本系列文章介紹如何用C#實(shí)現(xiàn)一個(gè)類似于查詢分析器的計(jì)算器。該計(jì)算器接受表達(dá)式輸入,支持多行表達(dá)式,可選擇部分表達(dá)式進(jìn)行計(jì)算,能定位語法錯(cuò)誤的位置,并且支持?jǐn)?shù)值、字符串和邏輯值的計(jì)算,內(nèi)置多種運(yùn)算符和函數(shù),并且可以根據(jù)需要擴(kuò)展出更多的運(yùn)算符和函數(shù)。程序中包含一些細(xì)節(jié)上的bug,有興趣的朋友可以完善一下。
本篇介紹如何將表達(dá)式分析成程序可以識(shí)別的記號(hào)對(duì)象列表,其中使用了依賴注入來提高靈活性。
承接上一篇,這一篇講如何把表達(dá)式轉(zhuǎn)換成記號(hào)對(duì)象,這里就涉及到了編譯原理中的詞法分析。關(guān)于編譯原理我不想多講,畢竟我自己也不怎么熟悉,現(xiàn)在只知道其中有個(gè)有限自動(dòng)機(jī)的概念。不管什么概念,用代碼實(shí)現(xiàn)才是最終目標(biāo)。
因?yàn)椴磺宄址械降装裁醋址荒芤粋€(gè)個(gè)字符進(jìn)行處理,采用循環(huán)一次次向后取一個(gè)字符進(jìn)行判斷。這里建立一個(gè)TokenFactory記號(hào)“工廠”類,由這個(gè)類負(fù)責(zé)對(duì)表達(dá)式進(jìn)行分析并“生產(chǎn)”出TokenRecord對(duì)象。其中包括兩個(gè)方法,LexicalAnalysis和ProduceToken。LexicalAnalysis用于詞法分析,分析到符合規(guī)則的記號(hào)對(duì)象后調(diào)用ProduceToken方法,“生產(chǎn)”出對(duì)應(yīng)的TokenRecord對(duì)象。這里偷了一點(diǎn)懶,把所有方法全部寫成了static,這樣就不用實(shí)例化多個(gè)子類了。
從這個(gè)類衍生出多個(gè)子類:
TokenKeywordFactory:用于處理關(guān)鍵字
TokenSymbolFactory:用于處理運(yùn)算符
TokenStringFactory:用于處理字符串
TokenNumberFactory:用于處理數(shù)字
類圖如下:
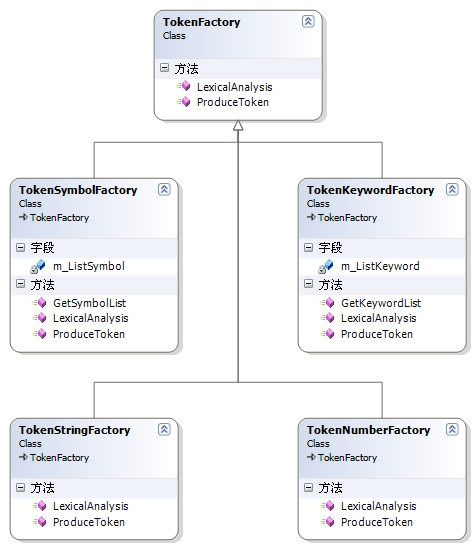
分析表達(dá)式的入口只有一個(gè),就是TokenFactory中的LexicalAnalysis。TokenFactory類的代碼如下:

 Code
Code
internal class TokenFactory
{
/// <summary>
/// 產(chǎn)生記號(hào)對(duì)象
/// </summary>
/// <param name="TokenWord">記號(hào)對(duì)應(yīng)的字符串</param>
/// <param name="Index">記號(hào)開始的列序號(hào)</param>
/// <returns>記號(hào)對(duì)象</returns>
protected static TokenRecord ProduceToken(string TokenWord, int Index)
{
throw new Exception("必須在子類中實(shí)現(xiàn)方法");
}
/// <summary>
/// 詞法分析
/// </summary>
/// <param name="TokenList">記號(hào)對(duì)象列表</param>
/// <param name="Code">表達(dá)式</param>
/// <param name="Index">列序號(hào)</param>
public static void LexicalAnalysis(List<TokenRecord> TokenList, string Code, ref int Index)
{
char chrTemp;//臨時(shí)字符
for (int intIndex = 0; intIndex < Code.Length; intIndex++)
{
chrTemp = Code[intIndex];//獲取當(dāng)前字符
//關(guān)鍵字分析
if (char.IsLetter(chrTemp))//如果當(dāng)前字符為字母,進(jìn)行關(guān)鍵字處理
{
TokenKeywordFactory.LexicalAnalysis(TokenList, Code, ref intIndex);
}
else if (chrTemp.Equals('\'') || chrTemp.Equals('"'))//如果是字符串分隔符,進(jìn)行字符串處理
{
TokenStringFactory.LexicalAnalysis(TokenList, Code, ref intIndex);
}
else if (char.IsDigit(chrTemp))//數(shù)值處理
{
TokenNumberFactory.LexicalAnalysis(TokenList, Code, ref intIndex);
}
else if (TokenSymbolFactory.GetSymbolDictionary().ContainsKey(chrTemp.ToString()))//運(yùn)算符處理
{
