
pytorch實(shí)踐(八) 繪制多輪訓(xùn)練和測(cè)試曲線
繪制訓(xùn)練/測(cè)試的 Loss 和 Accuracy 曲線,直觀判斷模型訓(xùn)練效果是否良好。
| 圖像 | 解釋 |
|---|---|
| Loss 曲線(損失函數(shù)) | 反映模型在訓(xùn)練和測(cè)試過(guò)程中的錯(cuò)誤程度,越低越好。 |
| Accuracy 曲線(準(zhǔn)確率) | 反映模型預(yù)測(cè)正確的比例,越高越好。 |
你可以從圖中看到什么?
1. 是否在收斂?
-
Loss 是否逐步降低?
-
Accuracy 是否逐步上升?
如果 loss 一直很高,說(shuō)明模型學(xué)不到東西,可能是網(wǎng)絡(luò)設(shè)計(jì)、學(xué)習(xí)率等參數(shù)有問(wèn)題。
2. 是否過(guò)擬合?
-
如果訓(xùn)練集 Accuracy 很高,但測(cè)試集 Accuracy 很低,就說(shuō)明模型只記住了訓(xùn)練數(shù)據(jù),沒(méi)有學(xué)會(huì)泛化能力(過(guò)擬合)。
3. 是否欠擬合?
-
如果訓(xùn)練集和測(cè)試集 Accuracy 都很低,說(shuō)明模型還沒(méi)有學(xué)好,可能是模型太簡(jiǎn)單,或訓(xùn)練輪數(shù)不夠。
neural_network_model.py
from torch import nn # 定義神經(jīng)網(wǎng)絡(luò)模型 class NeuralNetwork(nn.Module): def __init__(self): super().__init__() self.flatten = nn.Flatten() # 將 1x28x28 展平為 784 self.linear_relu_stack = nn.Sequential( nn.Linear(28*28, 128), nn.ReLU(), nn.Linear(128, 64), nn.ReLU(), nn.Linear(64, 10) # 最終10類輸出 ) def forward(self, x): x = self.flatten(x) logits = self.linear_relu_stack(x) return logits
loss_acc_plot.py
import torch from torch import nn from torch.utils.data import DataLoader from torchvision import datasets, transforms import matplotlib.pyplot as plt from neural_network_model import NeuralNetwork from torchvision.transforms import ToTensor # 下載 FashionMNIST 訓(xùn)練集和測(cè)試集 training_data = datasets.FashionMNIST( root="data", train=True, download=True, transform=ToTensor() ) test_data = datasets.FashionMNIST( root="data", train=False, download=True, transform=ToTensor() ) # 用 DataLoader 封裝 train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) # batch_size=64:每次迭代從訓(xùn)練集中取出 64 個(gè)樣本。 # shuffle=True:每輪訓(xùn)練(epoch)前會(huì)打亂數(shù)據(jù)順序,提高訓(xùn)練效果,防止模型記住順序。 test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True) # 設(shè)置訓(xùn)練設(shè)備、實(shí)例化模型和損失函數(shù) device = "cuda" if torch.cuda.is_available() else "cpu" model = NeuralNetwork().to(device) # 創(chuàng)建該網(wǎng)絡(luò)的一個(gè)實(shí)例對(duì)象并存儲(chǔ)到設(shè)備 loss_fn = nn.CrossEntropyLoss() #設(shè)置損失函數(shù) optimizer = torch.optim.SGD(model.parameters(), lr=1e-2) # 訓(xùn)練函數(shù) def train_loop(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) num_batches = len(dataloader) model.train() total_loss = 0 correct = 0 