
Zookeeper學(xué)習(xí)
轉(zhuǎn)自:http://www.rzrgm.cn/zlslch/p/5902680.html
在hadoop生態(tài)圈里,很多地方都需zookeeper。


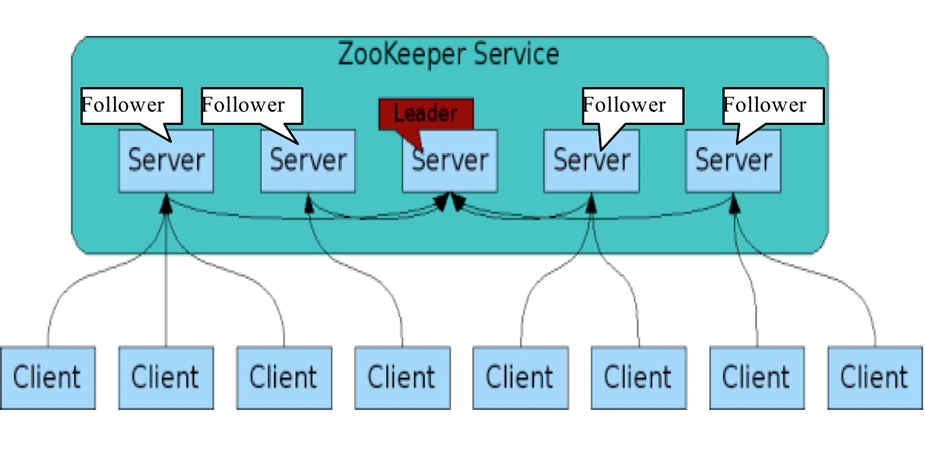
啟動的時候,都是普通的server,但在啟動過程中,通過一個特定的選舉機制,選出一個leader。




只運行在一臺服務(wù)器上,適合測試環(huán)境;Zookeeper 的啟動腳本在 bin 目錄下;在啟動腳本之前,還有幾個基本的配置項需要配置一下, tickTime :這個時間是作為 Zookeeper 服務(wù)器之間或客戶端與服務(wù)器之間維持心跳的時間間隔,也就是每個 tickTime 時間就會發(fā)送一個心跳;dataDir:顧名思義就是 Zookeeper 保存數(shù)據(jù)的目錄,默認(rèn)情況下,Zookeeper 將寫數(shù)據(jù)的日志文件也保存在這個目錄里;clientPort:這個端口就是客戶端連接 Zookeeper 服務(wù)器的端口,Zookeeper 會監(jiān)聽這個端口,接受客戶端的訪問請求。當(dāng)這些配置項配置好后,就可以啟動 Zookeeper 了,啟動后使用命令echo ruok | nc localhost 2181檢查 Zookeeper 是否已經(jīng)在服務(wù)

Zookeeper 不僅可以單機提供服務(wù),同時也支持多機組成集群來提供服務(wù) , 實際上 Zookeeper 還支持另外一種偽集群的方式,也就是可以在一臺物理機上運行多個 Zookeeper 實例;nitLimit:這個配置項是用來配置 Zookeeper 接受客戶端(這里所說的客戶端不是用戶連接 Zookeeper 服務(wù)器的客戶端,而是 Zookeeper 服務(wù)器集群中連接到 Leader 的 Follower 服務(wù)器)初始化連接時最長能忍受多少個心跳時間間隔數(shù)。當(dāng)已經(jīng)超過 10 個心跳的時間(也就是 tickTime)長度后 Zookeeper 服務(wù)器還沒有收到客戶端的返回信息,那么表明這個客戶端連接失敗。總的時間長度就是 5*2000=10 秒;syncLimit:這個配置項標(biāo)識 Leader 與 Follower 之間發(fā)送消息,請求和應(yīng)答時間長度,最長不能超過多少個 tickTime 的時間長度,總的時間長度就是 2*2000=4 秒;server.A=B:C:D:其中 A 是一個數(shù)字,表示這個是第幾號服務(wù)器;B 是這個服務(wù)器的 ip 地址;C 表示的是這個服務(wù)器與集群中的 Leader 服務(wù)器交換信息的端口;D 表示的是萬一集群中的 Leader 服務(wù)器掛了,需要一個端口來重新進行選舉,選出一個新的 Leader,而這個端口就是用來執(zhí)行選舉時服務(wù)器相互通信的端口。如果是偽集群的配置方式,由于 B 都是一樣,所以不同的 Zookeeper 實例通信端口號不能一樣,所以要給它們分配不同的端口號。除了修改 zoo.cfg 配置文件,集群模式下還要配置一個文件 myid,這個文件在 dataDir 目錄下,這個文件里面就有一個數(shù)據(jù)就是 A 的值,Zookeeper 啟動時會讀取這個文件,拿到里面的數(shù)據(jù)與 zoo.cfg 里面的配置信息比較從而判斷到底是那個 server。分別在3臺機器上啟動ZooKeeper的Server:sh bin/zkServer.sh start;運行于一個集群上,適合生產(chǎn)環(huán)境,這個計算機集群被稱為一個“集合體”(ensemble)。Zookeeper通過復(fù)制來實現(xiàn)高可用性,只要集合體中半 數(shù)以上的機器處于可用狀態(tài),它就能夠保證服務(wù)繼續(xù)。為什么一定要超過半數(shù)呢?這跟Zookeeper的復(fù)制策略有關(guān):zookeeper確保對znode 樹的每一個修改都會被復(fù)制到集合體中超過半數(shù)的機器上。