//有些運(yùn)算符為雙字符,但這里所有的雙字符運(yùn)算符的前一個(gè)字符都有對(duì)應(yīng)的單字符運(yùn)算符,可以只考慮一個(gè)字符
TokenSymbolFactory.LexicalAnalysis(TokenList, Code, ref intIndex);
}
else if (chrTemp.Equals(' '))
{
//如果是空格,則忽略不處理
}
else//錯(cuò)誤處理
{
//拋出錯(cuò)誤
throw new SyntaxException(intIndex, 1, "包含不合法字符:" + chrTemp.ToString());
}
}//for
}//LexicalAnalysis
/// <summary>
/// 獲取操作記號(hào)字典
/// </summary>
/// <param name="OperateTokenType">操作記號(hào)類型</param>
/// <returns>操作記號(hào)字典</returns>
/// <remarks>Author:Alex Leo; Date:2008-5-19; Remark:基于本地文件TokenRecord.xml;</remarks>
internal static SortedDictionary<string, string> GetOperateTokenDictionary(OperateTokenTypeEnum OperateTokenType)
{
SortedDictionary<string, string> myDictionary = new SortedDictionary<string, string>();
if (myDictionary.Count == 0)
{
XmlDocument myDoc = new XmlDocument();
myDoc.Load("./TokenRecord.xml");
XmlNodeList KeywordList = myDoc.SelectNodes(string.Format("TokenRecord/{0}/Token",
Enum.GetName(typeof(OperateTokenTypeEnum),OperateTokenType)));
foreach (XmlNode Node in KeywordList)
{
myDictionary.Add(Node.Attributes["Word"].Value, Node.Attributes["Class"].Value);
}
}
return myDictionary;
}//GetOperateTokenDictionary
}//class TokenFactory
在LexicalAnalysis方法中,只需要判斷當(dāng)前字符是否符合一定的起始規(guī)則,如果符合起始規(guī)則,就交給對(duì)應(yīng)的工廠類去處理。
下面用例子來講吧,比如123.3*2-(24+34),分析成記號(hào)對(duì)象如下:
|
記號(hào)對(duì)象
|
對(duì)應(yīng)表達(dá)式
|
|
TokenValue
|
123.3
|
|
TokenMultiply
|
*
|
|
TokenValue
|
2
|
|
TokenMinus
|
-
|
|
TokenLeftBracket
|
(
|
|
TokenValue
|
24
|
|
TokenPlus
|
+
|
|
TokenValue
|
34
|
|
TokenRightBracket
|
)
|
這里的處理過程是
1.取字符“1”,轉(zhuǎn)到TokenNumberFactory,把分析取到的字符串“123.3”轉(zhuǎn)換為TokenNumber并存到TokenList中
2.取字符“*”,轉(zhuǎn)到TokenSymbolFactory,把“*”轉(zhuǎn)換成TokenMultiply并存到TokenList中
3.取字符“2”,轉(zhuǎn)到TokenNumberFactory,把分析取到的字符串“2”轉(zhuǎn)換為TokenNumber并存到TokenList中
4.取字符“- ”,轉(zhuǎn)到TokenSymbolFactory,把“-”轉(zhuǎn)換成TokenMinus并存到TokenList中
5.取字符“( ”,轉(zhuǎn)到TokenSymbolFactory,把“(”轉(zhuǎn)換成TokenLeftBracket并存到TokenList中
6.取字符“2”,轉(zhuǎn)到TokenNumberFactory,把分析取到的字符串“24”轉(zhuǎn)換為TokenNumber并存到TokenList中
7.取字符“+”,轉(zhuǎn)到TokenSymbolFactory,把“+”轉(zhuǎn)換成TokenPlus并存到TokenList中
8.取字符“3”,轉(zhuǎn)到TokenNumberFactory,把分析取到的字符串“34”轉(zhuǎn)換為TokenNumber并存到TokenList中
9.取字符“) ”,轉(zhuǎn)到TokenSymbolFactory,把“)”轉(zhuǎn)換成TokenRightBracket并存到TokenList中
至于各個(gè)工廠類中怎么分析提取出對(duì)應(yīng)的字符串,則有各自不同的規(guī)則。如果符合規(guī)則就繼續(xù)向后分析,否則代表分析結(jié)束,然后從源字符串中截取開始分析的序號(hào)到結(jié)束分析的序號(hào)之間的字符串即可。這里的Index參數(shù)相當(dāng)于C++中的指針,指示當(dāng)前分析到哪一個(gè)字符。因?yàn)楦鱾€(gè)“工廠”類需要在分析完一個(gè)記號(hào)后將指針后移,這里就將Index設(shè)置為ref類型。
