數據依賴(三):序列語言下的存儲一致性
DeepSeek ISCA 2025 [1] 6.4 小節中提到無論 load/store 語義的 scale-up 網絡,還是 message 語義的 scale-out 網絡,維護一致性都會明顯增加額外的通信開銷。期望一種既需要程序員通過 acquire/release 等語義編程保證一致性,硬件上也不會增加太多額外開銷的方法。
序列性:編程語言隱式歸納偏置
hart(hardware thread) 含義類似邏輯核,在描述硬件資源時用 hart 而不是 core 更加準確,因為可以通過比如超線程等方法將一個物理 core 掰開成兩個邏輯 core
多線程為何需要程序員維護一致性呢?先前亂序執行相關 blog [2][3] 已闡述 hart 的順序性問題可以依靠編譯器解析、硬件調度保證,為什么現在又要程序員來維持順序性呢?
程序運行的實例叫做進程,而如果程序發掘并行度則是多線程程序,線程之間的調度靠 OS 處理。比如程序 A 有 16 線程,程序 B 有 16 線程,計算機只有 8 個 hart 同時只能運行 8 線程,靠 OS 調度運行哪些線程,既可能是一邊運行 4 個 A、4 個 B,也可能是 8個 A 8 個B 時分復用交替執行。由于用戶運行時會執行哪些進程非常復雜,且程序之間一般相對獨立,所以進程采取簡單的內存空間隔離策略;而同一個進程的線程內部往往存在數據局部性關系和耦合關系,(來源同一個進程之間的)多線程則是共用同一個內存空間。
既然多線程程序都是編譯器可見的,為什么還需要程序員手動維護,而不能類似單線程程序自動由編譯器解析?反過來說,單線程程序不需要顯式維護同步依賴關系才奇怪呢,用變量隱式構建依賴關系是天然的“語法福利”。序列性的單線程程序存在先后關系,利用先后關系便可解析出某變量讀寫的前后關系(數據依賴圖)。 維持解析處出來的讀寫關系不變,便能從一種序列變換成另一種順序序列。而多線程不存在隱式的先后關系,也就無法利用先后關系指定依賴,這便是 consistency 問題。
構建單線程程序時程序員也隱式地通過調用同變量代碼的先后順序構建了依賴關系,而多線程程序則需要顯式說明,也許是順序性符合人腦對文本處理習慣所以編程代價感受更低。用一副圖說明編程模型和運行的關系:
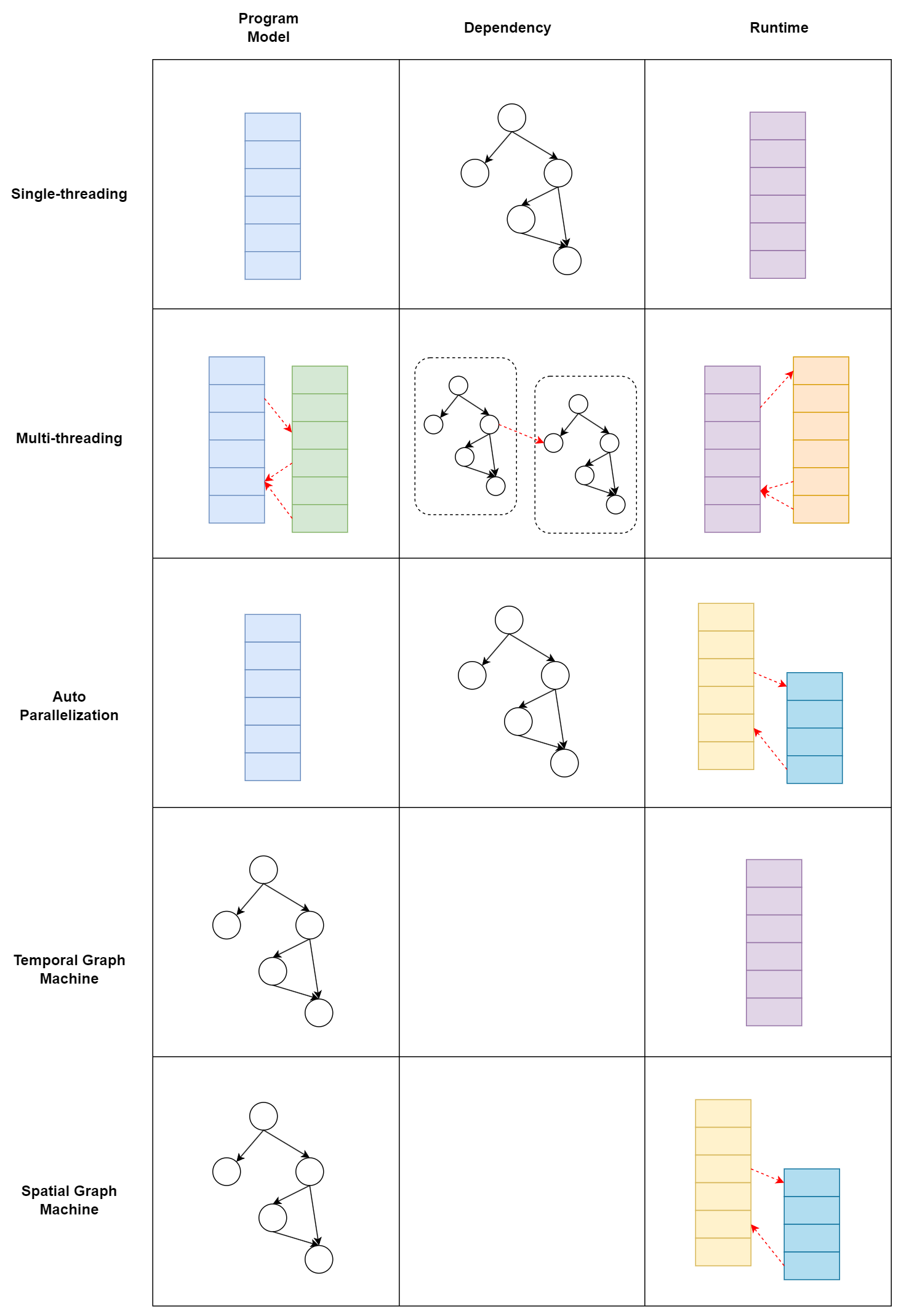
無論用什么編程模型本質都是描述一張數據依賴圖。也許因為編譯的 NP 問題或者歷史路線慣性,將圖的部分特性作為偏執歸納到了編程模型從而產生編程模型的差異區分,比如單線程模型比較親和順序性強的程序,多線程模型比較親和大部分并行、小部分依賴的程序(如 SIMT),而如果程序結構十分復雜,則需要一個圖親和的編程模型。同時,任何編程模型都是在表達數據圖,理論一張圖可以用多種編程模型表示,不一定只有顯式調用多線程庫才有并行性,比如編譯時開啟 auto-parallelization 可以將常見的遞歸、循環等并行結構編譯成多線程執行。
多線程編程也可以單 hart 機器時分復用執行,但一般線程數量都要求少于機器 hart 數量。不討論這種情況。
一致性:同步的代價
了解為什么多線程程序需要手動同步,接下來看看實現同步需要什么原語和代價。
#include <iostream>
#include <thread>
int data = 0;