在一臺機器上部署了3個server;需要注意的是clientPort這個端口如果在1臺機器上部署多個server,那么每臺機器都要不同的clientPort,比如 server1是2181,server2是2182,server3是2183,dataDir和dataLogDir也需要區(qū)分下。

在一臺機器上部署了3個server;需要注意的是clientPort這個端口如果在1臺機器上部署多個server,那么每臺機器都要不同的clientPort,比如 server1是2181,server2是2182,server3是2183,dataDir和dataLogDir也需要區(qū)分下;最后幾行唯一需要注意的地方就是 server.X 這個數(shù)字就是對應(yīng) data/myid中的數(shù)字。你在3個server的myid文件中分別寫入了1,2,3,那么每個server中的zoo.cfg都配 server.1,server.2,server.3就OK了。因為在同一臺機器上,后面連著的2個端口3個server都不要一樣,否則端口沖突,其 中第一個端口用來集群成員的信息交換,第二個端口是在leader掛掉時專門用來進行選舉leader所用。進入zookeeper-3.3.2/bin 目錄中,./zkServer.sh start啟動一個server,這時會報大量錯誤?其實沒什么關(guān)系,因為現(xiàn)在集群只起了1臺server,zookeeper服務(wù)器端起來會根據(jù) zoo.cfg的服務(wù)器列表發(fā)起選舉leader的請求,因為連不上其他機器而報錯,那么當(dāng)我們起第二個zookeeper實例后,leader將會被選 出,從而一致性服務(wù)開始可以使用,這是因為3臺機器只要有2臺可用就可以選出leader并且對外提供服務(wù)(2n+1臺機器,可以容n臺機器掛掉)。

- znode 可以被監(jiān)控,包括這個目錄節(jié)點中存儲的數(shù)據(jù)的修改,子節(jié)點目錄的變化等,一旦變化可以通知設(shè)置監(jiān)控的客戶端,這個功能是zookeeper對于應(yīng)用最重要的特性,通過這個特性可以實現(xiàn)的功能包括配置的集中管理,集群管理,分布式鎖等等。

