互聯的代價:量化互聯網絡的面積開銷
無論片內還是片外訪存,存儲器的訪存代價非常大 [1]。因此有非常多的工作放眼在減少 memory access 以提升系統能耗和表現。我將減少訪存歸類為三種方法:
- 發掘數據復用。如矩陣乘法中輸入某個矩陣的某一行/列要多次復用讀入,依次可以讀取一次之后利用先前讀取的結果,這一類方法依賴于算法的數據復用特征,復用度越高意義越大。軟件代表工作有 timeloop,硬件代表工作有 systolic array 復用輸入輸出,各種加速器中廣泛存在的 accumulator 復用輸出中間變量。
- Fused Operation。每次操作都需要讀入數據并輸出數據,計算過程中有大量中間變量生成以及相應的讀寫操作。把相鄰操作作為一個整體,將內部中間變量直接通過執行單元之間數據通路或者較低層次的 memory 就可以避開高層次高代價的 memory access。其本質也可以算作一種對中間變量讀/寫的一種數據復用,軟件代表工作有各種加速庫 fusion 算子,硬件代表工作有 DIANNAO 最早提及處理的執行 pipeline,MAC 單元后接 activation Speical Unit 成為加速器基操。
- Recomputaion。本質來自存儲空間有限和某些變量生存周期較長之間的矛盾,對計算圖某個節點重復執行以節約存儲空間進而減少 memory access。這種范式由于對編譯器改動較大暫時沒有看到比較系統的工作。
這三種范式編譯器開發難度依次增大,所有程序本質上都是數據依賴圖,但 NP 問題優化算力有限,需要分而治之劃分為多個子圖,或者稱算子和 kernel 進行局部優化。數據復用大致上沒有改變 kernel 的范圍優化難度相對較低,因此目前工作分析已經相對完備。而第二種擴大了 kernel 的范圍,優化難度提高,無論軟件或是硬件目前主要靠人力維護算子庫或者依賴硬件架構師的經驗。
但此類硬件工作本質上也和寫算子差不多,依靠人為經驗確定結構固化在電路上。最近也有很多新型的 spatial accelerator 選擇在更通用的互聯數據流架構上發力 [2] [3],一來支持更加通用的加速優化,二來將硬件設計的人力轉移到軟件編譯器層面,降低迭代周期和成本。
通用性架構往往需要引入各類互聯網絡以及相應的控制流,通路的 overhead 是否會超過優勢?如果優勢立得住的,那么又如何在參數空間取值以 trade-off?額外開銷反映在 both 硬件和軟件,本文嘗試從硬件視角建立一個簡單 baseline 比較開銷。
軟件和硬件 Baseline
考慮如下偽代碼
D1 = SiLU(D0)
D2 = Exp(D1)
這兩種在 SambaNova 總結的操作流類型中屬于最簡單的 element-wise map 操作[3:1],數據通路較為簡單利于展開分析。
考慮我們的硬件系統擁有一個存儲 SRAM ,以及兩個定制化的 SiLU 和 Exp 執行單元,所有執行單元都是純組合邏輯。另外一個先驗是現有的大部分網絡單層算子的維度遠遠大于硬件規格,即使一個算子也要拆分多個周期完成,比如 SiLU 算子在時間上分別執行 SiLU#0、SiLU#1、SiLU#2 ... 完成,或者說代碼中的循環是必然的 。我們假設 SRAM 和執行單元的數據寬度都是一致。
