Oracle打怪升級之路一【Oracle基礎、Oracle查詢】
前言
背景:2021年馬上結束了,在年尾由于工作原因接觸到一個政府單位比較傳統型的項目,數據庫用的是Oracle。需要做的事情其實很簡單,首先從大約2000多張表中將表結構及數據導入一個共享庫中,其次是將共享庫的數據進行清理落到業務庫里面。表不算多,但是表里面的數據量還蠻大的,開始是打算進行OGG同步,但由于數據保密的原因,機關單位不向外直接提供,只能導表結構及脫敏數據,于是進行dmp備份導入,再用存儲過程進行數據落地。在處理過程中發現Oracle常用的知識點基本都有涉及,于是決定寫下這篇博文。
整篇文章主要分為4大部分
- Oracle 基礎
- Oracle 查詢
- Oracle 對象
- Oracle 編程
當然,后續工作中有相應的知識點或者新的內容,再將輪子不斷完善。
Oracle基礎
Oracle簡介
(一) 什么是Oracle
ORACLE 數據庫系統是美國 ORACLE 公司(甲骨文)提供的以分布式數據庫為核心的一組軟件產品,是目前最流行的客戶/服務器(CLIENT/SERVER)或
B/S 體系結構的數據庫之一。
ORACLE 通常應用于大型系統的數據庫產品。
ORACLE 數據庫是目前世界上使用最為廣泛的數據庫管理系統,作為一個通用的數據庫系統,它具有完整的數據管理功能;作為一個關系數據庫,它是一個
完備關系的產品;作為分布式數據庫它實現了分布式處理功能。
ORACLE 數據庫具有以下特點:
(1)支持多用戶、大事務量的事務處理
(2)數據安全性和完整性控制
(3)支持分布式數據處理
(4)可移植性
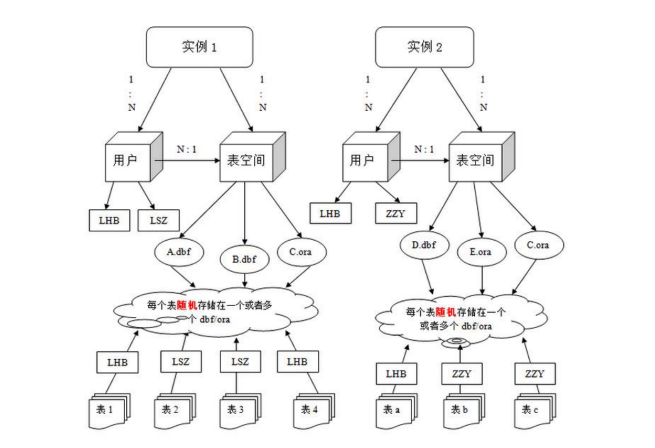
(二) Oracle體系結構
-
數據庫
Oracle 數據庫是數據的物理存儲。這就包括(數據文件 ORA 或者 DBF、控制文件、聯機日志、參數文件)。其實 Oracle 數據庫的概念和其它數據庫不一
樣,這里的數據庫是一個操作系統只有一個庫。可以看作是 Oracle 就只有一個北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090大數據庫。
-
實例
一個Oracle實例(Oracle Instance)有一系列的后臺進程(Backguound Processes)和內存結構(Memory Structures)組成。一個數據庫可以有 n 個實例。
-
數據文件(dbf)
數據文件是數據庫的物理存儲單位。數據庫的數據是存儲在表空間中的,真正是在某一個或者多個數據文件中。而一個表空間可以由一個或多個數據文件組成,一個數據文件只能屬于一個表空間。一旦數據文件被加入到某個表空間后,就不能刪除這個文件,如果要刪除某個數據文件,只能刪除其所屬于的表空間才行。
-
表空間
表空間是 Oracle 對物理數據庫上相關數據文件(ORA 或者 DBF 文件)的邏輯映射。一個數據庫在邏輯上被劃分成一到若干個表空間,每個表空間包含了在
邏輯上相關聯的一組結構。每個數據庫至少有一個表空間(稱之為 system 表空間)。
每個表空間由同一磁盤上的一個或多個文件組成,這些文件叫數據文件(datafile)。一個數據文件只能屬于一個表空間。

注:表的數據,是有用戶放入某一個表空間的,而這個表空間會隨機把這些表數據放到一個或者多個數據文件中。
由于 oracle 的數據庫不是普通的概念,oracle 是有用戶和表空間對數據進行管理和存放的。但是表不是有表空間去查詢的,而是由用戶去查的。因為不同用
戶可以在同一個表空間建立同一個名字的表!這里區分就是用戶了!