for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) loss = loss_fn(pred, y) optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() avg_loss = total_loss / num_batches accuracy = correct / size return avg_loss, accuracy # 測(cè)試函數(shù) def test_loop(dataloader, model, loss_fn): size = len(dataloader.dataset) num_batches = len(dataloader) model.eval() total_loss = 0 correct = 0 with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) loss = loss_fn(pred, y) total_loss += loss.item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() avg_loss = total_loss / num_batches accuracy = correct / size return avg_loss, accuracy # 準(zhǔn)備畫(huà)圖數(shù)據(jù) train_losses, train_accuracies = [], [] test_losses, test_accuracies = [], [] # 訓(xùn)練過(guò)程 epochs = 10 for epoch in range(epochs): print(f"Epoch {epoch+1}/{epochs}") train_loss, train_acc = train_loop(train_dataloader, model, loss_fn, optimizer) test_loss, test_acc = test_loop(test_dataloader, model, loss_fn) train_losses.append(train_loss) train_accuracies.append(train_acc) test_losses.append(test_loss) test_accuracies.append(test_acc) print(f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}") print(f"Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}") print("-" * 50) # 設(shè)置支持中文顯示 plt.rcParams['font.family'] = 'SimHei' plt.rcParams['axes.unicode_minus'] = False # 繪制 loss / accuracy 曲線 epochs_range = range(1, epochs + 1) plt.figure(figsize=(10, 4)) # Loss 曲線 plt.subplot(1, 2, 1) plt.plot(epochs_range, train_losses, label="Train Loss 訓(xùn)練損失") plt.plot(epochs_range, test_losses, label="Test Loss 測(cè)試損失") plt.xlabel("Epoch 訓(xùn)練輪數(shù)") plt.ylabel("Loss 損失") plt.title("Loss Curve 損失曲線") plt.legend() plt.grid(True) # Accuracy 曲線 plt.subplot(1, 2, 2) plt.plot(epochs_range, train_accuracies, label="Train Acc 訓(xùn)練準(zhǔn)確率") plt.plot(epochs_range, test_accuracies, label="Test Acc 測(cè)試準(zhǔn)確率") plt.xlabel("Epoch 訓(xùn)練輪數(shù)") plt.ylabel("Accuracy 準(zhǔn)確率") plt.title("Accuracy Curve 準(zhǔn)確率曲線") plt.legend() plt.grid(True) plt.tight_layout() plt.show()
訓(xùn)練10輪,繪圖效果:
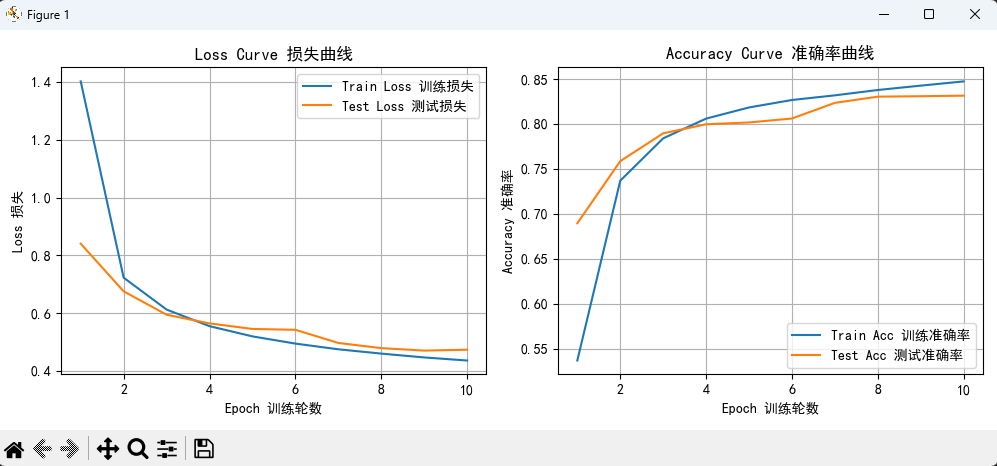
訓(xùn)練30輪效果:
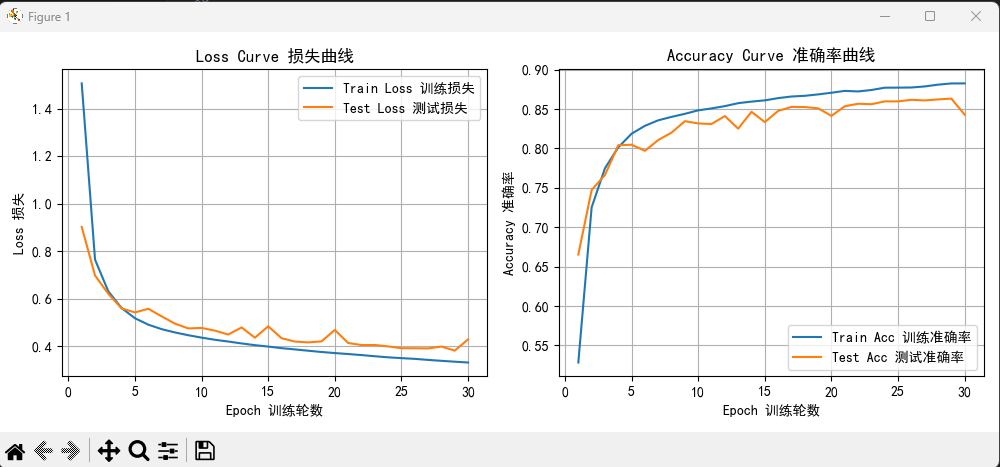
可以看的大概在25輪之后,測(cè)試準(zhǔn)確率就不再增長(zhǎng),甚至到了28輪之后,測(cè)試準(zhǔn)確率顯著下降,也就是過(guò)擬合了。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)