

hive group by 導致的數(shù)據(jù)傾斜問題
Group By
默認情況下,Map階段同一Key數(shù)據(jù)分發(fā)給一個reduce,當一個key數(shù)據(jù)過大時就傾斜了。
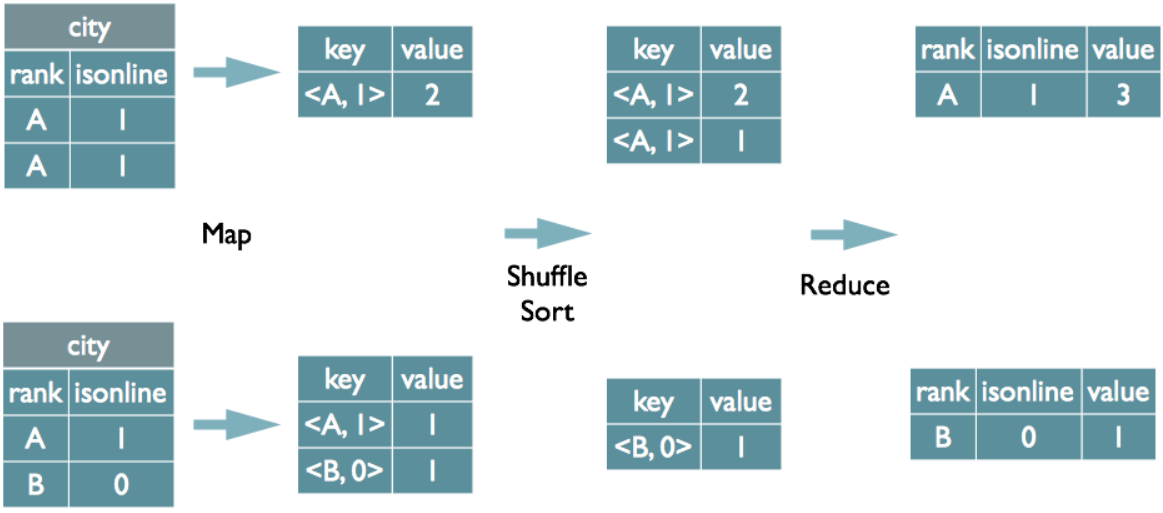
但并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端進行部分聚合,最后在Reduce端得出最終結果。
1)開啟Map端聚合參數(shù)設置
(1)是否在Map端進行聚合(默認為true)
set hive.auto.convert.join = true;
(2)在Map端進行聚合操作的條目數(shù)目
set hive.groupby.mapaggr.checkinterval = 100000
(3)有數(shù)據(jù)傾斜的時候進行負載均衡(默認是false)
set hive.groupby.skewindata = true
情況一:
select count(distinct member_no),trade_date from uiopdb.sx_trade_his_detail group by trade_date
優(yōu)化后
select count(member_no),trade_date from ( select member_no,trade_date as trade_date from uiopdb.sx_trade_his_detail group by member_no,trade_date ) d group by trade_date
情況二:
但是對于很大的表,比如需要統(tǒng)計每個會員的總的交易額情況,采用上面的方法也不能跑出來
優(yōu)化前的代碼(交易表中有三千萬的數(shù)據(jù))
set hive.groupby.skewindata = true; create table tmp_shop_trade_amt as select shop_no ,sum(txn_amt) as txn_amt from uiopdb.sx_trade_his_detail group by shop_no;

優(yōu)化思路:如果某個key的數(shù)據(jù)量特別大,數(shù)據(jù)都集中到某一個reduce Task去進行相關數(shù)據(jù)的處理,這就導致了數(shù)據(jù)傾斜問題。
解決方案是首先采用局部聚合,即給key加上100以內的隨機前綴,進行一次預聚合,然后對本次預聚合后的結果進行去掉隨機前綴,進行一次數(shù)據(jù)的全局聚合。
優(yōu)化后:
set hive.groupby.skewindata = true; create table tmp_shop_trade_amt_2 as select split(shop_no,'_')[1] as shop_no
,sum(txn_amt) total_txn_amt from
( select concat_ws("_", cast(ceiling(rand()*99) as string), shop_no) as shop_no
,sum(txn_amt) txn_amt from uiopdb.sx_trade_his_detail group by concat_ws("_", cast(ceiling(rand()*99) as string), shop_no) ) s group by split(shop_no,'_')[1] ;
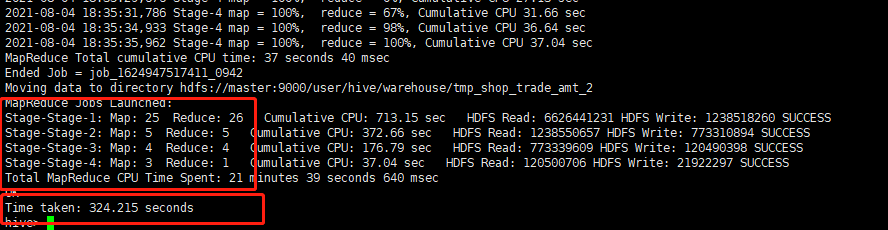
運行結果

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號