bool flag = false;
void writer_thread() {
data = 42; // 寫操作 1
flag = true; // 寫操作 2
}
void reader_thread() {
while(!flag) {}; // 讀操作 1
std::cout << "Data: " << data << std::endl; // 讀操作 2
}
int main() {
std::thread writer(writer_thread);
std::thread reader(reader_thread);
writer.join();
reader.join();
return 0;
}
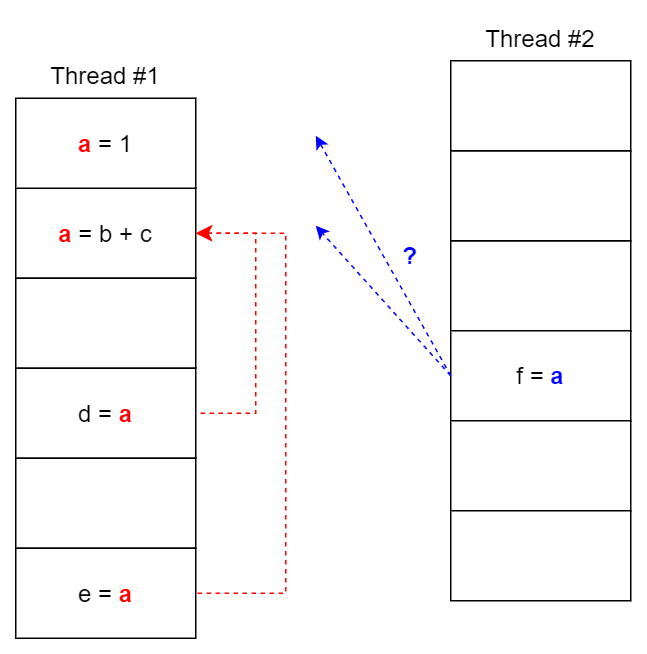
reader_thread 依賴于 flag 判斷 write_thread data 是否 store,但編程語言 ISA 的粒度不足以讓 flag 代表 data store 的狀態,兩者是分布執行。從單線程順序性來看, flag 賦值在 data store 之后,flag 賦值是 data store 的充分條件,但跨線程之間的數據依賴關系無法納入本線程分析,在 write_store 線程看來,data 和 flag 之間沒有用數據依賴,因此可能存在交換順序的情況,破壞了充分條件。
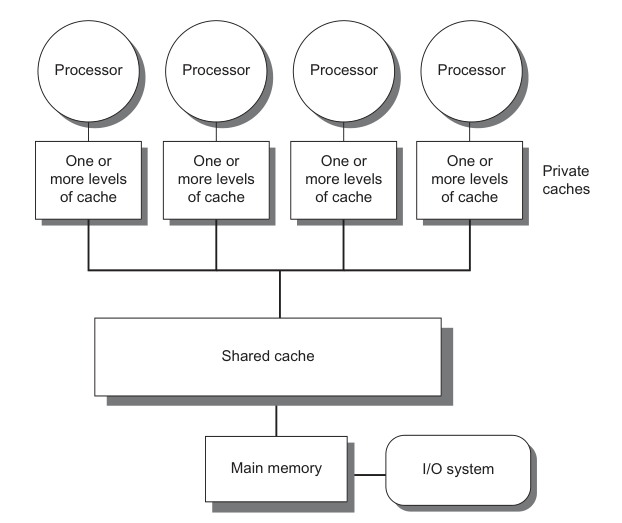
數據依賴關系通過共同變量定義,主流 CPU / GPU 一般是如下圖的 SMP (Symmetric multiprocessing)結構,共同變量的訪問實際上通過所有 hart 可見的 shared Cache / main memory 實現,hart register 和 main memory 之間交換順序一般定義為 load /store [4],所以控制代碼的順序和控制變量 load/store 的讀寫順序等價,這稱作內存序(memory order)。
我們此處關注的順序并非是流水線概念的順序執行(in-order),而是不僅當執行到下一個內存操作時,上一個內存操作必須完成,一個指令從發射(issue)到提交(commit)的完整周期。如果兩個連續的內存指令,意味著整條流水線的停頓,即對內存指令之間是原子的,而允許內存指令與其他指令并行。
- 第一種策略是讓程序嚴格按照編程順序執行。這種“寧愿錯殺一百,不愿放過一個”方案雖然保證了正確性,但在如今高 ILP 處理器上可能會帶來不可忽略的副作用,比如 X86 是強內存一致性模型(Sequential Consitency),每個線程內嚴格按照編程順序執行,以上代碼直接在 X86 上執行結果仍然正確。對內存模型有非常多種類的實現標準,此處介紹可詳見量化體系架構第五章。為了保證多線程間的一致性,反而使得單個線程內的調度空間受限,這個結論非常有意思;
- 第二種策略則是讓 data 和 flag 語義相同,flag 賦值成為 data 的充要條件,不存在部分執行的中間狀態,用互斥鎖將 data 和 flag 的存儲鎖住,其他 thread 只看到同時沒發生和同時發生的兩種狀態,互斥鎖也可以看作一種宏觀的原子操作,;
- 第三種策略則是針對性地維護語句順序,只關注保證正確性的順序部分。內存序通過設置 memory barrier / fence 限制跨線程的順序。
