
AI編程:代碼多,效果好?
 捏著鼻子用多了就會發現:各家模型都有自己擅長的能力,這與不同平臺所掌握的優質數據有關系,比如電商跨境,本地生活,內容制作,行業分析等。
捏著鼻子用多了就會發現:各家模型都有自己擅長的能力,這與不同平臺所掌握的優質數據有關系,比如電商跨境,本地生活,內容制作,行業分析等。
七號樓專欄,大模型測評第01期。
一、簡介
2024年AI編程剛有熱度,互聯網又嗅到降本增效的味道。
入職場到現在,記憶里還有低代碼,超級SaaS,數字化轉型,大模型,AI應用之編程;這些新概念的出場,都是在各種罵罵咧咧中,深夜王炸的吹噓聲中。
沿著信息化,數字化,智能化的方向持續推進。
在2024上半年,當時還在職場悠哉悠哉的劃水,公司已經開始火急火燎的推廣AI工具,其中以視覺設計和編程兩個崗位最直接。
市場認可的AI工具,直接買最貴的會員。
當時自己在做電商的供應鏈,對于業務模式一知半解,所以在嘗試大模型梳理業務,業務理清楚就拆分數據模型,然后投給AI編程工具,直接設計數據表結構。
那會AI還只能輔助寫代碼,核心業務工程還得靠自己手搓。
部門當時流傳一句玩笑:用自己熟練的技能訓練AI,等AI熟練后再替代自己,約等于我助推自己失業。
沒過多久,那句玩笑話就扎心了。
在2024年,還只是間歇性體驗一下大模型的能力水平;到2025年中,已經踩著AI風口,走上獨立開發的探索。
AI編程的回旋鏢,還是落在了程序員的手里。
二、測評指標
獨立開發之后,整天在各種模型和AI插件里切換。
捏著鼻子用多了就會發現:各家模型都有自己擅長的能力,這與不同平臺所掌握的優質數據有關系,比如電商跨境,本地生活,內容制作,行業分析等。
今年各家大模型,似乎都卷向了編程領域。
從現象來說,人工智能帶火了獨立開發賽道,這是一個龐大且有確定性的市場;從本質來說,編程的內核是結構和數學算法,很適配大模型在應用層的探索。
比較有意思的是:在今天剛發布的GPT5,從官方簡介和部分測評來看,也號稱編程能力一騎絕塵。
對于很多開發者來說,當積累一定的能力和年齡之后,我們都傾向等一個好的創業團隊,等一個好的想法和產品,甚至很多想法在反復思考后,總覺得不夠完美,或者無法實現。
在人工智能快速發展的當下,借助大模型的編程能力,可以快速的實現產品并進行傳播測試。