-
用戶
用戶是在表空間下建立的。用戶登陸后只能看到和操作自己的表, ORACLE的用戶與 MYSQL 的數據庫類似,每建立一個應用需要創建一個用戶。
Oracle安裝配置
關于搭建這一部分,詳細的流程就不一一列舉了,網上一查一大堆的資料,整體來說還是非常簡單的。而且一般來說在公司會有專門的DBA或者系統集成人員來做這部分工作,后續如果實際中工作有需要自己做這一塊,我再將這部分補充完整。
Oracle 表的基礎操作
-
查看當前數據庫實例名稱
select instance_name from v$instance; -
常用的數據字典信息查詢(數據字典視圖包含靜態數據字典視圖和動態性能視圖,其中靜態的數據字典視圖又分為三類,以不同前綴相互區分)
- DBA_*** 該視圖包含數據庫整個對象信息,只能由數據庫管理員查看
- ALL_*** 包含某個用戶所能看到的全部數據庫信息
- USER_*** 包含當前用戶訪問的數據庫對象信息
-- 通過數據字典視圖dba_objects查看某個用戶的數據庫對象信息,對于另外兩類視圖也是類似做法 select owner,object_name,created from from dba_objects where owner='HX_ZS'; -- 查看當前用戶所擁有的表 select table_name from user_tables; -- 查看當前用戶所擁有的表名和類型 select * from user_catalog; -
動態性能視圖查詢,動態性能視圖只存在于運行的數據庫中,只有數據庫管理員可以查詢,以v$為前綴。
- v$controlfile包含了控制文件存儲目錄和文件名信息
- v$datafile包含了數據庫文件信息
- v$fixed_table視圖包含了當前所有動態性能視圖
- v$datafile包含了當前所有動態性能視圖
-- 查詢所有和日志文件相關的動態性能視圖 select * from v$fixed_table where name like 'V$LOG%'; -- 查看當前正在使用的重做日志組,current說明正在使用 select group#,members,archived,status from v$log; -- 查看重做日志文件信息 select * from v$logfile; -- 查看實例信息 select instance_name,host_name,version,startup_time,logins from v$instance; -- 查看數據庫信息 select name,created,log_mode from v$database; -
查看表空間名稱
select tablespace_name,file_id,bytes,file_name from dba_data_files; -
創建表空間
create tablespace waterboss datafile '/u01/oradata/swgx/waterboss.dbf' size 100m autoextend on next 10m;解釋:
? waterboss 為表空間名稱
? datafile 用于設置物理文件名稱
? size 用于設置表空間的初始大小
? autoextend on 用于設置自動增長,如果存儲量超過初始大小,則開始自動擴容
? next 用于設置擴容的空間大小
-
創建用戶 表空間和用戶之間的關系是多對多
create user wateruser identified by wateruser default tablespace waterboss;解釋:
? wateruser 為創建的用戶名
? identified by 用于設置用戶的密碼
? default tablesapce 用于指定默認表空間名稱
-
用戶賦權,給用戶賦予DBA權限后即可登錄
grant dba to wateruser; -
數據類型
-
字符型
(1)CHAR : 固定長度的字符類型,最多存儲 2000 個字節
(2)VARCHAR2 :可變長度的字符類型,最多存儲 4000 個字節
(3)LONG : 大文本類型。最大可以存儲 2 個 G -
數值型
NUMBER : 數值類型
NUMBER(5) 最大可以存的數為 99999
NUMBER(5,2) 最大可以存的數為 999.99
-
日期型
(1)DATE:日期時間型,精確到秒
(2)TIMESTAMP:精確到秒的小數點后 9 位
-
二進制(大數據類型)
(1)CLOB : 存儲字符,最大可以存 4 個 G
(2)BLOB:存儲圖像、聲音、視頻等二進制數據,最多可以存 4 個 G
-
-
創建表
-- 語法 CREATE TABLE 表名稱( 字段名 類型(長度) primary key, 字段名 類型(長度), ....... ); -
修改表
增加字段語法
-- 語法 ALTER TABLE 表名稱 ADD( 列名 1 類型 [DEFAULT 默認值], 列名 1 類型 [DEFAULT 默認值] ... ) -- 語句 ALTER TABLE T_OWNERS ADD( REMARK VARCHAR2(20), OUTDATE DATE )修改字段語法
