
1、基本概念
多進程庫提供了Pool類來實現簡單的多進程任務。Pool類有以下方法:
- apply():直到得到結果之前一直阻塞。
- apply_async():這是apply()方法的一個變體,返回的是一個result對象。這是一個異步的操作,在所有的子類執行之前不會鎖住主進程。
- map():這是內置的map函數的并行版本,在得到結果之前一直阻塞,此方法將可迭代的數據的每一個元素作為進程池的一個任務來執行。
- map_async():這是map的一個變體,返回一個result對象。如果指定了回調函數,回調函數應該是callable的,并且只接受一個參數。當result準備好時,會自動調用回調函數,除非調用失敗。回調函數應該立即完成,否則,持有result的進程將被阻塞。
2、測試用例
創建四個進程池,然后使用map方法進行一個簡單的計算。
import multiprocessing def function_square(data): result = data * data return result if __name__ == "__main__": inputs = list(range(100)) pool = multiprocessing.Pool(processes=4) pool_outputs = pool.map(function_square, inputs) pool.close() pool.join() print("pool: ", pool_outputs)
pool.map方法將一些獨立的任務提交給進程池。pool.map和內置map的執行結果相同,但pool.map是通過多個并行進程計算的。
3、mpi4py模塊
Python提供了很多MPI模塊寫并行程序。其中mpi4py在MPI-1/2頂層構建,提供了面向對象的接口,緊跟C++綁定的MPI-2。MPI是C語言用戶可以無需學習新的接口就可以使用這個庫。
此模塊包含的主要的應用:
- 點對點通訊
- 集體通訊
- 拓撲
4、安裝mpi4py
安裝mpich:https://www.microsoft.com/en-us/download/confirmation.aspx?id=56727
下載并安裝msmpisetup.exe
安裝完成后安裝目錄如下:
將bin目錄添加到系統環境中:
用cmd輸入并顯示如下即為安裝成功
安裝mpi4py
pip install mpi4py
MPI測試用例
from mpi4py import MPI def mpi_test(rank): print("I am rank %s" %rank) if __name__ == "__main__": comm = MPI.COMM_WORLD rank = comm.Get_rank() mpi_test(rank) print("Hello world from process", rank)
使用mpi運行文件

在MPI中,并行程序中不同進程用一個非負整數來區別,如果我們有P個進程,那么rank會從0到P-1分配。
MPI拿到rank的函數如下:rank = comm.Get_rank()
這個函數返回調用它的進程的rank,comm叫做交流者,用于區別不同的進程集合:comm = MPI.COMM_WORLD
5、MPI點對點通訊
MPI提供的最實用的一個特性是點對點通訊。兩個不同的進程之間可以通過點對點通訊交換數據:一個進程是接收者,一個進程是發送者。
Python的mpi4py通過下面兩個函數提供了點對點通訊功能:
- Comm.Send(data, process_destination):通過它在交流組中的排名來區分發送給不同進程的數據。
- Comm.Recv(process_source):接收來自源進程的數據,也是通過在交流組中的排名來分分的。
Comm變量表示交流著,定義了可以互相通訊的進程組:
comm = MKPI.COMM_WORLD
交換信息測試用例:
from mpi4py import MPI comm = MPI.COMM_WORLD rank = comm.rank print("My rank is :",rank) if rank == 0: data = 10000000 destination_process = 4 comm.send(data, dest=destination_process) print("sending data %s to process %d" %(data, destination_process)) if rank == 1: destination_process = 8 data = "hello,I am rank 1" comm.send(data, dest=destination_process) print("sending data %s to process %d" %(data, destination_process)) if rank == 4: data = comm.recv(source=0) print("data received is = %s" %data) if rank == 8: data1 = comm.recv(source=1) print("data received is = %s" %data1)
運行結果:
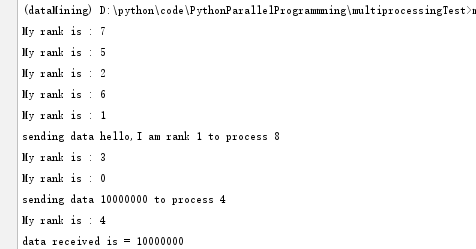
通過mpiexec -n 9運行9個互相通訊的進程,使用rank的值來區分每個進程。
整個過程分為兩部分,發送者發送數據,接收者接收數據,二者必須都指定發送方/接收方,source=為指定發送者。如果有發送的數據沒有被接收,程序會阻塞。
comm.send()和comm.recv()函數都是阻塞的函數,他們會一直阻塞調用者,直到數據使用完成,同時在MPI中,有兩種方式發送和接收數據:
- buffer模式
- 同步模式
在buffer模式中,只要需要發送的數據被拷貝到buffer中,執行權就會交回到主程序,此時數據并非已經發送/接收完成。在同步模式中,只有函數真正的結束發送/接收任務之后才會返回。
6、避免死鎖
mpi4py沒有提供特定的功能來解決這種情況,但是提供了一些程序員必須遵守的規則來避免死鎖的問題。
出現死鎖的情況:
from mpi4py import MPI comm = MPI.COMM_WORLD rank = comm.rank print("my rank is :",rank) if rank == 1: data_send = "a" destination_process = 5 source_process = 5 data_received = comm.recv(source=source_process) comm.send(data_send, dest=destination_process) print("sending data %s to process %d" %(data_send, destination_process)) print("data received is = %s" %data_received) if rank == 5: data_send = "b" destination_process = 1 source_process = 1 data_received = comm.recv(source=source_process) comm.send(data_send, dest=destination_process) print("sending data %s to process %d" % (data_send, destination_process)) print("data received is = %s" % data_received)
運行結果:

進程1和進程5產生阻塞,程序阻塞。
此時兩個進程都在等待對方,發生阻塞,因為recv和send都是阻塞的,兩個函數都先使用的recv,所以調用者都在等待他們完成。所以講上述代碼改為如下即可解決阻塞:
from mpi4py import MPI comm = MPI.COMM_WORLD rank = comm.rank print("my rank is :",rank) if rank == 1: data_send = "a" destination_process = 5 source_process = 5 comm.send(data_send, dest=destination_process) data_received = comm.recv(source=source_process) print("sending data %s to process %d" %(data_send, destination_process)) print("data received is = %s" %data_received) if rank == 5: data_send = "b" destination_process = 1 source_process = 1 data_received = comm.recv(source=source_process) comm.send(data_send, dest=destination_process) print("sending data %s to process %d" % (data_send, destination_process)) print("data received is = %s" % data_received)
將其中一個函數的recv和send順序調換。
運行結果:

也可通過Sendrecv函數解決,代碼如下:
from mpi4py import MPI comm = MPI.COMM_WORLD rank = comm.rank print("my rank is :",rank) if rank == 1: data_send = "a" destination_process = 5 source_process = 5 # comm.send(data_send, dest=destination_process) # data_received = comm.recv(source=source_process) data_received = comm.sendrecv(data_send, dest=destination_process, source=source_process) print("sending data %s to process %d" %(data_send, destination_process)) print("data received is = %s" %data_received) if rank == 5: data_send = "b" destination_process = 1 source_process = 1 # data_received = comm.recv(source=source_process) # comm.send(data_send, dest=destination_process) data_received = comm.sendrecv(data_send, dest=destination_process, source=source_process) print("sending data %s to process %d" % (data_send, destination_process)) print("data received is = %s" % data_received)
運行結果:
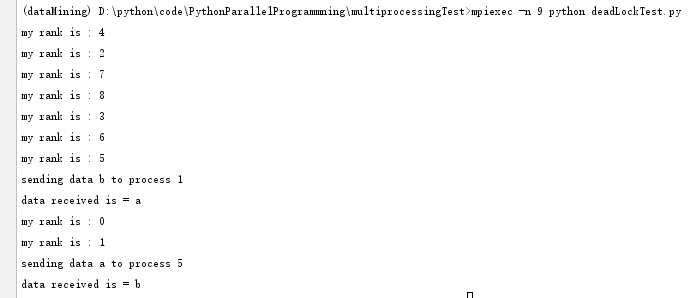
7、集體通訊:Broadcast
在并行代碼的開發中,會經常需要在多個進程間共享某個變量運行時的值,或操作多個進程提供的變量。MPI庫提供了在多個進程之間交換信息的方法,將所有進程變成通訊者的這種方法叫做集體交流。因此,一個集體交流通常是2個以上的進程,也可以稱為廣播——一個進程將消息發送給其他進程。mpi4py模塊通過以下方式提供廣播的功能:
buf = comm.bcast(data_to_share, rank_of_root_process)
這個函數將root消息中包含的信息發送給屬于comm通訊組其他的進程,每個進程必須通過相同的root和comm來調用它。
測試代碼:
from mpi4py import MPI comm = MPI.COMM_WORLD rank = comm.Get_rank() if rank == 0: variable_to_share = 100 else: variable_to_share = None variable_to_share = comm.bcast(variable_to_share, root=0) print("process = %d variable shared = %d" %(rank, variable_to_share))