嘗試機會的過程中,再次尋找機會。
本期的內容,站在一個普通開發者的角度,來綜合測評一下AI的編程能力。
參與的模型只有國內四款:DeepSeek,通義千問,Kimi,智譜。
作為一個開發者,更多關注的是:代碼量,代碼質量,呈現效果;選擇前端編程領域,可以看到實時的效果,目的是探索大模型編程的能力邊界。
備注:本次測試的錄屏會上傳視頻號,源碼會完整不動的上傳Git倉庫,有興趣的朋友自行查閱。
三、定制的需求
3.1 提示詞
基礎需求
使用前端編程語言,開發一款復雜的Web網站,涉及大模型信息采集和展示;進行數據分析,給用戶提供有價值的參考;做一個社區板塊,可以交流各種模型的使用案例;總共分為3個模塊,每個模塊都要填充一定的模擬數據,并且支持全站檢索功能;視覺追求創意和科技感;考慮問題的復雜性,需要先設計工程架構再編寫代碼。
規則約束
第一輪:代碼必須輸出1000行以上,完整的放在一個html文件中,可以直接預覽。
第二輪:代碼必須輸出5000行以上,完整的放在一個html文件中,可以直接預覽。
這里簡單提一句,為什么以1000行代碼為基準,當時第一次被DeepSeek能力驚艷到,就是它能穩定輸出千行代碼,并且質量高可以運行。
實際上自己還是沉浸在:已有的理解和習慣中。
最近的AI編程測評,依舊沿用1000行為基準,但是從測試效果看,上述四款模型:單次輸出2-3K行代碼,可以兼顧代碼數量和質量。
3.2 四款模型測試
使用相同的需求和不同的約束規則,讓上述四款模型分別執行。
首先測試1000行代碼的輸出能力,在本次回答中,四款模型的效果如下:

DeepSeek:輸出1500行代碼,布局結構和效果為本輪測試最好;
KimiK2:輸出800行代碼,出現問題只能展示主頁;
千問:輸出1600行代碼,布局完善但視覺效果一般,存在明顯問題;
智譜:輸出1200行代碼,布局一般,功能相對完善。
再次測試5000行代碼的輸出能力,在本次回答中,四款模型的效果如下:
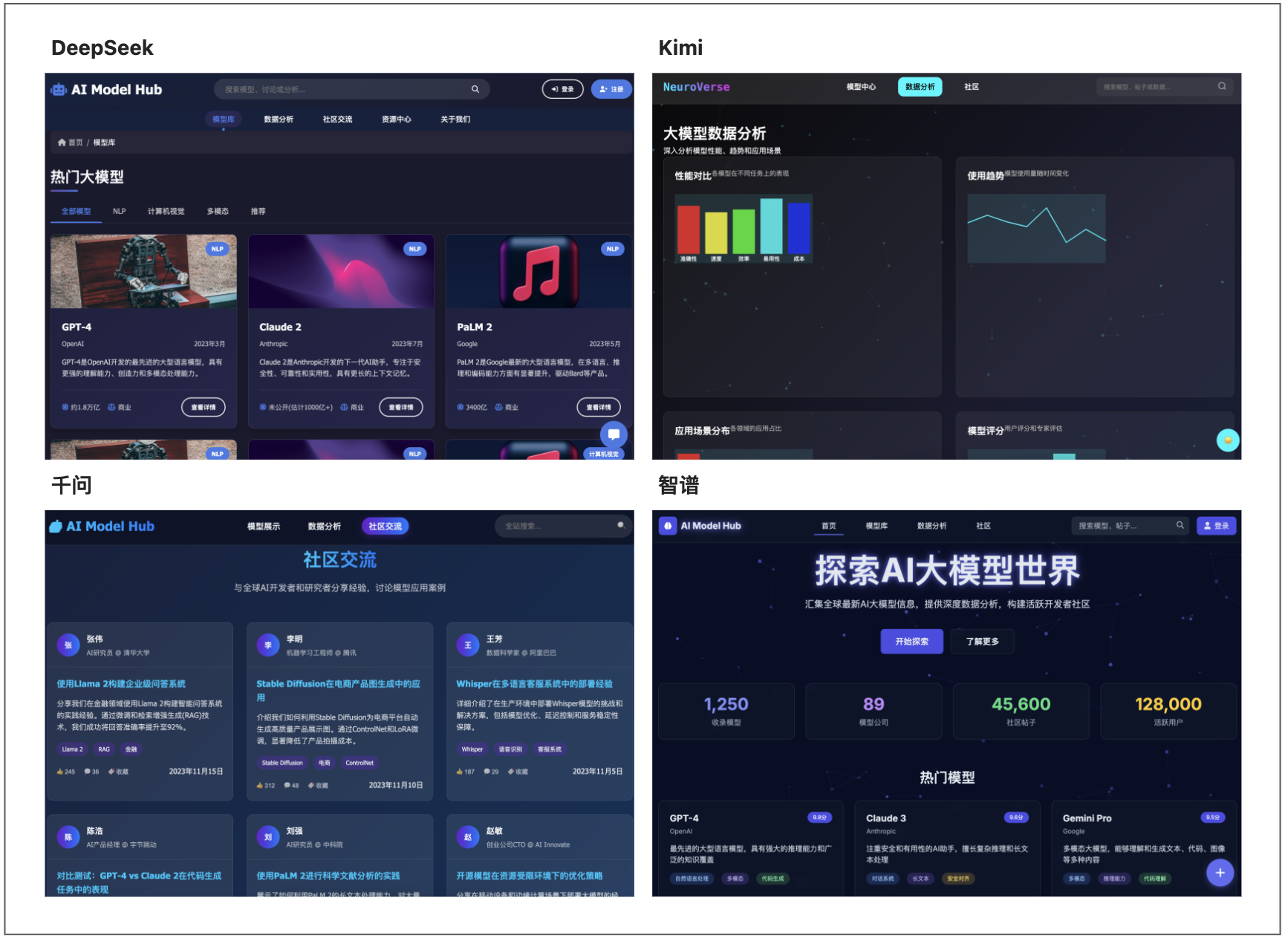
DeepSeek:輸出3200行代碼,只能加載首頁且速度很慢,整體結構略崩;
KimiK2:輸出1900行代碼,加載流暢,但是布局效果一般;