另一個(gè)方法GetOperateTokenDictionary是用來獲取記號(hào)字典的,字典的Key是運(yùn)算符和關(guān)鍵字,Value是對(duì)應(yīng)的類名稱。在分析中遇到運(yùn)算符和關(guān)鍵字的時(shí)候,通過查詢字典就可以獲取對(duì)應(yīng)的類名稱,然后通過反射生成類的實(shí)例,這樣就可以靈活將操作符和類對(duì)應(yīng)起來。字典的來源是本地的一個(gè)XML文件,當(dāng)新增一個(gè)操作符的時(shí)候,到XML文件里注冊(cè)一下,程序就可以識(shí)別出新操作符了,“工廠”類不需要做任何修改。如果需要修改操作符,可以直接在XML文件里面修改,程序也能識(shí)別,比如把mid改成substring,程序照樣可以運(yùn)行。這就是“依賴注入”的實(shí)際應(yīng)用。
這里需要使用的XML如下:
Code
<?xml version="1.0" encoding="utf-8" ?>
<TokenRecord>
<TokenKeyword>
<!--以下字符串處理函數(shù)記號(hào)對(duì)象-->
<Token Word="mid" Class="TokenMid" Example="mid('abcdefg',2,3) = 'bcd'" />
<Token Word="left" Class="TokenLeft" Example="left('abcdefg',5) = 'abcde'" />
<Token Word="right" Class="TokenRight" Example="right('abcdefg',5) = 'cdefg'" />
<Token Word="string" Class="TokenToString" Example="string(53.6) = '53.6'" />
<!--以下為數(shù)學(xué)運(yùn)算記號(hào)對(duì)象-->
<Token Word="round" Class="TokenRound" Example="round(0.12345,3) = 0.123" />
<Token Word="abs" Class="TokenAbs" Example="abs(-5) = 5" />
<Token Word="max" Class="TokenMax" Example="max(3,5) = 5" />
<Token Word="min" Class="TokenMin" Example="min(3,5) = 3" />
<!--如果希望取余采用VB的Mod函數(shù),形如Mod(5.4,2) = 1.4,將TokenMod修改為繼承自TokenMethod即可,此時(shí)用%必須形如%(5.4,2)-->
<!--<Token Word="mod" Class="TokenMod" Example="5.4 mod 2 = 1.4,mod后必須帶空格" />-->
<Token Word="pow" Class="TokenPow" Example="pow(2,3) = 8" />
<!--以下為三角函數(shù)記號(hào)對(duì)象,均采用角度計(jì)算而非弧度-->
<Token Word="sin" Class="TokenSin" Example="sin(30) = 0.5" />
<Token Word="asin" Class="TokenAsin" Example="asin(0.5) = 30" />
<Token Word="cos" Class="TokenCos" Example="cos(60) = 0.5" />
<Token Word="acos" Class="TokenAcos" Example="acos(0.5) = 60" />
<Token Word="tan" Class="TokenTan" Example="tan(45) = 1" />
<Token Word="atan" Class="TokenAtan" Example="atan(1) = 45" />
<Token Word="atan2" Class="TokenAtan2" Example="atan2(30,30) = 45" />
<!--以下為邏輯運(yùn)算記號(hào)對(duì)象,可以同時(shí)表示為關(guān)鍵字和運(yùn)算符,因?yàn)樗鼈兊母袷揭恢拢紴閠rue operate false-->
<Token Word="and" Class="TokenAnd" Example="true and false = false" />
<Token Word="or" Class="TokenOr" Example="true or false = true" />
<Token Word="not" Class="TokenNot" Example="not true = false" />
<Token Word="xor" Class="TokenXor" Example="true xor false = true" />
<!--以下為常量記號(hào)對(duì)象-->
<Token Word="pi" Class="TokenValue" Example="pi*1 = 3.1415926 " />
" />
