
讓ChatBI理解業(yè)務(wù):從“行話”到“黑話”的精準(zhǔn)詞典配置之道
探究如何通過構(gòu)建企業(yè)專屬業(yè)務(wù)術(shù)語詞典,從根本上提升ChatBI的語義理解與問答準(zhǔn)確率。
ChatBI(聊天式商業(yè)智能)的出現(xiàn),為企業(yè)數(shù)據(jù)分析帶來了革命性的變革。它承諾讓每一位業(yè)務(wù)人員都能通過自然語言與數(shù)據(jù)對(duì)話,從而實(shí)現(xiàn)數(shù)據(jù)的民主化。然而,理想與現(xiàn)實(shí)之間往往存在一道鴻溝——許多企業(yè)在引入ChatBI后發(fā)現(xiàn),它似乎總是“聽不懂”內(nèi)部的“行話”和“黑話”,導(dǎo)致問答準(zhǔn)確率低下,用戶體驗(yàn)不佳,最終淪為昂貴的“玩具”。
問題的根源在于語義理解的鴻溝。通用的AI模型并未針對(duì)特定企業(yè)的業(yè)務(wù)場(chǎng)景進(jìn)行訓(xùn)練,無法理解企業(yè)內(nèi)部獨(dú)特的指標(biāo)定義、行業(yè)術(shù)語和業(yè)務(wù)邏輯。本文旨在提供一套可操作的指南,闡述如何通過配置精準(zhǔn)的業(yè)務(wù)術(shù)語詞典,系統(tǒng)性地提升ChatBI的“智商”,并以DataFocus產(chǎn)品為例,展示如何將理論付諸實(shí)踐,讓您的ChatBI真正成為懂業(yè)務(wù)的智能分析伙伴。
一、語義鴻溝:為何你的ChatBI總是“答非所問”?
在將自然語言查詢轉(zhuǎn)化為可執(zhí)行的數(shù)據(jù)庫語言(如SQL)的過程中,ChatBI面臨著諸多挑戰(zhàn)。當(dāng)這些挑戰(zhàn)與企業(yè)復(fù)雜的業(yè)務(wù)場(chǎng)景相疊加時(shí),問題便愈發(fā)突出。市面上的ChatBI工具,若單純依賴大模型直接生成SQL,其查詢準(zhǔn)確率往往不盡人意,尤其在跨表查詢時(shí)問題更為嚴(yán)重。
企業(yè)在數(shù)據(jù)分析與決策中普遍面臨數(shù)據(jù)口徑混亂、使用門檻高等挑戰(zhàn)
1. 業(yè)務(wù)術(shù)語的“行話”壁壘
每個(gè)行業(yè)、每家企業(yè)都有其獨(dú)特的“行話”。例如,電商領(lǐng)域的“GMV”、“客單價(jià)”、“連帶率”,金融領(lǐng)域的“AUM”、“NPL”等。這些術(shù)語背后往往蘊(yùn)含著復(fù)雜的業(yè)務(wù)邏輯。例如,用戶提問“過去一個(gè)季度的GMV是多少?”,一個(gè)未經(jīng)配置的ChatBI可能完全無法理解“GMV”的含義,或者錯(cuò)誤地將其等同于“銷售總額”,從而導(dǎo)致分析結(jié)果失之毫厘,謬以千里。
2. 數(shù)據(jù)口徑的“黑話”困境
“黑話”指的是企業(yè)內(nèi)部約定俗成的非標(biāo)準(zhǔn)用語或特定數(shù)據(jù)統(tǒng)計(jì)口徑。比如,某公司將“華東大區(qū)”定義為“江浙滬皖”四個(gè)省份,或者將“核心用戶”定義為“近30天內(nèi)登錄超過15天且有過付費(fèi)行為的用戶”。這些規(guī)則并未顯式存儲(chǔ)在數(shù)據(jù)庫的任何地方,AI模型無從知曉,自然也無法正確處理“查詢?nèi)A東大區(qū)的銷售額”或“統(tǒng)計(jì)核心用戶數(shù)”這類問題。
