- 論文:CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering
- 項目:https://github.com/wuyike2000/CoTKR
- 參考:https://mp.weixin.qq.com/s/lCHxLxRP96Y3mofDVjKY9w
CoTKR(Chain-of-Thought Enhanced Knowledge Rewriting)方法交替生成推理路徑和相應(yīng)知識,從而克服了單步知識改寫的限制。此外,為了彌合知識改寫器和問答模型之間的偏好差異,我們提出了一種訓(xùn)練策略,即從問答反饋中對齊偏好通過利用QA模型的反饋進一步優(yōu)化知識改寫器。
2024.10
(48) Open-RAG【智囊團】
智囊團:把龐大的語言模型分解成專家小組,讓它們既能獨立思考又能協(xié)同工作,還特別會分辨真假信息,關(guān)鍵時刻知道該不該查資料,像個經(jīng)驗豐富的智囊團。
- 時間:10.02
- 論文:Open-RAG: Enhanced Retrieval-Augmented Reasoning with Open-Source Large Language Models
- 項目:https://github.com/ShayekhBinIslam/openrag
- 參考:https://mp.weixin.qq.com/s/H0_THczQ3UWCkSnnk-vveQ
Open-RAG通過開源大語言模型提高RAG中的推理能力,將任意密集的大語言模型轉(zhuǎn)換為參數(shù)高效的稀疏專家混合(MoE)模型,該模型能夠處理復(fù)雜的推理任務(wù),包括單跳和多跳查詢。OPEN-RAG獨特地訓(xùn)練模型以應(yīng)對那些看似相關(guān)但具有誤導(dǎo)性的挑戰(zhàn)性干擾項。
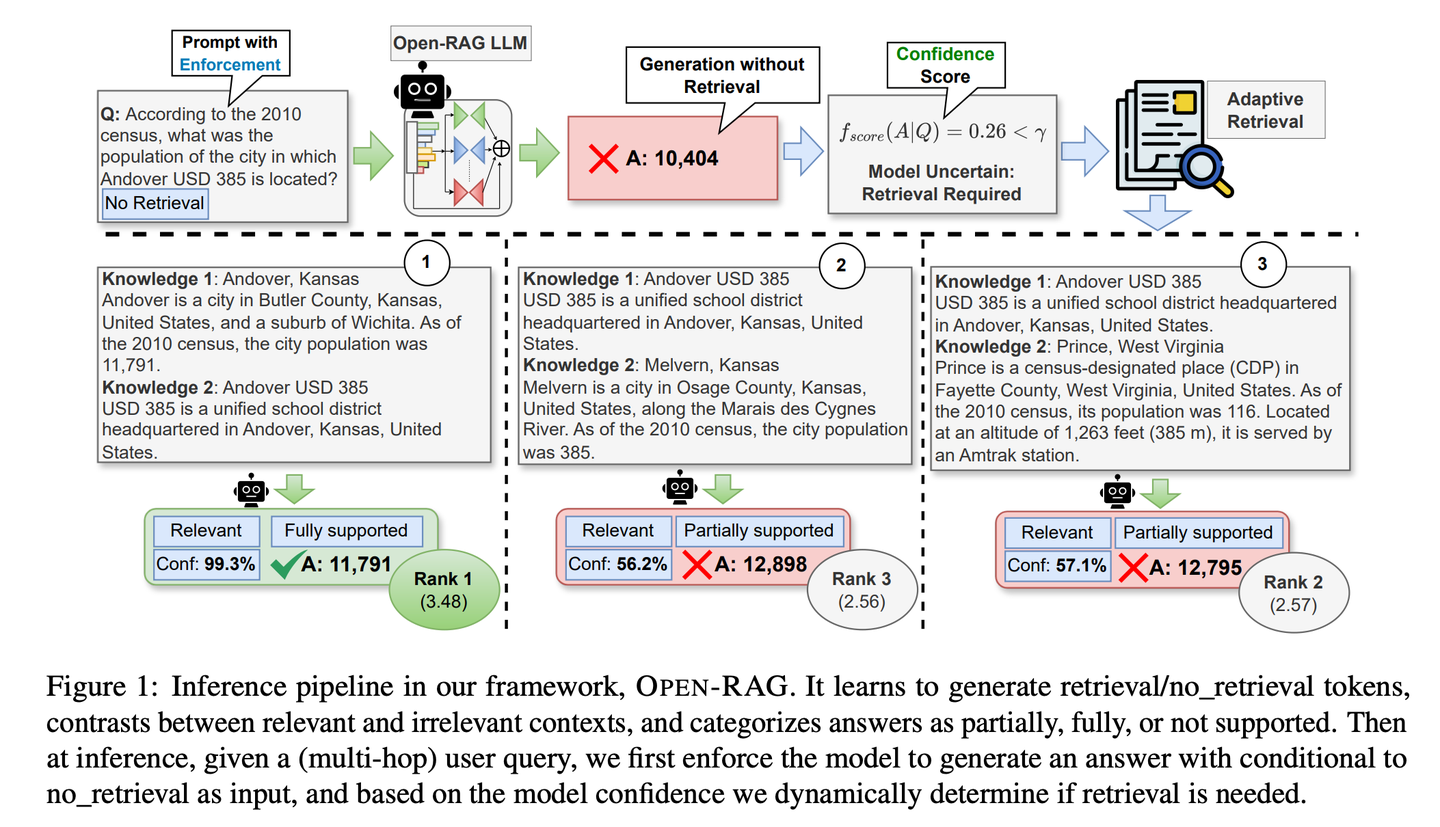
(49) TableRAG【Excel專家】
Excel專家:不只簡單地查看表格數(shù)據(jù),而是懂得從表頭和單元格兩個維度去理解和檢索數(shù)據(jù),就像熟練使用數(shù)據(jù)透視表一樣,能快速定位和提取所需的關(guān)鍵信息。
- 時間:10.07
- 論文:TableRAG: Million-Token Table Understanding with Language Models
- 參考:https://mp.weixin.qq.com/s/n0iu6qOufc1izlzuRjQO6g
TableRAG專為表格理解設(shè)計了檢索增強生成框架,通過查詢擴展結(jié)合Schema和單元格檢索,能夠在提供信息給語言模型之前精準定位關(guān)鍵數(shù)據(jù),從而實現(xiàn)更高效的數(shù)據(jù)編碼和精確檢索,大幅縮短提示長度并減少信息丟失。
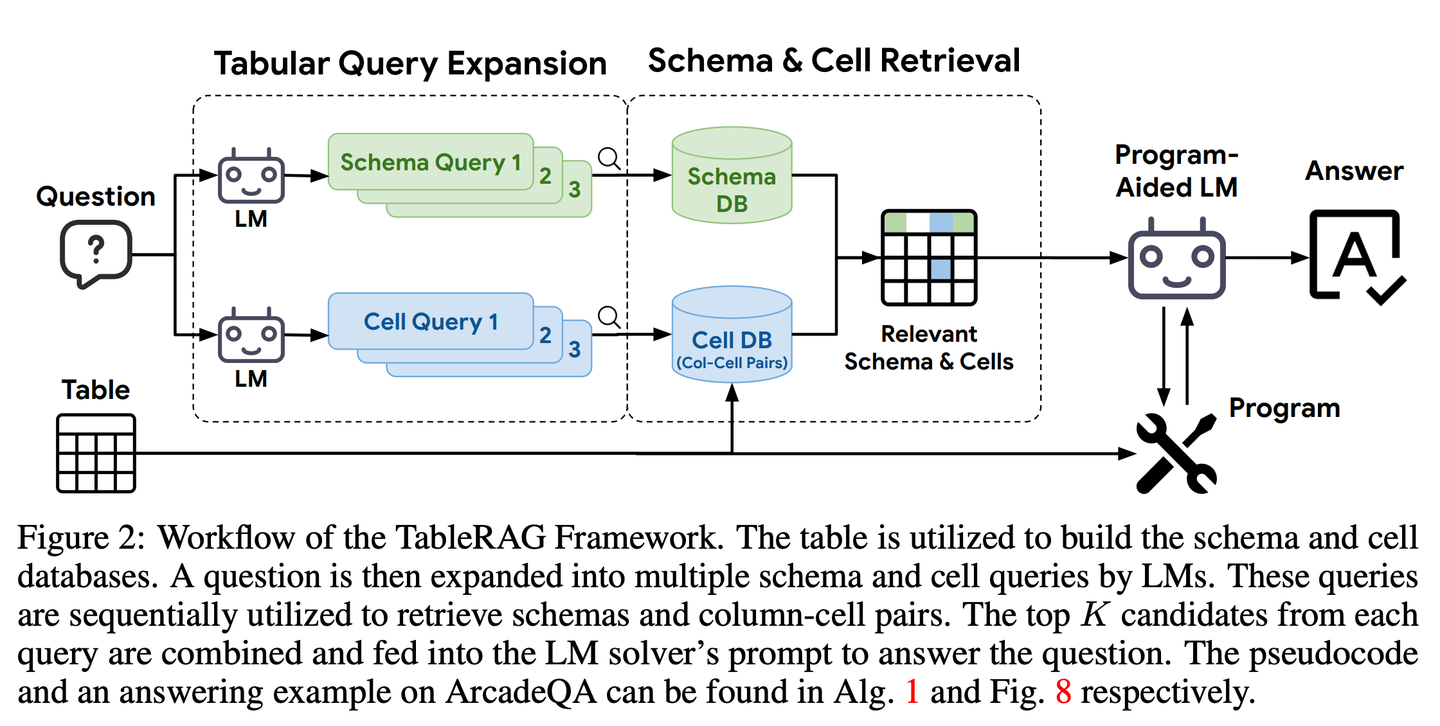
(50) LightRAG【蜘蛛俠】
蜘蛛俠:在知識的網(wǎng)中靈活穿梭,既能抓住知識點之間的絲,又能借網(wǎng)順藤摸瓜。像個長了千里眼的圖書管理員,不僅知道每本書在哪,還知道哪些書該一起看。
- 時間:10.08
- 論文:LightRAG: Simple and Fast Retrieval-Augmented Generation
- 項目:https://github.com/HKUDS/LightRAG
- 參考:https://mp.weixin.qq.com/s/1QKdgZMN55zD6X6xWSiTJw
該框架將圖結(jié)構(gòu)融入文本索引和檢索過程中。這一創(chuàng)新框架采用了一個雙層檢索系統(tǒng),從低級和高級知識發(fā)現(xiàn)中增強全面的信息檢索。此外,將圖結(jié)構(gòu)與向量表示相結(jié)合,便于高效檢索相關(guān)實體及其關(guān)系,顯著提高了響應(yīng)時間,同時保持了上下文相關(guān)性。這一能力通過增量更新算法得到了進一步增強,該算法確保了新數(shù)據(jù)的及時整合,使系統(tǒng)能夠在快速變化的數(shù)據(jù)環(huán)境中保持有效性和響應(yīng)性。
