摘要:  本文介紹了一種使用conda來安裝gcc和g++編譯工具的方法,可以不需要root權限,也能夠在本地自己的路徑下配置相應的編譯器版本。 閱讀全文
本文介紹了一種使用conda來安裝gcc和g++編譯工具的方法,可以不需要root權限,也能夠在本地自己的路徑下配置相應的編譯器版本。 閱讀全文
本文介紹了一種使用conda來安裝gcc和g++編譯工具的方法,可以不需要root權限,也能夠在本地自己的路徑下配置相應的編譯器版本。 閱讀全文
posted @ 2025-11-03 16:38
DECHIN
閱讀(18)
評論(0)
推薦(0)
 本文介紹了一種使用conda來安裝gcc和g++編譯工具的方法,可以不需要root權限,也能夠在本地自己的路徑下配置相應的編譯器版本。 閱讀全文
本文介紹了一種使用conda來安裝gcc和g++編譯工具的方法,可以不需要root權限,也能夠在本地自己的路徑下配置相應的編譯器版本。 閱讀全文
 本文介紹了一個Ubuntu操作系統下如何掛載新硬盤,并配置重啟開機默認掛載的流程和方法。 閱讀全文
本文介紹了一個Ubuntu操作系統下如何掛載新硬盤,并配置重啟開機默認掛載的流程和方法。 閱讀全文
 本文介紹了一個可以基于CPU和numpy的自動微分計算框架。如果只是需要使用自動微分計算的功能,就可以直接在CPU環境下簡便的部署,快捷的完成環境搭建。 閱讀全文
本文介紹了一個可以基于CPU和numpy的自動微分計算框架。如果只是需要使用自動微分計算的功能,就可以直接在CPU環境下簡便的部署,快捷的完成環境搭建。 閱讀全文
 本文重點介紹了一下如何在PyTorch中去計算一個高維tensor的大小,也就是元素的總數。在其他框架中我們需要使用size函數來獲取,而在PyTorch框架中這個接口被調整為numel,本文給出了兩個具體代碼示例。 閱讀全文
本文重點介紹了一下如何在PyTorch中去計算一個高維tensor的大小,也就是元素的總數。在其他框架中我們需要使用size函數來獲取,而在PyTorch框架中這個接口被調整為numel,本文給出了兩個具體代碼示例。 閱讀全文
 本文介紹了一個可以用于并行化串行累計操作的Blelloch算法,可以通過用空間換時間+并行計算的方法,來降低特定計算的時間復雜度。這里我們給出了算法原理的大致介紹,以及基于Numpy的算法代碼實現。 閱讀全文
本文介紹了一個可以用于并行化串行累計操作的Blelloch算法,可以通過用空間換時間+并行計算的方法,來降低特定計算的時間復雜度。這里我們給出了算法原理的大致介紹,以及基于Numpy的算法代碼實現。 閱讀全文