-- 語法 ALTER TABLE 表名稱 MODIFY( 列名 1 類型 [DEFAULT 默認值], 列名 1 類型[DEFAULT 默認值] ... ) -- 語句 ALTER TABLE T_OWNERS MODIFY( REMARK CHAR(20), OUTDATE TIMESTAMP )修改字段名語法
ALTER TABLE T_OWNERS RENAME COLUMN OUTDATE TO EXITDATE刪除字段名
-- 刪除一個字段 ALTER TABLE 表名稱 DROP COLUMN 列名 -- 刪除多個字段 ALTER TABLE 表名稱 DROP (列名 1,列名 2...) -- 語句 ALTER TABLE T_OWNERS DROP COLUMN REMARK -
刪除表
DROP TABLE 表名稱 -
基礎的增刪改查我就不一一去列舉語法了,這里提一下truncat 與 delete 表數據刪除差異
-- DELETE,執行 DELETE 后一定要再執行 COMMIT 提交事務 DELETE FROM 表名 WHERE 刪除條件; -- TRUNCATE 語法 TRUNCATE TABLE 表名稱二者差異:
- delete 刪除的數據可以 rollback
- delete 刪除可能產生碎片,并且不釋放空間
- truncate 是先摧毀表結構,再重構表結構
Oracle 數據的導入導出
當我們使用一個數據庫時,總希望數據庫的內容是可靠的、正確的,但由于計算機系統的故障(硬件故障、軟件故障、網絡故障、進程故障和系統故障)影響數據庫系統的操作,影響數據庫中數據的正確性,甚至破壞數據庫,使數據庫中全部或部分數據丟失。因此當發生上述故障后,希望能重構這個完整的數據庫該處理稱為數據庫恢復,而要進行數據庫的恢復必須要有數據庫的備份工作。
前提條件,切換至Oracle下并登陸
# Linux 切換oracle用戶 并登陸
$: su -l oracle
$: sqlplus 用戶名/密碼 as sysdba
(一) 整庫導入導出
$: exp system/wateruser full=y
解釋:添加參數 full=y 就是整庫導出,執行命令后會在當前目錄下生成一個叫 EXPDAT.DMP,此文件為備份文件。
如果想指定備份文件的名稱,則添加 file 參數即可,命令如下
$: exp system/wateruser file=文件名 full=y
整庫導入命令
$: imp system/wateruser full=y
此命令如果不指定 file 參數,則默認用備份文件 EXPDAT.DMP 進行導入如果指定 file 參數,則按照 file 指定的備份文件進行恢復
$: imp system/wateruser full=y file=water.dmp
(二) 按用戶導出與導入
按用戶導出
$: exp system/wateruser owner=wateruser file=wateruser.dmp
按用戶導入
$: imp system/wateruser file=wateruser.dmp fromuser=wateruser
(三) 按表導出與導入
按表導出,用 tables 參數指定需要導出的表,如果有多個表用逗號分割即可
$: exp wateruser/wateruser file=a.dmp tables=t_account,a_area
按表導入
$: imp wateruser/wateruser file=a.dmp tables=t_account,a_area
Oracle查詢
以下案例的SQL腳本及測試數據,可關注博主后私信獲取。原創不易,謝謝支持。
單表查詢
簡單條件查詢
精確查詢
需求:查詢水表編號為 30408 的業主記錄
查詢語句:
select * from T_OWNERS where watermeter='30408'
模糊查詢
需求:查詢業主名稱包含“劉”的業主記錄
查詢語句:
select * from t_owners where name like '%劉%'
and運算符
需求:查詢業主名稱包含“劉”的并且門牌號包含 5 的業主記錄
查詢語句:
select * from t_owners where name like '%劉%' and housenumber like '%5%'
or 運算符
需求:查詢業主名稱包含“劉”的或者門牌號包含 5 的業主記錄
查詢語句:
select * from t_owners where name like '%劉%' or housenumber like '%5%'
and 與 or 運算符混合使用
需求:查詢業主名稱包含“劉”的或者門牌號包含 5 的業主記錄,并且地址編號 為 3 的記錄。
select * from t_owners where (name like '%劉%' or housenumber like '%5%') and addressid=3
因為 and 的優先級比 or 大,所以我們需要用 ( ) 來改變優先級。
范圍查詢
需求:查詢臺賬記錄中用水字數大于等于 10000,并且小于等于 20000 的記錄
我們可以用>= 和<=來實現,查詢語句
select * from T_ACCOUNT where usenum>=10000 and usenum<=20000
我們也可以用 between .. and ..來實現
select * from T_ACCOUNT where usenum between 10000 and 20000
