高并發必修課:并行與并發的底層邏輯與內功修煉
?近日看到多篇有關并發和并行的文章,讀后有感,遂撰文梳理核心概念,以解其中之惑:
并發與并行是計算機科學中處理多任務執行的核心概念。并發關注任務的協調與交錯執行,而并行則強調任務的真正同時執行,以提升計算效率。這兩個術語常被混用,但實際上它們代表了不同的任務執行方式。
1. 引言
隨著計算需求的不斷增長,現代計算機系統正面臨前所未有的挑戰。從智能手機到超級計算機,多核處理器、分布式系統和云計算的廣泛應用使得并發與并行技術成為提升系統性能和響應能力的關鍵支柱。
并發通過管理多個任務的執行順序,確保系統在高負載下仍能保持響應性;并行則利用多處理器或多核心硬件,真正同時執行任務,以加速計算。這兩者在高性能計算、實時系統和用戶交互應用中發揮著不可替代的作用。
在多核處理器時代,傳統串行編程已無法充分利用硬件潛力。并行計算通過將任務分解到多個核心執行,顯著縮短了計算時間。然而,并發與并行的實現并非沒有代價,它們引入了諸如競爭條件、死鎖和負載均衡等復雜問題,需要開發者具備深厚的理論基礎和實踐經驗。
2. 并發與并行的理論基礎
2.1 定義
-
并發(Concurrency):
- 指系統在一段時間內管理多個任務的能力。并發關注任務的協調與交錯執行,通過時間分片等技術在一個或多個處理器上實現,因此并發看似同時進行,但不一定在同一時刻執行。
- 并發強調任務的邏輯組織和協調。
- 舉例:一個Web服務器可以并發處理多個客戶端請求,通過快速切換任務確保每個請求都能及時響應。
-
并行(Parallelism):
- 指多個任務在同一時刻真正同時執行,通常依賴于多核處理器或分布式系統。其核心目標是提升計算速度,通過將問題分解為獨立的子任務并同時處理。并行適用于計算密集型任務。
- 并行關注物理執行的并行性。
- 舉例:在并行矩陣乘法中,不同的核心可以同時計算矩陣的不同部分,從而顯著縮短總計算時間;科學模擬或圖像處理,其效果依賴于多核處理器、GPU或分布式計算系統的硬件支持。
2.2 區別
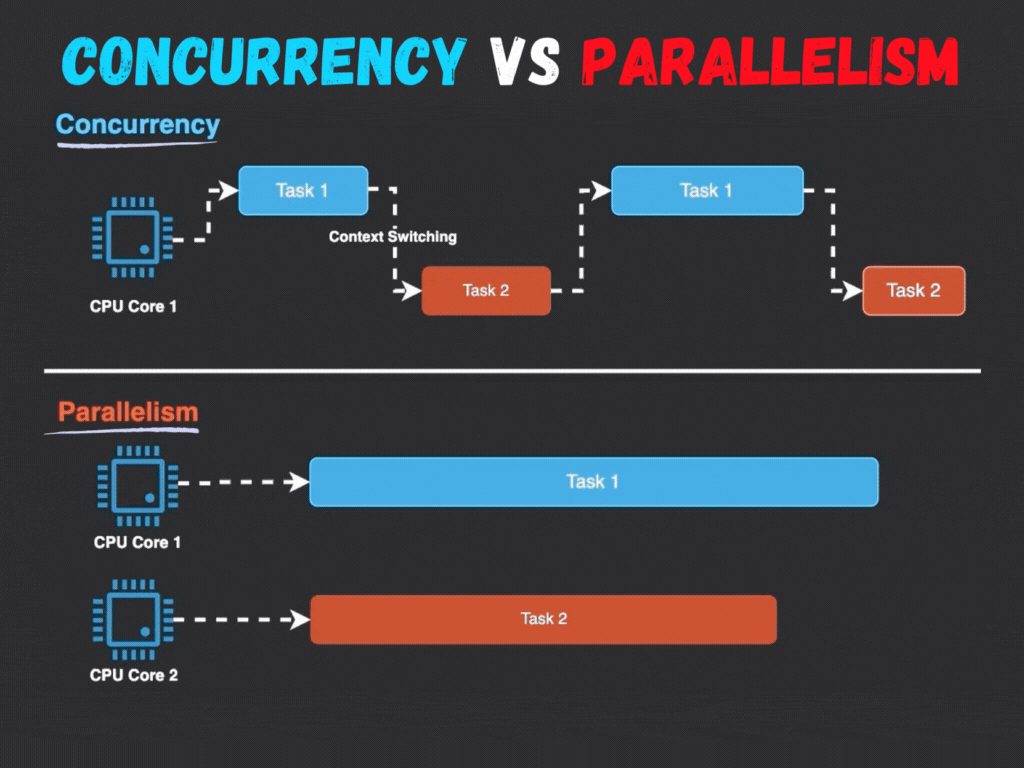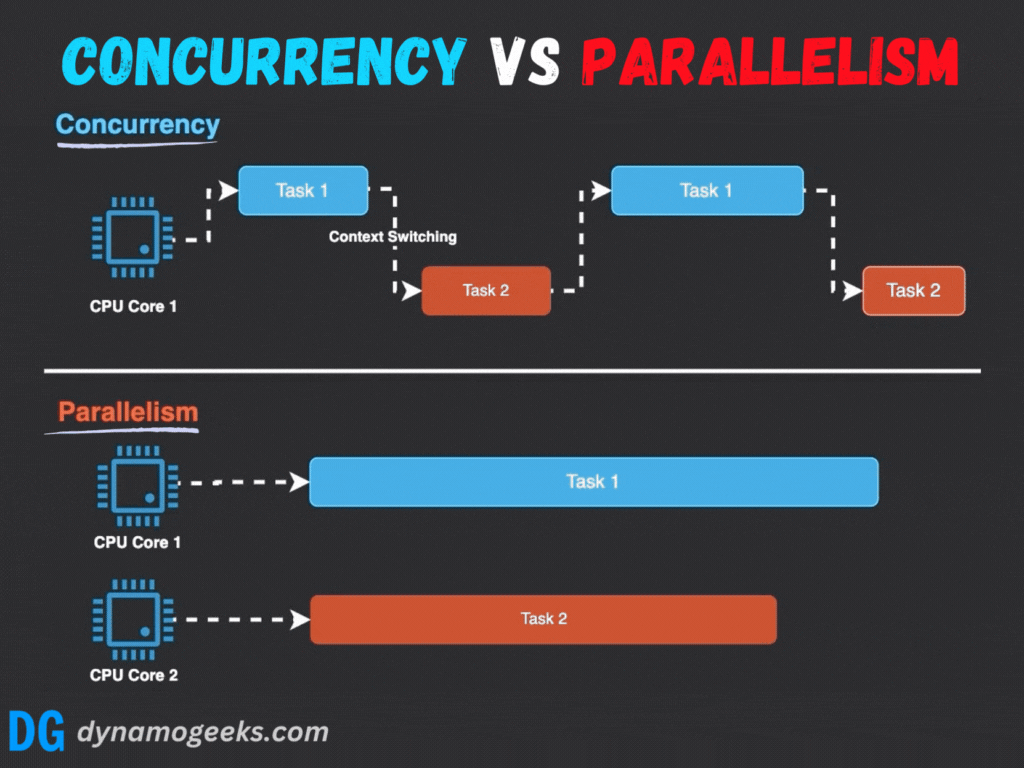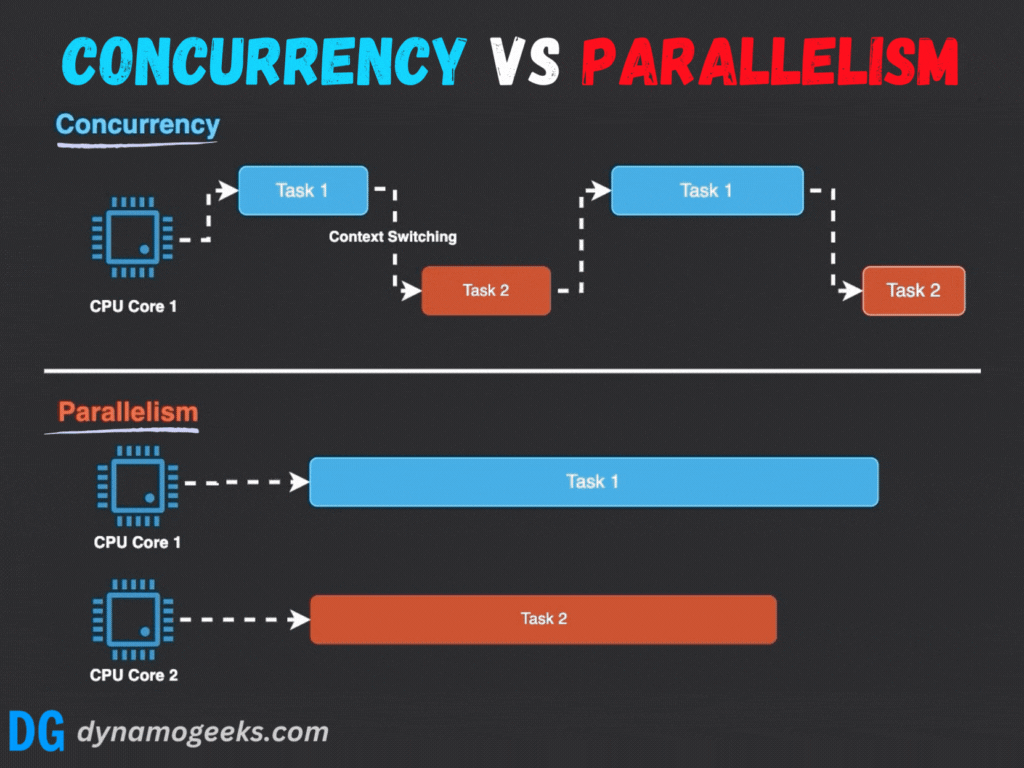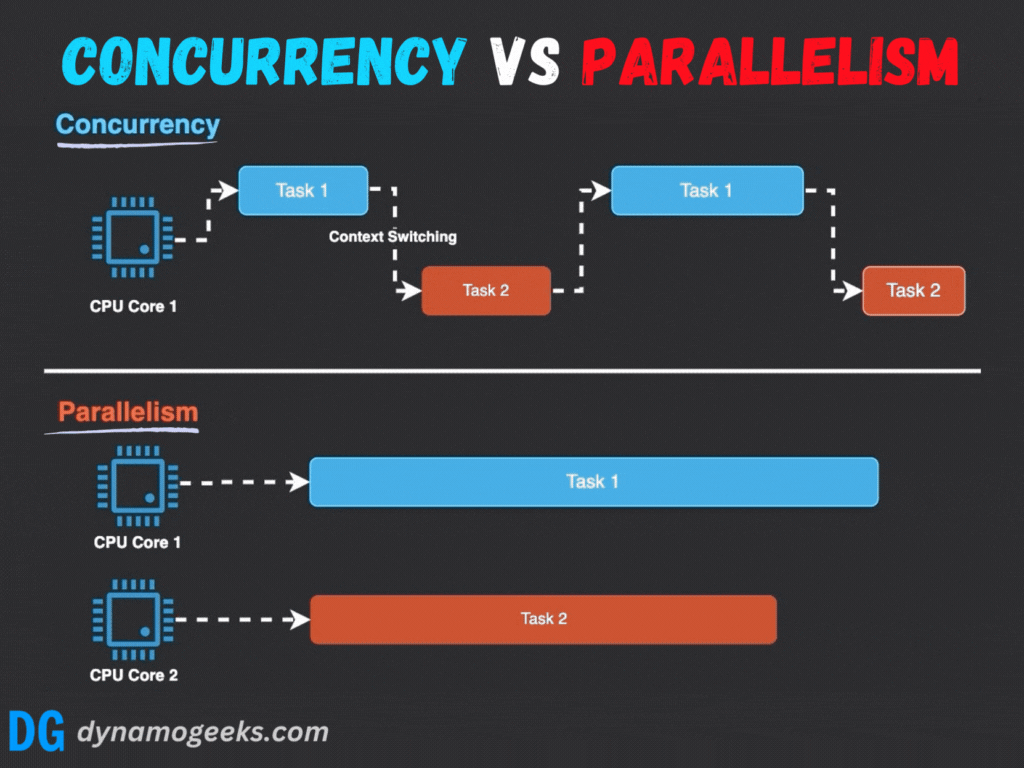
并發與并行的根本區別在于執行的時間性和資源依賴性:
- 執行模式:并行強調真正的同時執行,而并發通過任務切換營造同時進行的假象。
- 硬件依賴:并行需要多處理器或多核心支持,而并發在單核系統上即可實現。
- 目標:并行旨在加速計算,而并發注重系統響應性和多任務處理能力。
例如,在單核系統中,操作系統通過時間片輪轉調度多個線程;而多核系統中,線程可以分配到不同核心并行運行。
2.3 并發理論
并發理論為理解和管理多任務系統提供了形式化工具:
- 交錯執行(Interleaving):并發任務的執行可以看作動作序列的交錯組合。由于任務切換的非確定性,可能導致不同的執行路徑,增加了系統驗證的復雜性。
