
實驗一 感知機及其應用
------------恢復內容開始------------
| 作業課程 | 機器學習實驗-計算機18級 |
|---|---|
| 作業要求 | 實驗一 感知器及其應用 |
| 作業目標 | 理解感知器算法原理,能實現感知器算法 |
| 學號 | 3181002122 |
一、實驗目的
-
理解感知器算法原理,能實現感知器算法;
-
掌握機器學習算法的度量指標;
-
掌握最小二乘法進行參數估計基本原理;
-
針對特定應用場景及數據,能構建感知器模型并進行預測。
二、實驗內容
-
安裝Pycharm,注冊學生版。
-
安裝常見的機器學習庫,如Scipy、Numpy、Pandas、Matplotlib,sklearn等。
-
編程實現感知器算法。
-
熟悉iris數據集,并能使用感知器算法對該數據集構建模型并應用。
三、實驗報告要求
-
按實驗內容撰寫實驗過程;
-
報告中涉及到的代碼,每一行需要有詳細的注釋;
-
按自己的理解重新組織,禁止粘貼復制實驗內容。
四、實驗記錄
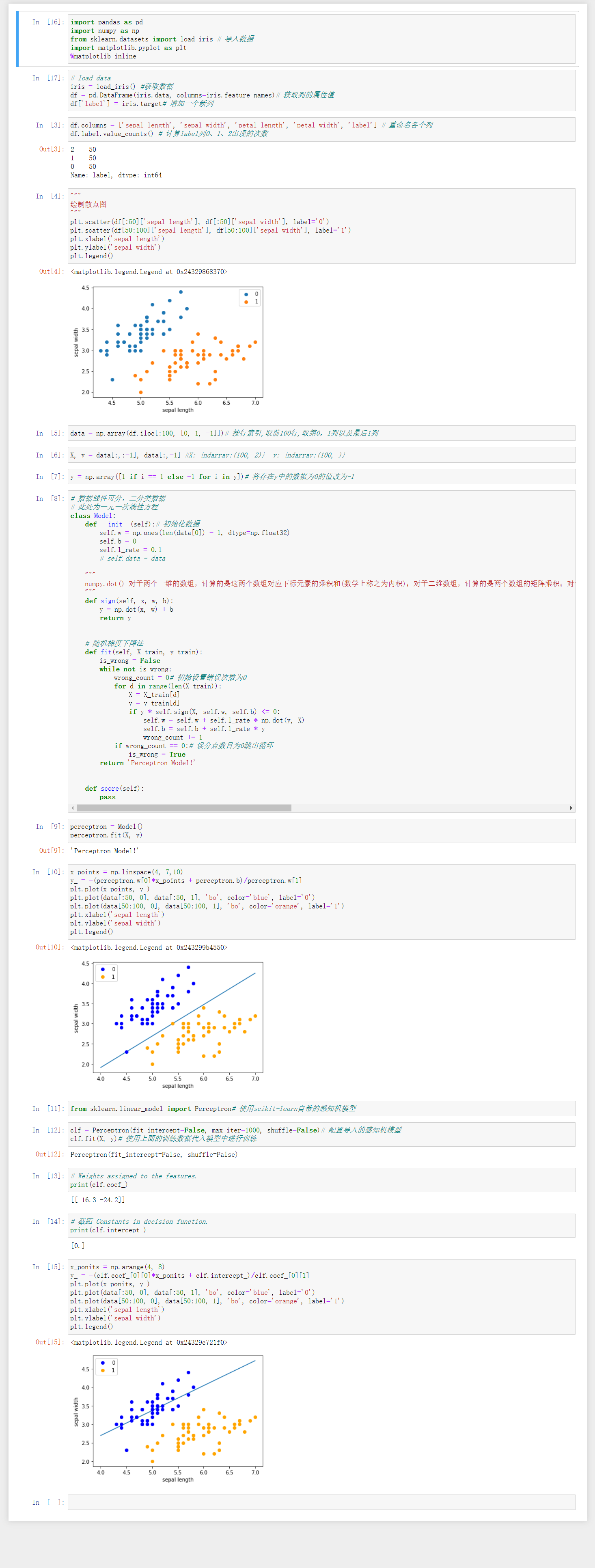
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris # 導入數據
import matplotlib.pyplot as plt
%matplotlib inline
# load data
iris = load_iris() #獲取數據
df = pd.DataFrame(iris.data, columns=iris.feature_names)# 獲取列的屬性值
df['label'] = iris.target# 增加一個新列
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label'] # 重命名各個列
df.label.value_counts() # 計算label列0、1、2出現的次數
"""
繪制散點圖
"""
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
data = np.array(df.iloc[:100, [0, 1, -1]])# 按行索引,取前100行,取第0,1列以及最后1列
X, y = data[:,:-1], data[:,-1] #X: {ndarray:(100, 2)} y: {ndarray:(100, )}
y = np.array([1 if i == 1 else -1 for i in y])# 將存在y中的數據為0的值改為-1
# 數據線性可分,二分類數據
# 此處為一元一次線性方程
class Model:
def __init__(self):# 初始化數據
self.w = np.ones(len(data[0]) - 1, dtype=np.float32)
self.b = 0
self.l_rate = 0.1
# self.data = data
"""
numpy.dot() 對于兩個一維的數組,計算的是這兩個數組對應下標元素的乘積和(數學上稱之為內積);對于二維數組,計算的是兩個數組的矩陣乘積;對于多維數組,它的通用計算公式如下,即結果數組中的每個元素都是:數組a的最后一維上的所有元素與數組b的倒數第二位上的所有元素的乘積和: dot(a, b)[i,j,k,m] = sum(a[i,j,:] * b[k,:,m])。