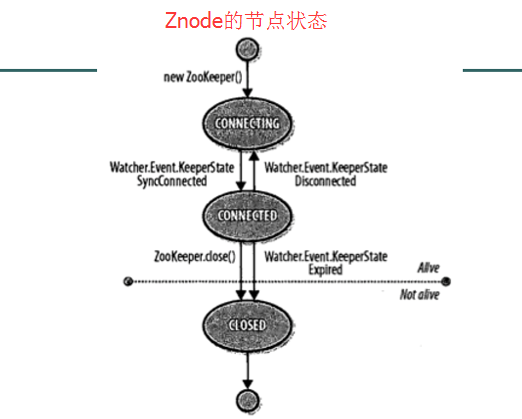
- znode 可以是臨時節(jié)點,一旦創(chuàng)建這個 znode 的客戶端與服務(wù)器失去聯(lián)系,這個 znode 也將自動刪除,Zookeeper 的客戶端和服務(wù)器通信采用長連接方式,每個客戶端和 服務(wù)器通過心跳來保持連接,這個連接狀態(tài)稱為 session,如果 znode 是臨時節(jié)點,這個 session 失效,znode 也就刪除了;持久化目錄節(jié)點,這個目錄節(jié)點存儲的數(shù)據(jù)不會丟失;順序自動編號的目錄節(jié)點,這種目錄節(jié)點會根據(jù)當(dāng)前已近存在的節(jié)點數(shù)自動加 1,然后返回給客戶端已經(jīng)成功創(chuàng)建的目錄節(jié)點名;臨時目錄節(jié)點,一旦創(chuàng)建這個節(jié)點的客戶端與服務(wù)器端口也就是 session 超時,這種節(jié)點會被自動刪除;臨時自動編號節(jié)點
至于,怎么刪除zookeeper的節(jié)點?
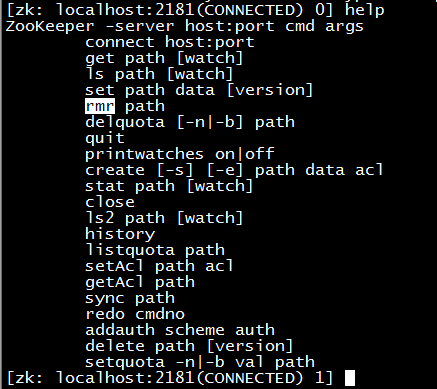

單節(jié)點
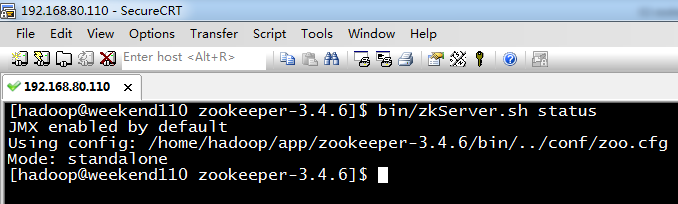
三節(jié)點
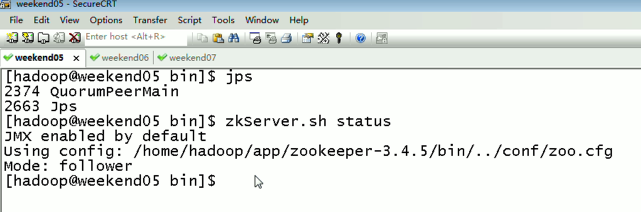
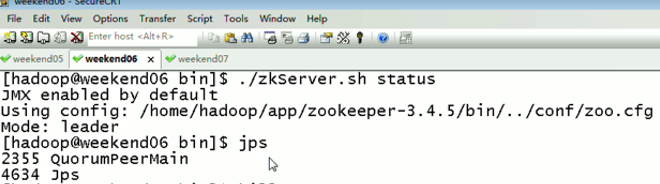
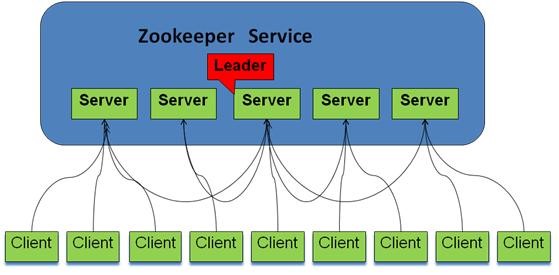



- 不存在部分?jǐn)?shù)據(jù)寫入成功或失敗的情形;

- 創(chuàng)建一個給定的目錄節(jié)點 path, 并給它設(shè)置數(shù)據(jù);判斷某個 path 是否存在,并設(shè)置是否監(jiān)控這個目錄節(jié)點,這里的 watcher 是在創(chuàng)建 ZooKeeper 實例時指定的 watcher,exists方法還有一個重載方法,可以指定特定的 watcher ;重載方法,這里給某個目錄節(jié)點設(shè)置特定的 watcher;刪除 path 對應(yīng)的目錄節(jié)點,version 為 -1 可以匹配任何版本,也就刪除了這個目錄節(jié)點所有數(shù)據(jù) ;獲取指定 path 下的所有子目錄節(jié)點,同樣 getChildren方法也有一個重載方法可以設(shè)置特定的 watcher 監(jiān)控子節(jié)點的狀態(tài)

