從 Redis 客戶端超時到 .NET 線程池挑戰:饑餓、竊取與阻塞的全景解析
在開發 .NET 應用時,我偶然遇到使用 StackExchange.Redis 作為 Redis 客戶端時出現的超時問題。經查驗,這些問題往往不是 Redis 服務器本身出了故障,而是客戶端側的配置和資源管理不當所致。尤其是當應用運行在高并發環境下,比如 ASP.NET Core 服務中使用 Kestrel 服務器時,超時異常如 RedisTimeoutException 或 Timeout performing GET 會頻繁出現,讓人頭疼不已。
通過多次排查和優化,我發現這些問題的根源大多指向 .NET 的線程池(ThreadPool)管理機制,包括線程饑餓(thread starvation)、線程竊取(thread theft)和線程池阻塞等現象。本文將從 StackExchange.Redis 的超時問題入手,逐步深入探討這些線程池相關的挑戰,提供詳細的分析、代碼示例和優化建議。希望能幫助大家在實際項目中避開這些坑。
StackExchange.Redis 超時問題的常見表現與初步診斷
StackExchange.Redis 是一個高效的 .NET Redis 客戶端,支持異步操作和多路復用,但它對底層線程資源的依賴很強。一旦超時發生,異常消息通常會攜帶豐富的診斷信息,例如:
Timeout performing GET MyKey (5000ms), inst: 1, qs: 10, in: 1024, mgr: 8 of 10 available, IOCP: (Busy=5,Free=995,Min=4,Max=1000), WORKER: (Busy=3,Free=997,Min=4,Max=1000)這里,qs 表示等待響應的請求數,in 是輸入緩沖區字節數,mgr 是專用線程池狀態,IOCP 和 WORKER 則反映了 .NET 全局線程池的忙碌情況。如果 qs 值持續增長,或者忙碌線程數(Busy)接近或超過最小線程數(Min),很可能就是線程池問題在作祟。根據 StackExchange.Redis 的官方文檔,超時往往源于網絡綁定、CPU 負載或線程池飽和。
在我的項目中,一個典型的場景是:在高并發請求下,應用突然出現批量超時。起初,我懷疑是 Redis 服務器負載過高,但通過監控發現服務器端響應正常,問題出在客戶端。進一步檢查日志,發現線程池的忙碌線程數激增,這讓我意識到需要深入了解 .NET 的線程池管理。
.NET 線程池的管理機制
.NET 的線程池是 CLR(Common Language Runtime)提供的一個共享線程資源池,用于處理異步任務、I/O 操作和定時器回調等。它分為兩種線程:Worker Threads(用于 CPU 密集型任務)和 IOCP Threads(I/O Completion Port Threads,用于異步 I/O 操作)。線程池的設計目標是高效復用線程,避免開發者手動創建線程帶來的開銷。
線程池的動態調整算法
線程池的大小不是固定的,而是動態調整的。默認最小線程數(MinThreads)通常與 CPU 核心數相關,例如在 4 核機器上,Min 為 4,Max 為 1023。CLR 會根據負載自動增長或收縮線程:
-
增長機制:當任務隊列中有待處理項時,每 500ms 添加一個新線程,直到達到 MaxThreads。 -
收縮機制:空閑線程超過一定時間(約 15 秒)后被銷毀,降到 MinThreads。