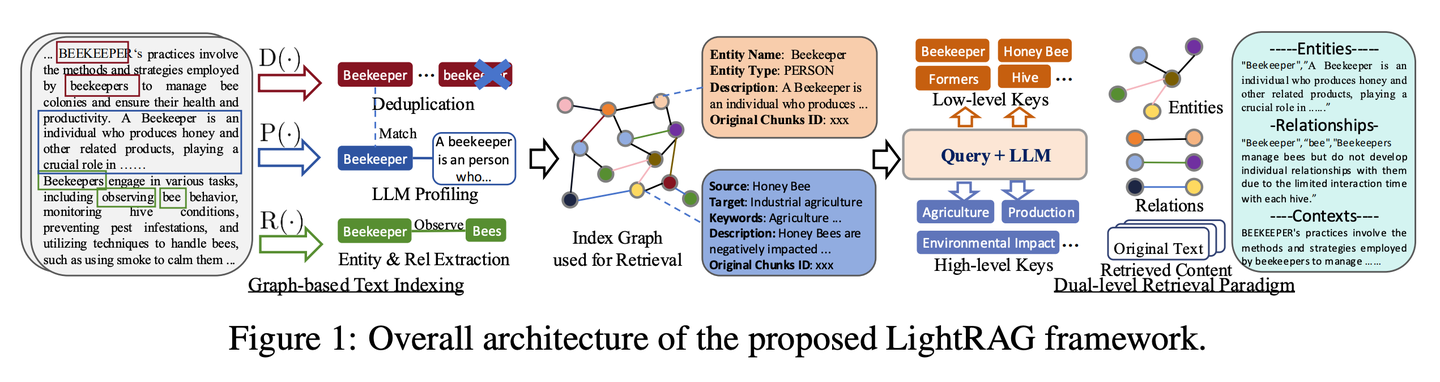
(51) AstuteRAG【明智判官】
明智判官:對外部信息保持警惕,不輕信檢索結(jié)果,善用自身積累的知識,甄別信息真?zhèn)危褓Y深法官一樣,權(quán)衡多方證據(jù)定論。
- 時間:10.09
- 論文:Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
- 參考:https://mp.weixin.qq.com/s/Y8ozl3eH1osJTNOSuu4v1w
通過適應(yīng)性地從LLMs內(nèi)部知識中提取信息,結(jié)合外部檢索結(jié)果,并根據(jù)信息的可靠性來最終確定答案,從而提高系統(tǒng)的魯棒性和可信度。
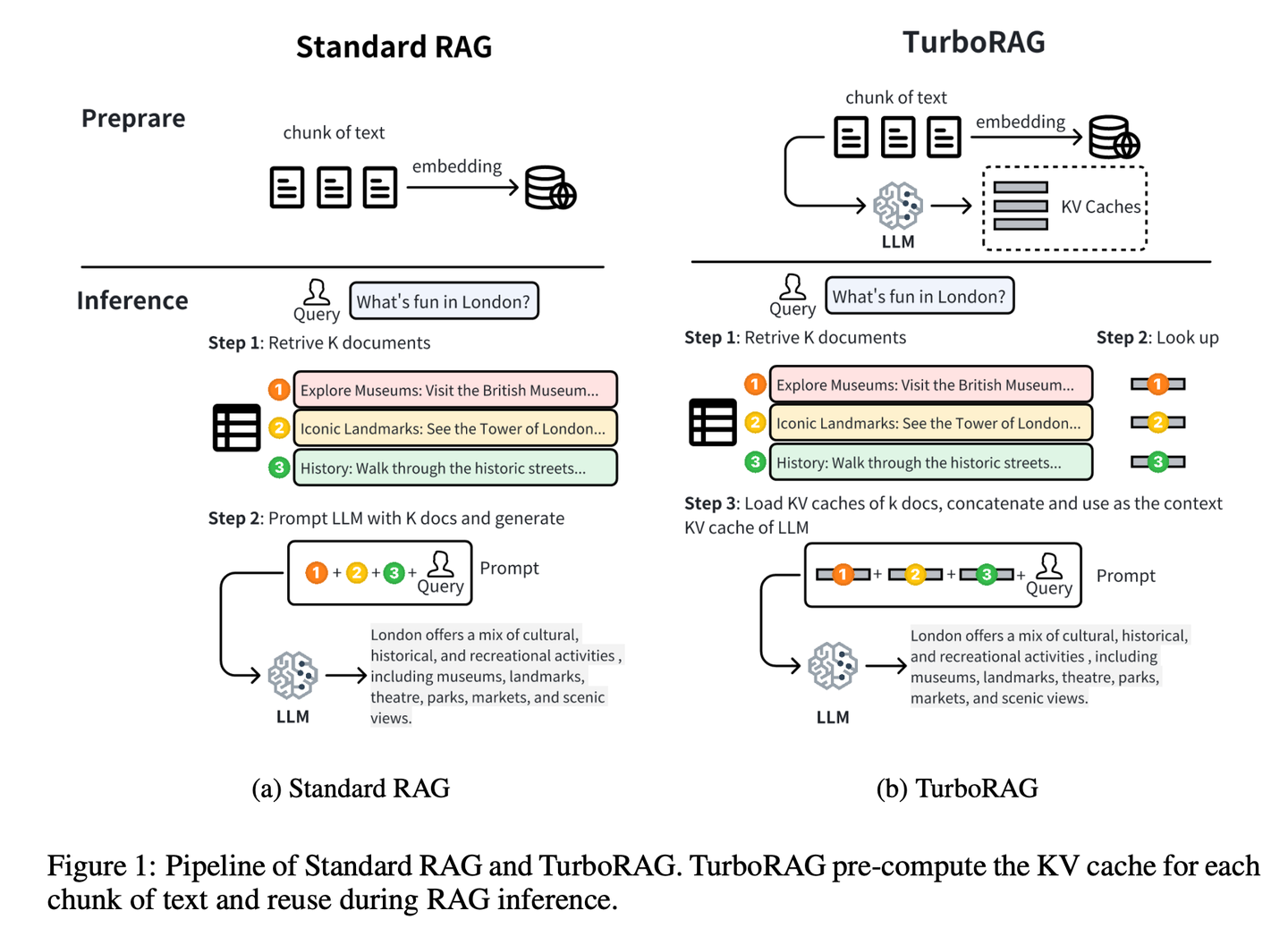
(52) TurboRAG【速記高手】
速記高手:提前把功課做好,把答案都記在小本本里。像個考前突擊的學(xué)霸,不是臨場抱佛腳,而是把常考題提前整理成錯題本。需要的時候直接翻出來用,省得每次都要現(xiàn)場推導(dǎo)一遍。
- 時間:10.10
- 論文:TurboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text
- 項目:https://github.com/MooreThreads/TurboRAG
- 參考:https://mp.weixin.qq.com/s/lanZ8cIEnIt12tFt4d-xzw
TurboRAG通過離線預(yù)計算和存儲文檔的KV緩存來優(yōu)化RAG系統(tǒng)的推理范式。與傳統(tǒng)方法不同,TurboRAG在每次推理時不再計算這些KV緩存,而是檢索預(yù)先計算的緩存以進行高效的預(yù)填充,從而消除了重復(fù)在線計算的需要。這種方法顯著減少了計算開銷,加快了響應(yīng)時間,同時保持了準確性。
(53) StructRAG【收納師】
收納師:把雜亂無章的信息像收納衣柜一樣分門別類地整理好。像個模仿人類思維的學(xué)霸,不是死記硬背,而是先畫個思維導(dǎo)圖。
- 時間:10.11
- 論文:StructRAG: Boosting Knowledge Intensive Reasoning of LLMs via Inference-time Hybrid Information Structurization
- 項目:https://github.com/Li-Z-Q/StructRAG
- 參考:https://mp.weixin.qq.com/s/9UQOozHNHDRade5b6Onr6w
受人類在處理知識密集型推理時將原始信息轉(zhuǎn)換為結(jié)構(gòu)化知識的認知理論啟發(fā),該框架引入了一種混合信息結(jié)構(gòu)化機制,該機制根據(jù)手頭任務(wù)的特定要求以最合適的格式構(gòu)建和利用結(jié)構(gòu)化知識。通過模仿類人的思維過程,提高了LLM在知識密集型推理任務(wù)上的表現(xiàn)。

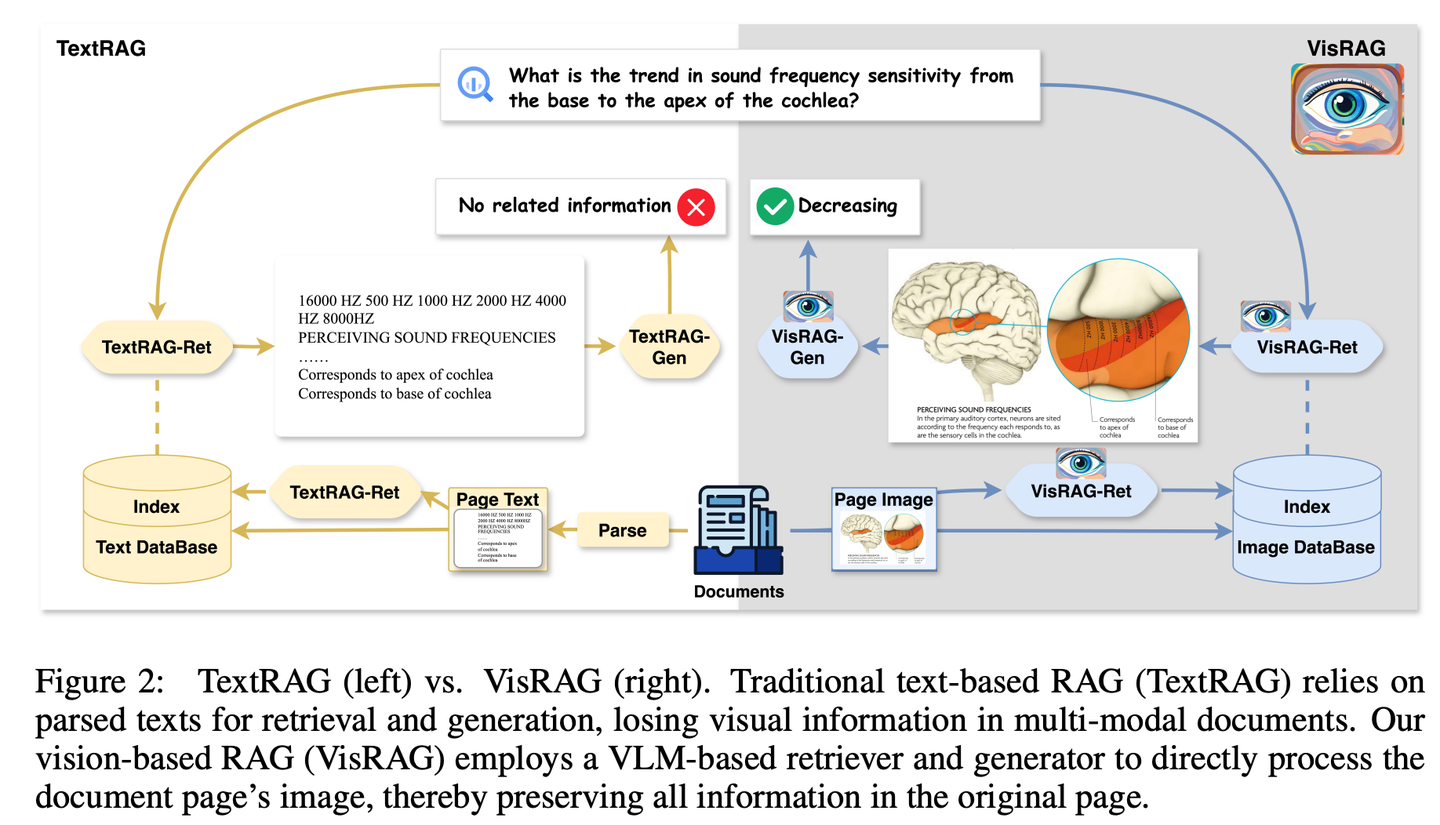
(54) VisRAG【火眼金睛】
火眼金睛:終于悟出文字不過是圖像的一種特殊表現(xiàn)形式。像個開了天眼的閱讀者,不再執(zhí)著于逐字解析,而是直接"看"透全局。用照相機代替了OCR,懂得了"一圖勝千言"的精髓。
- 時間:10.14
- 論文:VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents
- 項目:https://github.com/openbmb/visrag
- 參考:https://mp.weixin.qq.com/s/WB23pwJD-JV95ZlpB3bUew
通過構(gòu)建基于視覺-語言模型 (VLM) 的RAG流程,直接將文檔作為圖像嵌入并檢索,從而增強生成效果。相比傳統(tǒng)文本RAG,VisRAG避免了解析過程中的信息損失,更全面地保留了原始文檔的信息。實驗顯示,VisRAG在檢索和生成階段均超越傳統(tǒng)RAG,端到端性能提升達25-39%。VisRAG不僅有效利用訓(xùn)練數(shù)據(jù),還展現(xiàn)出強大的泛化能力,成為多模態(tài)文檔RAG的理想選擇。