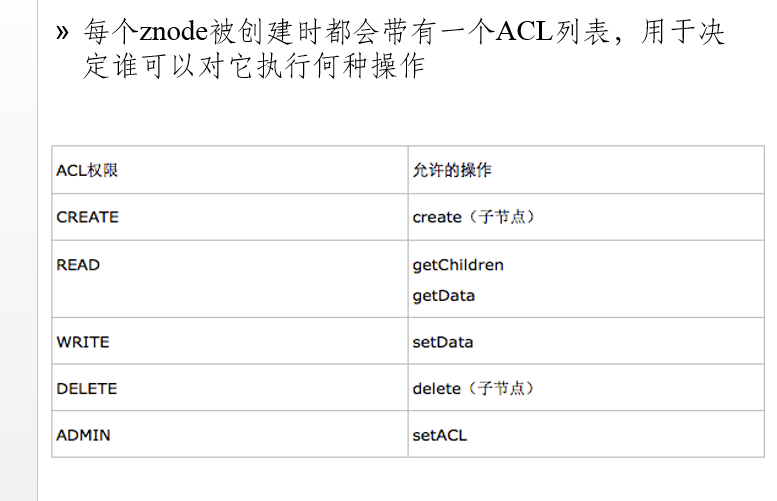
給 path 設(shè)置數(shù)據(jù),可以指定這個數(shù)據(jù)的版本號,如果 version 為 -1 怎可以匹配任何版本;獲取這個 path 對應(yīng)的目錄節(jié)點存儲的數(shù)據(jù),數(shù)據(jù)的版本等信息可以通過 stat 來指定,同時還可以設(shè)置是否監(jiān)控這個目錄節(jié)點數(shù)據(jù)的狀態(tài);客戶端將自己的授權(quán)信息提交給服務(wù)器,服務(wù)器將根據(jù)這個授權(quán)信息驗證客戶端的訪問權(quán)限;給某個目錄節(jié)點重新設(shè)置訪問權(quán)限,需要注意的是 Zookeeper 中的目錄節(jié)點權(quán)限不具有傳遞性,父目錄節(jié)點的權(quán)限不能傳遞給子目錄節(jié)點。目錄節(jié)點 ACL 由兩部分組成:perms 和 id。Perms 有 ALL、READ、WRITE、CREATE、DELETE、ADMIN 幾種 而 id 標(biāo)識了訪問目錄節(jié)點的身份列表,默認(rèn)情況下有以下兩種:ANYONE_ID_UNSAFE = new Id(“world”, “anyone”) 和 AUTH_IDS = new Id(“auth”, “”) 分別表示任何人都可以訪問和創(chuàng)建者擁有訪問權(quán)限;獲取某個目錄節(jié)點的訪問權(quán)限列表