<Token Word="e" Class="TokenValue" Example="e*1 = 2.71828" />
<Token Word="true" Class="TokenValue" Example="true and false = false" />
<Token Word="false" Class="TokenValue" Example="true and false = false" />
<!--以下為其他記號(hào)對(duì)象-->
<Token Word="if" Class="TokenIf" Example="if(3>5,12,24) = 24" />
</TokenKeyword>
<TokenSymbol>
<!--以下為分隔符-->
<Token Word="(" Class="TokenLeftBracket" Example="2*(5-3) = 4" />
<Token Word=")" Class="TokenRightBracket" Example="2*(5-3) = 4" />
<Token Word="," Class="TokenComma" Example="left('abcdefg',5) = 'abcde'" />
<!--以下為數(shù)學(xué)運(yùn)算符-->
<Token Word="+" Class="TokenPlus" Example="2+3 = 5 或 'abc' + 'def' = 'abcdef'" />
<Token Word="-" Class="TokenMinus" Example="5-3 = 2" />
<Token Word="*" Class="TokenMultiply" Example="3*4 = 12" />
<Token Word="/" Class="TokenDivide" Example="8/2 = 4" />
<Token Word="%" Class="TokenMod" Example="5.4%2 = 1.4" />
<!--如果希望求冪采用VB的^算法,形如2^3 = 8,將TokenPow修改為繼承自TokenArithmetic即可,此時(shí)用pow則必須輸入2 pow 3,pow后必須帶空格-->
<!--<Token Word="^" Class="TokenPow" Example="^(2,3) = 8" />-->
<!--以下為比較運(yùn)算符-->
<Token Word="=" Class="TokenEqual" Example="if(3=5,12,24) = 24" />
<Token Word="==" Class="TokenEqual" Example="if(3==5,12,24) = 24" />
<Token Word="<>" Class="TokenNotEqual" Example="if(3<>5,12,24) = 12" />
<Token Word="!=" Class="TokenNotEqual" Example="if(3!=5,12,24) = 12" />
<Token Word=">" Class="TokenGreatThan" Example="if(3>5,12,24) = 24" />
<Token Word=">=" Class="TokenGreatOrEqual" Example="if(3>=5,12,24) = 24" />
<Token Word="<" Class="TokenLessThan" Example="if(3<5,12,24) = 12" />
<Token Word="<=" Class="TokenLessOrEqual" Example="if(3<=5,12,24) = 12" />
<!--以下為邏輯運(yùn)算符,未定義短路操作,可自行實(shí)現(xiàn)-->
<Token Word="!" Class="TokenNot" Example="!true = false" />
<Token Word="&" Class="TokenAnd" Example="true & false = false" />
<Token Word="&&" Class="TokenAnd" Example="true && false = false" />
<Token Word="|" Class="TokenOr" Example="true | false = true" />
<Token Word="||" Class="TokenOr" Example="true || false = true" />
</TokenSymbol>
</TokenRecord>
接下來介紹各個(gè)工廠類。首先是關(guān)鍵字工廠TokenKeywordFactory。當(dāng)TokenFactory分析到英文字母的時(shí)候,把任務(wù)轉(zhuǎn)交給TokenKeywordFactory。該類從分析得到的第一個(gè)英文字母開始向后分析,如果后面還是英文字母或者數(shù)字,則繼續(xù)向后分析,否則結(jié)束分析。在這里關(guān)鍵字允許包含數(shù)字,但第一個(gè)字符必須是英文字母。分析結(jié)束后,截取分析得到的字符串,然后到交給ProduceToken方法產(chǎn)生一個(gè)TokenRecord類的實(shí)例。
在ProduceToken方法中,首先判斷傳入的字符串是否存在于關(guān)鍵字字典中,如果不存在則報(bào)錯(cuò),如果存在則用反射產(chǎn)生一個(gè)對(duì)應(yīng)類的實(shí)例。其中有些關(guān)鍵字是常量,所以進(jìn)行了特殊處理,需要設(shè)置記號(hào)對(duì)象的值和類型。
