AI與.NET技術(shù)實(shí)操系列(八):使用Catalyst進(jìn)行自然語(yǔ)言處理
引言
自然語(yǔ)言處理(Natural Language Processing, NLP)是人工智能領(lǐng)域中最具活力和潛力的分支之一。從智能客服到機(jī)器翻譯,再到語(yǔ)音識(shí)別,NLP技術(shù)正以其強(qiáng)大的功能改變著我們的生活方式和工作模式。
Catalyst的推出極大降低了NLP技術(shù)的應(yīng)用門檻。它支持文本分類、實(shí)體識(shí)別等多種功能,并配備了詳盡的API文檔和預(yù)訓(xùn)練模型,讓開(kāi)發(fā)者能夠快速上手并構(gòu)建功能強(qiáng)大的應(yīng)用。無(wú)論是打造智能對(duì)話系統(tǒng)、自動(dòng)化文本分析工具,還是實(shí)時(shí)監(jiān)測(cè)平臺(tái),Catalyst都能提供可靠的支持。
本文將通過(guò)一個(gè)具體的實(shí)踐任務(wù)——使用Catalyst進(jìn)行操作,深入展示如何在.NET環(huán)境中應(yīng)用NLP技術(shù)。這個(gè)實(shí)踐任務(wù)貼近實(shí)際業(yè)務(wù)需求,不僅能幫助讀者掌握Catalyst的核心用法,還能加深對(duì)NLP基本原理的理解。
Catalyst簡(jiǎn)介
在深入實(shí)踐之前,我們先來(lái)了解Catalyst的本質(zhì)及其在NLP開(kāi)發(fā)中的價(jià)值。
什么是Catalyst?
Catalyst是一個(gè)開(kāi)源的.NET庫(kù),專為自然語(yǔ)言處理任務(wù)設(shè)計(jì),旨在為.NET開(kāi)發(fā)者提供一個(gè)簡(jiǎn)單而強(qiáng)大的工具集。它支持多種NLP功能,如文本分類、命名實(shí)體識(shí)別(NER)和詞性標(biāo)注,并通過(guò)直觀的API和預(yù)訓(xùn)練模型,幫助開(kāi)發(fā)者快速構(gòu)建和部署智能應(yīng)用。
Catalyst融合了先進(jìn)的機(jī)器學(xué)習(xí)和深度學(xué)習(xí)技術(shù),它與.NET生態(tài)系統(tǒng)無(wú)縫集成,開(kāi)發(fā)者可以使用C#或F#直接調(diào)用其功能,無(wú)需轉(zhuǎn)向Python或其他語(yǔ)言環(huán)境。
此外,Catalyst還支持與主流NLP框架(如Transformers、spaCy)的集成,使開(kāi)發(fā)者能夠輕松利用最新的技術(shù)成果。無(wú)論是處理簡(jiǎn)單的文本分類,還是構(gòu)建復(fù)雜的對(duì)話系統(tǒng),Catalyst都能提供靈活而高效的解決方案。
Catalyst的優(yōu)勢(shì)
相比其他NLP工具,Catalyst具有以下獨(dú)特優(yōu)勢(shì):
-
無(wú)縫集成:通過(guò)NuGet包分發(fā),開(kāi)發(fā)者可在Visual Studio等IDE中輕松安裝使用。 -
功能全面:支持文本分類、實(shí)體識(shí)別等多種任務(wù),覆蓋廣泛的應(yīng)用場(chǎng)景。 -