橫向和縱向一致性
具體什么是 memory barrier [5]? 什么又是 acquire/release 語義?讀了 cpp reference [6] 還是迷迷糊糊。調研精力有限,這里給出自己的猜測。
release/acquire 通過保證 release 之前的所有對 read & write 操作都不會在 acquire 之后的 read & write 操作之后。如下圖,通過 release-acquire,可以保證 #11 在 #00 之后執行。從圖中可見,實現其需要完成兩個過程,縱向線程識別 fence 前后語句控制讀寫一致性;橫向同步匹配 release-acquire 的 fence,只有二者同時存在語義有效,這應當通過某種共享變量實現。

縱向:RISCV 中關于屏障指令 FENCE 和 FENCE.I 的介紹很多,而實現分析缺幾乎難以找到[7]。調研時間有限這里簡單猜測,FENCE 包含兩個操作數:前繼和后繼指令的內存操作類型,每個操作數是 r/w/rw 三者之一。猜測設置該指令后會在decode 階段設置一個 flag,當同時滿足 RS 中還存在前繼指令,并且 decode 遇到后繼指令時,阻塞流水線。
橫向:而關于原子操作在指令上往往提供 Read-Modify 原語。Read modify 原語重要性來自同步變量往往需要經過查詢-控制判斷-更新狀態的流程。讀和寫在 ISA 中分離,并且主存的訪問往往涉及多個周期。從全局的視角共享變量的修改應當是一致的,而每次讀都會在 hart 內產生副本,若在 Read-Modify 的期間如果有多個讀取同時發生,則會造成不一致的多個副本同時存在。
符合一致性的編程涉及硬件內存模型以及處理的具體問題。還是以上面例子舉例,僅僅需要維護 write_thread 線程內 data 和 flag 的縱向順序,而無需關心全局變量 flag 的原子性。
DeepEP 同步實踐分析
GPU 被認為是弱內存模型,需要通過顯式同步維護一致性關系。CUDA 層面最常見的便是 __syncthreads() 同步 block 內部的 threads。
以 Deep EP [8] 庫舉例,庫中最常用機器間通信同步是 barrier_device() , 其定義為:
template <int kNumRanks>
__forceinline__ __device__ void
barrier_device(int **task_fifo_ptrs, int head, int rank, int tag = 0) {
auto thread_id = static_cast<int>(threadIdx.x);
EP_DEVICE_ASSERT(kNumRanks <= 32);
if (thread_id < kNumRanks) {
atomicAdd_system(task_fifo_ptrs[rank] + head + thread_id, FINISHED_SUM_TAG);
memory_fence();
atomicSub_system(task_fifo_ptrs[thread_id] + head + rank, FINISHED_SUM_TAG);
}
timeout_check<kNumRanks>(task_fifo_ptrs, head, rank, 0, tag);