- 進程代數(Process Algebra):如通信順序進程(CSP)[Hoare, 1978],用于建模并發系統并驗證其性質,例如死鎖自由性。
- Petri網:一種圖形化工具,用于表示任務依賴、資源共享和并發行為,常用于系統設計和分析。
2.4 并行計算模型
并行計算依賴于理論模型來指導算法設計和性能分析:
-
Amdahl定律 [Amdahl, 1967]:量化了并行化的潛在加速比,指出加速受限于不可并行化的部分。其公式為: [ S = \frac{1}{(1 - P) + \frac{P}{N}} ] 其中 (S) 為加速比,(P) 為可并行化比例,(N) 為處理器數量。
-
Gustafson定律:與Amdahl定律相對,該定律認為隨著問題規模增加,并行的收益會更顯著,尤其適用于大數據處理。
-
PRAM模型(并行隨機訪問機):假設多個處理器共享內存并同步執行,用于分析并行算法的時間和空間復雜度。
這些理論為并發與并行的實現提供了堅實基礎,幫助開發者設計高效、可驗證的系統。
3. 實現并發
3.1 并行實現并發
在多核處理器上,任務可以分配到不同核心并行執行,從而實現高效并發。例如,Web服務器通過多線程并行處理客戶端請求。
偽代碼示例:多線程并行處理
function process_requests(requests):
thread_pool = create_thread_pool(num_cores) # 創建線程池
for request in requests:
thread_pool.submit(handle_request, request) # 提交任務
thread_pool.wait_for_completion() # 等待所有任務完成
function handle_request(request):
response = process(request) # 處理請求
send_response(response) # 發送響應3.2 任務調度
在單核處理器上,通過時間片輪轉等調度算法實現并發。操作系統在任務間快速切換,營造同時執行的假象。
偽代碼示例:時間片輪轉調度
function scheduler(tasks, time_slice):
while tasks not empty:
for task in tasks:
run_task(task, time_slice) # 執行任務一段時間
if task not finished:
requeue(task) # 未完成則重新排隊
else:
remove(task) # 完成后移除3.3 多線程
多線程通過創建多個執行單元實現并發。線程共享進程資源,通過同步機制(如互斥鎖)協調訪問。
偽代碼示例:多線程同步
mutex = create_mutex() # 創建互斥鎖
shared_data = initialize_data() # 初始化共享數據
function thread_function():
lock(mutex) # 加鎖
modify(shared_data) # 修改共享數據