預(yù)訓(xùn)練支持:內(nèi)置多種預(yù)訓(xùn)練模型,開(kāi)箱即用,同時(shí)支持模型微調(diào)。 -
性能優(yōu)異:針對(duì).NET環(huán)境優(yōu)化,確保高效的數(shù)據(jù)處理和模型推理。 -
社區(qū)活躍:擁有開(kāi)放的社區(qū)支持,開(kāi)發(fā)者可通過(guò)GitHub等問(wèn)題平臺(tái)獲取幫助。
這些特性使Catalyst成為.NET開(kāi)發(fā)者探索NLP的理想選擇。無(wú)論你是初學(xué)者還是資深開(kāi)發(fā)者,都能借助Catalyst快速實(shí)現(xiàn)創(chuàng)意,開(kāi)發(fā)出智能化的應(yīng)用程序。
安裝和配置Catalyst
在使用Catalyst之前,我們需要完成其安裝和基本配置。以下是詳細(xì)步驟,確保你的開(kāi)發(fā)環(huán)境順利就緒。
安裝Catalyst
Catalyst通過(guò)NuGet包管理系統(tǒng)分發(fā),安裝過(guò)程簡(jiǎn)單明了:
-
打開(kāi)Visual Studio,創(chuàng)建一個(gè)新的.NET項(xiàng)目(如控制臺(tái)應(yīng)用程序)。 -
在解決方案資源管理器中,右鍵項(xiàng)目,選擇“管理NuGet包”。 -
在NuGet包管理器中搜索“Catalyst”,選擇最新版本的“Catalyst”核心包并安裝。 -
根據(jù)需求,可選安裝附加包,如“Catalyst.Models.Chinese”以加載中文預(yù)訓(xùn)練模型。
安裝完成后,項(xiàng)目將自動(dòng)引用Catalyst的程序集,你即可開(kāi)始編寫NLP代碼。
配置開(kāi)發(fā)環(huán)境
Catalyst的配置相對(duì)簡(jiǎn)單,通常無(wú)需復(fù)雜調(diào)整。為確保最佳體驗(yàn),建議以下設(shè)置:
-
目標(biāo)框架:項(xiàng)目需使用.NET Core 3.1或更高版本,以保證兼容性。 -
GPU加速(可選):若需使用GPU提升性能,需安裝CUDA工具包并配置環(huán)境變量,具體參考官方文檔。 -
模型下載:部分功能依賴預(yù)訓(xùn)練模型,Catalyst支持自動(dòng)下載,也可手動(dòng)指定路徑。
注意事項(xiàng)
-
版本匹配:確保Catalyst版本與項(xiàng)目框架一致,避免兼容性問(wèn)題。 -
網(wǎng)絡(luò)環(huán)境:首次使用可能需要下載模型,需確保網(wǎng)絡(luò)暢通。 -
開(kāi)源許可:Catalyst遵循MIT許可證,可自由使用和修改。
完成以上步驟,你的開(kāi)發(fā)環(huán)境已準(zhǔn)備就緒,可以進(jìn)入NLP開(kāi)發(fā)的實(shí)戰(zhàn)環(huán)節(jié)。
文本處理基礎(chǔ)
在進(jìn)一步使用之前,我們需要掌握文本處理的基本技能,包括文本加載、分詞、詞性標(biāo)注和清洗。這些操作是所有NLP任務(wù)的基礎(chǔ)。
文本加載與分詞
Catalyst提供了便捷的工具來(lái)加載和分詞文本。以下是一個(gè)中文的簡(jiǎn)單示例,注意安裝 NuGet 包Catalyst.Models.Chinese:
using Catalyst;
using Mosaik.Core;
string text = "你好, 朋友";
Catalyst.Models.Chinese.Register();
// 創(chuàng)建中文NLP管道
Pipeline? nlp = Pipeline.For(Language.Chinese);
// 處理文本
IDocument? doc = nlp.ProcessSingle(new Document(text, Language.Chinese));
// 輸出分詞結(jié)果
foreach (IToken? token in doc.ToTokenList())
{
Console.WriteLine(token.Value);
}
Console.WriteLine(doc.ToJson());輸出示例:
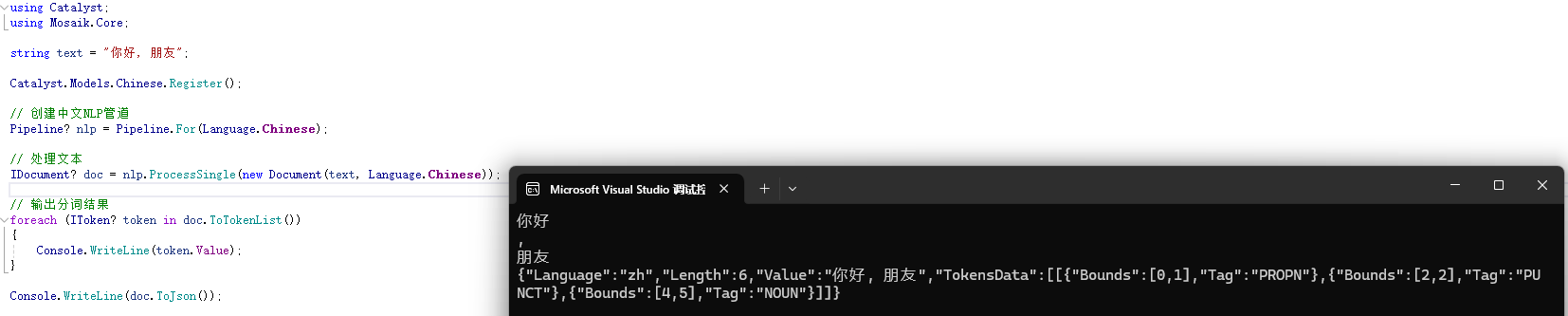
代碼解析:
-
Pipeline.For創(chuàng)建了一個(gè)針對(duì)英文的NLP處理管道。 -
Document封裝了輸入文本及其語(yǔ)言信息。 -
ProcessSingle對(duì)文本進(jìn)行分詞,Tokens屬性返回分詞結(jié)果。
詞性標(biāo)注
詞性標(biāo)注是NLP的核心任務(wù),用于識(shí)別每個(gè)詞的語(yǔ)法類別。Catalyst內(nèi)置支持:
// 輸出詞性標(biāo)注
foreach (var token in doc.ToTokenList)
{
Console.WriteLine($"{token.Value}: {token.POS}");
}輸出示例:

這里,token.POS返回詞性標(biāo)簽,如名詞(NOUN)、動(dòng)詞(PUNCT)等。
文本數(shù)據(jù)表示
Catalyst使用Document類表示文本數(shù)據(jù),包含原始文本、分詞結(jié)果和詞性信息等。例如:
Console.WriteLine($"語(yǔ)言: {doc.Language}");
Console.WriteLine($"分詞數(shù): {doc.TokensCount}");輸出示例:
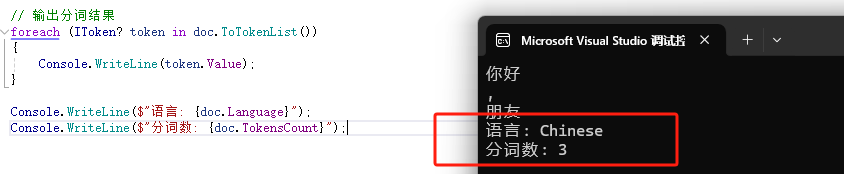
理解Document的結(jié)構(gòu)有助于后續(xù)的高級(jí)任務(wù)。
實(shí)體識(shí)別實(shí)踐
掌握文本處理后,我們將通過(guò)實(shí)體識(shí)別任務(wù)展示Catalyst的實(shí)戰(zhàn)能力。實(shí)體識(shí)別分析旨在判斷文本的實(shí)體,在信息提取、機(jī)器翻譯、問(wèn)答系統(tǒng)中應(yīng)用廣泛。
使用預(yù)訓(xùn)練模型
Catalyst提供預(yù)訓(xùn)練實(shí)體識(shí)別分析模型主要有三類:
-
Spotter:基于詞典的模型 -
PatternSpotter:基于正則的模型 -
AveragePerceptronEntityRecognizer:感知機(jī)模型
由于我嘗試了多次的中文文本,但都沒(méi)有取得比較好的效果,所以我改用了英文文本。
Spotter