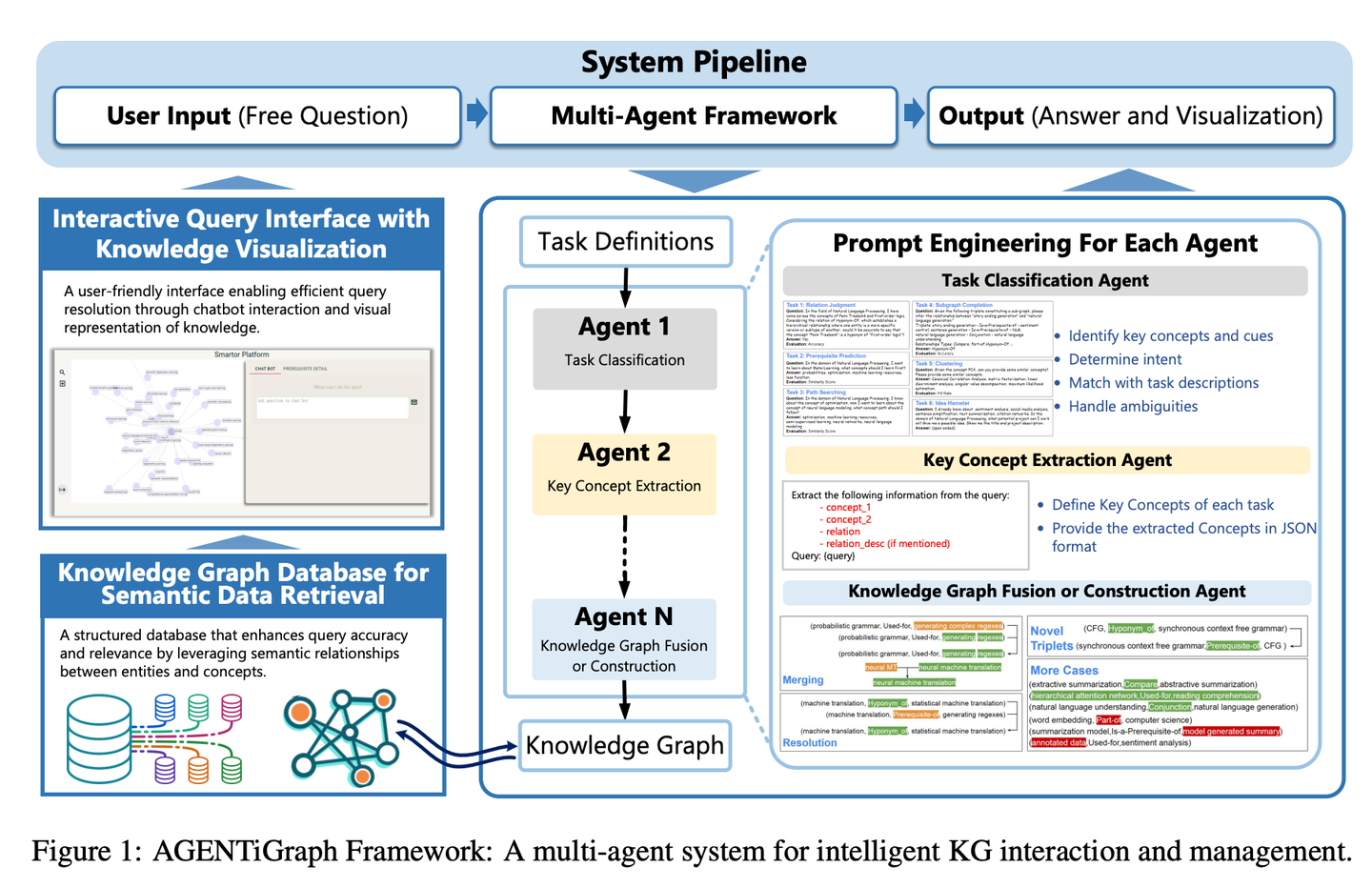
(55) AGENTiGraph【知識管家】
知識管家:像個善于對話的圖書管理員,通過日常交流幫你整理和展示知識,帶著一隊助手隨時準備解答問題、更新資料,讓知識管理變得簡單自然。
- 時間:10.15
- 論文:AGENTiGraph: An Interactive Knowledge Graph Platform for LLM-based Chatbots Utilizing Private Data
- 參考:https://mp.weixin.qq.com/s/iAlcxjXHlz7xfwVd4lpQ-g
AGENTiGraph通過自然語言交互進行知識管理的平臺。它集成了知識提取、集成和實時可視化。AGENTiGraph 采用多智能體架構(gòu)來動態(tài)解釋用戶意圖、管理任務(wù)和集成新知識,確保能夠適應(yīng)不斷變化的用戶需求和數(shù)據(jù)上下文。
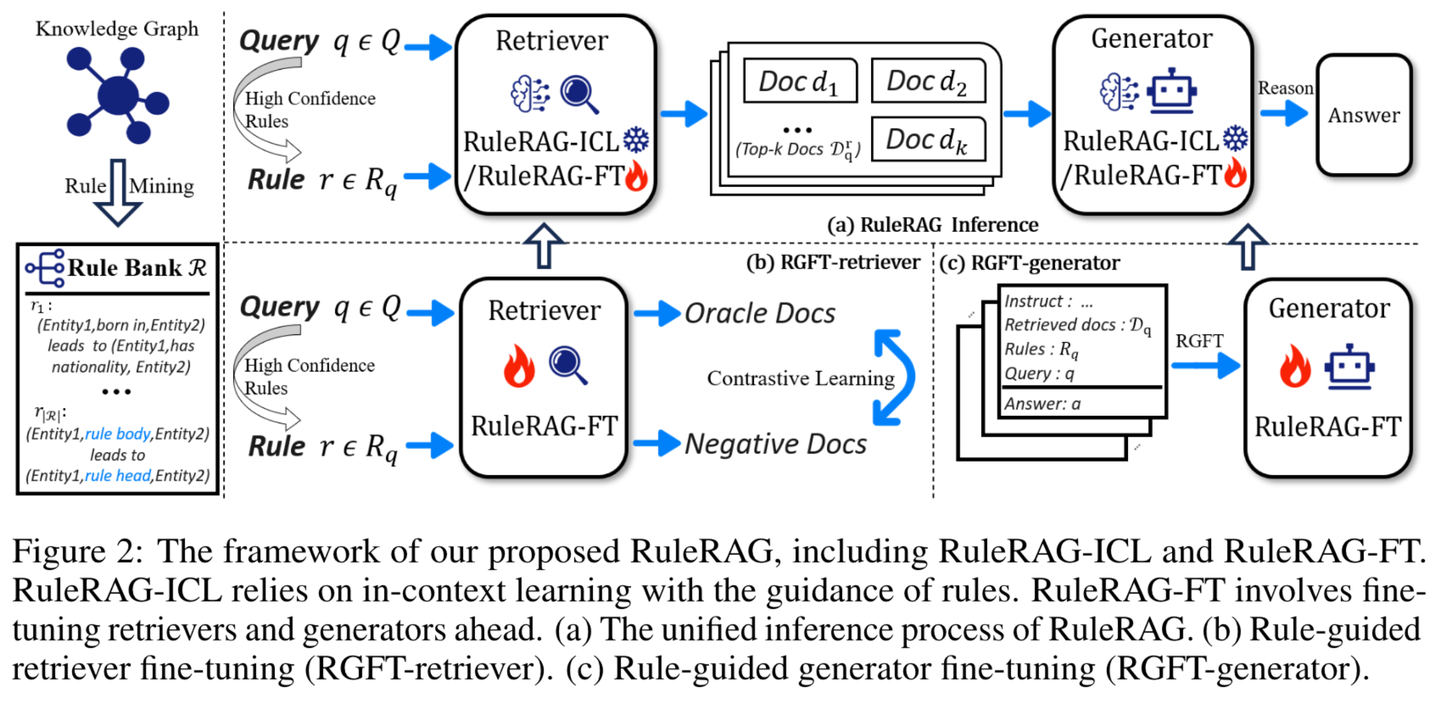
(56) RuleRAG【循規(guī)蹈矩】
循規(guī)蹈矩:用規(guī)矩來教AI做事,就像帶新人入職,先給本員工手冊。不是漫無目的地學(xué),而是像個嚴格的老師,先把規(guī)矩和范例都講明白,然后再讓學(xué)生自己動手。做多了,這些規(guī)矩就變成了肌肉記憶,下次遇到類似問題自然知道怎么處理。
- 時間:10.15
- 論文:RuleRAG: Rule-guided retrieval-augmented generation with language models for question answering
- 項目:https://github.com/chenzhongwu20/RuleRAG_ICL_FT
- 參考:https://mp.weixin.qq.com/s/GNLvKG8ZgJzzNsWyVbSSig
RuleRAG提出了基于語言模型的規(guī)則引導(dǎo)檢索增強生成方法,該方法明確引入符號規(guī)則作為上下文學(xué)習(xí)(RuleRAG - ICL)的示例,以引導(dǎo)檢索器按照規(guī)則方向檢索邏輯相關(guān)的文檔,并統(tǒng)一引導(dǎo)生成器在同一組規(guī)則的指導(dǎo)下生成有依據(jù)的答案。此外,查詢和規(guī)則的組合可進一步用作有監(jiān)督的微調(diào)數(shù)據(jù),用以更新檢索器和生成器(RuleRAG - FT),從而實現(xiàn)更好的基于規(guī)則的指令遵循能力,進而檢索到更具支持性的結(jié)果并生成更可接受的答案。
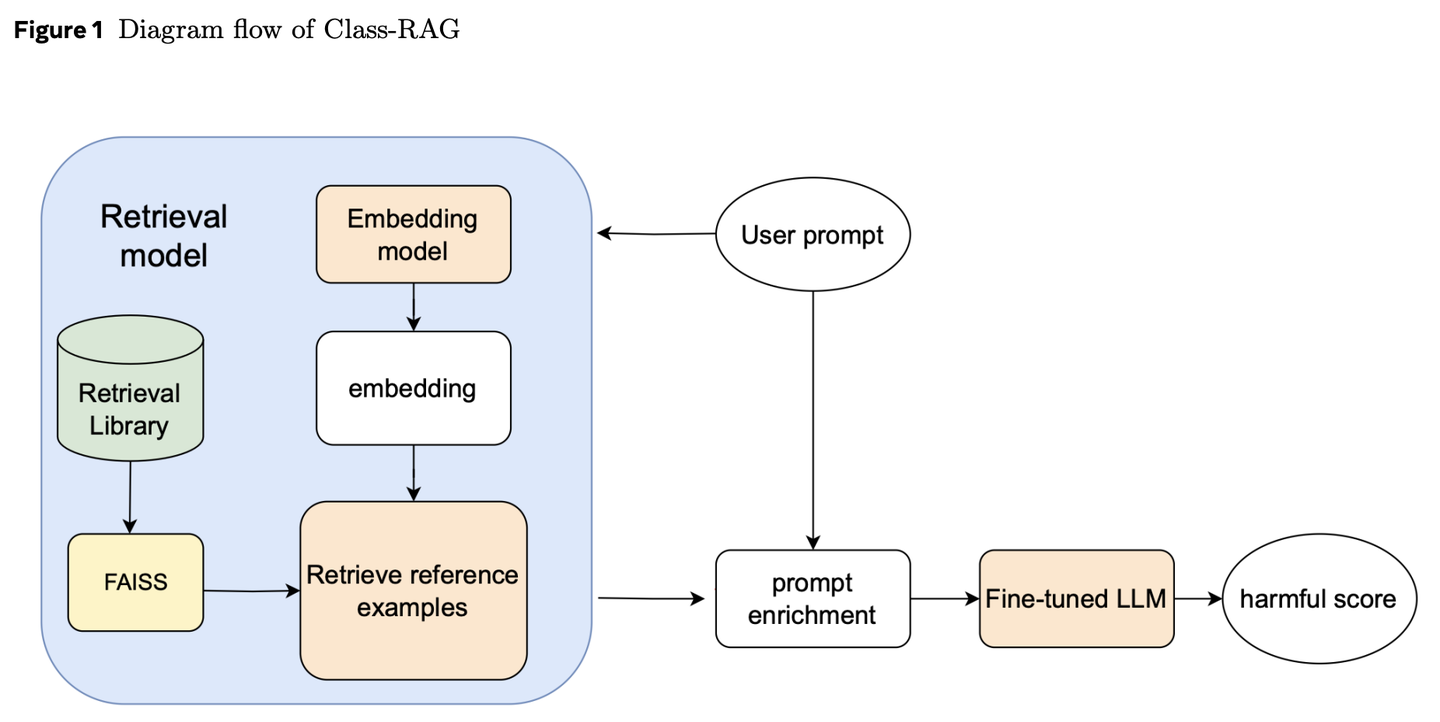
(57) Class-RAG【法官】
法官:不是靠死板的條文判案,而是通過不斷擴充的判例庫來研判。像個經(jīng)驗老到的法官,手握活頁法典,隨時翻閱最新案例,讓判決既有溫度又有尺度。
- 時間:10.18
- 論文:Class-RAG: Content Moderation with Retrieval Augmented Generation
- 參考:https://mp.weixin.qq.com/s/4AfZodMGJ5JQ2NUCFt3eqQ
內(nèi)容審核分類器對生成式 AI 的安全性至關(guān)重要。然而,安全與不安全內(nèi)容間的細微差別常令人難以區(qū)分。隨著技術(shù)廣泛應(yīng)用,持續(xù)微調(diào)模型以應(yīng)對風險變得愈發(fā)困難且昂貴。為此,我們提出 Class-RAG 方法,通過動態(tài)更新檢索庫,實現(xiàn)即時風險緩解。與傳統(tǒng)微調(diào)模型相比,Class-RAG 更具靈活性與透明度,且在分類與抗攻擊方面表現(xiàn)更佳。研究還表明,擴大檢索庫能有效提升審核性能,成本低廉。
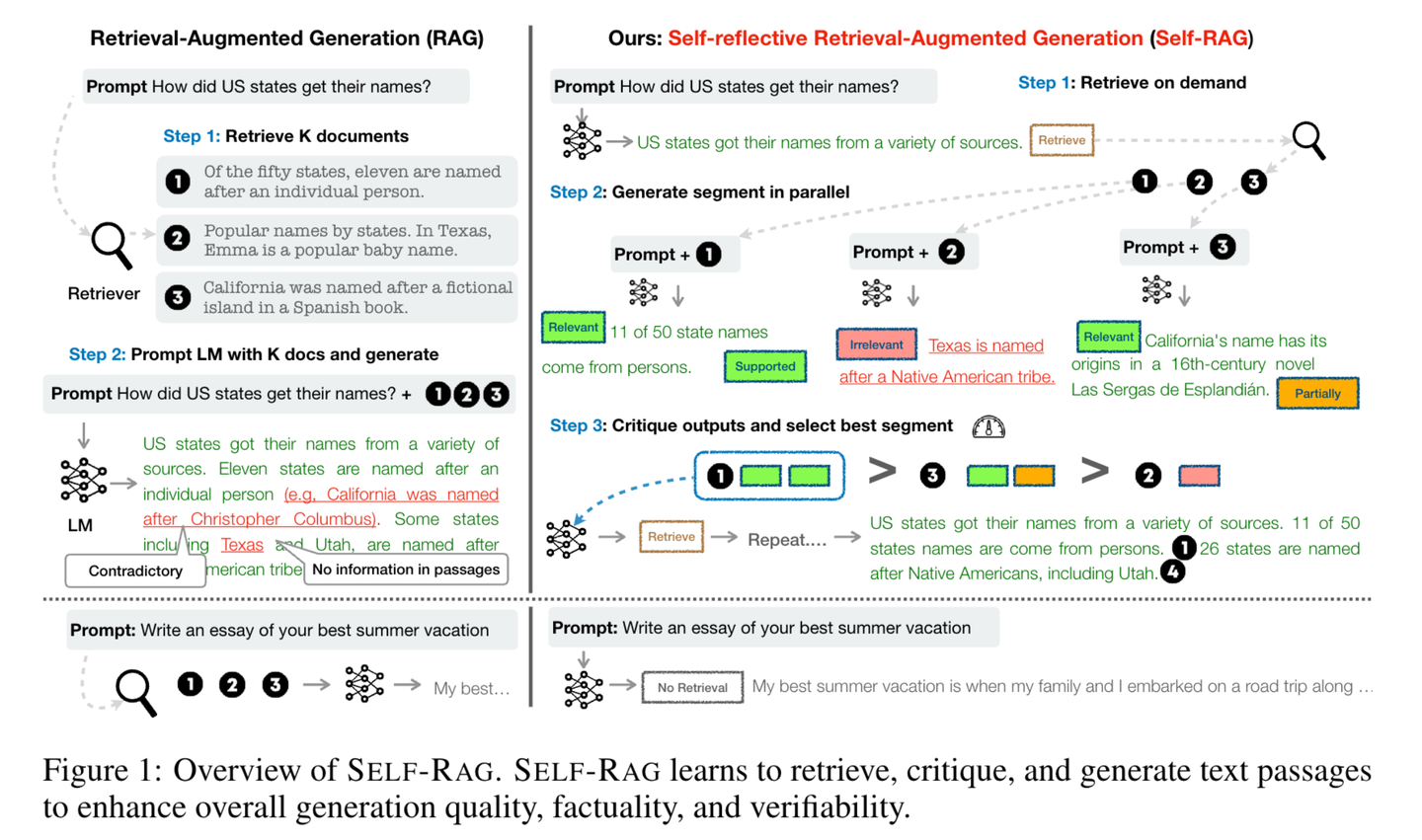
(58) Self-RAG【反思者】