硬件執行表現分析
考慮傳統硬件通路設計,即執行單元之間不存在直接通路,所有的數據交互都需要通過 SRAM 完成。比如 D1 數據就需要先從 SiLU 單元寫入 SRAM,然后 exp 單元再從 SRAM 中讀出。假設每個算子維度叫做寬度,多個算子連接叫做深度,執行上有兩種策略:
- 深度優先(DF)。SiLU #0, Exp#0, SiLU #1, Exp#1。
- 寬度優先(BF)。SiLU #0, SiLU#1, Exp#0, Exp#1。
Single Port
假設 SRAM 是 Signle Port,此時 SRAM 的接口帶寬全部占滿,無論 DF 還是 BF 都會卡在 SRAM 上結果一致。

Dual Port - BF
我們嘗試給 Memory 添加 dual port ,以同時支持讀寫。因為本身讀寫操作帶有延時,從讀取到寫入需要兩個周期完成,為避免數據依賴導致的序列化延時,采用 BF 策略。
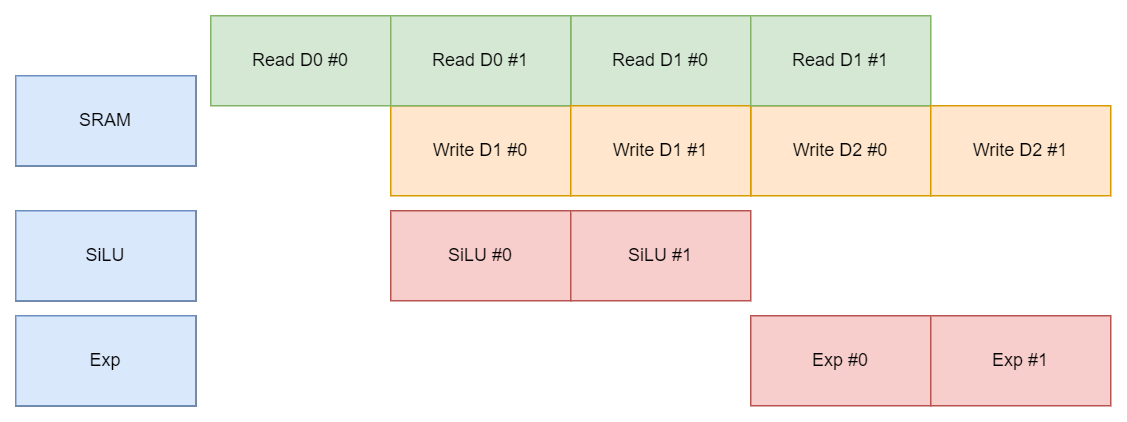
總體延時減少了,但除去啟動推出階段(Prologue/Epilogue),穩定階段(Steady)SRAM 的吞吐仍然被占滿而執行單元 utilization 較低,是否可以進一步提高 SRAM 吞吐減少延時。
Multi-bank
SRAM 可大致看為由 6T 存儲陣列以及讀入讀出接口組成,我們分析互聯代價需要保持存儲 capacity 不變而改變接口帶寬。有三種方法:
- 直接添加 port 的數量。比如 single port 到 dual port,好處是多個 port 共用同一塊存儲空間,可以真正意義上 random access,但存在電路上限,一般 PDK 提供類型還是以 1~2 個 port 為主;
- 減少 SRAM 深度增加寬度。但注意為了保持多個 EU 吞吐滿,SRAM 的寬度是大于單個 EU 的寬度的。需要在電路上引入一些變寬 FIFO 來轉換數據寬度,控制流復雜且適用場景有限(我嘗試繪制了這種情況的 pipeline,不會減少太多 latency);
- 縮小每個 bank 的深度,增加 bank 數量。這里 bank 的含義是邏輯上每個 bank 的地址都有相應的電路獨立控制,而非物理上生成多個 bank 然后用統一的地址邏輯管理拼成一個統一的邏輯存儲。這種方法可以充分利用增加的帶寬,但對數據的 memory layout 有一定要求,否則可能導致 serialized 降低性能,可見 ThunderKittens [4] 對 GPU L2 Cache memory layout 的分析。
為了突出穩定階段的變化,繪制更多循環次數的示意圖。

通過添加 bank 將存儲帶寬再次翻倍后,穩定階段 SRAM 和執行單元的 utilization 都達到 100%,大大降低了延時。另外僅當 serialize 嚴重時執行有先后 DF-BF 之分,這里單元全部跑起來沒有區分邊界。
Dataflow
假設 SiLU 和 Exp 單元之間存在數據通路,無需通過 SRAM 。
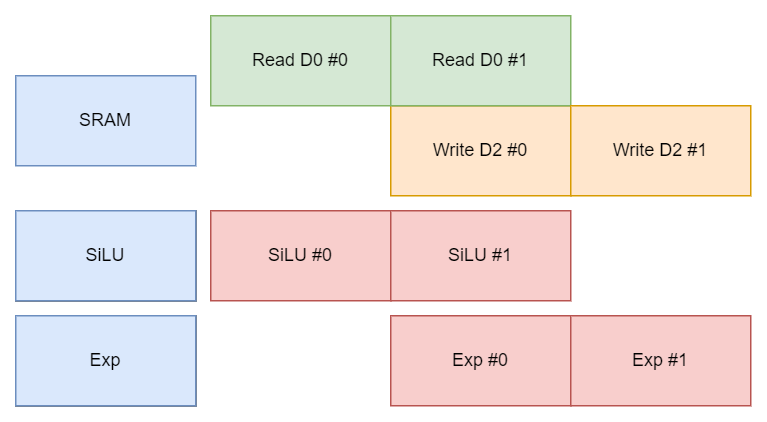
僅用 Dual Port 便實現了穩定階段執行單元 100% 的 utilization。
代價是什么?
