【Pig源碼分析】談談Pig的數據模型
1. 數據模型
Schema
Pig Latin表達式操作的是relation,FILTER、FOREACH、GROUP、SPLIT等關系操作符所操作的relation就是bag,bag為tuple的集合,tuple為有序的field列表集合,而field表示數據塊(A field is a piece of data),可理解為數據字段。
Schema為數據所遵從的類型格式,包括:field的名稱及類型(names and types)。用戶常用as語句來自定義schema,或是load函數導入schema,比如:
A = foreach X generate .. as field1:chararray, .. as field2:bag{};
A = load '..' using PigStorage('\t', '-schema');
A = load '..' using org.apache.pig.piggybank.storage.avro.AvroStorage();
若不指定field的類型,則其默認為bytearray。對未知schema進行操作時,有:
- 若join/cogroup/cross多關系操作遇到未知schema,則會將其視為null schema,導致返回結果的schema也為null;
- 若flatten一個empty inner schema的bag(即:bag{})時,則返回結果的schema為null;
- 若union時二者relation的schema不一致,則返回結果的schema為null;
- 若field的schema為null,會將該字段視為bytearray。
為了保證pig腳本運行的有效性,在寫UDF時要在outputSchema方法中指定返回結果的schema。
數據類型
Pig的基本數據類型與對應的Java類:
| Simple Pig Type | Example | Java Class |
|---|---|---|
| bytearray | DataByteArray | |
| chararray | 'hello world' | String |
| int | 10 | Integer |
| long | 10L | Long |
| float | 10.5F or 1050.0F | Float |
| double | Double | |
| boolean | true/false | Boolean |
| datetime | DateTime | |
| bigdecimal | BigDecimal | |
| biginteger | BigInteger |
復雜數據類型及其對應的Java類:
| Complex Pig Type | Example | Java Class |
|---|---|---|
| tuple | (19, 'hello') | Tuple |
| bag | DataBag | |
| map | [open#apache] | Map |
Pig的復雜數據類型可以嵌套表達,比如:tuple中有tuple (a, (b, c, d)),tuple中有bag (a, {(b,c), (d,e)})等等。但是一定要遵從數據類型本身的定義,比如:bag中只能是tuple的集合,比如{a, {(b),(c)}}就是不合法的。
Pig還有一種特殊的數據類型:null,與Java、C中null不一樣,其表示不知道的或不存在的數據類型(unknown or non-existent)。比如,在load數據時,如果有的數據行字段不符合定義的schema,則該字段會被置為null。
2. 源碼分析
以下源碼分析采用的是0.12版本。
Tuple
在KEYSET源碼中,創建Tuple對象采用工廠+單例設計模式:
private static final TupleFactory TUPLE_FACTORY = TupleFactory.getInstance();
Tuple t = TUPLE_FACTORY.newTuple(s);
事實上,TupleFactory是個抽象類,實現接口TupleMaker<Tuple>。在方法TupleFactory.getInstance()中,默認情況下返回的是BinSedesTupleFactory對象,同時支持加載用戶重寫的TupleFactory類(pig.data.tuple.factory.name指定類名、 pig.data.tuple.factory.jar指定類所在的jar)。BinSedesTupleFactory繼承于TupleFactory:

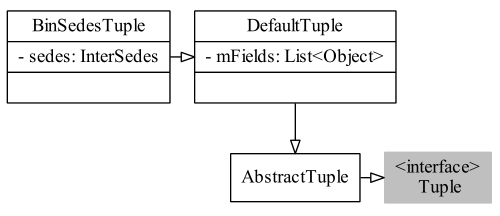
在BinSedesTupleFactory的newTuple方法中,返回的是BinSedesTuple對象。BinSedesTuple類繼承于DefaultTuple類,在DefaultTuple類中有List<Object> mFields字段,這便是存儲Tuple數據的地方了,mFields所持有類型為ArrayList<Object>();。類圖關系:
Bag
創建Bag對象有下面幾種方法:
// factory
BagFactory mBagFactory = BagFactory.getInstance();
DataBag output = mBagFactory.newDefaultBag();
// if you know upfront how many tuples you are going to put in this bag.