- znode以某種方式發(fā)生變化時,“觀察”(watch)機制可以讓客戶端得到通知。可以針對ZooKeeper服務(wù)的“操作”來設(shè)置觀察,該服務(wù)的其他 操作可以觸發(fā)觀察。比如,客戶端可以對某個客戶端調(diào)用exists操作,同時在它上面設(shè)置一個觀察,如果此時這個znode不存在,則exists返回 false,如果一段時間之后,這個znode被其他客戶端創(chuàng)建,則這個觀察會被觸發(fā),之前的那個客戶端就會得到通知。
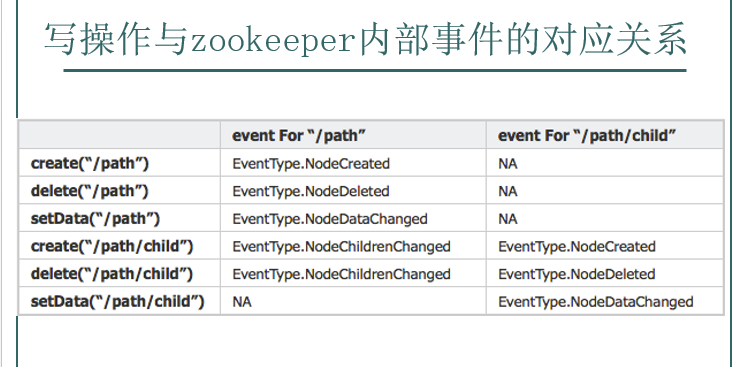
- znode以某種方式發(fā)生變化時,“觀察”(watch)機制可以讓客戶端得到通知。可以針對ZooKeeper服務(wù)的“操作”來設(shè)置觀察,該服務(wù)的其他 操作可以觸發(fā)觀察。比如,客戶端可以對某個客戶端調(diào)用exists操作,同時在它上面設(shè)置一個觀察,如果此時這個znode不存在,則exists返回 false,如果一段時間之后,這個znode被其他客戶端創(chuàng)建,則這個觀察會被觸發(fā),之前的那個客戶端就會得到通知。
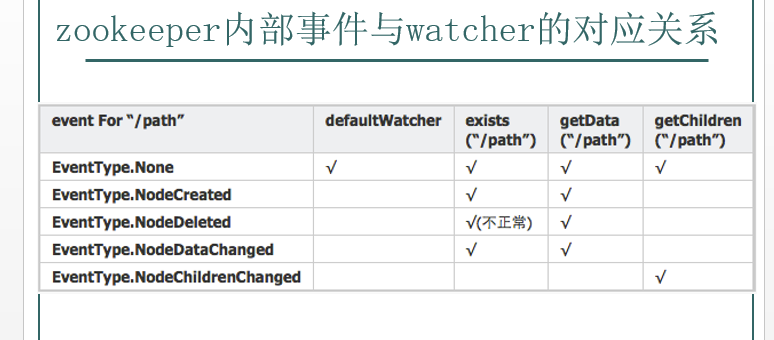
znode以某種方式發(fā)生變化時,“觀察”(watch)機制可以讓客戶端得到通知。可以針對ZooKeeper服務(wù)的“操作”來設(shè)置觀察,該服務(wù)的其他 操作可以觸發(fā)觀察。比如,客戶端可以對某個客戶端調(diào)用exists操作,同時在它上面設(shè)置一個觀察,如果此時這個znode不存在,則exists返回 false,如果一段時間之后,這個znode被其他客戶端創(chuàng)建,則這個觀察會被觸發(fā),之前的那個客戶端就會得到通知。
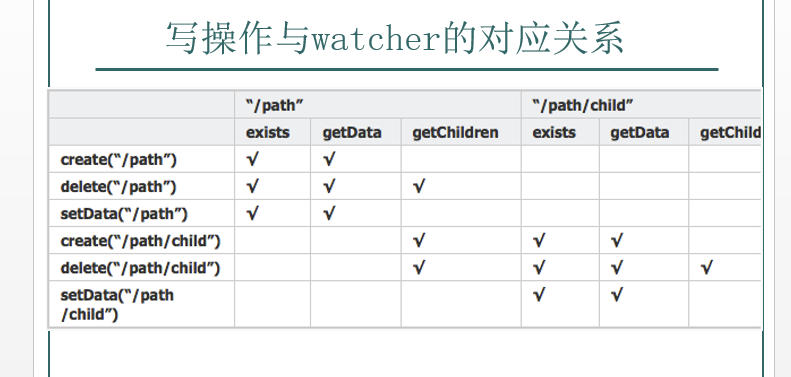
如果發(fā)生session close、authFail和invalid,那么所有類型的wather都會被觸發(fā)
NodeCreated:節(jié)點創(chuàng)建事件
NodeDeleted:節(jié)點被刪除事件
NodeDataChanged:節(jié)點數(shù)據(jù)改變事件
NodeChildrenChanged:節(jié)點的子節(jié)點改變事件

每個ACL都是身份驗證模式、符合該模式的一個身份和一組權(quán)限的組合
每個ACL都是身份驗證模式、符合該模式的一個身份和一組權(quán)限的組合

每個ACL都是身份驗證模式、符合該模式的一個身份和一組權(quán)限的組合

Broadcast模式極其類似于分布式事務(wù)中的2pc(two-phrase commit 兩階段提交):即leader提起一個決議,由followers進行投票,leader對投票結(jié)果進行計算決定是否通過該決議,如果通過執(zhí)行該決議(事務(wù)),否則什么也不做。

Broadcast模式極其類似于分布式事務(wù)中的2pc(two-phrase commit 兩階段提交):即leader提起一個決議,由followers進行投票,leader對投票結(jié)果進行計算決定是否通過該決議,如果通過執(zhí)行該決議(事務(wù)),否則什么也不做。

