
sklearn 特征選擇實(shí)戰(zhàn):用 RFE 找到最優(yōu)特征組合
特征越多模型效果就越好?這個(gè)想法在實(shí)踐中往往站不住腳,因?yàn)檫^多的特征反而會(huì)帶來(lái)過擬合、訓(xùn)練時(shí)間過長(zhǎng)、模型難以解釋等一堆麻煩。遞歸特征消除(RFE)就是用來(lái)解決這類問題的,算是特征選擇里面比較靠譜的方法之一。
本文會(huì)詳細(xì)介紹RFE 的工作原理,然后用 scikit-learn 跑一個(gè)完整的例子。
RFE 是什么
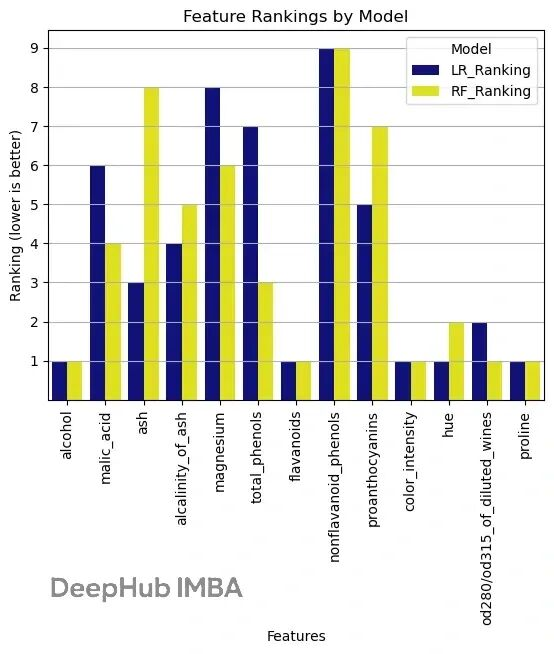
遞歸特征消除本質(zhì)上是個(gè)反向篩選過程。它會(huì)先用全部特征訓(xùn)練模型,然后根據(jù)模型給出的重要性評(píng)分把最不重要的特征踢掉,接著用剩下的特征重新訓(xùn)練,如此反復(fù)直到達(dá)到設(shè)定的特征數(shù)量。
這可以理解成雕刻的過程,一點(diǎn)點(diǎn)削掉不重要的部分,最后留下對(duì)預(yù)測(cè)真正有用的核心特征。
RFE 比單變量特征選擇高明的地方在于,它考慮了特征之間的交互關(guān)系。每次刪掉特征后都會(huì)重新訓(xùn)練,這樣能捕捉到特征組合的效果。
RFE 適用范圍比較廣,只要模型能給出特征重要性就能用。它會(huì)自己考慮特征之間怎么配合,這點(diǎn)很關(guān)鍵。刪掉無(wú)關(guān)特征后模型泛化能力會(huì)更好,不容易過擬合。特征少了模型自然更好理解,訓(xùn)練和預(yù)測(cè)的速度也快。
https://avoid.overfit.cn/post/2ef37f6acc184f2dbf8ae46fba3377bf

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)