空值查詢
需求:查詢 T_PRICETABLE 表中 MAXNUM 為空的記錄
語句:
select * from T_PRICETABLE t where maxnum is null
需求:查詢 T_PRICETABLE 表中 MAXNUM 不為空的記錄
查詢語句
select * from T_PRICETABLE t where maxnum is not null
去掉重復記錄
需求:查詢業主表中的地址 ID,不重復顯示
語句:
select distinct addressid from T_OWNERS
排序查詢
升序查詢
需求:對 T_ACCOUNT 表按使用量進行升序排序
語句:
select * from T_ACCOUNT order by usenum
降序排序
需求:對 T_ACCOUNT 表按使用量進行降序排序
語句:
select * from T_ACCOUNT order by usenum desc
基于偽列的查詢
在 Oracle 的表的使用過程中,實際表中還有一些附加的列,稱為偽列。偽列就 像表中的列一樣,但是在表中并不存儲。偽列只能查詢,不能進行增刪改操作。 接下來學習兩個偽列:ROWID 和 ROWNUM。
ROWID
表中的每一行在數據文件中都有一個物理地址,ROWID 偽列返回的就是該行的 物理地址。使用 ROWID 可以快速的定位表中的某一行。ROWID 值可以唯一的標識表中的一行。由于 ROWID 返回的是該行的物理地址,因此使用 ROWID 可以顯示行是如何存儲的。
select rowID,t.* from T_AREA t;
我們可以通過指定 ROWID 來查詢記錄
select rowID,t.* from T_AREA t where ROWID='AAAM1uAAGAAAAD8AAC';
ROWNUM
在查詢的結果集中,ROWNUM 為結果集中每一行標識一個行號,第一行返回 1, 第二行返回 2,以此類推。
通過 ROWNUM 偽列可以限制查詢結果集中返回的行數。可用作分頁查詢
查詢語句
select rownum,t.* from T_OWNERTYPE t
聚合統計
ORACLE 的聚合統計是通過分組函數來實現的,與 MYSQL 一致。
聚合函數
求和 SUM
需求:統計 2012 年所有用戶的用水量總和
select sum(usenum) from t_account where year='2012'
求平均值 AVG
需求:統計 2012 年所有用水量(字數)的平均值
select avg(usenum) from T_ACCOUNT where year='2012'
求最大值 MAX
需求:統計 2012 年最高用水量(字數)
select max(usenum) from T_ACCOUNT where year='2012'
求最小值 MIN
需求:統計 2012 年最低用水量(字數)
select min(usenum) from T_ACCOUNT where year='2012'
統計個數
需求:統計業主類型 ID 為 1 的業主數量
select count(*) from T_OWNERS t where ownertypeid=1
分組聚合
需求:按區域分組統計水費合計數
查詢語句
select areaid,sum(money) from t_account group by areaid
分組后條件查詢having
需求:查詢水費合計大于 16900 的區域及水費合計
查詢語句
select areaid,sum(money) from t_account group by areaid having sum(money)>169000
連接查詢
多表內連接查詢
需求:查詢顯示業主編號,業主名稱,業主類型名稱
查詢語句
select o.id 業主編號,o.name 業主名稱,ot.name 業主類型 from T_OWNERS o,T_OWNERTYPE ot where o.ownertypeid=ot.id
需求:查詢顯示業主編號,業主名稱、地址和業主類型
查詢語句
select o.id 業主編號,o.name 業主名稱,ad.name 地址, ot.name 業主類型 from T_OWNERS o,T_OWNERTYPE ot,T_ADDRESS ad where o.ownertypeid=ot.id and o.addressid=ad.id
需求:查詢顯示業主編號、業主名稱、地址、所屬區域、業主分類
查詢語句
select o.id 業主編號,o.name 業主名稱,ar.name 區域, ad.name 地 址, ot.name 業主類型
from T_OWNERS o ,T_OWNERTYPE ot,T_ADDRESS ad,T_AREA ar
where o.ownertypeid=ot.id and
o.addressid=ad.id and
ad.areaid=ar.id
需求:查詢顯示業主編號、業主名稱、地址、所屬區域、收費員、業主分類
查詢語句
select ow.id 業主編號,ow.name 業主名稱,ad.name 地址, ar.name 所屬區域,op.name 收費員, ot.name 業主類型
from