3. 自然語言的固有模糊性
即便是日常用語,也充滿了模糊性。用戶提問“上個(gè)月的熱銷產(chǎn)品”,這里的“熱銷”是指按銷售額、銷量還是利潤(rùn)排名?“上個(gè)月”是指自然月還是最近30天?缺乏明確上下文時(shí),AI只能進(jìn)行猜測(cè),而這種猜測(cè)往往是錯(cuò)誤的根源。根據(jù)相關(guān)研究,語義模糊與歧義是導(dǎo)致NL2SQL(自然語言轉(zhuǎn)SQL)出錯(cuò)的主要風(fēng)險(xiǎn)之一。
4. “黑盒”操作引發(fā)的信任危機(jī)
當(dāng)用戶無法理解ChatBI為何會(huì)給出錯(cuò)誤的答案時(shí),他們對(duì)工具的信任感會(huì)迅速下降。這種“黑盒”式的交互體驗(yàn),讓用戶感覺工具不可控、不可靠,最終導(dǎo)致其被束之高閣,企業(yè)的數(shù)據(jù)民主化進(jìn)程也因此受阻。
二、精準(zhǔn)詞典:從NL2SQL到NL2DSL2SQL的進(jìn)化
要從根本上解決上述問題,需要將技術(shù)路徑從簡(jiǎn)單的“自然語言直譯SQL”(NL2SQL)升級(jí)為更穩(wěn)健的“自然語言 → 領(lǐng)域特定語言 → SQL”(NL2DSL2SQL)架構(gòu)。這里的“領(lǐng)域特定語言”(Domain-Specific Language, DSL)正是我們所說的“精準(zhǔn)業(yè)務(wù)詞典”的技術(shù)體現(xiàn),它充當(dāng)了業(yè)務(wù)語言和機(jī)器語言之間的翻譯官和規(guī)則仲裁者。
根據(jù)學(xué)術(shù)研究,NL2DSL2SQL架構(gòu)將自然語言首先映射到一個(gè)結(jié)構(gòu)化的中間語言(DSL),再由DSL確定性地生成SQL。這種方式帶來了更強(qiáng)的語義約束、更易于校驗(yàn)和審計(jì),是企業(yè)級(jí)NL2SQL的實(shí)用設(shè)計(jì)模式。
這個(gè)作為“語義層”的業(yè)務(wù)詞典,其核心價(jià)值在于:
- 統(tǒng)一數(shù)據(jù)口徑:將模糊的業(yè)務(wù)概念(如“GMV”)轉(zhuǎn)化為精確、唯一的計(jì)算公式,確保全公司使用同一套標(biāo)準(zhǔn)。
- 消除語義歧義:為“行話”和“黑話”(如“華東大區(qū)”)提供明確的定義和范圍,消除AI的猜測(cè)空間。
- 提升查詢準(zhǔn)確性:通過預(yù)設(shè)的規(guī)則和邏輯,引導(dǎo)AI在正確的道路上進(jìn)行思考和轉(zhuǎn)換,從源頭上避免錯(cuò)誤SQL的生成。
- 增強(qiáng)系統(tǒng)可信度:詞典的配置過程由業(yè)務(wù)專家主導(dǎo),其內(nèi)容可讀、可管理、可驗(yàn)證,打破了“黑盒”狀態(tài),建立了用戶信任。
三、實(shí)戰(zhàn)指南:在DataFocus中構(gòu)建你的業(yè)務(wù)詞典