 Ollama在本地普通算力機器上部署DeepSeek等大模型,有一定的生態優勢。但是由于軟件本身的一些策略問題,Windows平臺的Ollama總是會隨系統開機自動啟動,還沒有設置界面可以關閉。這里提供一種方法,可以在Windows平臺永久關閉Ollama的開機自動啟動功能。 閱讀全文
Ollama在本地普通算力機器上部署DeepSeek等大模型,有一定的生態優勢。但是由于軟件本身的一些策略問題,Windows平臺的Ollama總是會隨系統開機自動啟動,還沒有設置界面可以關閉。這里提供一種方法,可以在Windows平臺永久關閉Ollama的開機自動啟動功能。 閱讀全文
 本文簡單的介紹了如何禁用VSCode的版本自動更新,以及禁用更新后如何手動更新,或者切換VSCode的版本。 閱讀全文
本文簡單的介紹了如何禁用VSCode的版本自動更新,以及禁用更新后如何手動更新,或者切換VSCode的版本。 閱讀全文
 本文通過幾個簡單的代碼示例,展示了一下NAN在PyTorch框架下形成的原因。通過了解這個原因和規則,有助于解決在深度學習開發和訓練過程中出現的NAN的問題。 閱讀全文
本文通過幾個簡單的代碼示例,展示了一下NAN在PyTorch框架下形成的原因。通過了解這個原因和規則,有助于解決在深度學習開發和訓練過程中出現的NAN的問題。 閱讀全文
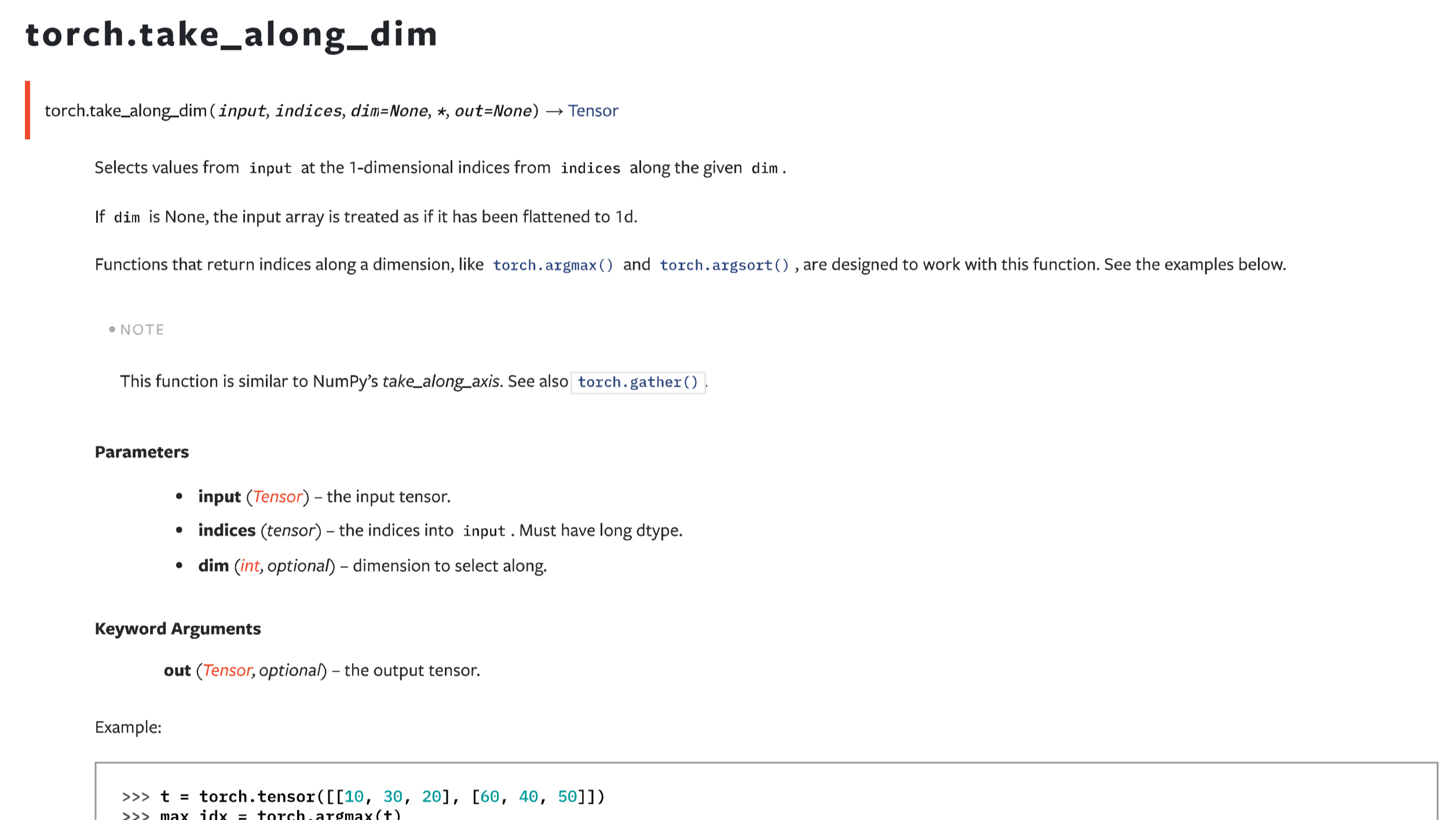 接前面一篇take_along_axis的文章,本文主要介紹在PyTorch框架下,功能基本一樣的函數take_along_dim。二者除了命名和一些關鍵詞參數不一致之外,用法是一樣的。需要注意的是,兩者都要求輸入的數組和索引數組維度數量一致。在特定場景下,需要手動進行擴維。 閱讀全文
接前面一篇take_along_axis的文章,本文主要介紹在PyTorch框架下,功能基本一樣的函數take_along_dim。二者除了命名和一些關鍵詞參數不一致之外,用法是一樣的。需要注意的是,兩者都要求輸入的數組和索引數組維度數量一致。在特定場景下,需要手動進行擴維。 閱讀全文
 本文簡單的介紹了一個在Pytorch中對張量進行逆序操作的方法相比于其他的框架,例如numpy和mindspore等的區別。在其他框架中我們可以直接使用slice的方法對一個張量做逆序,但是在Pytorch中,可能需要使用到一個flip函數。 閱讀全文
本文簡單的介紹了一個在Pytorch中對張量進行逆序操作的方法相比于其他的框架,例如numpy和mindspore等的區別。在其他框架中我們可以直接使用slice的方法對一個張量做逆序,但是在Pytorch中,可能需要使用到一個flip函數。 閱讀全文
 本文介紹了在PyTorch中直接使用冪次函數計算有可能導致的計算結果異常的問題。由于PyTorch中并未像Numpy和MindSpore一樣直接支持cbrt開立方函數,因此這里也提供了一個在PyTorch中計算開立方的函數。 閱讀全文
