
分布式文件系統(tǒng)應(yīng)用(上篇 理論)
2011-07-10 13:17 熬夜的蟲子 閱讀(738) 評論(0) 收藏 舉報自從6月份出山以來 就一直琢磨著搞一套通用的服務(wù)化平臺。在設(shè)計用戶行為分析以及用戶推廣的時候,發(fā)現(xiàn)自己的構(gòu)架里對海量文件的存儲沒有一個合理的方案。起初打算用windows2003中dfs系統(tǒng)開發(fā)一套新的文件系統(tǒng),后來發(fā)現(xiàn)win下的dfs是個大坑,未遂。然后考慮到win平臺與linux系統(tǒng)之間關(guān)于文件處理的優(yōu)劣與穩(wěn)定性,最終選擇linux下fastdfs。
下面先簡單介紹下分布式文件系統(tǒng)然后結(jié)合我的實際case給大家圖文演示,在這之前先感謝下fishman、咕咚、以及菲雪同學的大力支持。你們是最棒的!!
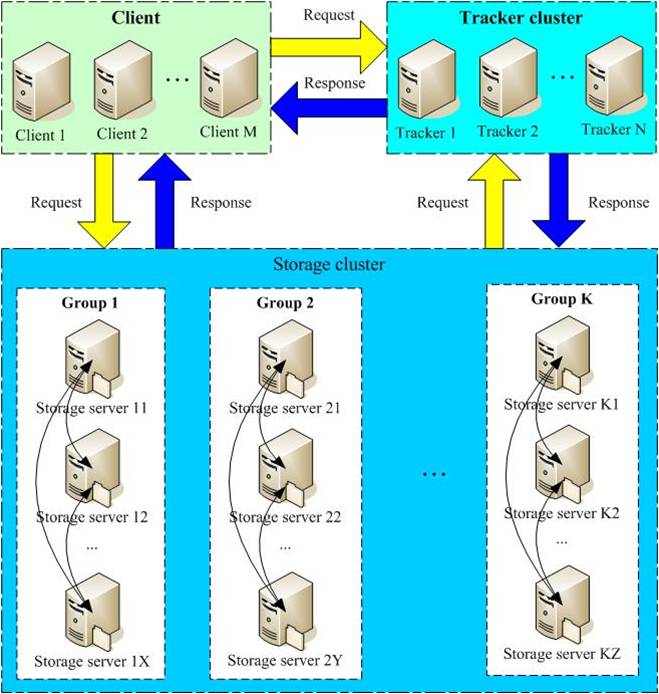
Tracker Server:跟蹤服務(wù)器,主要做調(diào)度工作,在訪問上起負載均衡的作用。在內(nèi)存中記錄集群中g(shù)roup和storage server的狀態(tài)信息,是連接Client和Storage server的樞紐。
Storage Server:存儲服務(wù)器,文件和文件屬性(meta data)都保存到存儲服務(wù)器上
架構(gòu)解讀:
只有兩個角色,tracker server和storage server,不需要存儲文件索引信息
所有服務(wù)器都是對等的,不存在Master-Slave關(guān)系
存儲服務(wù)器采用分組方式,同組內(nèi)存儲服務(wù)器上的文件完全相同(RAID 1)
不同組的storage server之間不會相互通信
由storage server主動向tracker server報告狀態(tài)信息,tracker server之間通常不會相互通信
上傳文件流程圖:
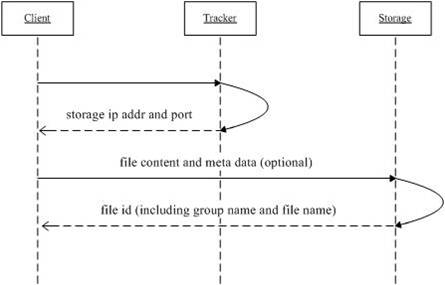
1.client詢問tracker上傳到的storage;
2.tracker返回一臺可用的storage;
3.client直接和storage通信完成文件上傳,storage返回文件ID
下載文件流程圖:

1. client詢問tracker可以下載指定文件的storage,參數(shù)為文件ID(組名和文件名);
2. tracker返回一臺可用的storage;
3. client直接和storage通信完成文件下載。
同步機制:
采用binlog文件記錄文件上傳、刪除等操作,根據(jù)binlog進行文件同步
binlog中只記錄文件名,不記錄文件內(nèi)容
記錄已同步的位置到.mark文件中
同組內(nèi)的storage server之間是對等的,文件上傳、刪除等操作可以在任意一臺storage server上進行
文件同步只在同組內(nèi)的storage server之間進行,采用push方式,即源頭服務(wù)器同步給目標服務(wù)器
同步延遲問題:
storage生成的文件名中,包含源頭storage IP地址和文件創(chuàng)建時間戳
源頭storage定時向tracker報告同步情況,包括向目標服務(wù)器同步到的文件時間戳
tracker收到storage的同步報告后,找出該組內(nèi)每臺storage被同步到的時間戳(取最小值),作為storage屬性保存到內(nèi)存中
通信協(xié)議:
二進制通信協(xié)議
協(xié)議包由兩部分組成:header和body
header共10字節(jié),格式如下:
8 bytes body length
1 byte command
1 byte status
body數(shù)據(jù)包格式由取決于具體的命令, body可以為空
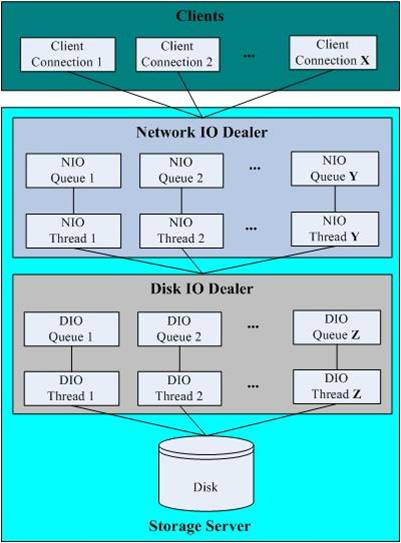
IO模型:
 |
原創(chuàng)作品允許轉(zhuǎn)載,轉(zhuǎn)載時請務(wù)必以超鏈接形式標明文章原始出處以及作者信息。 作者:熬夜的蟲子 點擊查看:博文索引 |

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號