以上工作完成后,調(diào)整分析指針的位置,回到TokenFactory類,執(zhí)行后續(xù)分析。TokenKeywordFactory的代碼如下:
Code
/// <summary>
/// 關(guān)鍵字工廠
/// </summary>
/// <remarks>Author:Alex Leo</remarks>
internal class TokenKeywordFactory : TokenFactory
{
private static SortedDictionary<string, string> m_DictionaryKeyword = new SortedDictionary<string, string>();
/// <summary>
/// 獲取關(guān)鍵字字典
/// </summary>
/// <returns>關(guān)鍵字字典</returns>
/// <remarks>Author:Alex Leo; Date:2008-5-19;</remarks>
internal static SortedDictionary<string, string> GetKeywordDictionary()
{
if (m_DictionaryKeyword.Count == 0)
{
m_DictionaryKeyword = TokenFactory.GetOperateTokenDictionary(OperateTokenTypeEnum.TokenKeyword);
}
return m_DictionaryKeyword;
}
/// <summary>
/// 詞法分析
/// </summary>
/// <param name="TokenList">記號(hào)對(duì)象列表</param>
/// <param name="Code">源表達(dá)式</param>
/// <param name="Index">分析序號(hào)</param>
/// <remarks>Author:Alex Leo</remarks>
public static new void LexicalAnalysis(List<TokenRecord> TokenList, string Code, ref int Index)
{
int intIndexCurrent = Index;//當(dāng)前序號(hào)
bool blnContinue = true;
//string strTempChar = "";//獲取臨時(shí)字符
char chrTemp;
string strTempWord = "";//獲取臨時(shí)字符串
while (blnContinue && intIndexCurrent < Code.Length)
{
chrTemp = Code[intIndexCurrent];
//關(guān)鍵字支持大小寫字母及數(shù)字,但不允許以數(shù)字開頭
if (char.IsLetter(chrTemp) || char.IsDigit(chrTemp))
{
intIndexCurrent += 1;//把當(dāng)前序號(hào)后移
}
else
{
blnContinue = false;
}
}
strTempWord = Code.Substring(Index, intIndexCurrent - Index);//獲取臨時(shí)詞
TokenRecord Token = ProduceToken(strTempWord, Index);
TokenList.Add(Token);
Index = intIndexCurrent - 1;//設(shè)置指針到讀取結(jié)束位置
}
/// <summary>
/// 產(chǎn)生記號(hào)對(duì)象
/// </summary>
/// <param name="TokenWord">分析得到的單詞</param>
/// <param name="Index">當(dāng)前序號(hào)</param>
/// <returns>記號(hào)對(duì)象</returns>
/// <remarks>Author:Alex Leo</remarks>
protected static new TokenRecord ProduceToken(string TokenWord, int Index)
{
TokenRecord Token;
if (GetKeywordDictionary().ContainsKey(TokenWord.ToLower()))
{
string strFullClassName = "ConExpress.Calculator." + GetKeywordDictionary()[TokenWord.ToLower()];
Type TokenType = Type.GetType(strFullClassName);
Token = (TokenRecord)Activator.CreateInstance(TokenType, new object[] { Index, TokenWord.Length });
//對(duì)常數(shù)的特殊處理
switch (TokenWord.ToLower())
{
case "pi"://以下為常量記號(hào)對(duì)象
Token.TokenValueType = typeof(double);