理論的價(jià)值在于實(shí)踐。DataFocus平臺(tái)提供了強(qiáng)大的后臺(tái)配置功能,讓企業(yè)可以輕松構(gòu)建和維護(hù)自己的業(yè)務(wù)詞典。以下是一份可直接上手的操作指南。
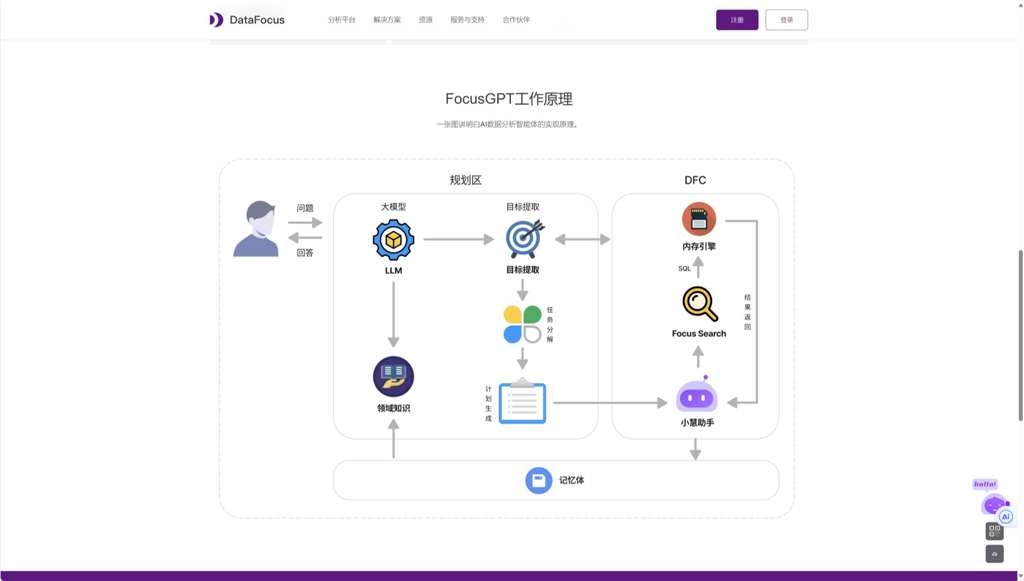
DataFocus的FocusGPT工作原理,其中“領(lǐng)域知識(shí)”和“記憶體”構(gòu)成了ChatBI理解業(yè)務(wù)的核心
第一步:定義核心指標(biāo) —— 使用“指標(biāo)公式”
對(duì)于企業(yè)中計(jì)算邏輯復(fù)雜的關(guān)鍵指標(biāo),應(yīng)使用“指標(biāo)公式”功能進(jìn)行統(tǒng)一定義。這確保了指標(biāo)在任何分析場(chǎng)景下的一致性。
-
定位功能:在DataFocus的“數(shù)據(jù)表管理”或“數(shù)據(jù)集”詳情頁中,找到“添加指標(biāo)公式列”功能。
-
創(chuàng)建公式:以“GMV”為例,業(yè)務(wù)人員可以像在Excel中一樣,使用平臺(tái)提供的函數(shù)和數(shù)據(jù)列來定義它。
-- 指標(biāo)公式名稱: GMV -- 公式內(nèi)容: sum(訂單金額) - sum(if(訂單狀態(tài)='已取消', 訂單金額, 0)) - sum(if(訂單狀態(tài)='已退款', 訂單金額, 0)) -
應(yīng)用:創(chuàng)建后,“GMV”就成了一個(gè)可直接被搜索和引用的“虛擬數(shù)據(jù)列”。當(dāng)用戶提問“各產(chǎn)品線的GMV是多少”時(shí),F(xiàn)ocusGPT會(huì)直接調(diào)用這個(gè)預(yù)設(shè)的、準(zhǔn)確的公式進(jìn)行計(jì)算,而無需猜測(cè)其含義。
第二步:翻譯“行話”與“黑話” —— 配置“搜索拓展”
對(duì)于業(yè)務(wù)中常用的別名、簡(jiǎn)稱和自定義分組,可以通過“搜索拓展”功能,為AI建立一個(gè)同義詞和自定義關(guān)鍵詞庫。
- 定位功能:在“系統(tǒng)管理”的“搜索配置”模塊,或單個(gè)數(shù)據(jù)表的“詳情”頁中,可以找到“搜索拓展”相關(guān)設(shè)置。
- 配置同義詞:為數(shù)據(jù)表中的具體值(列中值)添加別名。
- 場(chǎng)景:銷售區(qū)域數(shù)據(jù)中存的是“華東區(qū)”,但業(yè)務(wù)人員習(xí)慣稱之為“江浙滬”或“包郵區(qū)”。
- 操作:選擇“教材_電商銷售數(shù)據(jù)”表中的“區(qū)域”列,為列中值“華東”添加同義詞“江浙滬”、“包郵區(qū)”。
- 效果:配置后,用戶搜索“江浙滬的銷售額”,系統(tǒng)能自動(dòng)理解其等同于“華東區(qū)的銷售額”。
- 配置自定義關(guān)鍵詞:創(chuàng)建代表復(fù)雜篩選條件的自定義短語。
- 場(chǎng)景:需要頻繁分析“一線城市”的數(shù)據(jù),而“一線城市”并非數(shù)據(jù)庫中的一個(gè)字段。