DataBag bag = new NonSpillableDataBag(m.size());
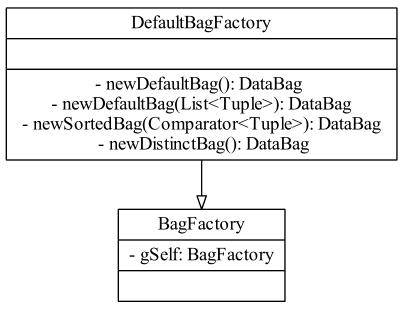
與TupleFactory一樣,BagFactory也是抽象類,也支持用戶自定義重寫;getInstance方法默認返回的是DefaultBagFactory。DefaultBagFactory有newDefaultBag、newSortedBag、newDistinctBag方法分別創建三類bag:
- default bag中的tuple沒有排序,也沒有去重;
- sorted bag中的tuple是按序存放,順序是由tuple default comparator或bag創建時的comparator所定義的;
- distinct bag顧名思義,tuple有去重。
三類bag的構造器如下:
public DefaultDataBag() {
mContents = new ArrayList<Tuple>();
}
public SortedDataBag(Comparator<Tuple> comp) {
mComp = (comp == null) ? new DefaultComparator() : comp;
mContents = new ArrayList<Tuple>();
}
public DistinctDataBag() {
mContents = new HashSet<Tuple>();
}
BagFactory的類圖:
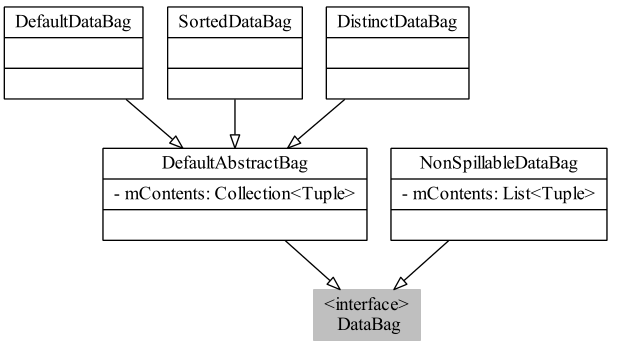
DefaultAbstractBag作為三種類型bag的基類,有一個字段mContents用于存放tuple,NonSpillableDataBag直接實現DataBag接口。DataBag的類圖:
3. 實戰
現有avro日志數據(見前一篇),其字段:
dvc表示用戶手機標識;appUse與appInstall同為avro Map類型,其key為app名稱(app name),value為Map<String, Object>,包含了一個表示使用時間的字段timelist(類型為ArrayList);具體格式如下
'dvc': 'imei_123',
'appUse': {
'app name1': {
...
'timelist': [...]
},
'app name2': {
...
'timelist': [...]
},
...
},
'appInstall': {
'app name1': {
...
'timelist': [...]
},
...