Token.TokenValue = Math.PI;
break;
case "e":
Token.TokenValueType = typeof(double);
Token.TokenValue = Math.E;
break;
case "true":
Token.TokenValueType = typeof(bool);
Token.TokenValue = true;
break;
case "false":
Token.TokenValueType = typeof(bool);
Token.TokenValue = false;
break;
default:
break;
}
}
else
{
//錯(cuò)誤字符串,拋出錯(cuò)誤,語法錯(cuò)誤
throw new SyntaxException(Index, TokenWord.Length, "未知表達(dá)式:" + TokenWord);
}
return Token;
}//ProduceToken
}//class TokenKeywordFactory
TokenSymbolFactory運(yùn)算符工廠類的分析過程和TokenKeywordFactory基本相似。但是運(yùn)算符一般只包含一個(gè)字符或者兩個(gè)字符,就不需要一直向后分析了,只需要判斷運(yùn)算符字典中是否存在對(duì)應(yīng)的項(xiàng)即可。另外有些操作符的第一個(gè)字符是重復(fù)的,比如“>”和“>=”,這時(shí)候就需要判斷“>”之后是否還存在“=”。如果向后再截取一個(gè)字符,在字典中也存在對(duì)應(yīng)項(xiàng),則按雙字符運(yùn)算符處理,否則就是單字符運(yùn)算符。TokenSymbolFactory的代碼如下:
Code
/// <summary>
/// 運(yùn)算符工廠
/// </summary>
/// <remarks>Author:Alex Leo</remarks>
class TokenSymbolFactory : TokenFactory
{
private static SortedDictionary<string, string> m_DictionarySymbol = new SortedDictionary<string, string>();
/// <summary>
/// 獲取運(yùn)算符字典
/// </summary>
/// <returns>運(yùn)算符字典</returns>
/// <remarks>Author:Alex Leo; Date:2008-5-19;</remarks>
internal static SortedDictionary<string, string> GetSymbolDictionary()
{
if (m_DictionarySymbol.Count == 0)
{
m_DictionarySymbol = TokenFactory.GetOperateTokenDictionary(OperateTokenTypeEnum.TokenSymbol);
}
return m_DictionarySymbol;
}
/// <summary>
/// 詞法分析
/// </summary>
/// <param name="TokenList">記號(hào)對(duì)象列表</param>
/// <param name="Code">源表達(dá)式</param>
/// <param name="Index">分析序號(hào)</param>
/// <remarks>Author:Alex Leo</remarks>
public new static void LexicalAnalysis(List<TokenRecord> TokenList, string Code, ref int Index)
{
string strTempWord;
if ((Index < Code.Length - 1) && GetSymbolDictionary().ContainsKey(Code.Substring(Index, 2)))//如果是雙字節(jié)操作符
{
strTempWord = Code.Substring(Index, 2);
Index += 1;//指針后移一位
}
else
{
strTempWord = Code.Substring(Index, 1);
}
TokenRecord Token = ProduceToken(strTempWord, Index);
TokenList.Add(Token);
}
/// <summary>
/// 產(chǎn)生記號(hào)對(duì)象
/// </summary>
/// <param name="TokenWord">分析得到的單詞</param>
/// <param name="Index">當(dāng)前序號(hào)</param>
/// <returns>記號(hào)對(duì)象</returns>
/// <remarks>Author:Alex Leo</remarks>
protected new static TokenRecord ProduceToken(string TokenWord, int Index)
{
TokenRecord Token;
if (GetSymbolDictionary().ContainsKey(TokenWord.ToLower()))
{