反思者:在回答問題時,不僅會查閱資料,還會不斷思考和檢查自己的答案是否準確完整。通過"邊說邊想"的方式,像一個謹慎的學(xué)者一樣,確保每個觀點都有可靠的依據(jù)支持。
- 時間:10.23
- 論文:Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- 項目:https://github.com/AkariAsai/self-rag
- 參考:https://mp.weixin.qq.com/s/y-hN17xFyODxzTIfEfm1Vg
Self-RAG通過檢索和自我反思來提升語言模型的質(zhì)量和準確性。框架訓(xùn)練一個單一的任意語言模型,該模型能按需自適應(yīng)地檢索文段,并使用被稱為反思標記的特殊標記來對檢索到的文段及其自身生成的內(nèi)容進行生成和反思。生成反思標記使得語言模型在推理階段具備可控性,使其能夠根據(jù)不同的任務(wù)要求調(diào)整自身行為。
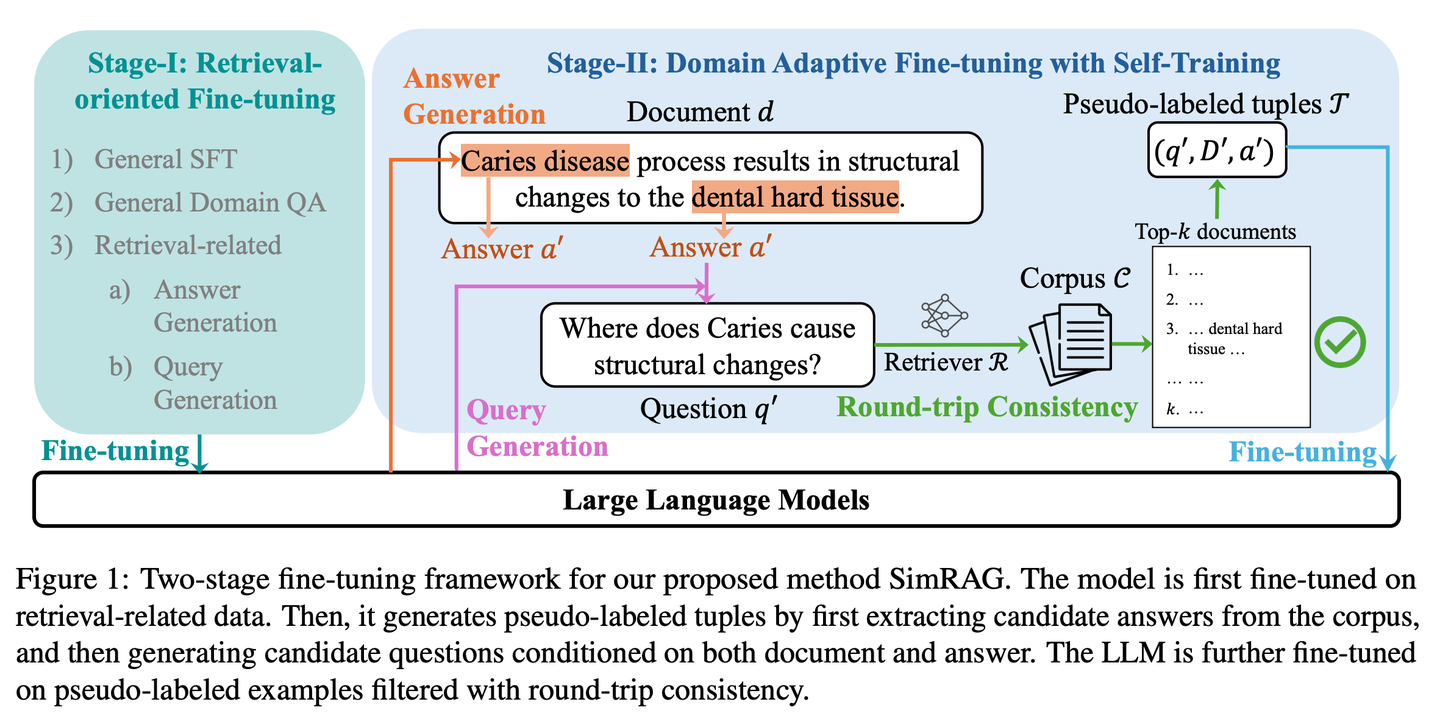
(59) SimRAG【自學(xué)成才】
自學(xué)成才:面對專業(yè)領(lǐng)域時,先自己提問再自己回答,通過不斷練習(xí)來提升專業(yè)知識儲備,就像學(xué)生通過反復(fù)做習(xí)題來熟悉專業(yè)知識一樣。
- 時間:10.23
- 論文:SimRAG: Self-Improving Retrieval-Augmented Generation for Adapting Large Language Models to Specialized Domains
- 參考:https://mp.weixin.qq.com/s/pR-W_bQEA4nM86YsVTThtA
SimRAG是一種自訓(xùn)練方法,使LLM具備問答和問題生成的聯(lián)合能力以適應(yīng)特定領(lǐng)域。只有真正理解了知識,才能提出好的問題。這兩個能力相輔相成,可以幫助模型更好地理解專業(yè)知識。首先在指令遵循、問答和搜索相關(guān)數(shù)據(jù)上對LLM進行微調(diào)。然后,它促使同一LLM從無標簽語料庫中生成各種與領(lǐng)域相關(guān)的問題,并采用額外的過濾策略來保留高質(zhì)量的合成示例。通過利用這些合成示例,LLM可以提高其在特定領(lǐng)域RAG任務(wù)上的性能。
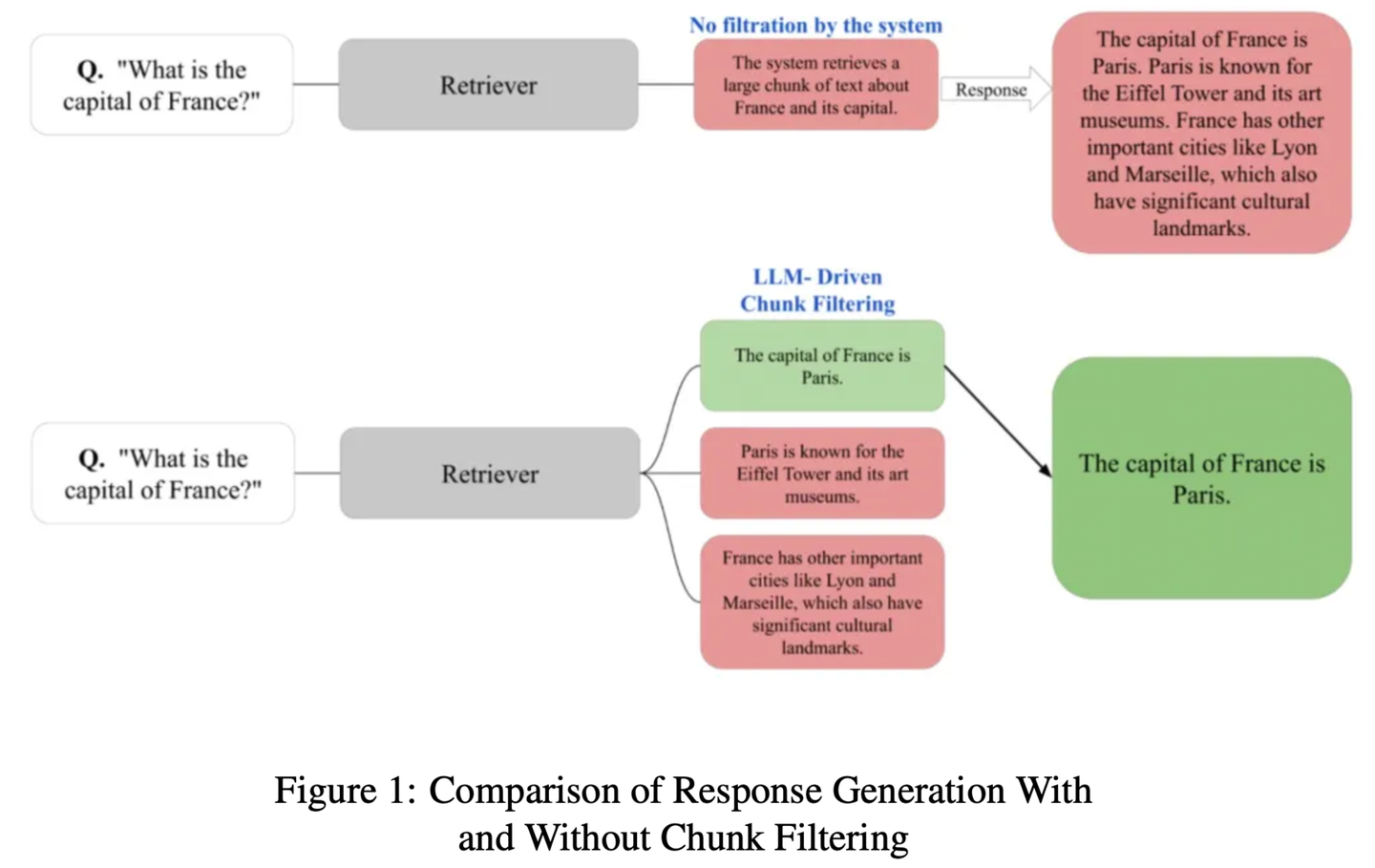
(60) ChunkRAG【摘抄達人】
摘抄達人:先把長文章分成小段落,再用專業(yè)眼光挑出最相關(guān)的片段,既不遺漏重點,又不被無關(guān)內(nèi)容干擾。
- 時間:10.23
- 論文:ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems
- 參考:https://mp.weixin.qq.com/s/Pw7_vQ9bhdDFTmoVwxGCyg
ChunkRAG提出LLM驅(qū)動的塊過濾方法,通過在塊級別評估和過濾檢索到的信息來增強RAG系統(tǒng)的框架,其中 “塊” 代表文檔中較小的連貫部分。我們的方法采用語義分塊將文檔劃分為連貫的部分,并利用基于大語言模型的相關(guān)性評分來評估每個塊與用戶查詢的匹配程度。通過在生成階段之前過濾掉不太相關(guān)的塊,我們顯著減少了幻覺并提高了事實準確性。
(61) FastGraphRAG【雷達】
雷達:像谷歌網(wǎng)頁排名一樣,給知識點也排出個熱度榜。就好比社交網(wǎng)絡(luò)中的意見領(lǐng)袖,越多人關(guān)注就越容易被看見。它不是漫無目的地搜索,而是像個帶著雷達的偵察兵,哪里的信號強就往哪里看。
- 時間:10.23
- 項目:https://github.com/circlemind-ai/fast-graphrag
- 參考:https://mp.weixin.qq.com/s/uBcYaO5drTUabcCXh3bzjA
FastGraphRAG提供了一個高效、可解釋且精度高的快速圖檢索增強生成(FastGraphRAG)框架。它將PageRank算法應(yīng)用于知識圖譜的遍歷過程,快速定位最相關(guān)的知識節(jié)點。通過計算節(jié)點的重要性得分,PageRank使GraphRAG能夠更智能地篩選和排序知識圖譜中的信息。這就像是為GraphRAG裝上了一個"重要性雷達",能夠在浩如煙海的數(shù)據(jù)中快速定位關(guān)鍵信息。
