
Hadoop之HDFS概念
@
- HDFS是Hadoop Distribute File System 的簡(jiǎn)稱(chēng),意為:Hadoop分布式文件系統(tǒng)。是Hadoop核心組件之一
1. HDFS設(shè)計(jì)目標(biāo)
- 硬件故障是常態(tài), HDFS將有成百上千的服務(wù)器組成,每一個(gè)組成部分都有可能出現(xiàn)故障。因此故障的檢測(cè)和自動(dòng)快速恢復(fù)是HDFS的核心架構(gòu)目標(biāo)。
- HDFS上的應(yīng)用與一般的應(yīng)用不同,它們主要是以流式讀取數(shù)據(jù)。(可以理解為:來(lái)一點(diǎn),處理一點(diǎn),就象看網(wǎng)絡(luò)上的黃片一樣,你永遠(yuǎn)不知道下一幀是啥)HDFS被設(shè)計(jì)成適合批量處理,而不是用戶交互式的。相較于數(shù)據(jù)訪問(wèn)的反應(yīng)時(shí)間,更注重?cái)?shù)據(jù)訪問(wèn)的高吞吐量。
- 典型的HDFS文件大小是GB到TB的級(jí)別。所以,HDFS被調(diào)整成支持大文件。它應(yīng)該提供很高的聚合數(shù)據(jù)帶寬,一個(gè)集群中支持?jǐn)?shù)百個(gè)節(jié)點(diǎn),一個(gè)集群中還應(yīng)該支持千萬(wàn)級(jí)別的文件。
- 大部分HDFS應(yīng)用對(duì)文件要求的是write-one-read-many(寫(xiě)少讀多)訪問(wèn)模型。一個(gè)文件一旦創(chuàng)建、寫(xiě)入、關(guān)閉之后就不需要修改了。這一假設(shè)簡(jiǎn)化了數(shù)據(jù)一致性問(wèn)題,使高吞吐量的數(shù)據(jù)訪問(wèn)成為可能。
- 移動(dòng)計(jì)算的代價(jià)比之移動(dòng)數(shù)據(jù)的代價(jià)低。一個(gè)應(yīng)用請(qǐng)求的計(jì)算,離它操作的數(shù)據(jù)越近就越高效,這在數(shù)據(jù)達(dá)到海量級(jí)別的時(shí)候更是如此。將計(jì)算移動(dòng)到數(shù)據(jù)附近,比之將數(shù)據(jù)移動(dòng)到應(yīng)用所在顯然更好。
- 在異構(gòu)的硬件和軟件平臺(tái)上的可移植性。這將推動(dòng)需要大數(shù)據(jù)集的應(yīng)用更廣泛地采用HDFS作為平臺(tái)。
2. HDFS重要特性
2.1.主從架構(gòu)
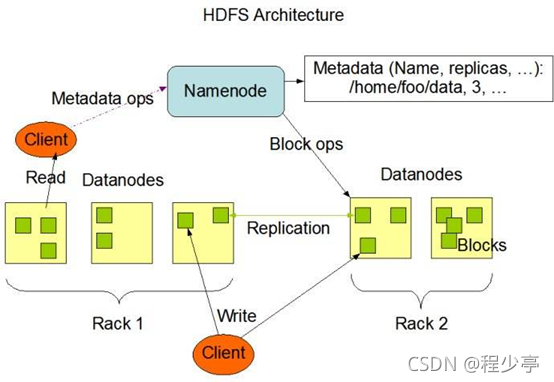
HDFS采用master/slave架構(gòu)。一般一個(gè)HDFS集群是有一個(gè)Namenode和一定數(shù)目的Datanode組成。
Namenode是HDFS集群主節(jié)點(diǎn),Datanode是HDFS集群從節(jié)點(diǎn),兩種角色各司其職,共同協(xié)調(diào)完成分布式的文件存儲(chǔ)服務(wù)。
2.2. 分塊存儲(chǔ)
HDFS中的文件在物理上是分塊存儲(chǔ)(block)的,塊的大小可以通過(guò)配置參數(shù)來(lái)規(guī)定,默認(rèn)大小在hadoop2.7.3版本后是128M,之前版本的默認(rèn)值是64M.
