

基于AST實現國際化文本提取
我們是袋鼠云數棧 UED 團隊,致力于打造優秀的一站式數據中臺產品。我們始終保持工匠精神,探索前端道路,為社區積累并傳播經驗價值。
本文作者:霜序
前言
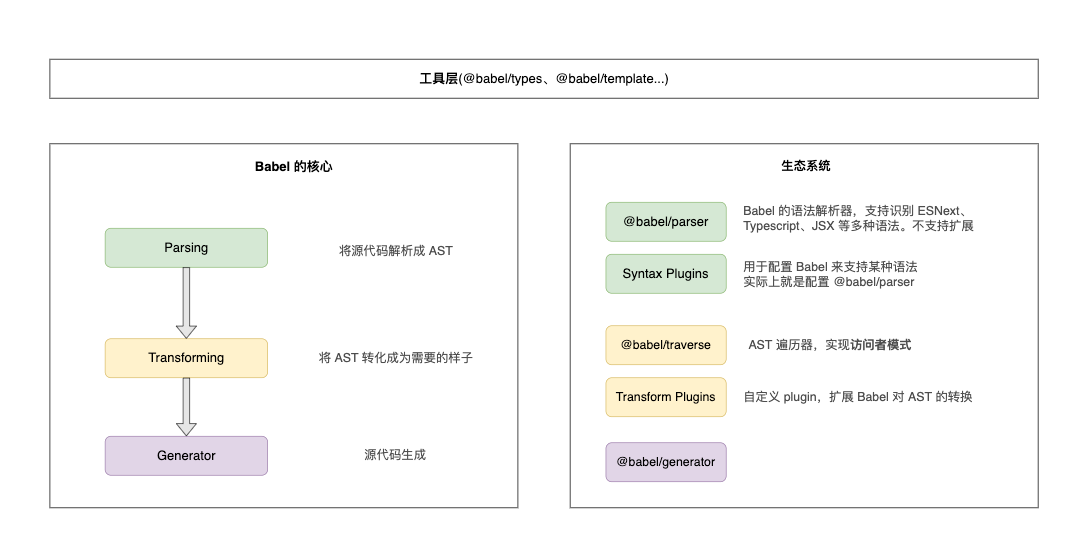
在閱讀本文之前,需要讀者有一些 babel 的基礎知識,babel 的架構圖如下:
確定中文范圍
先需要明確項目中可能存在中文的情況有哪些?
const a = '霜序';
const b = `霜序`;
const c = `${isBoolean} ? "霜序" : "FBB"`;
const obj = { a: '霜序' };
// enum Status {
// Todo = "未完成",
// Complete = "完成"
// }
// enum Status {
// "未完成",
// "完成"
// }
const dom = <div>霜序</div>;
const dom1 = <Customer name="霜序" />;
雖然有很多情況下會出現中文,在代碼中存在的時候大部分是string或者模版字符串,在react中的時候一個是dom的子節點還是一種是props上的屬性包含中文。
// const a = '霜序';
{
"type": "StringLiteral",
"start": 10,
"end": 14,
"extra": {
"rawValue": "霜序",
"raw": "'霜序'"
},
"value": "霜序"
}
StringLiteral
對應的AST節點為StringLiteral,需要去遍歷所有的StringLiteral節點,將當前的節點替換為我們需要的I18N.key這種節點。
// const b = `${finalRoles}(質量項目:${projects})`
{
"type": "TemplateLiteral",
"start": 10,
"end": 43,
"expressions": [
{
"type": "Identifier",
"start": 13,
"end": 23,
"name": "finalRoles"
},
{
"type": "Identifier",
"start": 32,
"end": 40,
"name": "projects"
}
],
"quasis": [
{
"type": "TemplateElement",
"start": 11,
"end": 11,
"value": {
"raw": "",
"cooked": ""
}
},
{
"type": "TemplateElement",
"start": 24,
"end": 30,
"value": {
"raw": "(質量項目:",
"cooked": "(質量項目:"
}
},
{
"type": "TemplateElement",
"start": 41,
"end": 42,
"value": {
"raw": ")",
"cooked": ")"
}
}
]
}
TemplateLiteral
相對于字符串情況會復雜一些,TemplateLiteral中會出現變量的情況,能夠看到在TemplateLiteral節點中存在expressions和quasis兩個字段分別表示變量和字符串
其實可以發現對于字符串來說全部都在TemplateElement節點上,那么是否可以直接遍歷所有的TemplateElement節點,和StringLiteral一樣。
直接遍歷TemplateElement的時候,處理之后的效果如下:
const b = `${finalRoles}(質量項目:${projects})`;
const b = `${finalRoles}${I18N.K}${projects})`;
// I18N.K = "(質量項目:"
那么這種只提取中文不管變量的情況,會導致翻譯不到的問題,上下文很缺失。
最后我們會處理成{val1}(質量項目:{val2})的情況,將對應val1和val2傳入
I18N.get(I18N.K, {
val1: finalRoles,
val2: projects,
});
JSXText