T_OWNERS ow,T_OWNERTYPE ot,T_ADDRESS ad , T_AREA ar,T_OPERATOR op
where ow.ownertypeid=ot.id
and ow.addressid=ad.id
and ad.areaid=ar.id
and ad.operatorid=op.id
左外連接查詢
需求:查詢業主的賬務記錄,顯示業主編號、名稱、年、月、金額。如果此業主沒有賬務記錄也要列出姓名。
查詢語句
-- SQL1999 標準的語法
SELECT ow.id,ow.name,ac.year ,ac.month,ac.money FROM T_OWNERS ow left join T_ACCOUNT ac on ow.id=ac.owneruuid
-- ORACLE 提供的語法
SELECT ow.id,ow.name,ac.year ,ac.month,ac.money FROM T_OWNERS ow,T_ACCOUNT ac WHERE ow.id=ac.owneruuid(+)
如果是左外連接,就在右表所在的條件一端填上(+)
右外連接查詢
需求:查詢業主的賬務記錄,顯示業主編號、名稱、年、月、金額。如果賬務記錄沒有對應的業主信息,也要列出記錄。
-- SQL1999 標準的語句
select ow.id,ow.name,ac.year,ac.month,ac.money from T_OWNERS ow right join T_ACCOUNT ac on ow.id=ac.owneruuid
-- ORACLE 提供的語法
select ow.id,ow.name,ac.year,ac.month,ac.money from T_OWNERS ow , T_ACCOUNT ac where ow.id(+) =ac.owneruuid
子查詢
where 子句中的子查詢
-
單行子查詢
-
只返回一條記錄
-
單行操作符
-

需求:查詢 2012 年 1 月用水量大于平均值的臺賬記錄
查詢語句:
select * from T_ACCOUNT where year='2012' and month='01'
and usenum> ( select avg(usenum) from T_ACCOUNT where year='2012' and month='01' )
-
多行子查詢
-
返回多條記錄
-
多行操作符
-
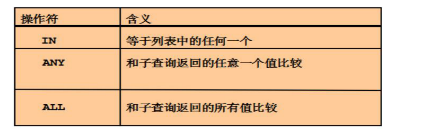
in運算符
需求:查詢地址編號為 1 、3、4 的業主記錄
分析:如果我們用 or 運算符編寫,SQL 非常繁瑣,所以我們用 in 來進行查詢
查詢語句
select * from T_OWNERS where addressid in ( 1,3,4 )
需求:查詢地址含有“花園”的業主的信息
查詢語句
select * from T_OWNERS where addressid in ( select id from t_address where name like '%花園%' )
需求:查詢地址不含有“花園”的業主的信息
查詢語句
select * from T_OWNERS where addressid not in ( select id from t_address where name like '%花園%' )
from 子句中的子查詢
from 子句的子查詢為多行子查詢
需求:查詢顯示業主編號,業主名稱,業主類型名稱,條件為業主類型為”居民”, 使用子查詢實現。
查詢語句
select * from (
select o.id 業主編號,o.name 業主名稱,ot.name 業主類型
from T_OWNERS o,T_OWNERTYPE ot
where o.ownertypeid=ot.id )
where 業主類型='居民';
select 子句中的子查詢
select 子句的子查詢必須為單行子查詢
需求:列出業主信息,包括 ID,名稱,所屬地址
查詢語句
select id,name, (select name from t_address where id=addressid) addressname from t_owners;
需求:列出業主信息,包括 ID,名稱,所屬地址,所屬區域
查詢語句
select id, name, ( select name from t_address where id=addressid ) addressname,
( select (select name from t_area where id=areaid ) from t_address where id = addressid ) adrename
from t_owners;
分頁查詢
簡單分頁
需求:分頁查詢臺賬表 T_ACCOUNT,每頁 10 條記錄
分析:我們在 ORACLE 進行分頁查詢,需要用到偽列 ROWNUM 和嵌套查詢
我們首先顯示前 10 條記錄,查詢語句:
select rownum,t.* from T_ACCOUNT t where rownum<=10
那么我們顯示第 11 條到第 20 條的記錄呢?編寫語句:
select rownum,t.* from T_ACCOUNT t where rownum>10 and rownum<=20
查詢結果為空
嗯?怎么沒有結果?