2.3. 名字空間(NameSpace)
HDFS支持傳統(tǒng)的層次型文件組織結(jié)構(gòu)。用戶或者應(yīng)用程序可以創(chuàng)建目錄,然后將文件保存在這些目錄里。文件系統(tǒng)名字空間的層次結(jié)構(gòu)和大多數(shù)現(xiàn)有的文件系統(tǒng)類(lèi)似:用戶可以創(chuàng)建、刪除、移動(dòng)或重命名文件。
Namenode負(fù)責(zé)維護(hù)文件系統(tǒng)的名字空間,任何對(duì)文件系統(tǒng)名字空間或?qū)傩缘男薷亩紝⒈籒amenode記錄下來(lái)。
HDFS會(huì)給客戶端提供一個(gè)統(tǒng)一的抽象目錄樹(shù),客戶端通過(guò)路徑來(lái)訪問(wèn)文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
2.4. Namenode元數(shù)據(jù)管理
我們把目錄結(jié)構(gòu)及文件分塊位置信息叫做元數(shù)據(jù)。Namenode負(fù)責(zé)維護(hù)整個(gè)hdfs文件系統(tǒng)的目錄樹(shù)結(jié)構(gòu),以及每一個(gè)文件所對(duì)應(yīng)的block塊信息(block的id,及所在的datanode服務(wù)器)。
2.5. Datanode數(shù)據(jù)存儲(chǔ)
文件的各個(gè)block的具體存儲(chǔ)管理由datanode節(jié)點(diǎn)承擔(dān)。每一個(gè)block都可以在多個(gè)datanode上。Datanode需要定時(shí)向Namenode匯報(bào)自己持有的block信息。
2.6. 副本機(jī)制
為了容錯(cuò),文件的所有block都會(huì)有副本。每個(gè)文件的block大小和副本系數(shù)都是可配置的。應(yīng)用程序可以指定某個(gè)文件的副本數(shù)目。副本系數(shù)可以在文件創(chuàng)建的時(shí)候指定,也可以在之后改變。
副本數(shù)量也可以通過(guò)參數(shù)設(shè)置dfs.replication,默認(rèn)是3。
2.7. 一次寫(xiě)入,多次讀出
HDFS是設(shè)計(jì)成適應(yīng)一次寫(xiě)入,多次讀出的場(chǎng)景,且不支持文件的修改。
正因?yàn)槿绱耍琀DFS適合用來(lái)做大數(shù)據(jù)分析的底層存儲(chǔ)服務(wù),并不適合用來(lái)做.網(wǎng)盤(pán)等應(yīng)用,因?yàn)椋薷牟环奖悖舆t大,網(wǎng)絡(luò)開(kāi)銷(xiāo)大,成本太高。
1. NameNode概述
a、 NameNode是HDFS的核心。
b、 NameNode也稱(chēng)為Master。
c、 NameNode僅存儲(chǔ)HDFS的元數(shù)據(jù):文件系統(tǒng)中所有文件的目錄樹(shù),并跟蹤整個(gè)集群中的文件。
d、 NameNode不存儲(chǔ)實(shí)際數(shù)據(jù)或數(shù)據(jù)集。數(shù)據(jù)本身實(shí)際存儲(chǔ)在DataNodes中。
e、 NameNode知道HDFS中任何給定文件的塊列表及其位置。使用此信息NameNode知道如何從塊中構(gòu)建文件。