對應的AST節點為JSXText,去遍歷JSXElement節點,在遍歷對應的children中的JSXText處理中文文本
{
"type": "JSXElement",
"start": 12,
"end": 25,
"children": [
{
"type": "JSXText",
"start": 17,
"end": 19,
"extra": {
"rawValue": "霜序",
"raw": "霜序"
},
"value": "霜序"
}
]
}
JSXAttribute
對應的AST節點為JSXAttribute,中文存在的節點還是StringLiteral,但是在處理的時候還是特殊處理JSXAttribute中的StringLiteral,因為對于這種JSX中的數據來說我們需要包裹{},不是直接做文本替換的
{
"type": "JSXOpeningElement",
"start": 13,
"end": 35,
"name": {
"type": "JSXIdentifier",
"start": 14,
"end": 22,
"name": "Customer"
},
"attributes": [
{
"type": "JSXAttribute",
"start": 23,
"end": 32,
"name": {
"type": "JSXIdentifier",
"start": 23,
"end": 27,
"name": "name"
},
"value": {
"type": "StringLiteral",
"start": 28,
"end": 32,
"extra": {
"rawValue": "霜序",
"raw": "\"霜序\""
},
"value": "霜序"
}
}
],
"selfClosing": true
}
使用 Babel 處理
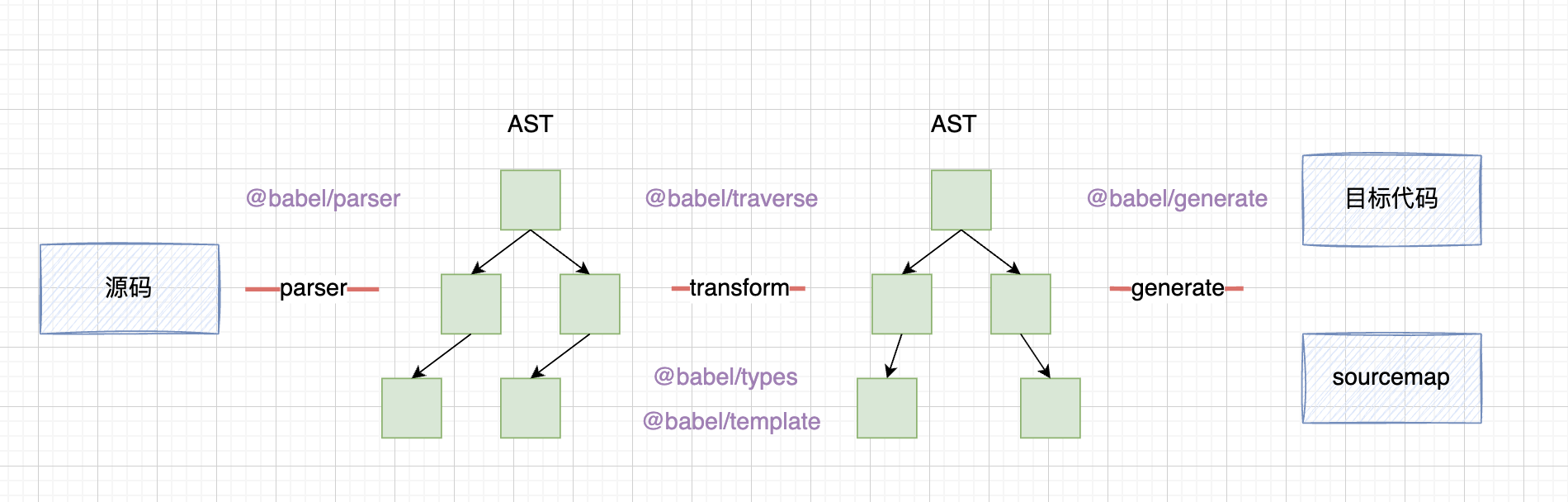
使用 @babel/parser 將源代碼轉譯為 AST
const plugins: ParserOptions['plugins'] = ['decorators-legacy', 'typescript'];
if (fileName.endsWith('text') || fileName.endsWith('text')) {
plugins.push('text');
}
const ast = parse(sourceCode, {
sourceType: 'module',
plugins,
});
@babel/traverse 特殊處理上述的節點,轉化 AST
babelTraverse(ast, {
StringLiteral(path) {
const { node } = path;
const { value } = node;
if (
!value.match(DOUBLE_BYTE_REGEX) ||
(path.parentPath.node.type === 'CallExpression' &&
path.parentPath.toString().includes('console'))
) {
return;
}
path.replaceWithMultiple(template.ast(`I18N.${key}`));
},
TemplateLiteral(path) {
const { node } = path;
const { start, end } = node;
if (!start || !end) return;
let templateContent = sourceCode.slice(start + 1, end - 1);
if (
!templateContent.match(DOUBLE_BYTE_REGEX) ||
(path.parentPath.node.type === 'CallExpression' &&
path.parentPath.toString().includes('console')) ||
path.parentPath.node.type === 'TaggedTemplateExpression'
) {
return;
}
if (!node.expressions.length) {