這是因為 rownum 是在查詢語句掃描每條記錄時產生的,所以不能使用“大于”
符號,只能使用“小于”或“小于等于” ,只用“等于”也不行。
那怎么辦呢?我們可以使用子查詢來實現
select * from (select rownum r,t.* from T_ACCOUNT t where rownum<=20) where r>10
基于排序的分頁
需求:分頁查詢臺賬表 T_ACCOUNT,每頁 10 條記錄,按使用字數降序排序。
我們查詢第 2 頁數據,如果基于上邊的語句添加排序,查詢語句如下
select * from (select rownum r,t.* from (select * from T_ACCOUNT order by usenum desc) t where rownum<=20 ) where r>10
單行函數查詢
字符函數
| 函數 | 說明 |
|---|---|
| ASCII | 返回對應字符的十進制值 |
| CHR | 給出十進制返回字符 |
| CONCAT | 拼接兩個字符串,與 |
| INITCAT | 將字符串的第一個字母變為大寫 |
| INSTR | 找出某個字符串的位置 |
| INSTRB | 找出某個字符串的位置和字節數 |
| LENGTH | 以字符給出字符串的長度 |
| LENGTHB | 以字節給出字符串的長度 |
| LOWER | 將字符串轉換成小寫 |
| LPAD | 使用指定的字符在字符的左邊填充 |
| LTRIM | 在左邊裁剪掉指定的字符 |
| RPAD | 使用指定的字符在字符的右邊填充 |
| RTRIM | 在右邊裁剪掉指定的字符 |
| REPLACE | 執行字符串搜索和替換 |
| SUBSTR | 取字符串的子串 |
| SUBSTRB | 取字符串的子串(以字節) |
| SOUNDEX | 返回一個同音字符串 |
| TRANSLATE | 執行字符串搜索和替換 |
| TRIM | 裁剪掉前面或后面的字符串 |
| UPPER | 將字符串變為大寫 |
常用字符函數:
字符串長度 LENGTH
select length('ABCD') from dual;
字符串的子串 SUBSTR
select substr('ABCD',2,2) from dual;
字符串拼接 CONCAT
select concat('ABC','D') from dual;
我們也可以用|| 對字符串進行拼接
select 'ABC'||'D' from dual;
數值函數
| 函數 | 說明 |
|---|---|
| ABS(value) | 絕對值 |
| CEIL(value) | 大于或等于 value 的最小整數 |
| COS(value) | 余弦 |
| COSH(value) | 反余弦 |
| EXP(value) | e 的 value 次冪 |
| FLOOR(value) | 小于或等于 value 的最大整數 |
| LN(value) | value 的自然對數 |
| LOG(value) | value 的以 10 為底的對數 |
| MOD(value,divisor) | 求模 |
| POWER(value,exponent) | value 的 exponent 次冪 |
| ROUND(value,precision) | 按 precision 精度 4 舍 5 入 |
| SIGN(value) | value 為正返回 1;為負返回-1;為 0 返回 0. |
| SIN(value) | 余弦 |
| SINH(value) | 反余弦 |
| SQRT(value) | value 的平方根 |
| TAN(value) | 正切 |
| TANH(value) | 反正切 |
| TRUNC(value,按 precision) | 按照 precision 截取 value |
| VSIZE(value) | 返回 value 在 ORACLE 的存儲空間大小 |
常用數值函數講解
四舍五入函數 ROUND
-- 不保留小數,四舍五入
select round(100.567) from dual;
-- 保留小數四舍五入
select round(100.567,2) from dual;
截取函數 TRUNC
select trunc(100.567) from dual
select trunc(100.567,2) from dual
取模 MOD
select mod(10,3) from dual
日期函數
| 函數 | 描述 |
|---|---|
| ADD_MONTHS | 在日期 date 上增加 count 個月 |
| GREATEST(date1,date2,. . .) | 從日期列表中選出最晚的日期 |
| LAST_DAY( date ) | 返回日期 date 所在月的最后一天 |
| LEAST( date1, date2, . . .) | 從日期列表中選出最早的日期 |
| MONTHS_BETWEEN(date2, date1) | 給出 Date2 - date1 的月數(可以是小數) |
| NEXT_DAY( date,’day’) | 給出日期 date 之后下一天的日期,這里的 day 為星期, 如: MONDAY,Tuesday 等。 |