本文介紹了在PyTorch中直接使用冪次函數計算有可能導致的計算結果異常的問題。由于PyTorch中并未像Numpy和MindSpore一樣直接支持cbrt開立方函數,因此這里也提供了一個在PyTorch中計算開立方的函數。 閱讀全文
 本文簡單的介紹了一下在空白的Ubuntu Linux中安裝conda的方法和腳本,其中包含了CUDA部分的安裝。 閱讀全文
本文簡單的介紹了一下在空白的Ubuntu Linux中安裝conda的方法和腳本,其中包含了CUDA部分的安裝。 閱讀全文
 本文介紹了MindSpore中的tensor_scatter_add算子的用法,可以對一個多維的tensor在指定的index上面進行加和操作。在PyTorch中雖然也有一個叫scatter_add的算子,但是本質上來說兩者是完全不一樣的操作。 閱讀全文
本文介紹了MindSpore中的tensor_scatter_add算子的用法,可以對一個多維的tensor在指定的index上面進行加和操作。在PyTorch中雖然也有一個叫scatter_add的算子,但是本質上來說兩者是完全不一樣的操作。 閱讀全文
 本文通過2個實際的案例,演示了一下gather算子在MindSpore框架下PyTorch框架下的異同點。兩者的輸入都是tensor-axis-index,一個是輸入順序上略有區別,另一個是對于輸入的張量索引維度的要求。在PyTorch中,如果我們要實現類似于MindSpore中的gather功能,需要手動對輸入索引的維度操作一下。 閱讀全文
本文通過2個實際的案例,演示了一下gather算子在MindSpore框架下PyTorch框架下的異同點。兩者的輸入都是tensor-axis-index,一個是輸入順序上略有區別,另一個是對于輸入的張量索引維度的要求。在PyTorch中,如果我們要實現類似于MindSpore中的gather功能,需要手動對輸入索引的維度操作一下。 閱讀全文
 本文介紹了在pytorch和mindspore中兩種計算張量最大值的算子,如果直接使用max算子,兩者的輸出都是最大值元素和最大值索引。但是mindspore中額外的支持了ReduceMax算子,可以允許我們只輸出最大值而不輸出最大值索引。 閱讀全文
本文介紹了在pytorch和mindspore中兩種計算張量最大值的算子,如果直接使用max算子,兩者的輸出都是最大值元素和最大值索引。但是mindspore中額外的支持了ReduceMax算子,可以允許我們只輸出最大值而不輸出最大值索引。 閱讀全文
 浙公網安備 33010602011771號
浙公網安備 33010602011771號