首先看一下選舉的過程,zk的實現(xiàn)中用了基于paxos算法(主要是fastpaxos)的實現(xiàn)。具體如下;此外恢復(fù)模式下,如果是重新剛從崩潰狀態(tài)恢復(fù)的或者剛啟動的的server還會從磁盤快照中恢復(fù)數(shù)據(jù)和會話信息。(zk會記錄事務(wù)日志并定期進行快照,方便在恢復(fù)時進行狀態(tài)恢復(fù))

選完leader以后,zk就進入狀態(tài)同步過程。
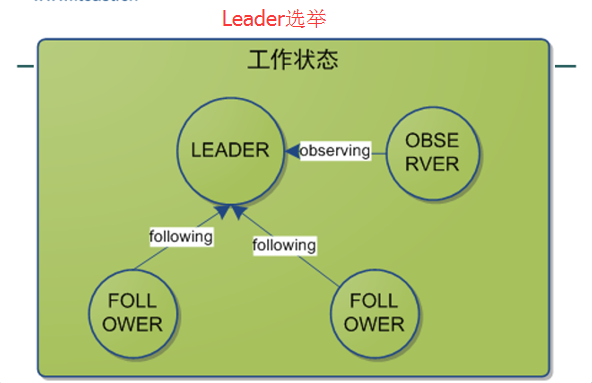
Observing: 觀察狀態(tài),這時候observer會觀察leader是否有改變,然后同步leader的狀態(tài);
Following: 跟隨狀態(tài),接收leader的proposal ,進行投票。并和leader進行狀態(tài)同步
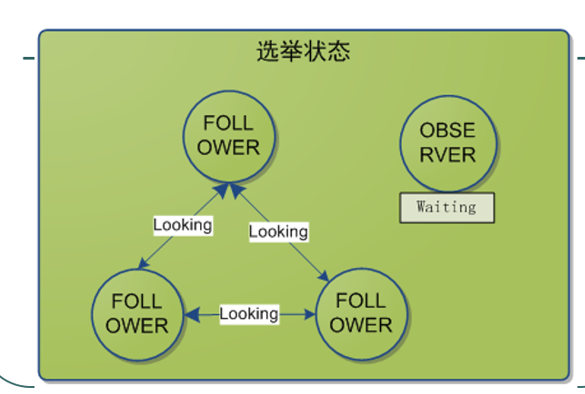
Looking: 尋找狀態(tài),這個狀態(tài)不知道誰是leader,會發(fā)起leader選舉;
Leading: 領(lǐng)導(dǎo)狀態(tài),對Follower的投票進行決議,將狀態(tài)和follower進行同步




