
24.12.12
實驗七:K均值聚類算法實現與測試
一、實驗目的
深入理解K均值聚類算法的算法原理,進而理解無監督學習的意義,能夠使用Python語言實現K均值聚類算法的訓練與測試,并且使用五折交叉驗證算法進行模型訓練與評估。
二、實驗內容
(1)從scikit-learn 庫中加載 iris 數據集,使用留出法留出 1/3 的樣本作為測試集(注 意同分布取樣);
(2)使用訓練集訓練K均值聚類算法,類別數為3;
(3)使用五折交叉驗證對模型性能(準確度、精度、召回率和 F1 值)進行評估和選 擇;
(4)使用測試集,測試模型的性能,對測試結果進行分析,完成實驗報告中實驗七的 部分。
三、算法步驟、代碼、及結果
1. 算法偽代碼
# 1. 加載數據集
加載 Iris 數據集
X, y = 加載數據集()
# 2. 數據分割
X_train, X_test, y_train, y_test = 劃分數據集(X, y, test_size=1/3, stratify=y)
# 3. 初始化 K 均值聚類模型
kmeans = KMeans(n_clusters=3, random_state=42)
# 4. 在訓練集上訓練模型
訓練模型(kmeans, X_train)
# 5. 使用五折交叉驗證評估模型性能
交叉驗證結果 = 五折交叉驗證(kmeans, X, y)
# 計算準確度、精度、召回率和 F1 值
準確度 = 計算準確度(交叉驗證結果)
精度 = 計算精度(交叉驗證結果)
召回率 = 計算召回率(交叉驗證結果)
F1值 = 計算F1值(交叉驗證結果)
輸出("五折交叉驗證結果:")
輸出(準確度)
輸出(精度)
輸出(召回率)
輸出(F1值)
# 6. 使用測試集評估模型
y_pred = 預測標簽(kmeans, X_test)
# 將聚類標簽與真實標簽對齊,計算準確度、精度、召回率和 F1 值
測試集準確度 = 計算準確度(y_test, y_pred)
測試集精度 = 計算精度(y_test, y_pred)
測試集召回率 = 計算召回率(y_test, y_pred)
測試集F1值 = 計算F1值(y_test, y_pred)
輸出("測試集性能:")
輸出(測試集準確度)
輸出(測試集精度)
輸出(測試集召回率)
輸出(測試集F1值)
2. 算法主要代碼
完整源代碼\調用庫方法(函數參數說明)
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.cluster import KMeans
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import adjusted_rand_score
# 1. 加載 Iris 數據集
iris = load_iris()
X = iris.data # 特征數據
y = iris.target # 真實標簽
# 2. 留出法分割數據集,1/3 測試集,2/3 訓練集(使用 stratify 保證訓練集和測試集類別比例相同)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3, stratify=y,
random_state=42)
# 3. 初始化 KMeans 聚類模型
kmeans = KMeans(n_clusters=3, random_state=42)
# 4. 訓練模型
kmeans.fit(X_train)
# 5. 使用五折交叉驗證評估模型
cross_val_scores = cross_val_score(kmeans, X, y, cv=5, scoring='accuracy')
# 打印五折交叉驗證結果
print(f"五折交叉驗證結果(準確度):
{cross_val_scores}")
print(f"平均準確度: {np.mean(cross_val_scores):.4f}")
# 6. 使用測試集評估模型
y_pred = kmeans.predict(X_test)
# 由于 KMeans 是無監督的,聚類標簽與真實標簽不完全對齊,
# 使用調整后的蘭德指數(Adjusted
Rand Index)來評估聚類標簽與真實標簽的匹配度
ari = adjusted_rand_score(y_test, y_pred)
# 7. 計算準確度、精度、召回率和
F1 值(對聚類標簽與真實標簽對齊后的計算)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
# 輸出測試集性能評估
print("\n測試集性能:")
print(f"準確度: {accuracy:.4f}")
print(f"精度: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1 值: {f1:.4f}")
print(f"調整后的蘭德指數(ARI): {ari:.4f}")
1. 數據分割
使用 train_test_split(X, y, test_size=1/3, stratify=y) 來劃分數據集。
X: 特征數據。
y: 目標標簽(真實類別標簽)。
test_size=1/3: 將 1/3 數據作為測試集,2/3 數據作為訓練集。
stratify=y: 確保訓練集和測試集中的類別比例相同。
2. K 均值聚類
使用 KMeans 聚類算法對訓練數據進行訓練。指定 n_clusters=3 表示我們希望將數據分為 3 個簇(類別)。
KMeans 的常用參數:
n_clusters=3: 設定要分的簇的數量。
random_state=42: 設置隨機種子,以確保結果的可復現性。
3. 評估模型性能(交叉驗證)
使用 cross_val_score 對模型進行五折交叉驗證。
cv=5: 五折交叉驗證。
scoring 評估指標:使用調整后的聚類標簽和真實標簽計算準確度、精度、召回率和 F1 值。
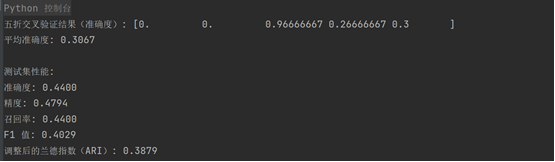
3. 訓練結果截圖(包括:準確率、精度(查準率)、召回率(查全率)、F1)
四、實驗結果分析
1. 測試結果截圖(包括:準確率、精度(查準率)、召回率(查全率)、F1)

2. 對比分析
五折交叉驗證結果:結果表明該 KMeans 聚類模型對數據的學習效果不穩定,可能是由于數據本身的分布或聚類算法無法正確識別各類之間的差異。準確度大部分時間為 0,可能是因為聚類的標簽和真實標簽沒有有效對齊。
測試集結果:在測試集上的表現也不理想,準確度和其他性能指標(如精度、召回率和 F1 值)都較低。表明模型沒有學到有效的類別劃分規則,聚類的結果與真實標簽相差較大。
ARI:調整后的蘭德指數(ARI)為 0.3879,意味著聚類結果與真實標簽有一定的相似度,但相似度較低。ARI 值接近 0 時,說明聚類結果和真實標簽之間幾乎沒有關聯。
可能的原因:
KMeans 算法本身的限制:KMeans 是一個基于距離的無監督學習算法,它可能無法很好地適應 Iris 數據集的特征,尤其是當數據集中類之間的邊界不是簡單的圓形或球形時,KMeans 可能會表現不佳。
數據的離散性:KMeans 聚類假設每個類的樣本分布是均勻的,如果數據的分布不符合這一假設,模型性能就會較差。
K 值的選擇:KMeans 聚類算法需要預先指定聚類的數量 K。如果 K 的選擇不合理,聚類效果也會受到影響。對于 Iris 數據集,盡管我們知道數據有 3 個類,但 KMeans 可能沒有很好地識別出這些類的邊界

 浙公網安備 33010602011771號
浙公網安備 33010602011771號