}
現在,想要得到每個用戶的app列表及app的打開次數,以格式dvc, {(app)}, {(app, frequency)}輸出,即用戶 + app列表 + 使用次數類表。如果用MapRduce做,得分為以下步驟:
- 以(dvc, app)為key值,計算value值為使用次數;
- 以dvc為key值,合并同一用戶的不同app,value值為(app, fre);
- 以dvc為key值,計算appinstall的app列表;
- 將步驟2得到的數據與步驟3得到的數據做join,然后輸出。
可以看出用MapReduce略顯繁復,如何來用pig來實現呢?我們可以對appUse:map[]編寫EVAL UDF,讓其返回(app名稱, timelist的長度) :
public class AppTimelist extends EvalFunc<DataBag>{
private static final TupleFactory TUPLE_FACTORY = TupleFactory.getInstance();
private static final BagFactory BAG_FACTORY = BagFactory.getInstance();
@SuppressWarnings({ "unchecked" })
@Override
public DataBag exec(Tuple input) throws IOException {
Map<String, Map<String, Object>> m = (Map<String, Map<String, Object>>) input.get(0);
List<Object> result = new ArrayList<Object>();
DataBag output = BAG_FACTORY.newDefaultBag();
if(m == null)
return null;
for(Map.Entry<String, Map<String, Object>> e: m.entrySet()) {
result.clear();
String app = e.getKey();
long size = ((DataBag) e.getValue().get("timelist")).size();
result.add(app);
result.add(size);
output.add(TUPLE_FACTORY.newTuple(result));
}
return output;
}
}
pig將Java的ArrayList轉成DataBag的類型,所以要對timelist進行強轉操作。
對appInstall:map[]編寫EVAL UDF,返回(appList):
public class DistinctBag extends EvalFunc<DataBag> {
BagFactory mBagFactory = BagFactory.getInstance();
@Override
public DataBag exec(Tuple input) throws IOException {
if(input == null || input.size() == 0) {
return null;
}
DataBag in = (DataBag) input.get(0);
DataBag out = mBagFactory.newDistinctBag();
if(in == null) {
return null;
}
for(Tuple tp: in) {
DataBag applist = (DataBag) tp.get(0);
for(Tuple app: applist)
out.add(app);
}
return out;
}
}
上面提到過,若沒有給EVAL UDF指定返回值的schema,則返回結果的schema為null,如此會造成類型的丟失,在后面的操作中容易報NullPointerException。
// AppTimelist.java
@Override
public Schema outputSchema(Schema input) {
try {
Schema tupleSchema = new Schema();
FieldSchema chararrayFieldSchema = new Schema.FieldSchema(null, DataType.CHARARRAY);
FieldSchema longFieldSchema = new Schema.FieldSchema(null, DataType.LONG);
tupleSchema.add(chararrayFieldSchema);
tupleSchema.add(longFieldSchema);
return new Schema(new Schema.FieldSchema(getSchemaName(this
.getClass().getName().toLowerCase(), input), tupleSchema,
DataType.TUPLE));
} catch (Exception e) {
return null;
}
}
// DistinctBag.java
@Override
public Schema outputSchema(Schema input) {
FieldSchema innerFieldSchema = new Schema.FieldSchema(null, DataType.CHARARRAY);
Schema innerSchema = new Schema(innerFieldSchema);
Schema bagSchema = null;
try {
bagSchema = new Schema(new FieldSchema(null, innerSchema, DataType.BAG));
} catch(FrontendException e) {
throw new RuntimeException(e);
}
return bagSchema;
}
統計app列表:
define AvroStorage org.apache.pig.piggybank.storage.avro.AvroStorage;
define DistinctBag com.pig.udf.bag.DistinctBag;
A = load '..' using AvroStorage();
B = foreach A generate value.fields.data#'dvc' as dvc:chararray, value.fields.data#'appInstall' as ins:map[map[]];
C = foreach B generate dvc, KEYSET(ins) as applist;
D = group C by dvc;
-- extract applist from grouped D
E = foreach D {
projected = foreach $1 generate applist;
generate group as dvc, projected as grouped;
}
F = foreach E generate dvc, DistinctBag(grouped) as applist;
store F into '..' using AvroStorage();
統計app使用時長:
define AvroStorage org.apache.pig.piggybank.storage.avro.AvroStorage;
define AppTimelist com.pig.udf.map.AppTimelist;
A = load '..' using AvroStorage();
B = foreach A generate value.fields.data#'dvc' as dvc:chararray, value.fields.data#'appUse' as use:map[map[]];
C = foreach B generate dvc, flatten(AppTimelist(use)) as (app, fre);
D = group C by (dvc, app);
E = foreach D generate flatten(group) as (dvc, app), SUM($1.fre) as fre;
F = group E by dvc;
G = foreach F {
projected = foreach $1 generate app, fre;
generate group as dvc, projected as appfre;
}
store G into '..' using AvroStorage();
二者做join即可得到結果。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號