比如Dubbo,


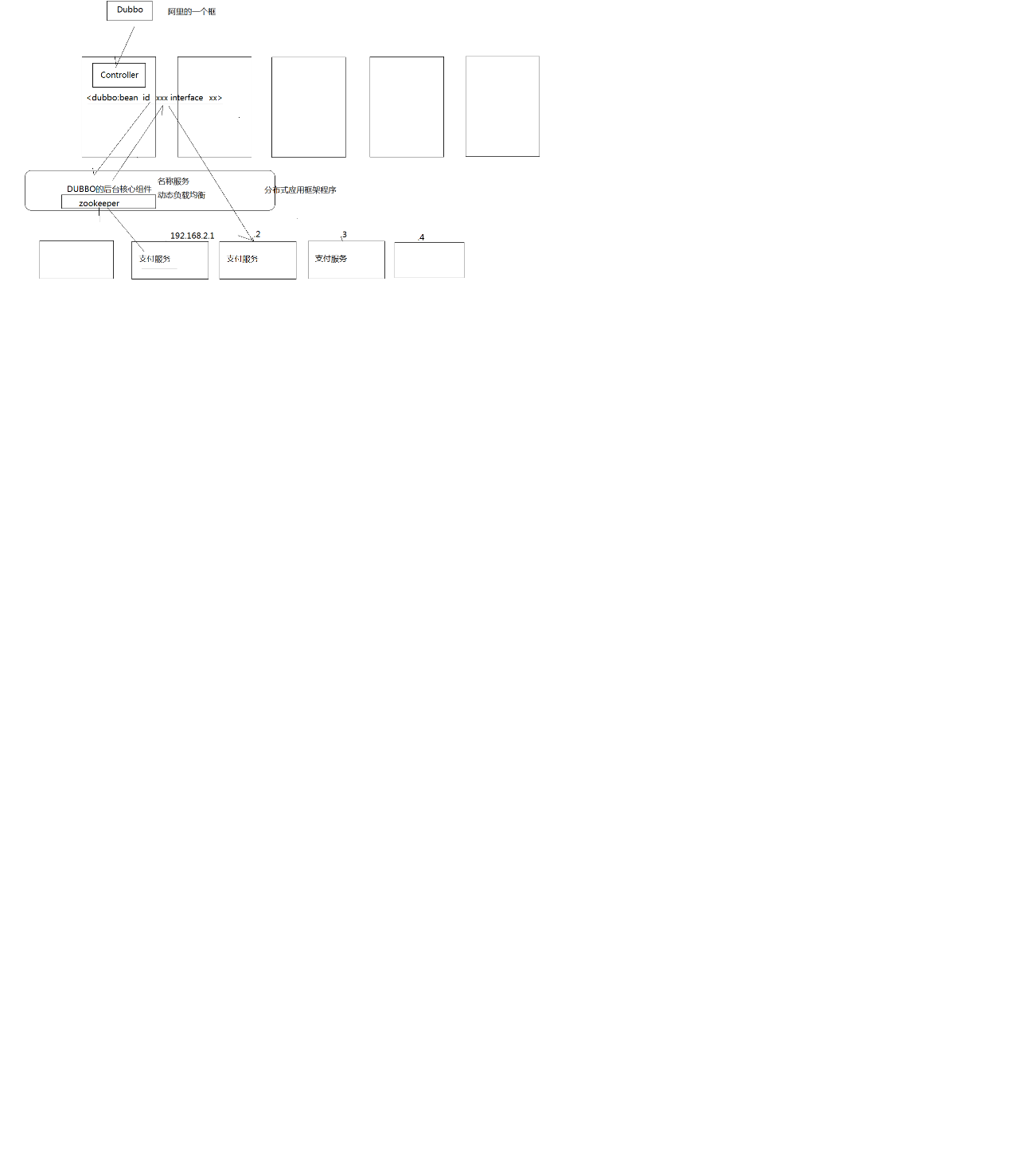
底層可以任意加,上層不需改。
它這個就是一個典型的Dubbo框架,底層可以任意加,上層不需改

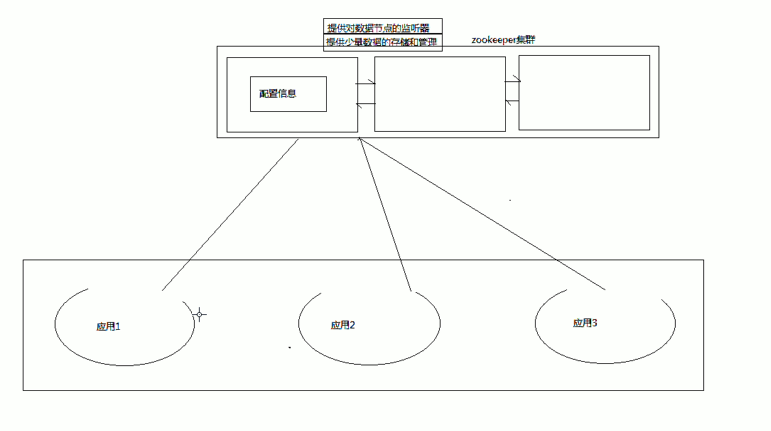
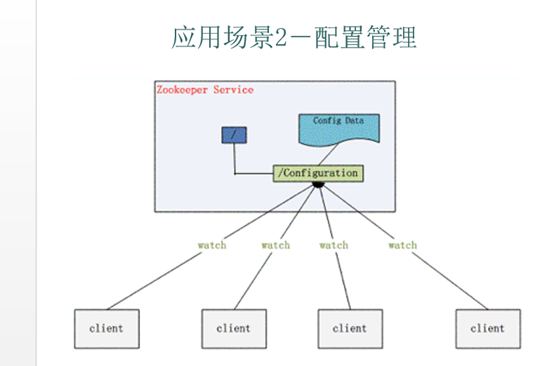
Zookeeper很容易實現(xiàn)這種集中式的配置管理,比如將APP1的所有配置配置到/APP1 znode下,APP1所有機器一啟動就對/APP1這個節(jié)點進行監(jiān)控(zk.exist(“/APP1″,true)),并且實現(xiàn)回調(diào)方法 Watcher,那么在zookeeper上/APP1 znode節(jié)點下數(shù)據(jù)發(fā)生變化的時候,每個機器都會收到通知,Watcher方法將會被執(zhí)行,那么應(yīng)用再取下數(shù)據(jù)即可 (zk.getData(“/APP1″,false,null));