unlock(mutex) # 解鎖3.4 異步編程
異步編程通過事件循環和回調函數處理I/O密集型任務,避免阻塞主線程。
偽代碼示例:異步I/O
function async_read(file, callback):
event_loop.add_task(read_file, file, callback) # 添加異步任務
function read_file(file, callback):
data = read_from_disk(file) # 讀取文件
callback(data) # 執行回調
# 事件循環
while True:
task = event_loop.get_next_task()
task.execute()3.5 協程
協程通過yield和resume機制在單線程內實現并發,適用于I/O密集型任務,具有低開銷優勢。
偽代碼示例:協程
function coroutine_example():
while True:
data = yield # 暫停并接收數據
process(data) # 處理數據
coroutine = coroutine_example()
coroutine.send(data) # 發送數據并恢復執行3.6 事件驅動
事件驅動編程通過事件循環監聽和處理事件,適用于GUI和網絡應用。
偽代碼示例:事件驅動
function event_loop():
while True:
event = wait_for_event() # 等待事件
handler = get_handler(event) # 獲取處理函數
handler(event) # 處理事件3.7 多進程
多進程通過創建獨立進程實現并發,進程間通過IPC(如管道或消息隊列)通信,適用于CPU密集型任務。
偽代碼示例:多進程
function main():
processes = []
for i in range(num_processes):
p = create_process(target=worker, args=(i,)) # 創建進程
processes.append(p)
p.start() # 啟動進程
for p in processes:
p.join() # 等待進程結束
function worker(id):
result = compute(id) # 執行計算任務
send_result(result) # 發送結果4. 實現并行的技術
4.1 多線程(Multithreading)
多線程通過在單個或多個處理器核心上運行多個線程來實現并行。在多核處理器上,線程可以真正并行執行;在單核處理器上,通過時間片切換實現偽并行。多線程適用于I/O密集型和計算密集型任務,能提高資源利用率和程序響應速度。
偽代碼示例:
// 創建并啟動多個線程
threads = []
for i in 1 to N:
thread = create_thread(task_function, args)
threads.append(thread)
start_thread(thread)