(62) AutoRAG【調(diào)音師】
調(diào)音師:一位經(jīng)驗豐富的調(diào)音師,不是靠猜測調(diào)音,而是通過科學(xué)測試找到最佳音效。它會自動嘗試各種RAG組合,就像調(diào)音師測試不同的音響設(shè)備搭配,最終找到最和諧的"演奏方案"。
- 時間:10.28
- 論文:AutoRAG: Automated Framework for optimization of Retrieval Augmented Generation Pipeline
- 項目:https://github.com/Marker-Inc-Korea/AutoRAG_ARAGOG_Paper
- 參考:https://mp.weixin.qq.com/s/96r6y3cNmLRL2Z0W78X1OQ
AutoRAG框架能夠自動為給定數(shù)據(jù)集識別合適的RAG模塊,并探索和逼近該數(shù)據(jù)集的RAG模塊的最優(yōu)組合。通過系統(tǒng)評估不同的RAG設(shè)置來優(yōu)化技術(shù)選擇,該框架類似于傳統(tǒng)機器學(xué)習(xí)中的AutoML實踐,通過廣泛實驗來優(yōu)化RAG技術(shù)的選擇,提高RAG系統(tǒng)的效率和可擴展性。
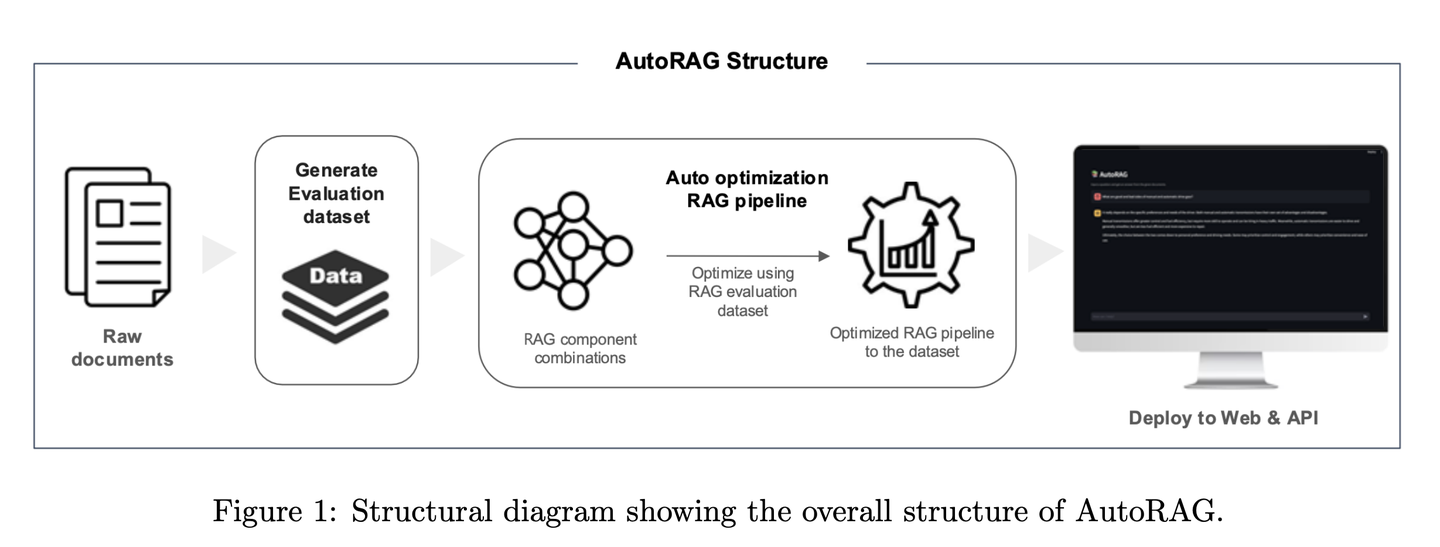
(63) Plan×RAG【項目經(jīng)理】
項目經(jīng)理:先規(guī)劃后行動,把大任務(wù)分解成小任務(wù),安排多個"專家"并行工作。每個專家負責自己的領(lǐng)域,最后由項目經(jīng)理統(tǒng)籌匯總結(jié)果。這種方式不僅更快、更準,還能清楚交代每個結(jié)論的來源。
- 時間:10.28
- 論文:Plan×RAG: Planning-guided Retrieval Augmented Generation
- 參考:https://mp.weixin.qq.com/s/I_-NDGzd7d8l4zjRfCsvDQ
Plan×RAG是一個新穎的框架,它將現(xiàn)有RAG框架的 “檢索 - 推理” 范式擴充為 “計劃 - 檢索”范式。Plan×RAG 將推理計劃制定為有向無環(huán)圖(DAG),將查詢分解為相互關(guān)聯(lián)的原子子查詢。答案生成遵循 DAG 結(jié)構(gòu),通過并行檢索和生成顯著提高效率。雖然最先進的RAG解決方案需要大量的數(shù)據(jù)生成和語言模型(LMs)的微調(diào),但Plan×RAG納入了凍結(jié)的LMs作為即插即用的專家來生成高質(zhì)量的答案。
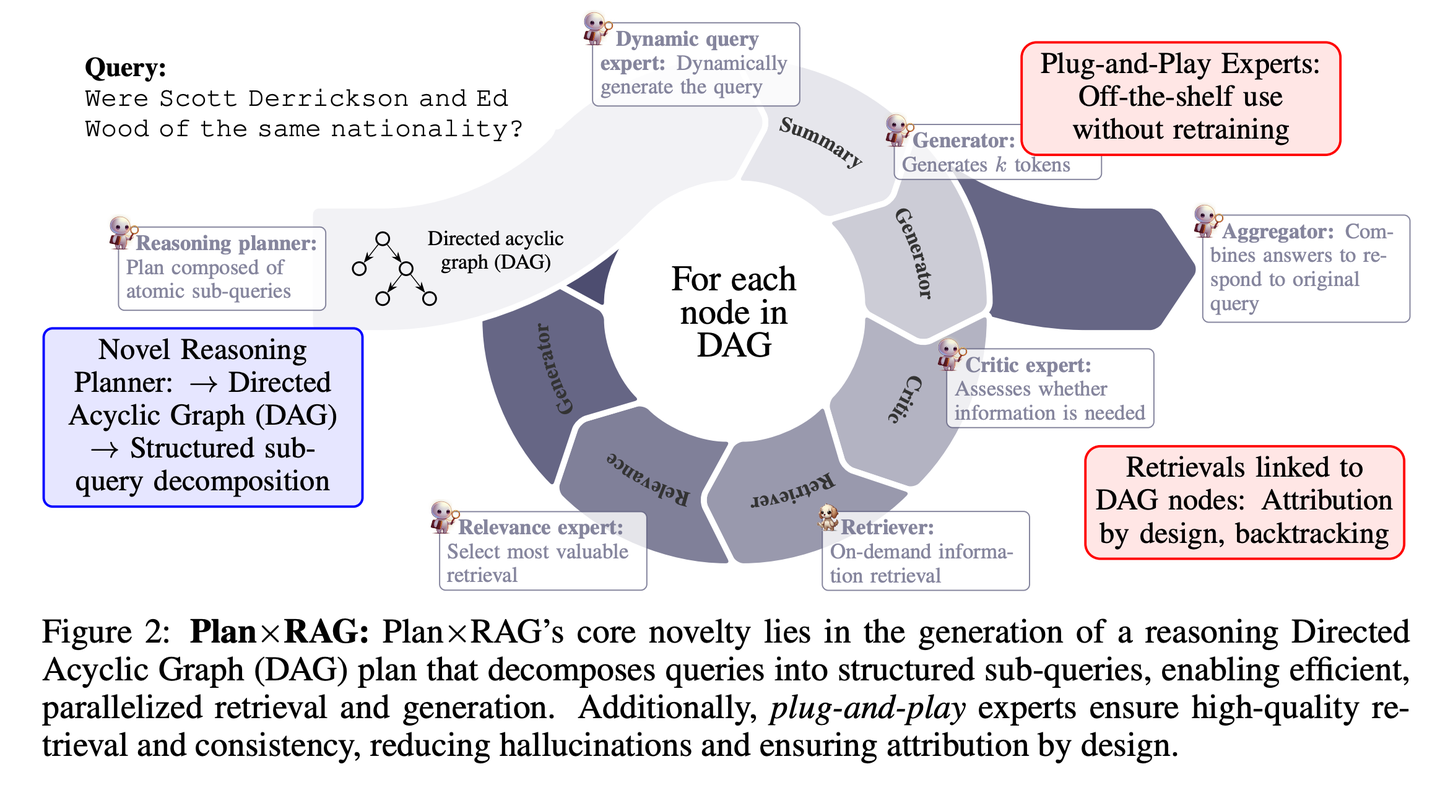
(64) SubgraphRAG【定位儀】
定位儀:不是漫無目的地大海撈針,而是精準繪制一張小型知識地圖,讓 AI 能快速找到答案。
- 時間:10.28
- 論文:Simple is Effective: The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation
- 項目:https://github.com/Graph-COM/SubgraphRAG
- 參考:https://mp.weixin.qq.com/s/ns22XLKsABly7RjpSjQ_Fw
SubgraphRAG擴展了基于KG的RAG框架,通過檢索子圖并利用LLM進行推理和答案預(yù)測。將輕量級多層感知器與并行三元組評分機制相結(jié)合,以實現(xiàn)高效靈活的子圖檢索,同時編碼有向結(jié)構(gòu)距離以提高檢索有效性。檢索到的子圖大小可以靈活調(diào)整,以匹配查詢需求和下游LLM的能力。這種設(shè)計在模型復(fù)雜性和推理能力之間取得了平衡,實現(xiàn)了可擴展且通用的檢索過程。
2024.11
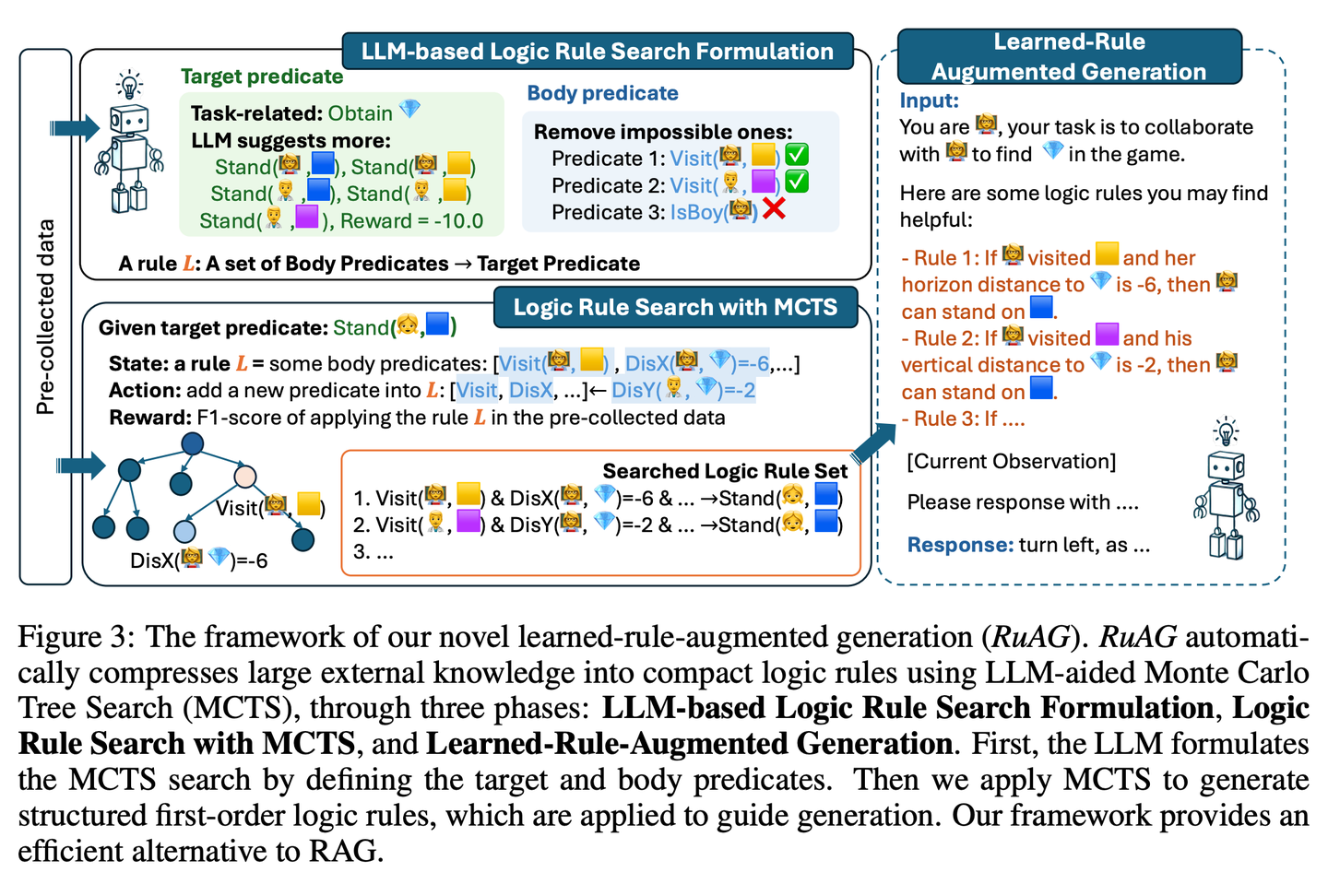
(65) RuAG【煉金術(shù)士】