Multi-bank 和 Dataflow 都實現了 100% 的 utlization,那么代價是什么呢?Multi-bank 相比 Dataflow 多了一倍帶寬,需要額外的讀寫電路支持,并且由于劃分邏輯 bank 需要特殊的 memory layout 設計;Dataflow 為了支持執行單元之間的通信則需要額外的互聯網絡。
由于程序上 Exp 在 SiLU 之后執行,所以僅需從 SiLU 到 Exp 的通路即可實現,但電路需要保證通用性,理論上支持任意互聯則要將所有可能的輸入輸出端口之間建立通路,比如 SiLU->Exp, Exp->SiLU,Exp->Exp,SiLU->SiLU, Buf->SiLU, Buf->Exp, SiLU->Buf, Exp->Buf。
為了泛化分析,假如系統中存在著 N 個這樣的 map element-wise 單元以及一個 dual port SRAM,那么互聯網絡由 N 個可以選擇 N 輸入的 MUX 組成。而 multi-bank 系統則需要保證有 N 個 bank。量化分析需要比對添加 bank 和添加互聯網絡的邊緣成本。
Bank 的邊緣成本
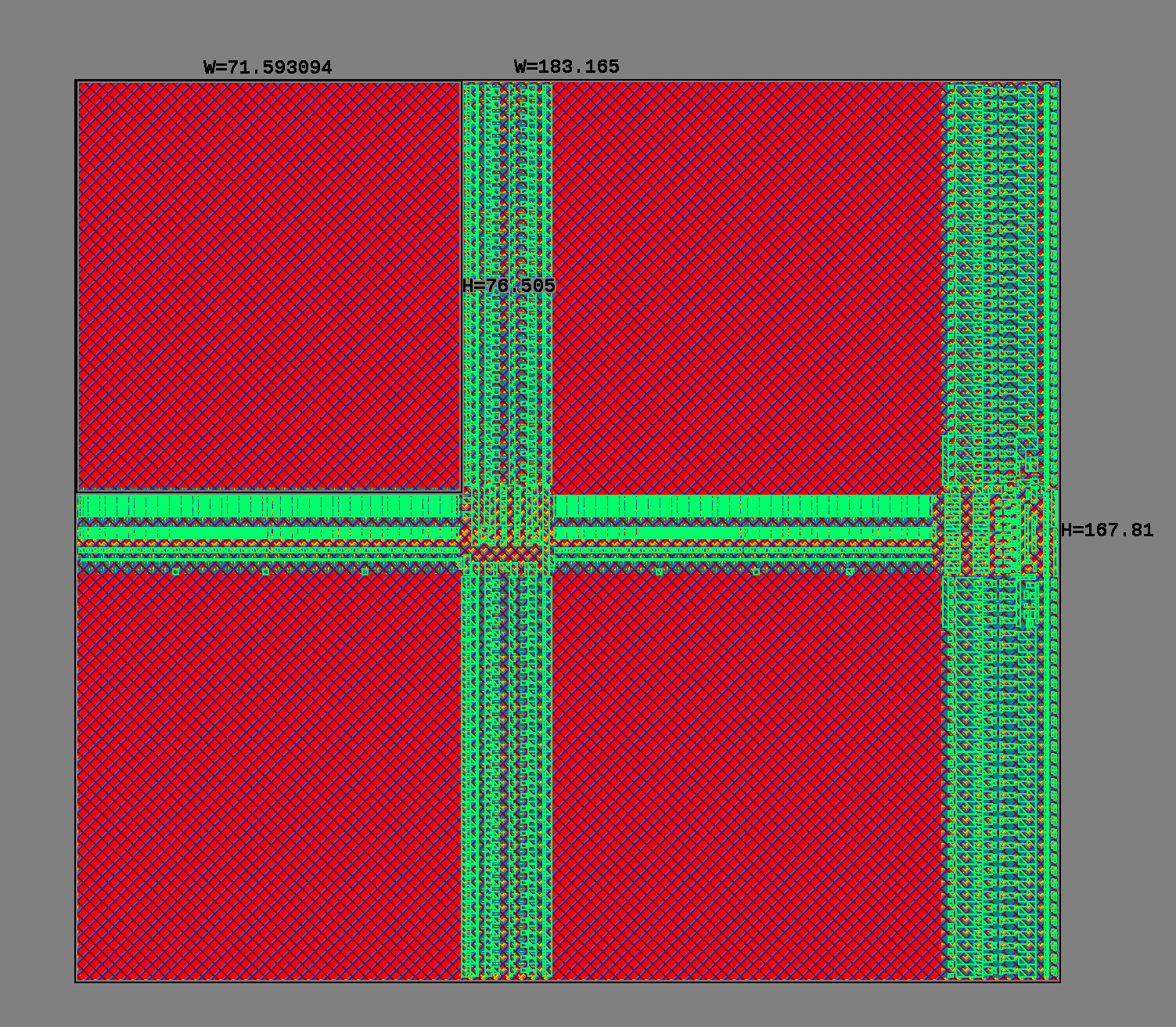
以上是寬度為 64bit 深度為 2048 的 Single Port SRAM,面積大致由三部分組成:
- Cell。圖上紅色的部分,cell 分布均勻密度固定,總面積和 capacity 有關;
- Necessary Driver。wordline、bitline driver、SA、decoder 等等。Dataport 和 address port 在圖的右側,右側豎著一條主要是 bitline driver,而中間橫著一條是 wordline driver。
- Additional Driver。隨著陣列尺寸擴大,bitline 和 wordline 長度相應擴大,為了優化時序和能耗特性,會將 bitline 和 wordline 拆分打斷(又稱 {hierarchical/splitted} {wordline/bitline}),引入額外的驅動電路至負責驅動一小節,比如這里的十字架將bitline 和 wordline 都分成了兩端。