}
memory_fence() 的定義為對 PTX 系統級 acquire & release fence 包了一層, 此 fence 同時是 acquire 也是 release:
__device__ __forceinline__ void memory_fence() {
asm volatile("fence.acq_rel.sys;":: : "memory");
}
scale-up 可以通過 NV-Link 處理,scale-out 則需要顯示調用 GPU 處理 RDMA 同步。這里通過 thread_id < kNumRanks <= 32 顯式指定第一個 wrap SM0 負責處理機器間通信 [9],每個 thread 記錄一個其余機器信息。
繼續檢查 timeout_check() 來理解共享變量的含義:
template <int kNumRanks>
__device__ __forceinline__ bool not_finished(int *task, int expected) {
auto result = false;
auto lane_id = threadIdx.x % 32;
if (lane_id < kNumRanks)
result = ld_volatile_global(task + lane_id) != expected;
return __any_sync(0xffffffff, result);
}
template <int kNumRanks>
__forceinline__ __device__ void
timeout_check(int **task_fifo_ptrs, int head, int rank, int expected, int tag = 0) {
auto start_time = clock64();
while (not_finished<kNumRanks>(task_fifo_ptrs[rank] + head, expected)) {
if (clock64() - start_time > NUM_TIMEOUT_CYCLES and threadIdx.x == 0) {
printf("DeepEP timeout check failed: %d (rank = %d)\n", tag, rank);
trap();
}
}
}
可見,機器 i 上的第 j 個 thread 負責檢查 task_fifo_ptrs[i] + j + head 位置的變量,也就是 task_fifo_ptrs[i] 存儲的是機器 i 對其余機器的同步信息,反推 fence 之前的系統級原子加法 atomicAdd_system 是先將自己的信息添加,然后 fence 全局同步添加操作,此時得到一個全是 1 的 kNumRanks x kNumRanks 的矩陣,然后依次執行 atomicSub_sytem 再將別人那里對自己的狀態減少。相當于每個機器都是平權的,如果有某個機器掛了,其余所有運行良好的機器都應該能夠檢測出來。
不過如果機器掛了在 fence 階段是否會出錯呢?這個坑留到以后再填吧。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號