千問:輸出1400行代碼,布局和功能都非常完善;
智譜:輸出3200行代碼,視覺和布局都是本輪測試最佳,但是中間進行了一次干預,才輸出較復雜的代碼。
所有模型代碼輸出都不足5000行,于是又挨個問了下面的問題:
請說明一下:是因為計算資源問題,還是模型能力問題,導致代碼輸出不夠5000行?更多的回答是Token長度限制,還有就是考慮編程的工程規范,代碼的精簡和高效。
其實還可以測一測:用最精簡的代碼實現需求。
四、模型自由發揮
上面測試中,給模型指定了需求,本輪測試降低提示詞要求,但是為了可以比較,還是約束前端編程和2000行代碼。
更考驗大模型的想象能力,提示詞:
使用前端編程語言做一個網頁,做什么你自己發揮想象,功能要盡可能完善,視覺要有質感,編程只有一個要求:純代碼超過2000行,放在一個html文件中,可以直接預覽。
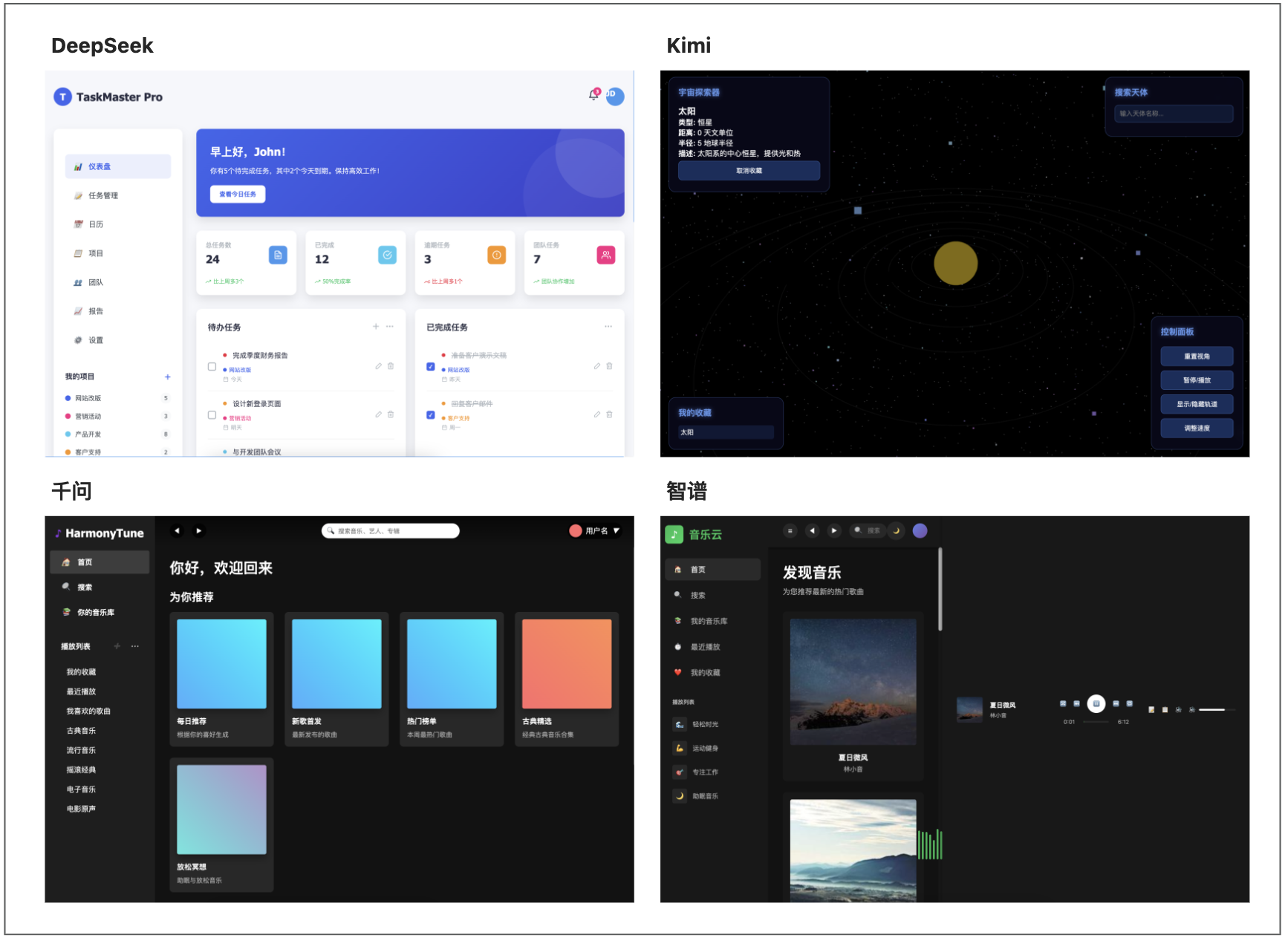
DeepSeek:輸出2100行代碼,做的是任務管理儀表盤網頁,為本輪測試最佳;
KimiK2:輸出800行代碼,做的是3D宇宙可視化應用;
千問:輸出1300行代碼,做的是音樂播放器網頁;
智譜:輸出1600行代碼,做的是在線音樂播放器應用。
基于最近AI編程的使用和調研,以及上面的測評案例來說,DeepSeek的綜合能力,輸入信息的理解,以及內容輸出的穩定性和質量。
在前端編程這個測試場景中,個人感覺效果最佳。
每個模型也都有能力突出的地方,KimiK2的視覺能力,智譜的布局結構,千問的功能完善;不同需求的側重點不一樣,按需選擇即可。
五、最后總結
做大模型編程測試,其中一方面是想看看不同模型的編程能力邊界,另一方面也是想在測試中挖掘想法。
希望這些模型的能力,能夠不斷的完善提高,先匯聚到一款模型上也可以,記得某天上午:付費的AI編程工具服務全部宕機,居然再次靠搜索解決問題。
搜索引擎:我到底能不能被AI替代,回答我!
模型測評Git倉庫
https://gitee.com/t_qhl/model-chaos
知識歸檔Git倉庫
https://gitee.com/cicadasmile/butte-java-note

 浙公網安備 33010602011771號
浙公網安備 33010602011771號