| NEW_TIME(date,’this’,’other’) | 給出在 this 時區=Other 時區的日期和時間 |
| ROUND(date,’format’) | 未指定 format 時,如果日期中的時間在中午之前,則 將日期中的時間截斷為 12 A.M.(午夜,一天的開始),否 則進到第二天。時間截斷為 12 A.M.(午夜,一天的開始),否則進到第二天。 |
| TRUNC(date,’format’) | 未指定 format 時,將日期截為 12 A.M.( 午夜,一天的開始)。 |
我們用 sysdate 這個系統變量來獲取當前日期和時間
select sysdate from dual;
常用日期函數講解:
加月函數 ADD_MONTHS :在當前日期基礎上加指定的月
select add_months(sysdate,2) from dual;
求所在月最后一天 LAST_DAY
select last_day(sysdate) from dual;
日期截取 TRUNC
select TRUNC(sysdate) from dual;
select TRUNC(sysdate,'yyyy') from dual
select TRUNC(sysdate,'mm') from dual
轉換函數
| 函數 | 描述 |
|---|---|
| CHARTOROWID | 將 字符轉換到 rowid 類型 |
| CONVERT | 轉換一個字符節到另外一個字符節 |
| HEXTORAW | 轉換十六進制到 raw 類型 |
| RAWTOHEX | 轉換 raw 到十六進制 |
| ROWIDTOCHAR | 轉換 ROWID 到字符 |
| TO_CHAR | 轉換日期格式到字符串 |
| TO_DATE | 按照指定的格式將字符串轉換到日期型 |
| TO_MULTIBYTE | 把單字節字符轉換到多字節 |
| TO_NUMBER | 將數字字串轉換到數字 |
| TO_SINGLE_BYTE | 轉換多字節到單字節 |
常用轉換函數
數字轉字符串
select TO_CHAR(1024) from dual
日期轉字符串 TO_CHAR
select TO_CHAR(sysdate,'yyyy-mm-dd') from dual;
select TO_CHAR(sysdate,'yyyy-mm-dd hh:mi:ss') from dual;
字符串轉日期 TO_DATE
select TO_DATE('2017-01-01','yyyy-mm-dd') from dual;
字符串轉數字 TO_NUMBER
select to_number('100') from dual;
其他函數
空值處理函數 NVL
語法: NVL(檢測的值,如果為 null 的值);
select NVL(NULL,0) from dual;
-- 需求:顯示價格表中業主類型 ID 為 1 的價格記錄,如果上限值為 NULL,則顯示 9999999
select PRICE,MINNUM,NVL(MAXNUM,9999999) from T_PRICETABLE where OWNERTYPEID=1;
空值處理函數 NVL2
語法: NVL2(檢測的值,如果不為 null 的值,如果為 null 的值);
-- 需求:顯示價格表中業主類型 ID 為 1 的價格記錄,如果上限值為 NULL,顯示“不限”
select PRICE,MINNUM,NVL2(MAXNUM,to_char(MAXNUM) , '不限') from T_PRICETABLE where OWNERTYPEID=1;
條件取值 decode
語法: decode(條件,值 1,翻譯值 1,值 2,翻譯值 2,...值 n,翻譯值 n,缺省值) 【功能】根據條件返回相應值
select name,decode(ownertypeid,
1,'居民',
2,'行政事業單位',
3,'商業') as 類型 from T_OWNERS
上邊的語句也可以用 case when then 語句來實現
select name ,(case ownertypeid
when 1 then '居民'
when 2 then '行政事業單位'
when 3 then '商業'
else '其它'
end ) from T_OWNERS;
-- 另外一種寫法
select name,(case when ownertypeid= 1 then '居民'
when ownertypeid= 2 then '行政事業'
when ownertypeid= 3 then '商業'
end ) from T_OWNERS
行列轉換
需求:按月份統計 2012 年各個地區的水費,如下圖
select (select name from T_AREA where id = areaid) 區域,
sum(case when month = '01' then money else 0 end) 一月,
sum(case when month = '02' then money else 0 end) 二月,
sum(case when month = '03' then money else 0 end) 三月,
sum(case when month = '04' then money else 0 end) 四月,