這三種面積開銷中,只有 cell 部分面積是固定的。但我們可以大致引入數量級比較。以下是 64bit 寬度 512 深度的 single port / dual port SRAM 面積 profile。
| Type | Cell Area | Other Area |
|---|---|---|
| Single Port | 5300 | 3860 |
| Dual Port | 5300 | 8010 |
對于 512 深度下增加 64bit 的 port,面積數量級大致在 k。
互聯網絡的邊緣成本
之前純理論分析 MUX 的面積正比于輸入選擇 port 數量 [5]。2 輸入選擇 MUX 代碼如下,其余規格以此類推:
module mux_2to1_64bit (
input wire clock, // Clock signal
input wire [63:0] in0,
input wire [63:0] in1, // 2 inputs
input wire [0:0] sel, // Selection signal
output reg [63:0] out // 64-bit registered output
);
// Internal signal to hold the selected value
wire [63:0] mux_out;
// The output is assigned based on the value of sel
assign mux_out = sel == 1'd0 ? in0 :
sel == 1'd1 ? in1 : 64'b0;
// Register the output on the rising edge of the clock
always @(posedge clock) begin
out <= mux_out;
end
endmodule
因為執行單元組合邏輯,在網絡中引入打拍才合理。以下是不同輸入的 MUX 在 200 MHz 約束下的面積:
| MUX | 2-1 | 4-1 | 8-1 | 32-1 | 64-1 |
|---|---|---|---|---|---|
| Area | 628 | 671 | 803 | 1470 | 2326 |
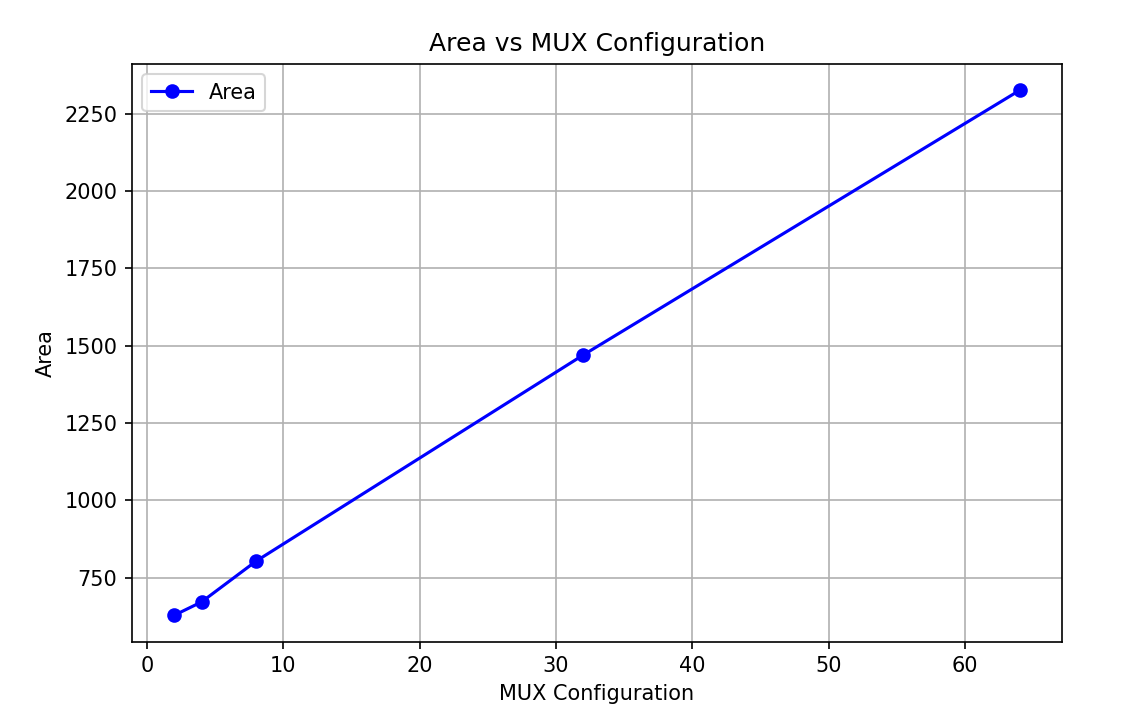
面積曲線大致成線性,驗證之前分析是正確的,即 \(Area = k \times N\)。
互聯 vs Bank
而整個網絡互聯面積應為 \(Area= k \times N^2\)。擬合斜率大致為 27.48,得到 64bit 粒度寬度下全互聯網絡隨著計算單元個數變化的面積范圍:
| N | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|
| 27.48 * N2 | 109.92 | 439.68 | 1758.72 | 7043.52 | 28035.84 | 69870.72 |
| 1000 * N | 2000 | 4000 | 8000 | 16000 | 32000 | 64000 |
因為假設port增加的數量是線性的,以1000斜率預估數量級,在 8 個互聯之前互聯網絡面積開銷比 port 小一個數量級。
總結
建模較為粗糙,比如只考慮綜合面積,MUX 選擇應該對布局布線有很大影響;Bank 系統也應該有選擇執行單元的 MUX;對 Bank 提高帶寬方式分析建模并不夠準確等等。但從結論來看,在 MUX 互聯數量較少的情況下,面積還是有數量級的優勢的,現有 CGRA 大都以相鄰四向或是八向連接是能夠立得住的。
硬件層面功耗實驗還沒考慮,而軟件層面也缺失對編譯棧改動的影響。值得進一步關注分析。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號