
《CPython Internals》閱讀筆記:p97-p117
《CPython Internals》學習第 7 天,p97-p117 總結,總計 21 頁。
一、技術總結
1.詞法分析(lexical analysis)
根據《Compilers-Principles, Techniques, and Tools》(《編譯原理》第2版)第 5 頁:The first phase of a compiler is called lexical analysis or scanning. The lexcical analyzer reads the stream of characters making up the source program and groups the characters into meaningful sequences called lexemes. For each lexeme, the lexical analyzer produces as output a token of the form <token-name, attribute-value> that is passes on to the subsequent phase, syntax analysis。
執行詞法分析(lexical analysis)的 component 稱為 lexical analyzer(有時候也稱為lexer, scanner, tokenizer)。
2.關于parser-tokenizer的一疑問
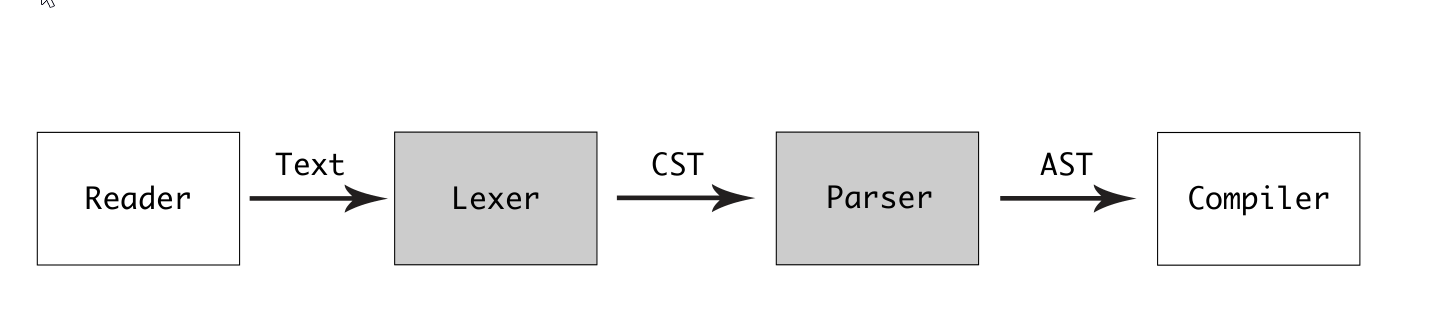
p92, Creating a concrete syntax tree using a parser-tokenizer, or lexer.
p92,The CST is created from a tokenizer and a parser.
說實話,我不是很理解作者為什么要將編譯流程畫成這樣,以及為什么要用 parser-tokenizer這個術語,這樣真是太混亂了。
流程圖以及第一句表明 lexer 的輸出是 CST, 但是第二句 CST的輸出來自于 tokenizer 和 parser,簡直就是前后矛盾。lexer 的輸出是 token, 所以才有 tokenizer 這個稱呼。 CST 是 parser 的輸出。
以及最后又流入到 compiler,也是很莫名其妙, lexer 和 parser 其實屬于 compiler。
3.AST
p102, The structure is a representation of the CST called an abstract syntax tree (AST).
p111,Abstract syntax tree (AST): A contextual tree representation of Python’s grammar and statements.
看完上面這兩個定義哪個讀者能不迷糊。
二、英語總結(生詞:0)
無。
關于英語的注解同步更新匯總到 https://github.com/codists/English-In-CS-Books 倉庫。
三、其它
Lexing and Parsing With Syntax Trees: 本章作者介紹比較混亂,如果讀者不熟悉編譯原理的知識,那么最好先補充下編譯原理知識,這樣才能更好的理解本章內容。
四、參考資料
1. 編程
(1) Anthony Shaw,《CPython Internals》:https://book.douban.com/subject/35405785/
2. 英語
(1) Etymology Dictionary:https://www.etymonline.com
(2) Cambridge Dictionary:https://dictionary.cambridge.org

歡迎搜索及關注:編程人(a_codists)

 浙公網安備 33010602011771號
浙公網安備 33010602011771號