// 等待所有線程完成
for thread in threads:
join_thread(thread)
// 線程執行的函數
function task_function(args):
result = perform_task(args)
return result4.2 多進程(Multiprocessing)
多進程通過創建多個獨立進程實現并行,每個進程運行在不同的處理器核心上。進程間通過管道或消息隊列等通信機制協調工作。多進程適用于需要高隔離性和安全性的任務,如科學計算和服務器應用。
偽代碼示例:
// 創建并啟動多個進程
processes = []
for i in 1 to N:
process = create_process(target=worker_function, args=(i,))
processes.append(process)
start_process(process)
// 等待所有進程完成
for process in processes:
join_process(process)
// 進程執行的函數
function worker_function(id):
result = compute(id)
send_result(result)4.3 分布式計算(Distributed Computing)
分布式計算將任務分配到網絡中的多臺計算機上并行執行,通常使用消息傳遞接口(MPI)進行通信。適用于大規模數據處理和復雜計算任務,如天氣預報和分布式數據庫。
偽代碼示例:
// MPI 偽代碼示例
if rank == 0: // 主節點
data = load_data()
for worker in 1 to num_workers:
send_data(data_chunk, worker)
results = []
for worker in 1 to num_workers:
result = receive_result(worker)
results.append(result)
final_result = aggregate(results)
else: // 工作節點
data_chunk = receive_data(0)
result = process(data_chunk)
send_result(result, 0)4.4 GPU并行計算
GPU并行計算利用圖形處理單元(GPU)的多核心架構,通過CUDA或OpenCL等技術實現高度并行。適用于數據密集型任務,如圖像處理和機器學習。
偽代碼示例:
// CUDA 偽代碼示例
function gpu_kernel(input, output):
tid = get_thread_id()
if tid < input.size:
output[tid] = compute(input[tid])
// 主函數
input = load_input()
output = allocate_output()
launch_kernel(gpu_kernel, input, output)