sum(case when month = '05' then money else 0 end) 五月,
sum(case when month = '06' then money else 0 end) 六月,
sum(case when month = '07' then money else 0 end) 七月,
sum(case when month = '08' then money else 0 end) 八月,
sum(case when month = '09' then money else 0 end) 九月,
sum(case when month = '10' then money else 0 end) 十月,
sum(case when month = '11' then money else 0 end) 十一月,
sum(case when month = '12' then money else 0 end) 十二月
from T_ACCOUNT
where year = '2012'
group by areaid;
需求:按季度統計 2012 年各個地區的水費
select (select name from T_AREA where id = areaid) 區域,
sum(case when month >= '01' and month <= '03' then money else 0 end) 第一季度,
sum(case when month >= '04' and month <= '06' then money else 0 end) 第二季度,
sum(case when month >= '07' and month <= '09' then money else 0 end) 第三季度,
sum(case when month >= '10' and month <= '12' then money else 0 end) 第四季度
from T_ACCOUNT
where year = '2012'
group by areaid;
分析函數
以下三個分析函數可以用于排名使用。
RANK 相同的值排名相同,排名跳躍
需求:對 T_ACCOUNT 表的 usenum 字段進行排序,相同的值排名相同,排名跳北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
躍
select rank() over(order by usenum desc ),usenum from T_ACCOUNT;
DENSE_RANK 相同的值排名相同,排名連續
需求:對 T_ACCOUNT 表的 usenum 字段進行排序,相同的值排名相同,排名連續
select dense_rank() over(order by usenum desc ),usenum from T_ACCOUNT;
ROW_NUMBER 返回連續的排名,無論值是否相等
需求:對 T_ACCOUNT 表的 usenum 字段進行排序,返回連續的排名,無論值是否相等
select row_number() over(order by usenum desc ),usenum from T_ACCOUNT
用 row_number()分析函數實現的分頁查詢相對三層嵌套子查詢要簡單的多
select *
from (select row_number() over (order by usenum desc ) rownumber, usenum from T_ACCOUNT)
where rownumber > 10
and rownumber <= 20
集合運算
集合運算,集合運算就是將兩個或者多個結果集組合成為一個結果集。
集合運算包括:
- UNION ALL(并集),返回各個查詢的所有記錄,包括重復記錄
- UNION(并集),返回各個查詢的所有記錄,不包括重復記錄
- INTERSECT(交集),返回兩個查詢共有的記錄
- MINUS(差集),返回第一個查詢檢索出的記錄減去第二個查詢檢索出的記錄之后剩余的記錄

并集運算
UNION ALL 不去掉重復記錄
select *
from t_owners
where id <= 7
union all
select *
from t_owners
where id >= 5
UNION 去掉重復記錄
select * from t_owners where id<=7
union
select * from t_owners where id>=5
交集運算
select * from t_owners where id<=7
intersect
select * from t_owners where id>=5
差集運算
select * from t_owners where id<=7
minus
select * from t_owners where id>=5
如果我們用 minus 運算符來實現分頁,語句如下
select rownum,t.* from T_ACCOUNT t where rownum<=20
minus
select rownum,t.* from T_ACCOUNT t where rownum<=10

 浙公網安備 33010602011771號
浙公網安備 33010602011771號