string strFullClassName = "ConExpress.Calculator." + GetSymbolDictionary()[TokenWord.ToLower()];
Type TokenType = Type.GetType(strFullClassName);
Token = (TokenRecord)Activator.CreateInstance(TokenType, new object[] { Index, TokenWord.Length });
}
else
{
//錯(cuò)誤字符串,拋出錯(cuò)誤,語法錯(cuò)誤
throw new SyntaxException(Index, TokenWord.Length, "未知表達(dá)式:" + TokenWord);
}
return Token;
}//ProduceToken
}//class TokenSymbolFactory
TokenStringFactory字符串工廠類的分析是按照VB語法,只有引號(hào)需要轉(zhuǎn)義,用兩個(gè)引號(hào)即可,其他特殊字符不需要轉(zhuǎn)義。而且引號(hào)和JavaScript一樣,可以用大寫或者小寫,只要兩端匹配就可以了。如果在單引號(hào)標(biāo)記的字符串中包含雙引號(hào),則不需要轉(zhuǎn)義,雙引號(hào)標(biāo)記的字符串中出現(xiàn)單引號(hào)也不需要轉(zhuǎn)義。字符串的分析是以引號(hào)作為界定,向后分析的過程中,如果遇到與起始引號(hào)相同的字符,判斷后面是否存在重復(fù)引號(hào),存在則轉(zhuǎn)義,不存在則結(jié)束分析。將兩個(gè)引號(hào)之間的字符串截取,創(chuàng)建一個(gè)TokenValue對(duì)象,結(jié)束分析。TokenStringFactory代碼如下:
Code
/// <summary>
/// 字符串工廠
/// </summary>
/// <remarks>Author:Alex Leo</remarks>
class TokenStringFactory : TokenFactory
{
/// <summary>
/// 詞法分析
/// </summary>
/// <param name="TokenList">記號(hào)對(duì)象列表</param>
/// <param name="Code">源表達(dá)式</param>
/// <param name="Index">分析序號(hào)</param>
/// <remarks>Author:Alex Leo</remarks>
public new static void LexicalAnalysis(List<TokenRecord> TokenList, string Code, ref int Index)
{
string strQuotationMark = Code.Substring(Index, 1);//引號(hào),可以是單引號(hào),也可以是雙引號(hào)
int intIndexCurrent = Index + 1;//指向后一個(gè)字符
string strTempChar = "";//臨時(shí)字符
StringBuilder strTempWord = new StringBuilder();//臨時(shí)字符串
bool blnContinue = true;
while (blnContinue && intIndexCurrent < Code.Length)//循環(huán)直到標(biāo)志位置False或超出長度
{
strTempChar = Code.Substring(intIndexCurrent, 1);
if (strTempChar.Equals(strQuotationMark))//如果是字符串分隔符
{
if ((intIndexCurrent < Code.Length - 1)
&& Code.Substring(intIndexCurrent + 1, 1).Equals(strQuotationMark))//如果后面還是引號(hào),則進(jìn)行轉(zhuǎn)義,將兩個(gè)引號(hào)轉(zhuǎn)義為一個(gè)引號(hào)字符
{
strTempWord.Append(strQuotationMark);//添加一個(gè)引號(hào)字符到臨時(shí)字符串中
intIndexCurrent += 2;//向后移兩位
}
else
{
blnContinue = false;//遇到字符串結(jié)束引號(hào),退出
}
}
else
{
strTempWord.Append(strTempChar);//添加當(dāng)前字符到臨時(shí)字符串中
intIndexCurrent += 1;//向后移一位
}//if
}//while
TokenRecord Token = ProduceToken(strTempWord.ToString(), Index);
TokenList.Add(Token);
Index = intIndexCurrent;//指針移到當(dāng)前指針,即字符串結(jié)束引號(hào)
}//LexicalAnalysis
/// <summary>
/// 產(chǎn)生記號(hào)對(duì)象
/// </summary>
/// <param name="TokenWord">分析得到的單詞</param>
/// <param name="Index">當(dāng)前序號(hào)</param>