煉金術(shù)士:像個煉金術(shù)士,能將海量數(shù)據(jù)提煉成清晰的邏輯規(guī)則,并用通俗易懂的語言表達出來,讓AI在實際應(yīng)用中更有智慧。
- 時間:11.04
- 論文:RuAG: Learned-rule-augmented Generation for Large Language Models
- 參考:https://mp.weixin.qq.com/s/A4vjN1eJr7hJd75UH0kuXA
旨在通過將大量離線數(shù)據(jù)自動蒸餾成可解釋的一階邏輯規(guī)則,并注入大型語言模型(LLM)中,以提升其推理能力。該框架使用蒙特卡洛樹搜索(MCTS)來發(fā)現(xiàn)邏輯規(guī)則,并將這些規(guī)則轉(zhuǎn)化為自然語言,實現(xiàn)針對LLM下游任務(wù)的知識注入和無縫集成。該論文在公共和私有工業(yè)任務(wù)上評估了該框架的有效性,證明了其在多樣化任務(wù)中增強LLM能力的潛力。
(66) RAGViz【透視眼】
透視眼:讓RAG系統(tǒng)變透明,看得見模型在讀哪句話,像醫(yī)生看X光片一樣,哪里不對一目了然。
- 時間:11.04
- 論文:RAGViz: Diagnose and Visualize Retrieval-Augmented Generation
- 項目:https://github.com/cxcscmu/RAGViz
- 參考:https://mp.weixin.qq.com/s/ZXvAWDhqKRPq1u9NTfYFnQ
RAGViz提供了對檢索文檔和模型注意力的可視化,幫助用戶理解生成的標記與檢索文檔之間的交互,可用于診斷和可視化RAG系統(tǒng)。

(67) AgenticRAG【智能助手】
智能助手:不再是簡單的查找復(fù)制,而是配了個能當機要秘書的助手。像個得力的行政官,不光會查資料,還知道什么時候該打電話,什么時候該開會,什么時候該請示領(lǐng)導(dǎo)。
AgenticRAG描述了基于AI智能體實現(xiàn)的RAG。具體來說,它將AI智能體納入RAG流程中,以協(xié)調(diào)其組件并執(zhí)行超出簡單信息檢索和生成的額外行動,以克服非智能體流程的局限性。
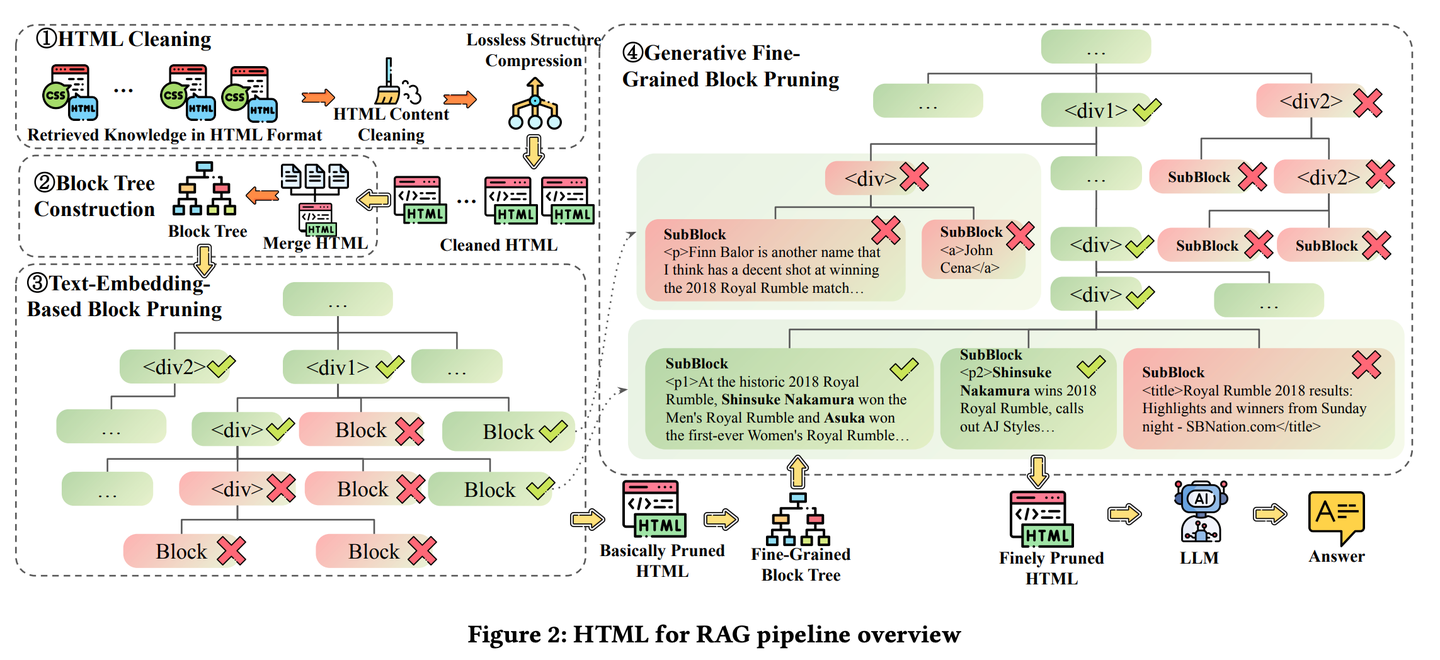
(68) HtmlRAG【排版師】
排版師:把知識不是當作流水賬來記,而是像排版雜志一樣,該加粗的加粗,該標紅的標紅。就像一個挑剔的美編,覺得光有內(nèi)容不夠,還得講究排版,這樣重點才能一目了然。
- 時間:11.05
- 論文:HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems
- 項目:https://github.com/plageon/HtmlRAG
- 參考:https://mp.weixin.qq.com/s/1X6k9QI71BIyQ4IELQxOlA
HtmlRAG在RAG中使用HTML而不是純文本作為檢索知識的格式,在對外部文檔中的知識進行建模時,HTML比純文本更好,并且大多數(shù)LLM具有強大的理解HTML的能力。HtmlRAG提出了HTML清理、壓縮和修剪策略,以縮短HTML同時最小化信息損失。
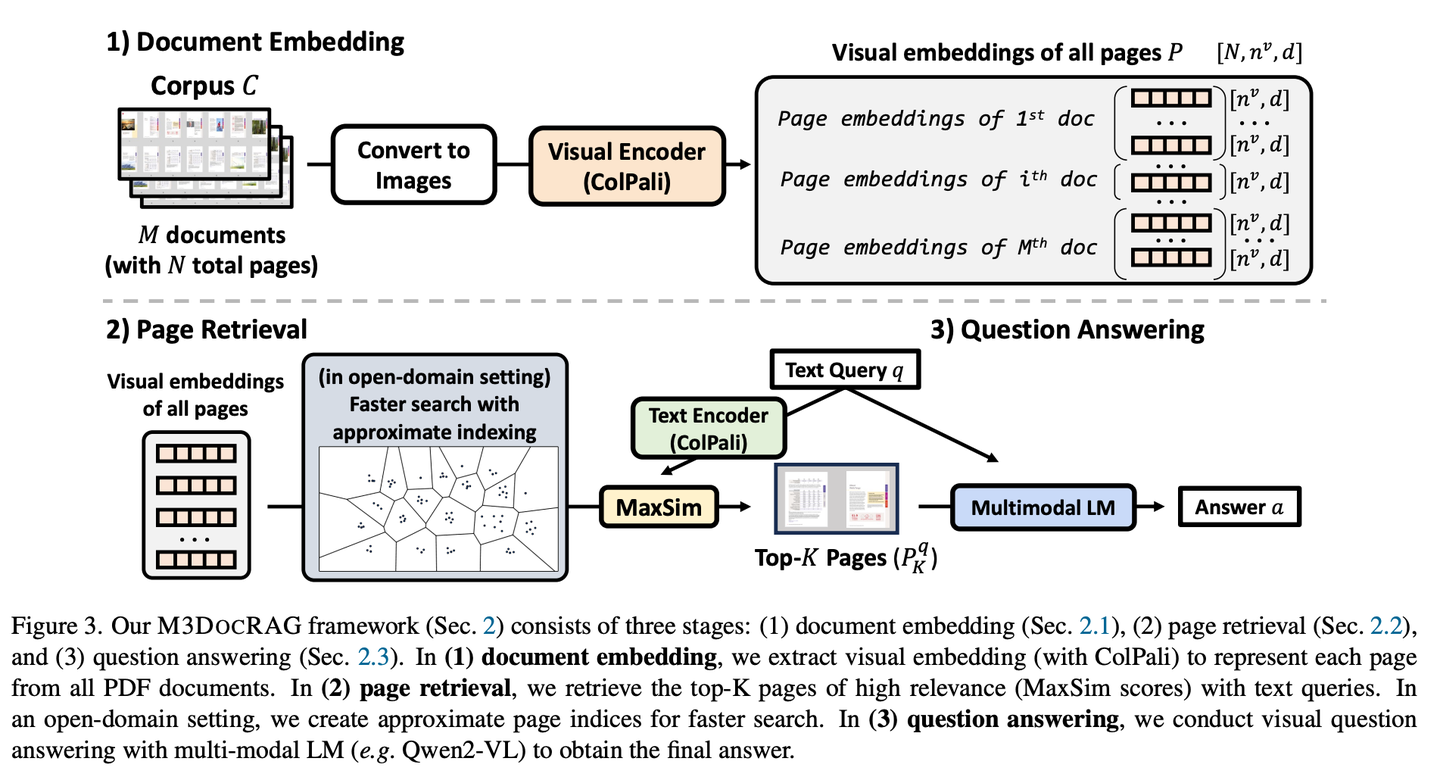
(69) M3DocRAG【感官達人】
感官達人:不是只會讀書,還能看圖識圖,聽聲辨位。像個綜藝節(jié)目里的全能選手,圖片能看懂,文字能理解,該跳躍思維時就跳躍,該專注細節(jié)時就專注,各種挑戰(zhàn)都難不倒。
- 時間:11.07
- 論文:M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding
- 參考:https://mp.weixin.qq.com/s/a9tDj6BmIZHs2vTFXKSPcA
M3DocRAG是一種新穎的多模態(tài)RAG框架,能夠靈活適應(yīng)各種文檔上下文(封閉域和開放域)、問題跳轉(zhuǎn)(單跳和多跳)和證據(jù)模式(文本、圖表、圖形等)。M3DocRAG使用多模態(tài)檢索器和MLM查找相關(guān)文檔并回答問題,因此它可以有效地處理單個或多個文檔,同時保留視覺信息。