Spotter 是 Catalyst(一個(gè) C# 自然語(yǔ)言處理庫(kù))中提供的一個(gè)實(shí)體識(shí)別工具,其主要作用是進(jìn)行 基于詞典的實(shí)體識(shí)別(Dictionary-based Entity Recognition)。它通過(guò)一個(gè)預(yù)定義的實(shí)體詞典,快速識(shí)別和標(biāo)注文本中的特定實(shí)體,適用于需要高效、定制化實(shí)體識(shí)別的場(chǎng)景。
主要功能
Spotter 的核心功能是通過(guò)匹配用戶提供的詞典來(lái)識(shí)別文本中的實(shí)體,具體包括:
-
詞典匹配:將文本中的詞或短語(yǔ)與預(yù)定義的實(shí)體列表進(jìn)行精確匹配。 -
實(shí)體標(biāo)注:將匹配到的文本片段標(biāo)注為用戶指定的實(shí)體類型,例如“編程語(yǔ)言”、“公司名稱”等。 -
快速處理:基于詞典的直接查找使其速度快,適合實(shí)時(shí)或輕量級(jí)應(yīng)用。
工作原理:
-
構(gòu)建詞典:用戶需要為 Spotter提供一個(gè)包含目標(biāo)實(shí)體的詞典,詞典條目可以是單個(gè)詞(如“C#”)或短語(yǔ)(如“New York”)。 -
文本匹配:在處理輸入文本時(shí), Spotter將文本分詞(tokens)后,與詞典中的實(shí)體進(jìn)行逐一比對(duì)。 -
標(biāo)注實(shí)體:當(dāng)發(fā)現(xiàn)匹配時(shí), Spotter會(huì)為該文本片段添加實(shí)體標(biāo)簽,例如標(biāo)記“C#”為“ProgrammingLanguage”。
此外,Spotter 支持一些靈活性設(shè)置,例如通過(guò) IgnoreCase 屬性忽略大小寫,從而提高匹配的適應(yīng)性。
使用場(chǎng)景:
-
專有名詞:如人名、地點(diǎn)、組織名稱(例如“Microsoft”)。 -
技術(shù)術(shù)語(yǔ):如編程語(yǔ)言(“Python”)、科學(xué)名詞等。 -
自定義實(shí)體:用戶可以根據(jù)需求定義特定領(lǐng)域的實(shí)體列表,例如產(chǎn)品名稱或品牌。 -
快速原型開(kāi)發(fā):在需要快速實(shí)現(xiàn)實(shí)體識(shí)別功能的場(chǎng)景中, Spotter是一個(gè)簡(jiǎn)單高效的選擇。
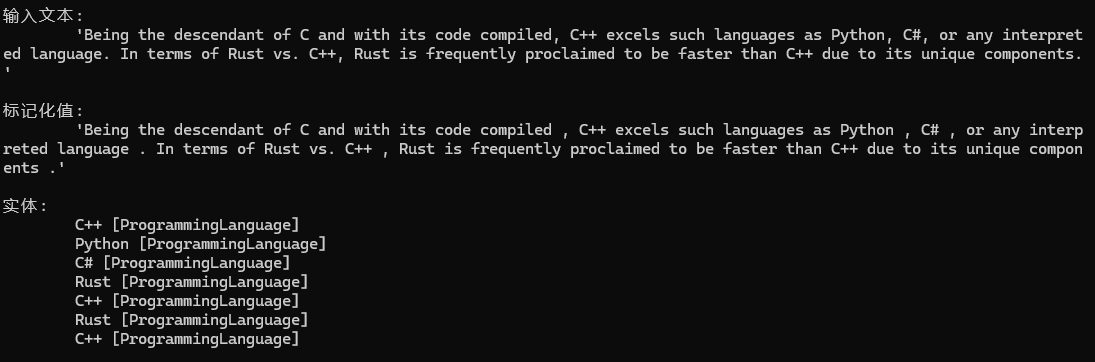
使用方式
Spotter spotter = new Spotter(Language.Any, 0, "programming", "ProgrammingLanguage")
{
Data =
{
IgnoreCase = true
}
};
spotter.AddEntry("C#");
spotter.AddEntry("Python");
spotter.AddEntry("Python 3");// 條目可以有多個(gè)詞,會(huì)自動(dòng)在空格處進(jìn)行標(biāo)記化
spotter.AddEntry("C++");
spotter.AddEntry("Rust");
spotter.AddEntry("Java");
Pipeline? nlp = Pipeline.TokenizerFor(Language.English);