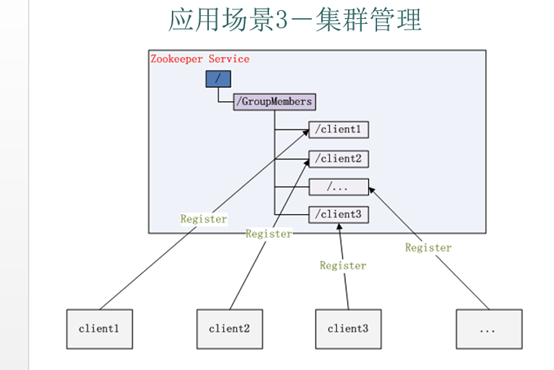
應(yīng)用集群中,我們常常需要讓每一個機器知道集群中(或依賴的其他某一個集群)哪些機器是活著的,并且在集群機器因為宕機,網(wǎng)絡(luò)斷鏈等原因能夠不在人工介入的情況下迅速通知到每一個機器。Zookeeper同樣很容易實現(xiàn)這個功能,比如我在zookeeper服務(wù)器端有一個znode叫/APP1SERVERS,那么集群中每一個機器啟動 的時候都去這個節(jié)點下創(chuàng)建一個EPHEMERAL類型的節(jié)點,比如server1創(chuàng)建/APP1SERVERS/SERVER1(可以使用ip,保證不重 復(fù)),server2創(chuàng)建/APP1SERVERS/SERVER2,然后SERVER1和SERVER2都watch /APP1SERVERS這個父節(jié)點,那么也就是這個父節(jié)點下數(shù)據(jù)或者子節(jié)點變化都會通知對該節(jié)點進行watch的客戶端。因為EPHEMERAL類型節(jié) 點有一個很重要的特性,就是客戶端和服務(wù)器端連接斷掉或者session過期就會使節(jié)點消失,那么在某一個機器掛掉或者斷鏈的時候,其對應(yīng)的節(jié)點就會消 失,然后集群中所有對/APP1SERVERS進行watch的客戶端都會收到通知,然后取得最新列表即可。
Zookeeper 如何實現(xiàn) Leader Election,也就是選出一個 Master Server;另外有一個應(yīng)用場景就是集群選master,一旦master掛掉能夠馬上能從slave中選出一個master,實現(xiàn)步驟和前者一樣,只是機器在啟動的 時候在APP1SERVERS創(chuàng)建的節(jié)點類型變?yōu)镋PHEMERAL_SEQUENTIAL類型,這樣每個節(jié)點會自動被編號

Zookeeper 如何實現(xiàn) Leader Election,也就是選出一個 Master Server;另外有一個應(yīng)用場景就是集群選master,一旦master掛掉能夠馬上能從slave中選出一個master,實現(xiàn)步驟和前者一樣,只是機器在啟動的 時候在APP1SERVERS創(chuàng)建的節(jié)點類型變?yōu)镋PHEMERAL_SEQUENTIAL類型,這樣每個節(jié)點會自動被編號

Zookeeper 如何實現(xiàn) Leader Election,也就是選出一個 Master Server;另外有一個應(yīng)用場景就是集群選master,一旦master掛掉能夠馬上能從slave中選出一個master,實現(xiàn)步驟和前者一樣,只是機器在啟動的 時候在APP1SERVERS創(chuàng)建的節(jié)點類型變?yōu)镋PHEMERAL_SEQUENTIAL類型,這樣每個節(jié)點會自動被編號

Zookeeper 如何實現(xiàn) Leader Election,也就是選出一個 Master Server;另外有一個應(yīng)用場景就是集群選master,一旦master掛掉能夠馬上能從slave中選出一個master,實現(xiàn)步驟和前者一樣,只是機器在啟動的 時候在APP1SERVERS創(chuàng)建的節(jié)點類型變?yōu)镋PHEMERAL_SEQUENTIAL類型,這樣每個節(jié)點會自動被編號




 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號