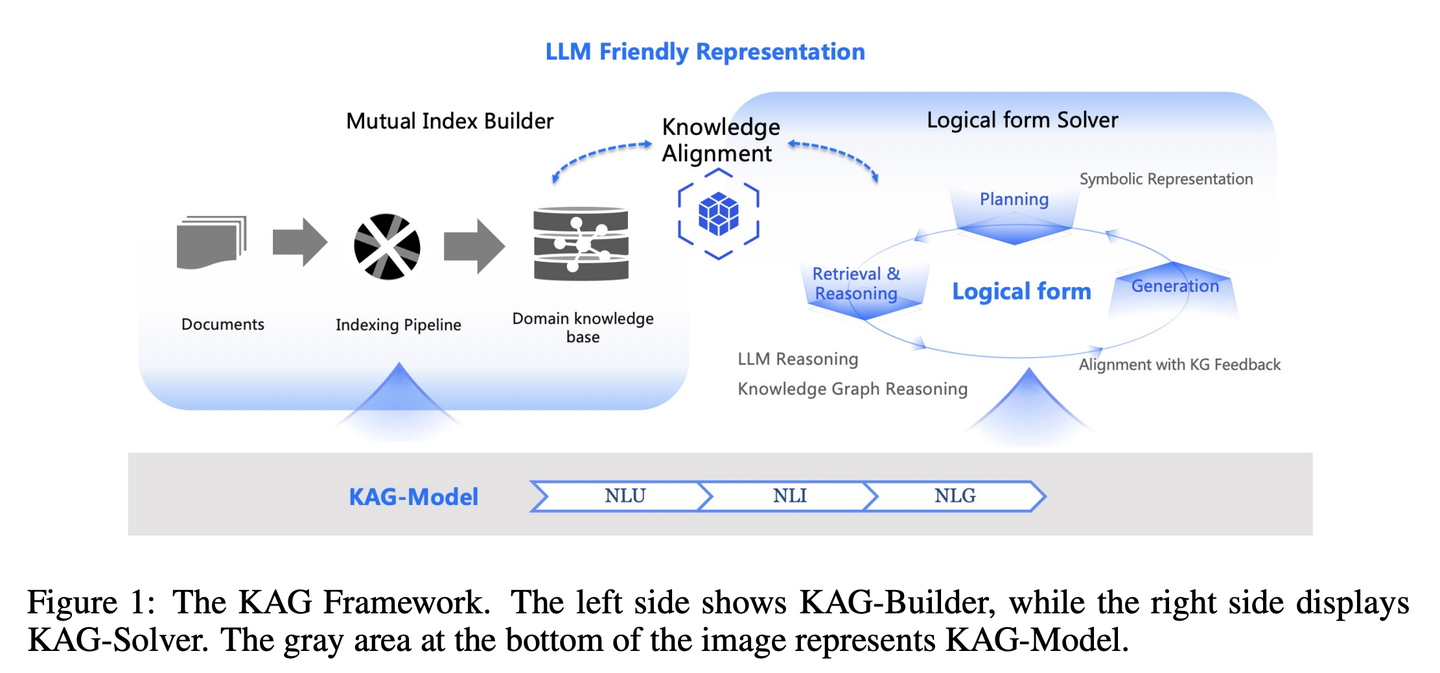
(70) KAG【邏輯大師】
邏輯大師:不光靠感覺找相似的答案,還得講究知識間的因果關(guān)系。像個嚴謹?shù)臄?shù)學(xué)老師,不僅要知道答案是什么,還得解釋清楚這答案是怎么一步步推導(dǎo)出來的。
- 時間:11.10
- 論文:KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation
- 項目:https://github.com/OpenSPG/KAG
- 參考:https://mp.weixin.qq.com/s/oOzFBHS_B7FST6YKynD1GA
RAG中向量相似性與知識推理的相關(guān)性之間的差距,以及對知識邏輯(如數(shù)值、時間關(guān)系、專家規(guī)則等)不敏感阻礙了專業(yè)知識服務(wù)的有效性。KAG的設(shè)計目的是充分利用知識圖譜(KG)和向量檢索的優(yōu)勢來應(yīng)對上述挑戰(zhàn),并通過五個關(guān)鍵方面雙向增強大型語言模型(LLM)和知識圖譜來提高生成和推理性能:(1)對LLM友好的知識表示,(2)知識圖譜與原始塊之間的相互索引,(3)邏輯形式引導(dǎo)的混合推理引擎,(4)與語義推理的知識對齊,(5)KAG的模型能力增強。
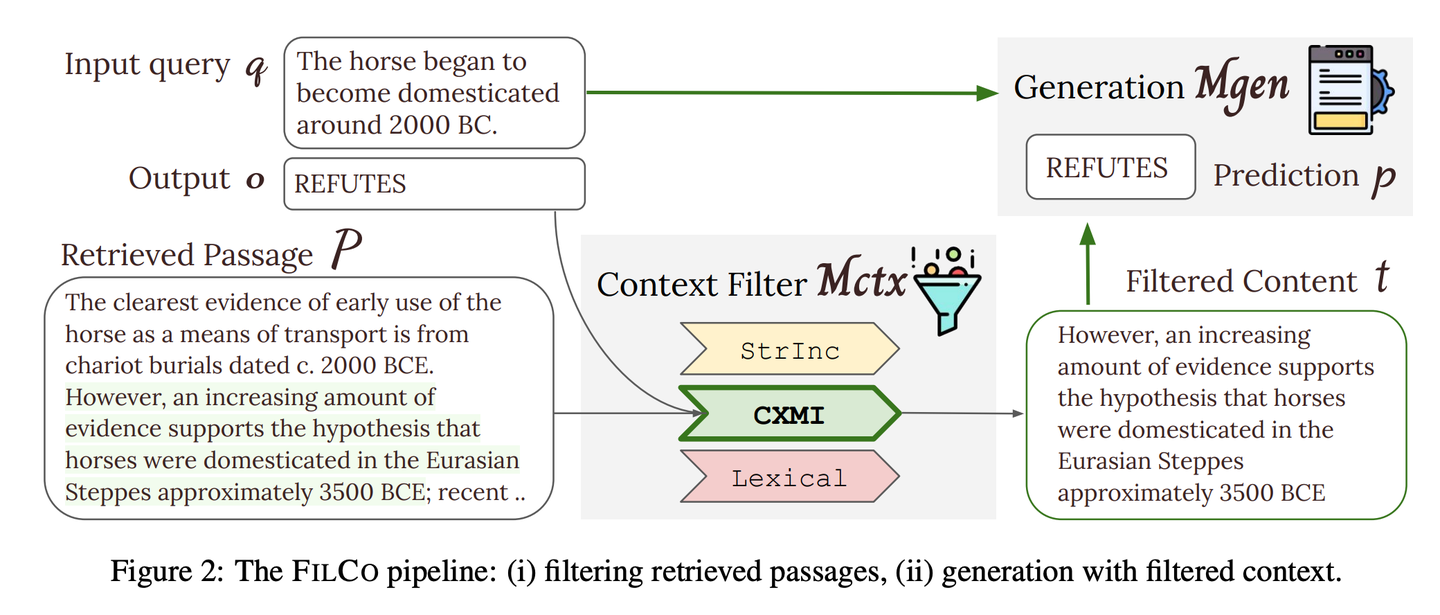
(71) FILCO【篩選師】
篩選師:像個嚴謹?shù)木庉嫞朴趶拇罅课谋局凶R別并保留最有價值的信息,確保傳遞給AI的每段內(nèi)容都精準且相關(guān)。
- 時間:11.14
- 論文:Learning to Filter Context for Retrieval-Augmented Generation
- 項目:https://github.com/zorazrw/filco
- 參考:https://mp.weixin.qq.com/s/93CdvD8FLZjaA7E724bf7g
FILCO通過基于詞法和信息論方法識別有用的上下文,以及訓(xùn)練上下文過濾模型,以過濾檢索到的上下文,來提高提供給生成器的上下文質(zhì)量。
(72) LazyGraphRAG【精算師】
精算師:能省一步是一步,把貴的大模型用在刀刃上。就像個會過日子的主婦,不是看到超市打折就買,而是貨比三家后才決定在哪里花錢最值。
- 時間:11.25
- 項目:https://github.com/microsoft/graphrag
- 參考:https://mp.weixin.qq.com/s/kDUcg5CzRcL7lTGllv-GKA
一種新型的圖譜增強生成增強檢索(RAG)方法。這種方法顯著降低了索引和查詢成本,同時在回答質(zhì)量上保持或超越競爭對手,使其在多種用例中具有高度的可擴展性和高效性。LazyGraphRAG推遲了對LLM的使用。在索引階段,LazyGraphRAG僅使用輕量級的NLP技術(shù)來處理文本,將LLM的調(diào)用延遲到實際查詢時。這種“懶惰”的策略避免了前期高昂的索引成本,實現(xiàn)了高效的資源利用。
| 傳統(tǒng)GraphRAG | LazyGraphRAG | |
|---|---|---|
| 索引階段 | - 使用LLM提取并描述實體和關(guān)系 - 為每個實體和關(guān)系生成摘要 - 利用LLM總結(jié)社區(qū)內(nèi)容 - 生成嵌入向量 - 生成Parquet文件 |
- 使用NLP技術(shù)提取概念和共現(xiàn)關(guān)系 - 構(gòu)建概念圖 - 提取社區(qū)結(jié)構(gòu) - 索引階段不使用LLM |
| 查詢階段 | - 直接使用社區(qū)摘要回答查詢 - 缺乏對查詢的細化和對相關(guān)信息的聚焦 |
- 使用LLM細化查詢并生成子查詢 - 根據(jù)相關(guān)性選擇文本片段和社區(qū) - 使用LLM提取和生成答案 - 更加聚集于相關(guān)內(nèi)容,回答更精確 |
| LLM調(diào)用 | - 在索引階段和查詢階段都大量使用 | - 在索引階段不使用LLM - 僅在查詢階段調(diào)用LLM - LLM的使用更加高效 |