nlp.Add(spotter);
Document docAboutProgramming = new Document(Data.SampleProgramming, Language.English);
nlp.ProcessSingle(docAboutProgramming);
PrintDocumentEntities(docAboutProgramming);輸出示例
PatternSpotter
該類的主要作用是進(jìn)行基于模式的實(shí)體識(shí)別(Pattern-based Entity Recognition),允許用戶通過(guò)定義自定義的語(yǔ)言模式來(lái)識(shí)別和標(biāo)注文本中的特定實(shí)體或結(jié)構(gòu)。
主要功能
PatternSpotter 提供了一種靈活的方式,用于在文本中識(shí)別符合特定語(yǔ)言規(guī)則的片段,例如:
-
語(yǔ)法結(jié)構(gòu):如 "is a" 后面的名詞短語(yǔ)。 -
詞性組合:如動(dòng)詞后跟多個(gè)名詞或?qū)S忻~。 -
自定義實(shí)體:根據(jù)用戶定義的規(guī)則識(shí)別特定類型的實(shí)體。
這種方法類似于使用正則表達(dá)式進(jìn)行文本匹配,但 PatternSpotter 是在標(biāo)記化(tokenized)的文本上操作,結(jié)合了詞性(POS)、實(shí)體類型等語(yǔ)言特征,使得模式匹配更加智能和精確。
工作原理
-
定義模式:用戶通過(guò) PatternSpotter 類定義一個(gè)或多個(gè)模式,這些模式可以基于詞性、詞形、實(shí)體類型等特征。 -
文本:在處理文本時(shí),PatternSpotter 會(huì)掃描標(biāo)記化的文本,尋找與定義的模式相匹配的片段。 -
標(biāo)注實(shí)體:一旦找到匹配的片段,PatternSpotter 會(huì)將這些片段標(biāo)注為用戶指定的實(shí)體類型。
使用場(chǎng)景
-
義實(shí)體識(shí)別:識(shí)別特定領(lǐng)域中的專有術(shù)語(yǔ),如法律文件中的法律條款或醫(yī)療文本中的疾病名稱。 -
關(guān)系抽取:識(shí)別文本中的特定關(guān)系模式,如 "X 是 Y" 結(jié)構(gòu)中的 X 和 Y。 -
文本結(jié)構(gòu)分析:識(shí)別文本中的特定句法結(jié)構(gòu),如引用、列表等。
使用方式
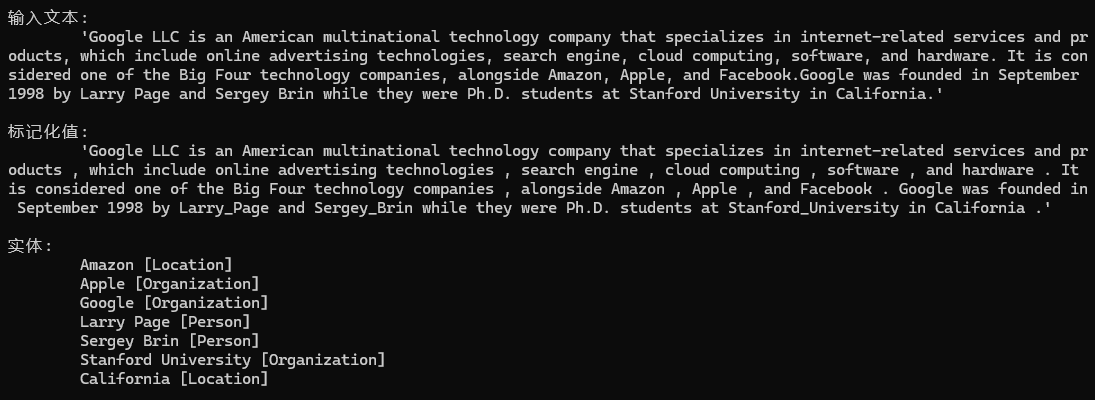
PatternSpotter isApattern = new PatternSpotter(Language.English, 0, tag: "is-a-pattern", captureTag: "IsA");
isApattern.NewPattern(
"Is+Noun",
mp => mp.Add(
new PatternUnit(P.Single().WithToken("is").WithPOS(PartOfSpeech.VERB)),
new PatternUnit(P.Multiple().WithPOS(PartOfSpeech.NOUN, PartOfSpeech.PROPN, PartOfSpeech.AUX, PartOfSpeech.DET, PartOfSpeech.ADJ))