/// <returns>記號(hào)對(duì)象</returns>
/// <remarks>Author:Alex Leo</remarks>
public new static TokenRecord ProduceToken(string TokenWord, int Index)
{
TokenRecord Token = new TokenValue(Index, TokenWord.Length);
Token.TokenValue = TokenWord;
Token.TokenValueType = typeof(string);
return Token;
}
}//class TokenStringFactory
TokenNumberFactory數(shù)值工廠的分析最簡單,主要是判斷下一個(gè)字符是否是數(shù)字或者小數(shù)點(diǎn)。將分析得到的字符串轉(zhuǎn)換為double類型,然后賦值給創(chuàng)建的TokenValue對(duì)象即可。TokenNumberFactory代碼如下:
Code
/// <summary>
/// 數(shù)值工廠
/// </summary>
/// <remarks>Author:Alex Leo</remarks>
class TokenNumberFactory : TokenFactory
{
/// <summary>
/// 詞法分析
/// </summary>
/// <param name="TokenList">記號(hào)對(duì)象列表</param>
/// <param name="Code">源表達(dá)式</param>
/// <param name="Index">分析序號(hào)</param>
/// <remarks>Author:Alex Leo</remarks>
public new static void LexicalAnalysis(List<TokenRecord> TokenList, string Code, ref int Index)
{
int intIndexCurrent = Index;//指向后一個(gè)字符
bool blnContinue = true;
char chrTemp;
string strTempWord;
while (blnContinue && intIndexCurrent < Code.Length)
{
chrTemp = Code[intIndexCurrent];
if (char.IsDigit(chrTemp) || chrTemp.Equals('.'))
{
intIndexCurrent += 1;
}
else
{
blnContinue = false;
}
}//while
strTempWord = Code.Substring(Index, intIndexCurrent - Index);//取得臨時(shí)字符串
TokenRecord Token = ProduceToken(strTempWord, Index);
TokenList.Add(Token);
Index = intIndexCurrent - 1;//指針移到當(dāng)前指針的前一位,然后賦值給循環(huán)指針
}//LexicalAnalysis
/// <summary>
/// 產(chǎn)生記號(hào)對(duì)象
/// </summary>
/// <param name="TokenWord">分析得到的單詞</param>
/// <param name="Index">當(dāng)前序號(hào)</param>
/// <returns>記號(hào)對(duì)象</returns>
/// <remarks>Author:Alex Leo</remarks>
public new static TokenRecord ProduceToken(string TokenWord, int Index)
{
TokenRecord Token = new TokenValue(Index + 1, TokenWord.Length);
Token.TokenValueType = typeof(double);
double dblValue;
if (double.TryParse(TokenWord, out dblValue))
{
Token.TokenValue = dblValue;
}
else
{
throw new SyntaxException(Index, TokenWord.Length, "表達(dá)式 " + TokenWord + " 無法轉(zhuǎn)換成數(shù)值。");
}
return Token;
}//ProduceToken
}//class TokenNumberFactory
通過這些“工廠”類就可以完成把表達(dá)式分析成記號(hào)對(duì)象列表,為程序理解表達(dá)式做好了基礎(chǔ)工作。在下一篇中會(huì)介紹如何將記號(hào)對(duì)象分析成樹視圖,進(jìn)而通過樹視圖逐級(jí)求解。
代碼下載:
https://files.cnblogs.com/conexpress/ConExpress_MyCalculator.rar
Author:Alex Leo
Email:conexpress@qq.com
Blog:http://conexpress.cnblogs.com/


 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)