| 成本效率 | - 索引成本高,耗時長 - 查詢性能受限于索引質(zhì)量 |
- 索引成本僅為傳統(tǒng)GraphRAG的0.1% - 查詢效率高,答案質(zhì)量好 |
| 數(shù)據(jù)存儲 | - 索引數(shù)據(jù)生成 Parquet 文件,適合大規(guī)模數(shù)據(jù)的存儲和處理 | - 索引數(shù)據(jù)存儲為輕量級格式(如 JSON、CSV),更適合快速開發(fā)和小規(guī)模數(shù)據(jù) |
| 使用場景 | - 適用于對計算資源和時間不敏感的場景 - 需要提前構(gòu)建完整的知識圖譜,并存儲為Parquet文件,方便后續(xù)導(dǎo)入數(shù)據(jù)庫進行復(fù)雜分析 |
- 適用于需要快速索引和響應(yīng)的場景 - 適合一次性查詢、探索性分析和流式數(shù)據(jù)處理 |
RAG Survey
- A Survey on Retrieval-Augmented Text Generation
- Retrieving Multimodal Information for Augmented Generation: A Survey
- Retrieval-Augmented Generation for Large Language Models: A Survey
- Retrieval-Augmented Generation for AI-Generated Content: A Survey
- A Survey on Retrieval-Augmented Text Generation for Large Language Models
- RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing
- A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models
- Evaluation of Retrieval-Augmented Generation: A Survey
- Retrieval-Augmented Generation for Natural Language Processing: A Survey
- Graph Retrieval-Augmented Generation: A Survey
- A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, Current Landscape and Future Directions
- Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely
RAG Benchmark
- Benchmarking Large Language Models in Retrieval-Augmented Generation
- RECALL: A Benchmark for LLMs Robustness against External Counterfactual Knowledge
- ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
- RAGAS: Automated Evaluation of Retrieval Augmented Generation
- CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
- FeB4RAG: Evaluating Federated Search in the Context of Retrieval Augmented Generation
- CodeRAG-Bench: Can Retrieval Augment Code Generation?
- Long2RAG: Evaluating Long-Context & Long-Form Retrieval-Augmented Generation with Key Point Recall
若本文對你有所幫助,您的 關(guān)注 和 推薦 是我分享知識的動力!

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號