));
nlp.Add(isApattern);輸出示例1
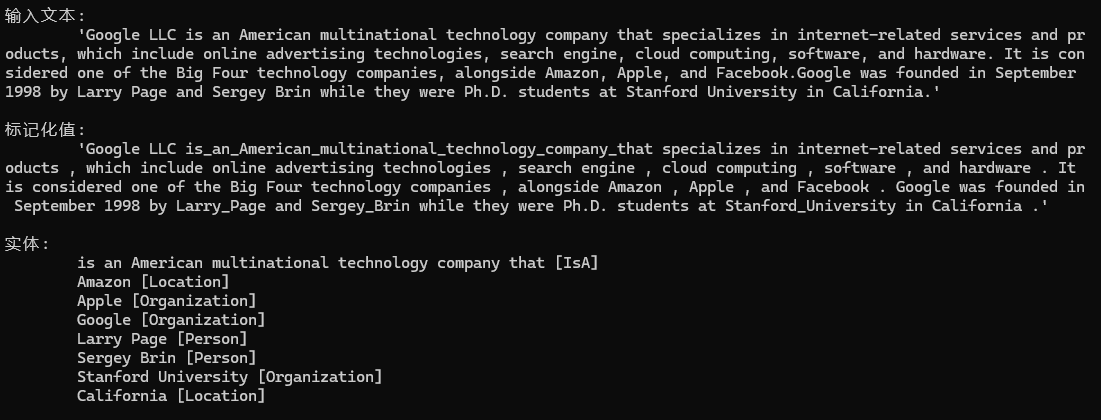
在這個(gè)示例里面Amazon既是地點(diǎn)名稱,又是企業(yè)組織的名稱,所以可以考慮使用糾錯(cuò)類Neuralyzer,幫助我們得到想要的答案。
Neuralyzer neuralizer = new Neuralyzer(Language.English, 0, "WikiNER-sample-fixes");
neuralizer.TeachForgetPattern("Location", "Amazon", mp => mp.Add(new PatternUnit(P.Single().WithToken("Amazon").WithEntityType("Location"))));
neuralizer.TeachAddPattern("Organization", "Amazon", mp => mp.Add(new PatternUnit(P.Single().WithToken("Amazon"))));
// 將 Neuralyzer 添加到管道中
nlp.UseNeuralyzer(neuralizer);輸出示例2
現(xiàn)在你可以看到Amazon被正確識(shí)別為實(shí)體類型Organization.
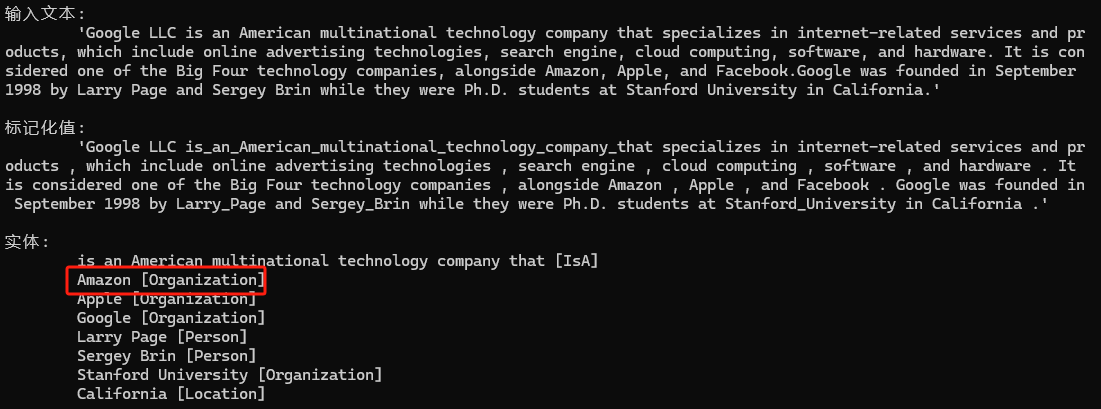
AveragePerceptronEntityRecognizer
利用平均感知機(jī)(Average Perceptron)算法來(lái)訓(xùn)練和執(zhí)行實(shí)體識(shí)別任務(wù)。
AveragePerceptronEntityRecognizer 利用平均感知機(jī)(Average Perceptron)算法來(lái)訓(xùn)練和執(zhí)行實(shí)體識(shí)別任務(wù)。它的核心功能包括:
主要功能
-
訓(xùn)練模型:通過(guò)帶標(biāo)簽的訓(xùn)練數(shù)據(jù)(如 WikiNER 數(shù)據(jù)集),學(xué)習(xí)如何識(shí)別不同類型的實(shí)體。 -
實(shí)體識(shí)別:對(duì)新的文本進(jìn)行處理,識(shí)別并標(biāo)注出其中的命名實(shí)體。 -
多語(yǔ)言支持:支持多種語(yǔ)言的實(shí)體識(shí)別,適應(yīng)不同語(yǔ)言環(huán)境下的需求。
2.##### 工作原理
-
特征提取:將輸入文本分解為標(biāo)記(tokens),并提取每個(gè)標(biāo)記的特征,例如詞形、詞性、上下文信息等。 -
分類:使用平均感知機(jī)算法對(duì)每個(gè)標(biāo)記進(jìn)行分類,判斷其是否屬于某個(gè)實(shí)體類別。 -
實(shí)體標(biāo)注:根據(jù)分類結(jié)果,將連續(xù)的標(biāo)記組合成完整的實(shí)體,并賦予相應(yīng)的標(biāo)簽(如“人名”、“地點(diǎn)”)。
