圖表的分類法:解耦數據和圖表類型
HKUST 25 Fall COMP 6411D Data Visualization 課堂筆記
可視化的可視化
當我第一眼看到 slide 中“chart taxonomies” ,我有兩個反應:
- 圖表數量也太多了
- 這個分類方式并不是很直觀,Comparsion / Relationship / Distribution / Composition 這些術語都是一些很高層的抽象概念,并且分類本身比較繁瑣,比如 Qlik 的分類是一個不規則的樹結構,層層分類。并且分類方式并不唯一,比如可以看到 Bar Chart 在 Qlik 中出現多次
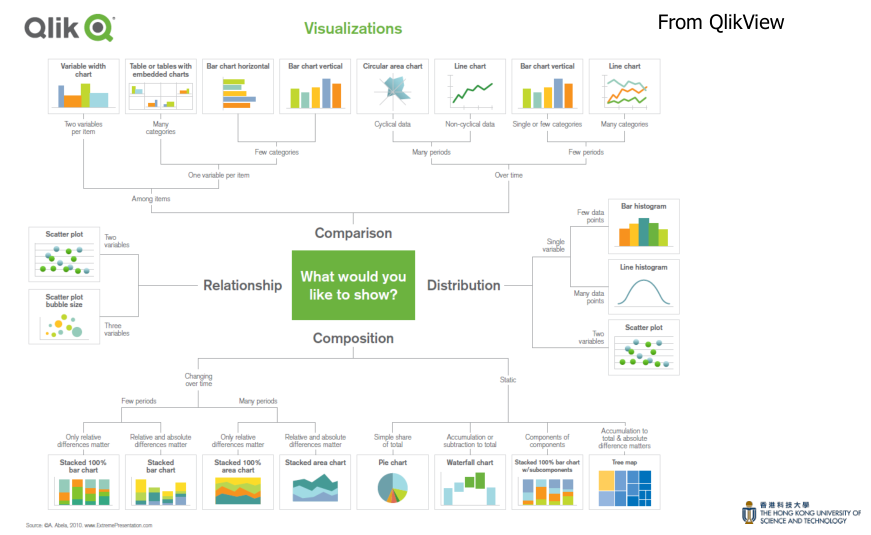
是否能夠找到一個更加直觀、客觀、唯一的分類方式?
25-象限分類圖
我對圖形的分類通過三個性質判斷
- 數據是“自變量”還是“因變量”
- 數據是可量化的 (value) 還是不可量化的 (label)
- 自變量/因變量的數量
比如 Single Line plot 就是 “單個自變量 value 到單個因變量 value” 的一種圖像
可視化必然包括表達者和觀眾主觀性
所謂“自變量”“因變量”并非出自數學函數的定義,而是出自觀眾的角度定義,大致來說“自變量”是觀測前已知的,是觀眾的出發點,是切入數據的角度;而“因變量”是觀測前未知的,是觀眾想要知道的,是觀測的結果。一種簡單的判斷方式是自變量可以展示在圖像的標題中,“1-12 月英偉達股價變化”,只看標題已經大概知道我們的自變量可能是月份,包含一月、二月、...,而具體股價是多少需要查看圖表才能知道
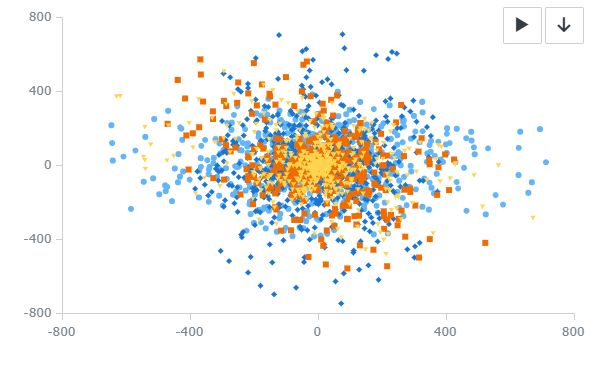
當然以上定義也是一種主觀定義方式,即使是同一張圖,觀眾也可能有多種觀測的角度,比如如下的 Dot Chart,可能存在多個解釋角度:
- 我可以將 x-y axis 當作兩個自變量,即二維空間作為觀測角度,去觀測不同顏色/形狀的 label 在二維空間的分布,此時是 “兩個自變量 value 到兩個因變量 label” 的圖像;
- 同樣也可以將 label 看作自變量,觀察數據在二維空間的未知信息,此時是 “兩個自變量 label 到兩個因變量 value” 的圖像
- 分布這個概念是一個高級的抽象概念,我還可以說以二維空間作為觀測角度,去觀測不同顏色/形狀的 label 在二維空間的“數量”(盡管當點的數量很多時很難直觀從 dot 圖上得到具體的數值,只能直觀感知個大概), 此時是“兩個自變量 value 到三個因變量,兩個 label 一個 value” 的一種圖像
并且不僅和觀眾相關因人而異,和數據的具體數值也相關。當然如果存在切入角度較多的問題,也說明此時表達著應該盡可能調整作圖方式確保呈現信息唯一確定。