"""
def sign(self, x, w, b):
y = np.dot(x, w) + b
return y
# 隨機梯度下降法
def fit(self, X_train, y_train):
is_wrong = False
while not is_wrong:
wrong_count = 0# 初始設置錯誤次數為0
for d in range(len(X_train)):
X = X_train[d]
y = y_train[d]
if y * self.sign(X, self.w, self.b) <= 0:
self.w = self.w + self.l_rate * np.dot(y, X)
self.b = self.b + self.l_rate * y
wrong_count += 1
if wrong_count == 0:# 誤分點數目為0跳出循環
is_wrong = True
return 'Perceptron Model!'
def score(self):
pass
perceptron = Model()
perceptron.fit(X, y)
x_points = np.linspace(4, 7,10)
y_ = -(perceptron.w[0]*x_points + perceptron.b)/perceptron.w[1]
plt.plot(x_points, y_)
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
from sklearn.linear_model import Perceptron# 使用scikit-learn自帶的感知機模型
clf = Perceptron(fit_intercept=False, max_iter=1000, shuffle=False)# 配置導入的感知機模型
clf.fit(X, y)# 使用上面的訓練數據代入模型中進行訓練
# Weights assigned to the features.
print(clf.coef_)
# 截距 Constants in decision function.
print(clf.intercept_)
x_ponits = np.arange(4, 8)
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_)
plt.plot(data[:50, 0], data[:50, 1], 'bo', color='blue', label='0')
plt.plot(data[50:100, 0], data[50:100, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
五、運行結果
六、實驗小結
本次實驗是理解感知機算法的原理并實現感知機算法,感知機稱為單層感知機模型,其輸入是實例的特征向量,輸出為實例的分類類別。它是一種使用階梯函數激活的人工神經元,以產生二分類輸出,用于將數據分為兩部分,因此也稱為線性二分類器。實驗中使用jupyterbook進行實驗,并使用到了pandas、numpy、Matplotlib、sklearn等機器學習庫,對于機器學習有了一點新的理解,未來也會繼續加強理解。


 浙公網安備 33010602011771號
浙公網安備 33010602011771號