平均感知機(jī)算法是感知機(jī)的一種改進(jìn)版本,通過(guò)對(duì)多次迭代的權(quán)重取平均值,提升了模型的穩(wěn)定性和泛化能力,使其在處理大規(guī)模文本數(shù)據(jù)時(shí)表現(xiàn)更為出色。
使用場(chǎng)景
-
信息抽取:從新聞文章、社交媒體等文本中提取關(guān)鍵信息,如公司名稱、事件地點(diǎn)等。 -
問(wèn)答系統(tǒng):識(shí)別用戶提問(wèn)中的實(shí)體,以便提供更精準(zhǔn)的回答。 -
文本分析:作為預(yù)處理步驟,為情感分析、主題建模等任務(wù)提供實(shí)體信息。
它通過(guò)高效的訓(xùn)練和識(shí)別能力,幫助開(kāi)發(fā)者從文本中提取結(jié)構(gòu)化的實(shí)體信息,適用于多種 NLP 應(yīng)用場(chǎng)景。
使用方式
本示例使用預(yù)訓(xùn)練的 WikiNER 模型,詳情請(qǐng)查看 https://github.com/dice-group/FOX/tree/master/input/Wikiner。
為英文創(chuàng)建一個(gè)新的管道,并將 WikiNER 模型添加到其中
Pipeline? nlp = await Pipeline.ForAsync(Language.English);
nlp.Add(await AveragePerceptronEntityRecognizer.FromStoreAsync(language: Language.English, version: Version.Latest, tag: "WikiNER"));輸出示例
技術(shù)倫理
Catalyst不僅是一款工具,更啟發(fā)我們思考NLP的深層問(wèn)題:
-
倫理考量:模型偏見(jiàn)可能導(dǎo)致不公,開(kāi)發(fā)者需確保公平性。 -
隱私權(quán)衡:數(shù)據(jù)處理需兼顧功能與用戶權(quán)益。
?這些擔(dān)憂提醒我們,開(kāi)發(fā)者需要具備技術(shù)與倫理的雙重素養(yǎng)。
結(jié)語(yǔ)
本文通過(guò)Catalyst的基礎(chǔ)知識(shí)、安裝配置、文本處理、實(shí)體識(shí)別分析實(shí)踐及意義挑戰(zhàn)的全面探討,為.NET開(kāi)發(fā)者提供了一份深入的NLP指南。Catalyst以其易用性和強(qiáng)大功能,為開(kāi)發(fā)者開(kāi)啟了智能語(yǔ)言處理的大門。希望你能從中獲得啟發(fā),加深自己對(duì).NET的理解和使用!
參考鏈接
https://github.com/curiosity-ai/catalyst/blob/master/samples/EntityRecognition/Program.cs
本文來(lái)自博客園,作者:AI·NET極客圈,轉(zhuǎn)載請(qǐng)注明原文鏈接:http://www.rzrgm.cn/code-daily/p/18776627

歡迎關(guān)注我們的公眾號(hào),作為.NET工程師,我們聚焦人工智能技術(shù),探討 AI 的前沿應(yīng)用與發(fā)展趨勢(shì),為你立體呈現(xiàn)人工智能的無(wú)限可能,讓我們共同攜手共同進(jìn)步。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)