synchronize() // 等待GPU完成4.5 任務并行(Task Parallelism)
任務并行將一個大任務分解為多個獨立子任務,并行執行這些子任務。適用于任務間依賴較少的場景,如編譯器并行處理多個文件。
偽代碼示例:
// 使用 OpenMP 實現任務并行
#pragma omp parallel
{
#pragma omp single
{
#pragma omp task
task1()
#pragma omp task
task2()
#pragma omp task
task3()
}
}4.6 數據并行(Data Parallelism)
數據并行將數據分割成多個部分,每個部分由不同的處理器或線程并行處理。適用于矩陣運算和圖像處理等數據密集型任務。
偽代碼示例:
// 使用 OpenMP 實現數據并行
#pragma omp parallel for
for i in 0 to N-1:
output[i] = compute(input[i])4.7 流水線并行(Pipeline Parallelism)
流水線并行將任務分解為一系列階段,每個階段由不同處理器或線程處理,形成處理流水線。適用于數據流處理和視頻編碼等場景。
偽代碼示例:
// 流水線并行偽代碼
function stage1(input):
intermediate1 = process_stage1(input)
return intermediate1
function stage2(intermediate1):
intermediate2 = process_stage2(intermediate1)
return intermediate2
function stage3(intermediate2):
output = process_stage3(intermediate2)
return output
// 在不同線程或處理器上執行各階段
thread1: stage1(input)
thread2: stage2(stage1_output)
thread3: stage3(stage2_output)4.8 Actor模型
Actor模型是一種并發計算模型,通過將系統分解為獨立執行的Actor來實現并發和并行。每個Actor可以通過消息傳遞與其他演員通信,避免共享內存和鎖的使用。常見的Actor模型有Orleans、Akka、Erlang等。
偽代碼示例:
// 創建兩個Actor
actor1 = create_actor(1)
actor2 = create_actor(2)
// Actor1 發送 Ping 消息給 Actor2
send_message(2, Ping, 1)
// Actor2 收到 Ping 后會回復 Pong 給 Actor1
// Actor1 收到 Pong 后打印消息
// 停止兩個Actor
send_message(1, Stop, 0) // 0可以是系統或主線程的ID
send_message(2, Stop, 0)5. 實踐應用