- 操作:新增一個(gè)自定義關(guān)鍵詞,命名為“一線城市”,并將其定義為篩選條件
城市 in ('北京', '上海', '廣州', '深圳')。 - 效果:用戶可以直接搜索“一線城市的用戶數(shù)”,系統(tǒng)會(huì)自動(dòng)應(yīng)用背后復(fù)雜的篩選邏輯。
第三步:管理與迭代
業(yè)務(wù)詞典的構(gòu)建并非一蹴而就。企業(yè)應(yīng)指定專人或團(tuán)隊(duì)(如數(shù)據(jù)分析師、業(yè)務(wù)部門接口人)負(fù)責(zé)維護(hù)這份詞典,并根據(jù)業(yè)務(wù)發(fā)展和用戶反饋,持續(xù)地添加新術(shù)語、優(yōu)化舊定義,讓ChatBI的知識(shí)庫與企業(yè)共同成長(zhǎng)。
四、超越詞典:引入“人機(jī)協(xié)同”的智能交互
一個(gè)頂級(jí)的ChatBI系統(tǒng),除了擁有一個(gè)強(qiáng)大的業(yè)務(wù)詞典,還應(yīng)具備在交互中學(xué)習(xí)和澄清的能力。當(dāng)遇到詞典無法覆蓋的模糊問題時(shí),系統(tǒng)不應(yīng)直接返回錯(cuò)誤答案,而是主動(dòng)與用戶溝通,尋求澄清。

智能的ChatBI系統(tǒng)能通過反問、追問等方式引導(dǎo)用戶,實(shí)現(xiàn)“人機(jī)在環(huán)”的精準(zhǔn)分析
例如,當(dāng)用戶提出“我想看一下最近的銷售情況”這種模糊查詢時(shí),一個(gè)更智能的系統(tǒng)(如資料中提到的SwiftAgent)會(huì)主動(dòng)提供選項(xiàng),如“您是指‘最近7天銷售額’,還是‘本月至今銷售額’?”,通過這種“用戶可干預(yù)”(Human in the Loop)的機(jī)制,引導(dǎo)用戶明確意圖,從而確保最終分析的準(zhǔn)確性。這種持續(xù)學(xué)習(xí)和反思的能力,是ChatBI從一個(gè)“工具”進(jìn)化為“伙伴”的關(guān)鍵。
五、結(jié)論:讓ChatBI成為真正的數(shù)據(jù)驅(qū)動(dòng)引擎
ChatBI的問答準(zhǔn)確率,并非完全由底層AI模型的能力決定,更大程度上取決于我們?nèi)绾螢槠洹笆跇I(yè)解惑”。通過系統(tǒng)性地構(gòu)建和維護(hù)一個(gè)精準(zhǔn)的、與企業(yè)業(yè)務(wù)深度綁定的術(shù)語詞典,我們可以有效地填平語義鴻溝,將ChatBI的潛力真正釋放出來。
這不僅是技術(shù)層面的優(yōu)化,更是一次管理思想的升級(jí)。它要求企業(yè)將數(shù)據(jù)治理和知識(shí)管理融入日常運(yùn)營(yíng),將業(yè)務(wù)人員的隱性知識(shí)轉(zhuǎn)化為系統(tǒng)可理解的顯性規(guī)則。唯有如此,ChatBI才能擺脫“花瓶”的宿命,成為賦能每一位員工、加速企業(yè)決策、推動(dòng)業(yè)務(wù)增長(zhǎng)的強(qiáng)大引擎。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)