
實驗五 文件應用編程
實驗任務6
task6:
源代碼:
1 import csv 2 with open(r'C:\Users\LENOVO\Desktop\python\data6.csv','r',encoding = 'gbk') as f: 3 data = f.readlines() 4 5 data1 = [i.strip('\n') for i in data] 6 data2 = [eval(j) for j in data1[1:]] 7 print(f'{data1[0]}:\n{data2}') 8 9 data3 = [int(y+0.5) for y in data2] 10 title = [data1[0]] 11 title.append('四舍五入后數(shù)據(jù)') 12 file = [] 13 for z in range(len(data2)): 14 a = [] 15 a.append(str(data2[z])) 16 a.append(str(data3[z])) 17 file.append(a) 18 19 print(f'{title[1]}:\n{data3}') 20 21 with open(r'C:\Users\LENOVO\Desktop\python\data6.csv','w',encoding = 'gbk',newline='') as f: 22 content = csv.writer(f) 23 content.writerow(title) 24 content.writerows(file)
運行結果:

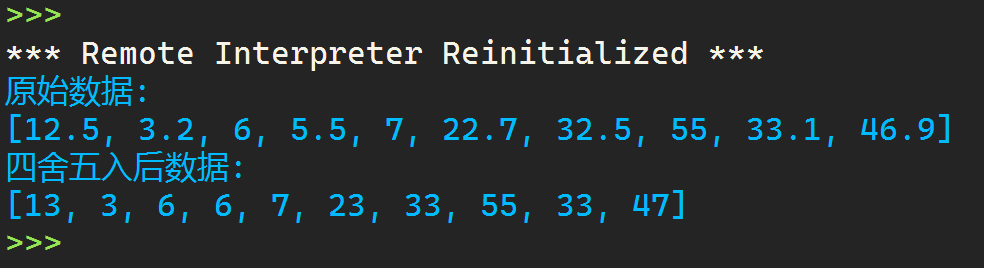
實驗任務7
task7:
源代碼:
1 import csv 2 3 with open(r'C:\Users\LENOVO\Desktop\python\data7.csv','r',encoding='gbk') as f: 4 data = f.readlines() 5 6 data = [i.strip('\n') for i in data] 7 title = data[0].split(',') 8 9 del data[0] 10 data = [i.split(',') for i in data] 11 12 id_name_major_score = {} 13 for i in data: 14 data1 = i[1:] 15 id_name_major_score[i[0]] = data1 16 17 print(f'{title[0]:8s}{title[1]:8s}{title[2]:8s}{title[3]:8s}') 18 data2 = sorted(id_name_major_score.items(),key = lambda x:x[1][2],reverse=True) 19 for j in data2: 20 print(f'{j[0]:8s}{j[1][0]:8s}{j[1][1]:8s}{j[1][2]:8s}') 21 22 data3 = [] 23 for y in data2: 24 a = [y[0]] 25 a.append(y[1][0]) 26 a.append(y[1][1]) 27 a.append(y[1][2]) 28 data3.append(a) 29 with open(r'C:\Users\LENOVO\Desktop\python\data7.csv','w',encoding='gbk',newline='') as f: 30 content = csv.writer(f) 31 content.writerow(title) 32 content.writerows(data3)
運行結果:

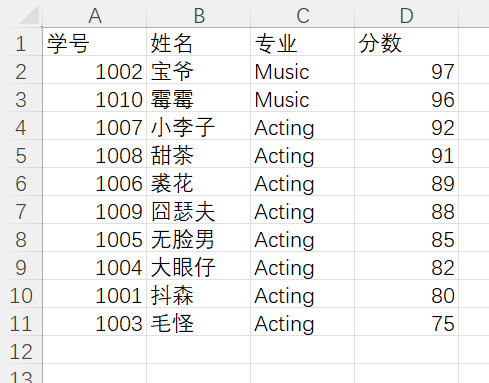
實驗任務8
task8:
源代碼:
1 with open(r'C:\Users\LENOVO\Desktop\python\hamlet.txt','r',encoding='utf-8') as f: 2 data = f.readlines() 3 4 hang = len(data) 5 6 data1 = '' 7 for line in data: 8 data1 += line 9 al = len(data1.split()) 10 blanket = data1.count(' ') 11 a,b = 0,0 12 for i in data1: 13 if i.isalpha(): 14 a += 1 15 else: 16 b += 1 17 string = a+b 18 19 print(f'行數(shù):{hang}\n單詞數(shù):{al}\n字符數(shù):{string}\n空格數(shù):{blanket}') 20 data2 = [] 21 num = [str(i) for i in range(1,hang+1)] 22 for i in range(1,hang+1): 23 a = num[i-1]+' '+data[i-1] 24 data2.append(a) 25 26 with open(r'C:\Users\LENOVO\Desktop\python\hamlet_with_line_number.txt','w',encoding='utf-8') as f: 27 f.writelines(data2)
運行結果:

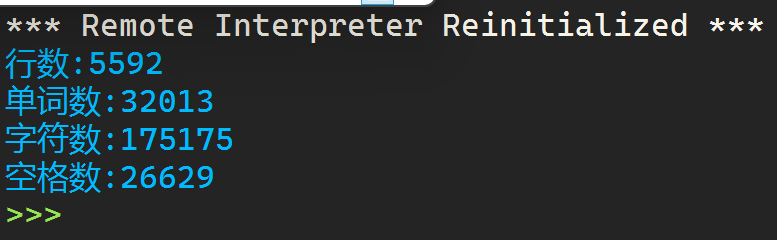
實驗任務9
task9:
源代碼:
1 with open(r'C:\Users\LENOVO\Desktop\python\data9_id.txt','r',encoding='utf-8') as f: 2 data = f.readlines() 3 4 def is_valid(n): 5 length = len(n) 6 if length == 18: 7 al = n.count('X') 8 if al == 0: 9 return True 10 elif al == 1: 11 w = n.index('X') 12 if w == 17: 13 return True 14 else: 15 return False 16 else: 17 return False 18 data1 = [i.strip('\n') for i in data] 19 del data1[0] 20 data2 = [i.split(',') for i in data1] 21 name_id = {} 22 for i in data2: 23 id = i[1] 24 if is_valid(id) == True: 25 name_id[i[0]] = id 26 27 name_data_age = {} 28 for key,j in name_id.items(): 29 time = j[6:10]+'-'+j[10:12]+'-'+j[12:14] 30 ages = str(2023-int(j[6:10])) 31 name_data_age[key] = time,ages 32 33 print('姓名,出生日期,年齡') 34 data3 = sorted(name_data_age.items(),key = lambda x:x[1][1],reverse=True) 35 for i in data3: 36 print(f'{i[0]},{i[1][0]},{i[1][1]}')
運行結果:
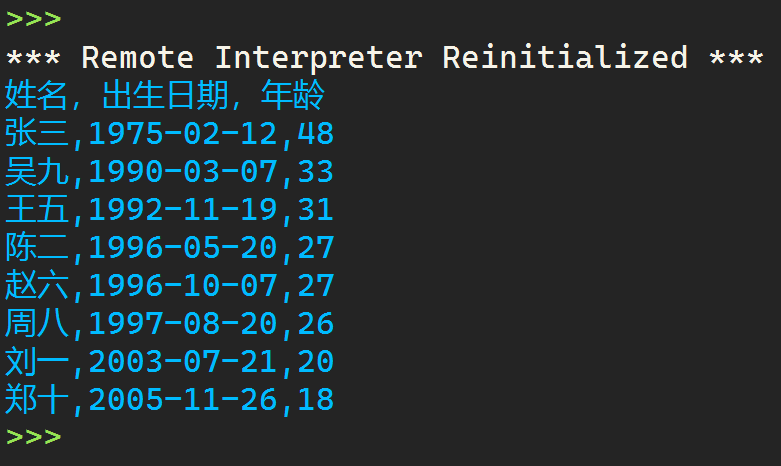
實驗任務10
task10-1:
源代碼:
1 import datetime 2 import random 3 4 n = eval(input('輸入隨機抽點人數(shù):')) 5 data = datetime.datetime.now() 6 filename = data.strftime('%Y%m%%d') + '.txt' 7 8 with open(r'C:\Users\LENOVO\Desktop\python\data10_stu.txt','r',encoding='utf-8') as f: 9 data1 = f.readlines() 10 11 def random_n(n): 12 data2 = random.sample(data1,n) 13 return data2 14 15 data3 = random_n(n) 16 for i in data3: 17 print(i.strip('\n')) 18 19 with open(r'C:\Users\LENOVO\Desktop\python\filename','w',encoding='utf-8') as f: 20 f.writelines(data3)
運行結果:
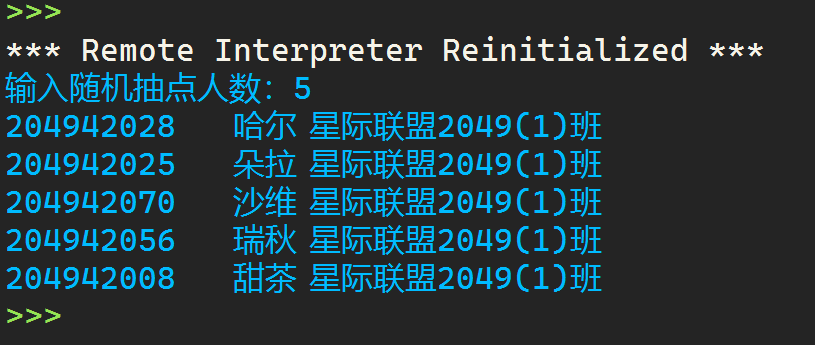

task10-2:
源代碼:
1 import datetime 2 import random 3 4 print('*'*20+'抽點開始'+'*'*20) 5 6 data = datetime.datetime.now() 7 filename = data.strftime('%Y%m%%d') + '.txt' 8 9 with open(r'C:\Users\LENOVO\Desktop\python\data10_stu.txt','r',encoding='utf-8') as f: 10 data1 = f.readlines() 11 12 def random_n(n): 13 data2 = random.sample(data1,n) 14 return data2 15 16 while True: 17 n = eval(input('輸入隨機抽點人數(shù):')) 18 if n!=0: 19 data3 = random_n(n) 20 for i in data3: 21 print(i.strip('\n')) 22 23 with open(r'C:\Users\LENOVO\Desktop\python\filename','w',encoding='utf-8') as f: 24 f.writelines(data3) 25 else: 26 print('*'*20+'抽點結束'+'*'*20) 27 break
運行結果:



 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號