
解決GRPO優勢歸因錯誤,Chunk-GRPO讓文生圖模型更懂"節奏"
文本到圖像(T2I)生成模型的發展速度超出很多人的預期。從SDXL到Midjourney,再到最近的FLUX.1,這些模型在短時間內就實現了從模糊抽象到逼真細膩的跨越。但問題也隨之而來——如何讓模型生成的不僅僅是"一張圖",而是"正確的那張圖"?這涉及到如何讓AI理解人類在審美、風格和構圖上的真實偏好。
強化學習(RL)成為解決這個問題的關鍵技術。通過將人類偏好分數作為獎勵信號,可以對這些大模型進行微調。群體相對策略優化(GRPO)是近期比較熱門的方案。但清華大學和快手的研究團隊最近發現,這個方法存在一個隱藏的根本性缺陷。
這個缺陷會讓模型學錯東西,即便最終生成的圖像看起來還不錯。論文"SAMPLE BY STEP, OPTIMIZE BY CHUNK: CHUNK-LEVEL GRPO FOR TEXT-TO-IMAGE GENERATION"提出了一個叫Chunk-GRPO的解決方案,思路直接并且效果出眾,算是訓練生成模型思路上的一次轉向。
GRPO的問題:不準確的優勢歸因
要理解Chunk-GRPO做了什么,得先搞清楚現有方法的問題出在哪。論文把這個問題叫做**"不準確的優勢歸因"**(inaccurate advantage attribution)。
可以用一個類比來說明。假設你在教學徒做酸面團面包,整個流程有17個步驟。學徒做了兩個面包——面包A各方面都很棒,面包B勉強及格。作為師傅,你給A打了高分(+10),給B打了低分(+2)。
標準GRPO的做法相當于告訴學徒:"面包A的每一個步驟都比B好。"它把最終的高分獎勵追溯性地分配給制作A的所有17個步驟。
但實際情況可能是,做A的第3步時學徒差點打翻面團,而做B的第3步手法其實很標準。標準GRPO仍然會獎勵A的糟糕第3步,懲罰B的正常第3步,就因為最終結果不同。這就是"不準確的優勢歸因"——模型被強化的某個具體動作,單獨看其實是個錯誤。訓練幾千次之后,這種錯誤的反饋信號會讓模型困惑,導致訓練不穩定,效果也達不到最優。
論文用圖像生成的真實案例展示了這個問題: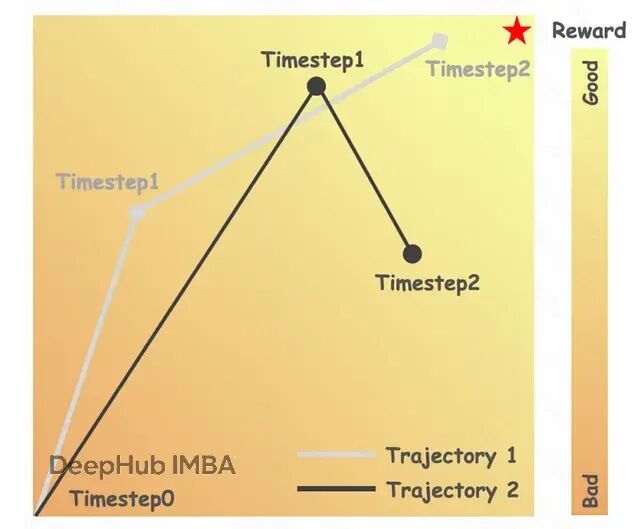
https://avoid.overfit.cn/post/801e16bc6ddb464bbeb532f74cdceb91

 浙公網安備 33010602011771號
浙公網安備 33010602011771號