數據是可量化/不可量化的同樣存在這個問題,比如連續、密集的時間,毫無疑問是 value;是男性還是女性,毫無疑問是 label;那月份呢,似乎可以作為 label 寫成一月、二月、...,也可以認作是以一個月為粒度的時間 value,隨著可量化的數值離散化稀疏化,value 和 label 的界限會愈加模糊。
表達者/觀眾的主觀性必然導致無法完全客觀分類,但本文盡量朝著這個方向呈現。
分類結果
我根據前文提到的三個性質,將圖表分為 5x 5=25 個種類,并將部分在課程中介紹過的表格放入對應象限中:

大致來說,此圖左下角 “Single 自變量-Single 因變量” 是最直觀、信息量最少的圖表,左上、右下是信息量較多的圖表,而右上是信息量最多的圖表。其中 Box 圖表因變量包含 value 和 label,其中 label 指的是“是否是 Outliner"。此類分類方法具有局限性,僅適用于表格類數據,而并不適用樹或者圖結構。
BTW,“25-象限分類圖” 在 “25-象限分類圖”中的位置屬于 “單 label (圖的種類)-多 label(自變量-因變量) ”
自動數據可視化
給這種分類方法設想了一個假想應用場景,在科研實驗/寫文章繪制圖表時,我總要畫一些時間思考到底使用什么圖表,特別是對于有復雜變量的系統在做大量實驗時,我需要花相當一部分時間思考從哪個角度觀測系統找到相關性,然后再畫一些時間思考用什么圖表展示,最后告訴 Chat GPT 讓他完成對應的 matplotlib 代碼,如果不直觀,可能還要多想幾種呈現方式。
這種分類方法解耦了數據結構和圖表之間的依賴關系,也許可以實現一個 Chart Compiler,輸入數據并指定數據的分類,其就能自動識別找到有幾種圖表符合,自動返回幾種不同的圖表給用戶評估。這或許能夠節省做實驗的時間
老師推薦了來自 UW Interactive Lab [1] 的工作 voyage[2] 和 dacro[3] 工作,該方向叫做 automated visualization design。其中將數據和圖像解耦只是第一步,確認數據可以允許由什么 chart 呈現 (hard constraints),而 hard constraints 所允許的 design space 中仍存在大量的選項,第二步則是通過某種需要某種“評分機制”量化排序找到最佳的圖表。這面臨著兩個問題:
- Design space 非常大
- 可視化判斷標準相當主觀,難以判斷
靠用戶收集的數據僅僅只是占 design space 中一小部分,所以“評分機制”需要某種泛化性。 voyager 的思想主要是用預先設定規則啟發式搜索,而 draco 的方法采用了 learning based 方法嘗試學習泛化判斷標準。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號