運行結果:

rank等于0的root進程初始化了一個變量,variable_to_share,值為100,然后聲明了一個廣播variable_to_share = comm.bcast(variable_to_share, root=0)
這個變量將通過通訊組發送給其他進程。
集體通訊允許組中的多個進程同時進行數據交流。在mpi4py模塊中,只提供了阻塞版本的集體通訊(阻塞調用者,直到緩存中的數據全部安全發送。)
廣泛應用的集體通訊應該是:
- 組中的進程提供通訊的屏障
- 通訊方式包括:
- 將一個進程的數據廣播到組中其他進程中
- 從其他進程收集數據發給一個進程
- 從一個進程散播數據到其他進程中
- 減少操作
8、集體通訊:Scatter
scatter函數和廣播很像,但是不同的是comm.bcast將相同的數據發送給所有在監聽的進程,comm.scatter可以將數據放在數據中,發送給不同的進程。
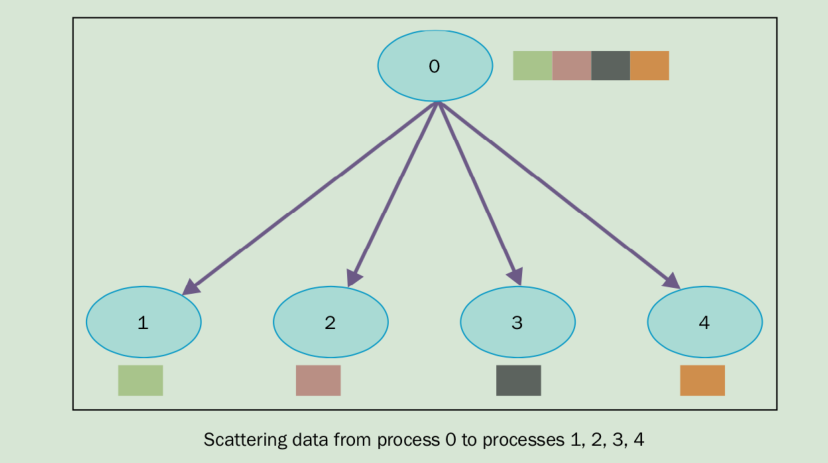
comm.scatter函數接收一個array,根據進程的rank將其中的元素發給不同的進程,第一個元素發送給進程0,第二個元素發給進程1,以此類推。
測試用例:
from mpi4py import MPI comm = MPI.COMM_WORLD rank = comm.Get_rank() # array_to_share = ["a","b","c","d","e","f","g","h","i","j"] if rank == 0: array_to_share = [0,1,2,3,4,5,6,7,8,9] else: array_to_share = None recvbuf = comm.scatter(array_to_share, root=0) print("Process = %d recvbuf = %s" %(rank, recvbuf))
執行結果:

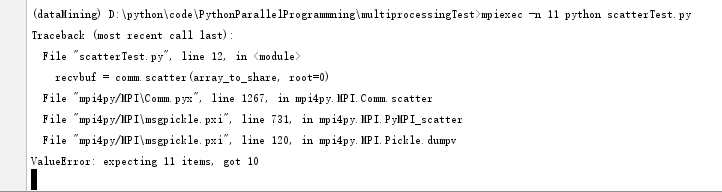
注意:列表中的元素個數,需要個進程保持一致。否則會出現如下錯誤。
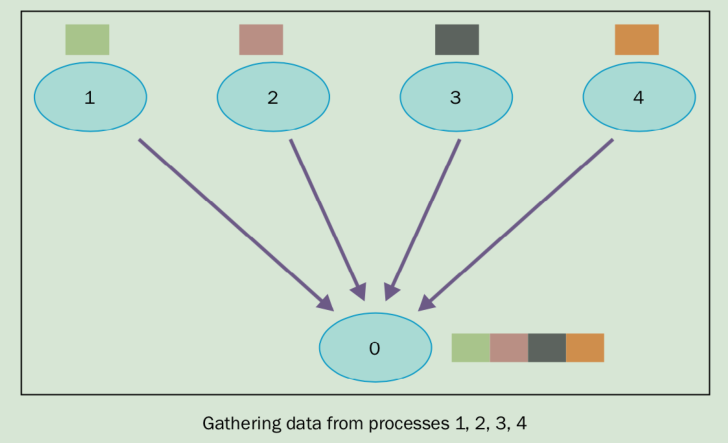
9、集體通訊:gather
gather函數基本上是反向的scatter,即收集所有進程發送到root進程數據。方法如下:
recvbuf = comm.gather(sendbuf, rank_of_root_process)
sendbuf是要發送的數據,rank_of_root_process代表要接收數據的進程。
測試用例:
from mpi4py import MPI comm = MPI.COMM_WORLD size = comm.Get_size() # print(size) rank = comm.Get_rank() data = "process %s" %rank # print("start %s"%data) data = comm.gather(data, root=0) # print(data) if rank == 0: print("rank = %s receiving data to other process" %rank) for i in range(1, size): #data[i] = (i+1) ** 2 value = data[i] print("process %s receiving %s from process %s" %(rank, value, i)) # print(data)
執行結果:

10、使用Alltoall通訊
Alltoall集體通訊結合了scatter和gather的功能。在mpi4py中,有以下三類的Alltoall集體通訊。
- comm.Alltoall(sendbuf, recvbuf);
- comm.Alltoallv(sendbuf, recvbuf);
- comm.Alltoallw(sendbuf, recvbuf);
Alltoall測試用例:
from mpi4py import MPI import numpy comm = MPI.COMM_WORLD size = comm.Get_size() rank = comm.Get_rank() a_size = 1 # print("numpy arange: %s" %numpy.arange(size, dtype=int)) senddata = (rank+1)*numpy.arange(size, dtype=int) recvdata = numpy.empty(size * a_size, dtype=int) print("senddata is %s , recvdata is %s" %(senddata, recvdata)) # print("Recvdata is %s: , \n numpy.empty is %s" %(recvdata, numpy.empty(size * a_size, dtype=int))) comm.Alltoall(senddata, recvdata) print("process %s sending %s, receiving %s" %(rank, senddata, recvdata))
運行結果:

comm.alltoall方法將task j的sendbuf的第j個對象拷貝到task i中,recvbuf的第j個對象,一一對應。發送過程如圖:
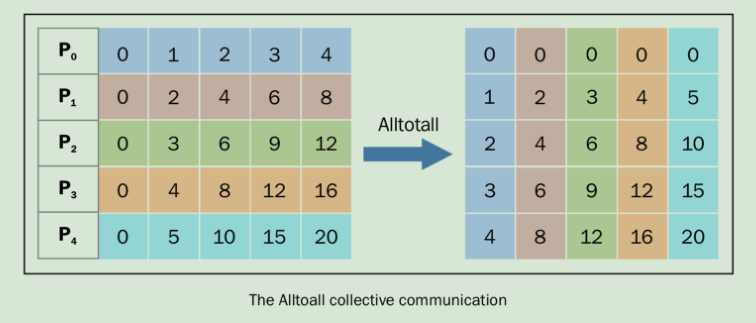
可以將左右兩個方格看做xy軸,結果一一對應,如左圖的(0,0)對應的值為0,其對應的有圖的值為右圖的(0,0)也為0。左圖的3,4對應的值為16,右圖(4,3)也為16。
P0包含的數據[0 1 2 3 4],它將值0賦值給自己,1傳給進程P1,2傳給進程P2,3傳給進程P3,以此類推。
相同的P1的數據為[0 2 4 6 8] , 它將0傳給P0,2傳給P1,4傳給P2,以此類推。
All-to-all定制通訊也叫全部交換,這種操作經常用于各種并發算法中,比如快速傅里葉變換,矩陣變換,樣本排序以及一些數據庫的 Join 操作。
11、簡化操作
同comm.gather一樣,comm.reduce接收一個數組,每一個元素是一個進程的輸入,然后返回一個數組,每一個元素是進程的輸出,返回給root進程。輸出的元素包含了簡化的結果。
簡化定義如下:comm.Reduce(sendbuf, recvbuf, rank_of_root_process, op = type_of_reduction_operation)
這里需要注意的是,參數op和comm.gather不同,它代表你想應用在數據上的操作,mpi4py模塊代表定義了一系列的簡化操作,包括:
- MPI.MAX:返回最大的元素
- MPI.MIN:返回最小的元素
- MPI.SUM:對所有的元素相加
- MPI.PROD:對所有元素相乘
- MPI.LAND:對所有元素進行邏輯操作
- MPI.MAXLOC:返回最大值,以及擁有它的進程
- MPI.MINLOC:返回最小值,以及擁有它的進程
測試用例:
import numpy as np from mpi4py import MPI comm = MPI.COMM_WORLD size = comm.size rank = comm.rank array_size = 3 recvdata = np.zeros(array_size, dtype=np.int) senddata = (rank+1)*np.arange(size, dtype=np.int) print("+++++++++++++%s+++++++++++++%s++++++++++++" %(recvdata, senddata)) print("Process %s sending %s" %(rank, senddata)) comm.Reduce(senddata, recvdata, root=0, op=MPI.SUM) print("on task %s, after Reduce: data = %s" %(rank, recvdata))
執行結果:
MPI.SUM為求和操作,過程如下:
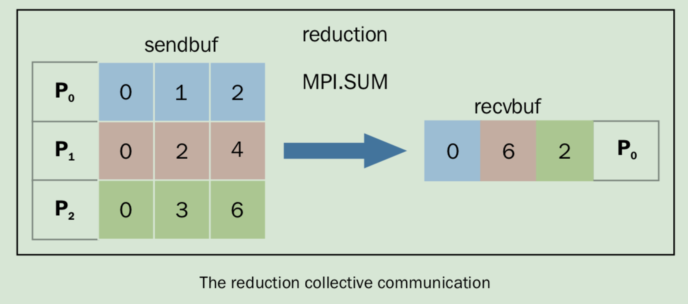
簡化操作將每個task的第i個元素相加,然后放回到P0進程(root進程)的第i個元素中。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號