path.replaceWithMultiple(template.ast(`I18N.${key}`));
path.skip();
return;
}
const expressions = node.expressions.map((expression) => {
const { start, end } = expression;
if (!start || !end) return;
return sourceCode.slice(start, end);
});
const kvPair = expressions.map((expression, index) => {
templateContent = templateContent.replace(
`\${${expression}}`,
`{val${index + 1}}`,
);
return `val${index + 1}: ${expression}`;
});
path.replaceWithMultiple(
template.ast(`I18N.get(I18N.${key},{${kvPair.join(',\n')}})`),
);
},
JSXElement(path) {
const children = path.node.children;
const newChild = children.map((child) => {
if (babelTypes.isJSXText(child)) {
const { value } = child;
if (value.match(DOUBLE_BYTE_REGEX)) {
const newExpression = babelTypes.jsxExpressionContainer(
babelTypes.identifier(`I18N.${key}`),
);
return newExpression;
}
}
return child;
});
path.node.children = newChild;
},
JSXAttribute(path) {
const { node } = path;
if (
babelTypes.isStringLiteral(node.value) &&
node.value.value.match(DOUBLE_BYTE_REGEX)
) {
const expression = babelTypes.jsxExpressionContainer(
babelTypes.memberExpression(
babelTypes.identifier('I18N'),
babelTypes.identifier(`${key}`),
),
);
node.value = expression;
}
},
});
對于TemplateLiteral來說需要處理expression,通過截取的方式獲取到對應的模版字符串 templateContent,如果不存在expressions,直接類似StringLiteral處理;存在expressions的情況下,遍歷expressions通過${val(index)}替換掉templateContent中的expression,最后使用I18N.get的方式獲取對應的值
const name = `${a}霜序`;
// const name = I18N.get(I18N.test.A, { val1: a });
const name1 = `${a ? '霜' : '序'}霜序`;
// const name1 = I18N.get(I18N.test.B, { val1: a ? I18N.test.C : I18N.test.D });
對于TemplateLiteral節點來說,如果是嵌套的情況,會出現問題。
const name1 = `${a ? `霜` : `序`}霜序`;
// const name1 = I18N.get(I18N.test.B, { val1: a ? `霜` : `序` });
?? 為何對于
TemplateLiteral中嵌套的StringLiteral會處理,而TemplateLiteral就不處理呢?