5.1 軟件開發中的并行應用
并行廣泛應用于需要高計算能力的場景,包括:
- 科學模擬:天氣預報、分子動力學等任務涉及大量方程求解,可通過并行化顯著加速。
- 機器學習:深度神經網絡訓練依賴矩陣運算,TensorFlow和PyTorch等框架利用GPU并行性加速訓練過程。
- 圖像與視頻處理:如3D渲染或視頻濾鏡應用,可將任務分配到多核或GPU上并行執行。
常見的并行編程模型包括:
- TPL:
TPL是.NET中用于并行編程的一個強大庫 - OpenMP:基于指令的共享內存并行
API,適用于C/C++和Fortran。 - MPI(消息傳遞接口):分布式內存并行的標準,用于高性能計算集群。
- CUDA:
NVIDIA的并行計算平臺,支持GPU上的細粒度并行。
5.2 軟件開發中的并發應用
并發在需要處理多任務或事件的系統中至關重要,例如:
- Web服務器:如
Apache和Nginx,通過多線程、多進程或事件驅動架構并發處理大量客戶端請求。 - 圖形用戶界面(GUI):并發確保界面在執行后臺任務(如數據加載)時仍能響應用戶輸入。
- 數據庫系統:通過鎖和事務等并發控制機制,管理多用戶對數據的并發訪問。
常見的并發模型包括:
- 多線程:C#、Java和C++提供線程庫(如
System.Thread、java.lang.Thread、std::thread)實現并發。 - 異步編程:Node.js和Python的
asyncio支持非阻塞代碼,適用于I/O密集型任務。 - Actor模型:Erlang和Akka框架通過獨立的Actor單元和消息傳遞實現并發,避免共享內存問題。
6. 并發與并行編程的挑戰
6.1 并發挑戰
并發引入了多個復雜問題:
- 競爭條件(Race Conditions):多個線程同時訪問共享資源,可能導致不可預測的結果。例如,未同步的計數器遞增可能丟失更新。
- 死鎖(Deadlocks):線程間相互等待對方釋放資源,導致永久阻塞。例如,兩個線程各自持有對方需要的鎖。
- 活鎖(Livelocks):線程不斷嘗試解決問題但無進展,如反復讓出資源。
- 饑餓(Starvation):某些線程因調度不公而無法獲得資源。
解決這些問題通常依賴同步原語(如互斥鎖、信號量),但過度同步可能降低性能。
6.2 并行挑戰
并行計算也有其難點:
- 負載均衡:確保所有處理器或核心均勻分擔工作量,避免部分核心空閑。
- 通信開銷:分布式系統中,節點間通信成本可能抵消并行收益。
- 可擴展性:隨著處理器數量增加,同步開銷或串行部分可能導致收益遞減。
并行算法需精心設計,采用動態負載均衡或工作竊取等技術應對這些挑戰。
7. 管理并行與并發的工具與技術
7.1 調試與測試
并發與并行程序的非確定性使其調試異常困難,常用工具包括:
- 靜態分析:如Intel Inspector或FindBugs,可在不運行代碼的情況下檢測潛在問題。
- 運行時驗證:Valgrind的Helgrind等工具在程序運行時監控同步錯誤。
- 測試框架:JUnit或pytest可擴展用于并發測試,模擬多線程場景。
7.2 設計模式