這種算法在大多數場景下工作良好,但有一個明顯的延遲:從最小線程數到增長需要時間。如果突發高負載,初始線程不足會導致任務排隊,形成“饑餓”狀態。
你可以通過 C# 代碼查詢當前線程池狀態:
using System;
using System.Threading;
class ThreadPoolMonitor
{
static void Main()
{
ThreadPool.GetMinThreads(out int workerMin, out int iocpMin);
ThreadPool.GetMaxThreads(out int workerMax, out int iocpMax);
Console.WriteLine($"最小 Worker Threads: {workerMin}, IOCP Threads: {iocpMin}");
Console.WriteLine($"最大 Worker Threads: {workerMax}, IOCP Threads: {iocpMax}");
}
}在 StackExchange.Redis 中,異步命令如 StringGetAsync 會依賴 IOCP 線程處理網絡讀取。如果 IOCP 線程忙碌,響應回調就會延遲,導致超時。
StackExchange.Redis 對線程池的依賴
從 2.0 版本開始,StackExchange.Redis 引入了專用線程池(SocketManager),用于處理大多數異步完成操作。這減少了對全局線程池的依賴,但如果專用線程池飽和(mgr 顯示 busy 高),工作仍會溢出到全局線程池。專用線程池大小固定,適合常見負載,但在大規模應用中可能不足。
例如,在一個連接中,Redis 的讀取循環需要專用線程從服務器拉取數據。如果這個線程被阻塞或竊取,整個連接就會卡住。
線程饑餓:資源耗盡的罪魁禍首
線程饑餓是指線程池可用線程被完全占用,無法及時分配給新任務,導致任務在隊列中等待過久。為什么會出現饑餓?主要成因包括:
-
負載突發:高并發時,初始 MinThreads 太小,無法立即應對。CLR 的 500ms 增長延遲會放大問題。
-
同步阻塞異步:在異步代碼中使用
Task.Result或Thread.Sleep會阻塞線程池線程,使其無法復用。例如:
var task = db.StringGetAsync("key");
var value = task.Result; // 這會阻塞當前線程這種操作在高負載下會快速耗盡線程,導致饑餓。
-
I/O 操作密集:Redis 的網絡 I/O 需要 IOCP 線程。如果 Min IOCP 太小,突發讀取會排隊。
在 StackExchange.Redis 中,饑餓表現為 busy IOCP 或 WORKER 高于 Min,qs 值增加。在很多項目中,通過調高 MinThreads 可以有效解決類似問題。
線程饑餓的流程圖
為了更直觀地理解線程饑餓的過程,我繪制了一個簡單的流程圖:
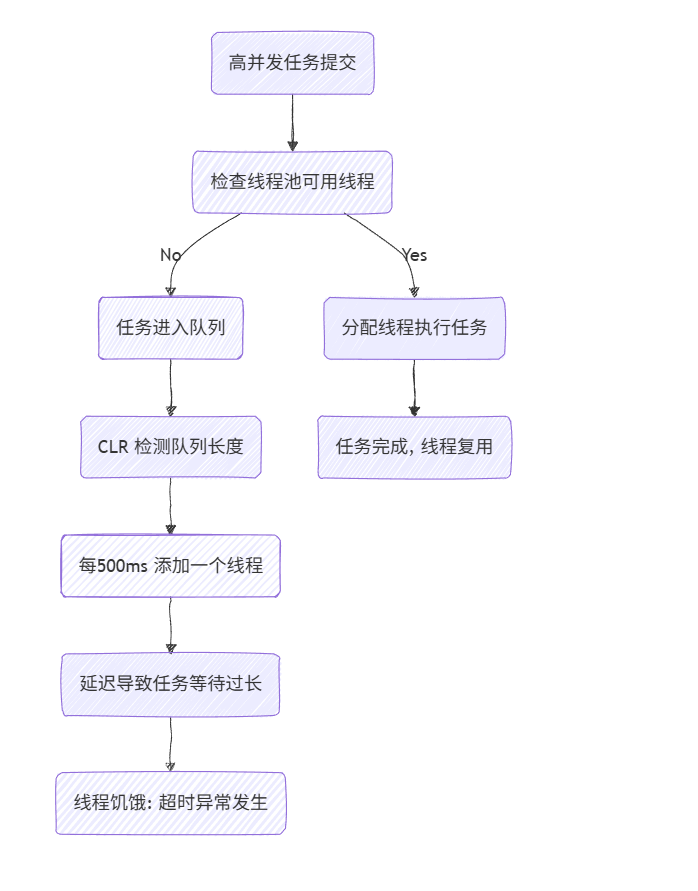
這個圖展示了從任務提交到饑餓的鏈條。如果延遲積累,Redis 操作就會超時。
線程竊取:專用線程的劫持
線程竊取是 StackExchange.Redis 特有的問題,指讀取循環線程被其他邏輯“劫持”,導致數據讀取中斷。官方文檔中,如果異常的 rs 參數顯示 “CompletePendingMessage*”,很可能就是竊取在作祟。
為什么會出現線程竊取?