?? 導致原因為babel不會自動遞歸處理TemplateLiteral的子級嵌套模板。
上述的代碼中通過遍歷一些AST處理完了之后,我們需要統一引入當前I18N這個變量。那么沒我們需要在當前文件的AST頂部的import語句后插入當前的importStatement
Program: {
exit(path) {
const importStatement = projectConfig.importStatement;
const result = importStatement
.replace(/^import\s+|\s+from\s+/g, ',')
.split(',')
.filter(Boolean);
// 判斷當前的文件中是否存在 importStatement 語句
const existingImport = path.node.body.find((node) => {
return (
babelTypes.isImportDeclaration(node) &&
node.source.value === result[1]
);
});
if (!existingImport) {
const importDeclaration = babelTypes.importDeclaration(
[
babelTypes.importDefaultSpecifier(
babelTypes.identifier(result[0]),
),
],
babelTypes.stringLiteral(result[1]),
);
path.node.body.unshift(importDeclaration);
}
},
}
轉為代碼
const { code } = generate(ast, {
retainLines: true,
comments: true,
});
因為我們的場景不適合將該功能封裝成plugin,但是整體和寫plugin的思路差不多。在.babelrc中配置對應的plugin即可
const i18nPlugin = () => {
return {
visitor: {
StringLiteral(path) {},
TemplateLiteral(path) {},
JSXElement(path) {},
JSXAttribute(path) {},
Program: {},
},
};
};
其他處理
動態生成 key
每一個中文生成key的方式都是固定的,類似excel列名
export const getSortKey = (n: number, extractMap = {}): string => {
let label = '';
let num = n;
while (num > 0) {
num--;
label = String.fromCharCode((num % 26) + 65) + label;
num = Math.floor(num / 26);
}
const key = `${label}`;
if (_.get(extractMap, key)) {
return getSortKey(n + 1, extractMap);
}
return key;
};
每一個文件的前綴都是一定的,按著路徑生成的,不會包含extractDir之前的內容
export const getFileKey = (filePath: string) => {
const extractDir = getProjectConfig().extractDir;
const basePath = path.resolve(process.cwd(), extractDir);
const relativePath = path.relative(basePath, filePath);
const names = slash(relativePath).split('/');
const fileName = _.last(names) as any;
let fileKey = fileName.split('.').slice(0, -1).join('.');
const dir = names.slice(0, -1).join('.');
if (dir) fileKey = names.slice(0, -1).concat(fileKey).join('.');
return fileKey.replace(/-/g, '_');
};
腳手架命令
目前支持命令如下:
- init: 用于初始化配置化文件
- extract: 根據配置文件提取 extractDir 的中文寫入到對應的文件
- extract:check: 檢查 extractDir 文件夾中的中文是否提取完全
- extract:clear: 清理 extractDir 尚未使用的國際化文案
npx i18n-extract-cli init
會初始化一份i18n.config.json
{
"localeDir": "locales",
"extractDir": "./",
"importStatement": "import I18N from @/utils/i18n",
"excludeFile": [],
"excludeDir": []
}
執行如下命令,開始提取extractDir目錄下的中文文本到localeDir/zh-CN
npx i18n-extract-cli extract
執行如下命令,檢查 extractDir 文件夾中的中文是否提取完全,需要注意 console 中的中文也會被檢查
npx i18n-extract-cli extract:check
執行如下命令,清理 extractDir 尚未使用的國際化文案
值得注意,是按著每個文件路徑作為key來判斷當前文件中的 sortKey 是否使用,因此必須保證每個文件中使用的 key 為fileKey + sortKey,否則會導致當前腳本失效
npx i18n-extract-cli extract:clear
最后
歡迎關注【袋鼠云數棧UED團隊】~
袋鼠云數棧 UED 團隊持續為廣大開發者分享技術成果,相繼參與開源了歡迎 star

 浙公網安備 33010602011771號
浙公網安備 33010602011771號