設計模式為常見問題提供解決方案:
- 線程池:管理固定數量的線程執行任務,減少創建和銷毀開銷。
- 生產者-消費者:生產者生成數據,消費者處理數據,通過同步隊列協調。
- Map-Reduce:將任務映射到數據分片并歸約結果,適用于大數據處理。
7.3 編程語言支持
現代語言內置了對并行與并發的支持:
- CSharp:通過
TPL和System.Collections.Concurrent等庫簡化并發和并行編程。 - Go:通過
goroutines和通道簡化并發編程。 - Rust:通過所有權模型在編譯時防止數據競爭。
- Java:提供
java.util.concurrent包,包括線程池、并發集合等高級工具。
8. 并行與并發的權衡
8.1 復雜度與性能
并行與并發提升性能的同時增加了代碼復雜度:
- 多線程:提供細粒度控制,但易引入競爭條件。
- 異步編程:避免線程開銷,但可能導致回調地獄或復雜邏輯。
8.2 共享內存與消息傳遞
并發模型分為兩種:
- 共享內存:線程共享數據,需同步以避免沖突,效率高但易出錯。
- 消息傳遞:通過消息通信避免共享狀態,安全性高但可能引入延遲。
如何選擇取決于性能、安全性和應用需求。
9. 結語
并行與并發是現代軟件開發不可或缺的技術,它們使系統能夠充分利用多核處理器和分布式環境,同時提升性能與響應性。盡管它們帶來復雜性和挑戰,但通過理論理解、工具支持和設計模式,開發者一定可以構建高效、可擴展的系統。
10. 參考文獻
- Lamport, L. (1979). "How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs." IEEE Transactions on Computers, 28(9), 690-691.
- Herlihy, M., & Shavit, N. (2008). The Art of Multiprocessor Programming. Morgan Kaufmann.
- Amdahl, G. M. (1967). "Validity of the Single Processor Approach to Achieving Large Scale Computing Capabilities." AFIPS Conference Proceedings, 30, 483-485.
- Hoare, C. A. R. (1978). "Communicating Sequential Processes." Communications of the ACM, 21(8), 666-677.
本文來自博客園,作者:AI·NET極客圈,轉載請注明原文鏈接:http://www.rzrgm.cn/code-daily/p/18812278

歡迎關注我們的公眾號,作為.NET工程師,我們聚焦人工智能技術,探討 AI 的前沿應用與發展趨勢,為你立體呈現人工智能的無限可能,讓我們共同攜手共同進步。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號