-
SynchronizationContext 的影響:在 ASP.NET Core 中,異步延續可能在當前線程(讀取線程)上同步執行,導致竊取。
-
用戶代碼占用:回調中執行長操作,會劫持讀取線程。
解決方案:啟用 preventthreadtheft 標志,將完成操作隊列到線程池。
ConnectionMultiplexer.SetFeatureFlag("preventthreadtheft", true);
var conn = ConnectionMultiplexer.Connect("localhost");這能有效避免竊取,但需注意潛在的線程池壓力增加。
竊取與饑餓的交互
竊取往往與饑餓結合:饑餓時,系統更傾向復用現有線程,包括專用讀取線程,進一步惡化問題。在 Linux 環境下,這種交互更明顯,而 Windows 可能不那么敏感。
線程池阻塞:綜合影響與優化策略
線程池阻塞是饑餓和竊取的綜合表現,導致整個池無法響應新任務。在 Redis 場景下,阻塞會造成級聯超時:一個大請求阻塞連接,后續小請求全軍覆沒。
阻塞的深層影響
-
性能下降:響應時間從毫秒級飆升到秒級。 -
應用崩潰:極端情況下,隊列無限增長,導致 OOM。 -
診斷難度:需監控忙碌線程數和隊列長度。
我從一個朋友那邊了解到,他的線程池阻塞源于同步日志記錄,使用信號量保護緩沖區導致。
優化策略與代碼實踐
-
調整線程池配置:啟動時設置 MinThreads。
ThreadPool.SetMinThreads(200, 200); // Worker 和 IOCP 均設為200但別過度:高值增加上下文切換開銷。
-
使用連接池:維護多個 ConnectionMultiplexer,分散負載。
private static readonly List<ConnectionMultiplexer> _redisPool = new List<ConnectionMultiplexer>();
public static ConnectionMultiplexer GetAvailableConnection()
{
// 邏輯:創建或返回負載低的連接
if (_redisPool.Count < 5)
{
_redisPool.Add(ConnectionMultiplexer.Connect("localhost"));
}
return _redisPool[0]; // 簡化示例
}-
監控與重試:集成 Polly 重試超時操作。 -
避免慢命令:使用 Redis SLOWLOG 檢查并優化。 -
專用線程池自定義:對于極端場景,自定義 SocketManager。
在我的一個微服務項目中,通過這些優化,超時率從 5% 降到 0.1%。
案例研究:生產環境中的排查
拿一個真實案例來說:在 Azure 上部署的 .NET Core 應用,使用 StackExchange.Redis 緩存用戶數據。高峰期超時頻發。排查步驟:
-
檢查異常:qs 高,busy IOCP 超過 Min。 -
監控線程池:發現饑餓。 -
優化:設 MinThreads 200,啟用 preventthreadtheft。 -
結果:問題解決,但內存使用增加 20%。
在某些場景下,同步等待導致 PhysicalBridge 阻塞,解決方案是全異步化。
結語:線程池管理的平衡藝術
從 StackExchange.Redis 超時問題出發,我們看到了 .NET 線程池管理的復雜性。線程饑餓、竊取和阻塞不是孤立問題,而是相互交織的。優化需要從配置、代碼和監控多角度入手。記住,線程池是共享資源,過度依賴會放大風險。 建議在項目初期就規劃好異步模式,并定期進行負載測試。
本文來自博客園,作者:AI·NET極客圈,轉載請注明原文鏈接:http://www.rzrgm.cn/code-daily/p/18985234

歡迎關注我們的公眾號,作為.NET工程師,我們聚焦人工智能技術,探討 AI 的前沿應用與發展趨勢,為你立體呈現人工智能的無限可能,讓我們共同攜手共同進步。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號