f、 NameNode并不持久化存儲(chǔ)每個(gè)文件中各個(gè)塊所在的DataNode的位置信息,這些信息會(huì)在系統(tǒng)啟動(dòng)時(shí)從數(shù)據(jù)節(jié)點(diǎn)重建。
g、 NameNode對(duì)于HDFS至關(guān)重要,當(dāng)NameNode關(guān)閉時(shí),HDFS / Hadoop集群無(wú)法訪問(wèn)。
h、 NameNode是Hadoop集群中的單點(diǎn)故障。
i、 NameNode所在機(jī)器通常會(huì)配置有大量?jī)?nèi)存(RAM)
2. DataNode概述
a、 DataNode負(fù)責(zé)將實(shí)際數(shù)據(jù)存儲(chǔ)在HDFS中。
b、 DataNode也稱(chēng)為Slave。
c、 NameNode和DataNode會(huì)保持不斷通信。
d、 DataNode啟動(dòng)時(shí),它將自己發(fā)布到NameNode并匯報(bào)自己負(fù)責(zé)持有的塊列表。
e、 當(dāng)某個(gè)DataNode關(guān)閉時(shí),它不會(huì)影響數(shù)據(jù)或群集的可用性。NameNode將安排由其他DataNode管理的塊進(jìn)行副本復(fù)制。
f、 DataNode所在機(jī)器通常配置有大量的硬盤(pán)空間。因?yàn)閷?shí)際數(shù)據(jù)存儲(chǔ)在DataNode中。
g、 DataNode會(huì)定期(dfs.heartbeat.interval配置項(xiàng)配置,默認(rèn)是3秒)向NameNode發(fā)送心跳,如果NameNode長(zhǎng)時(shí)間沒(méi)有接受到DataNode發(fā)送的心跳, NameNode就會(huì)認(rèn)為該DataNode失效。
h、 block匯報(bào)時(shí)間間隔取參數(shù)dfs.blockreport.intervalMsec,參數(shù)未配置的話默認(rèn)為6小時(shí).
3. HDFS的工作機(jī)制
- NameNode負(fù)責(zé)管理整個(gè)文件系統(tǒng)元數(shù)據(jù);DataNode負(fù)責(zé)管理具體文件數(shù)據(jù)塊存儲(chǔ);
- Secondary,NameNode協(xié)助NameNode進(jìn)行元數(shù)據(jù)的備份。
- HDFS的內(nèi)部工作機(jī)制對(duì)客戶端保持透明,客戶端請(qǐng)求訪問(wèn)HDFS都是通過(guò)向NameNode申請(qǐng)來(lái)進(jìn)行。
3.1 HDFS寫(xiě)數(shù)據(jù)流程
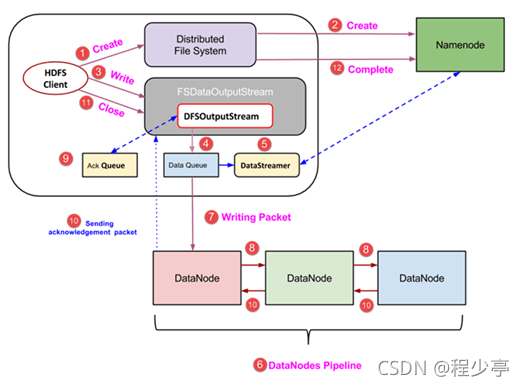
詳細(xì)步驟解析:
1、客戶端也就是hdfs發(fā)起文件上傳的請(qǐng)求 ,這個(gè)時(shí)候他們通過(guò)RPC協(xié)議與集群中的NameNode建立連接,Namenode開(kāi)始檢查要上傳的文件的父目錄是否存在,返回消息通知hdfs是否可以上傳.
2、 client請(qǐng)求第一個(gè) block該傳輸?shù)侥男〥ataNode服務(wù)器上;
3、 NameNode根據(jù)配置文件中指定的備份數(shù)量及副本放置策略進(jìn)行文件分配,返回可用的DataNode的地址,如:A,B,C;
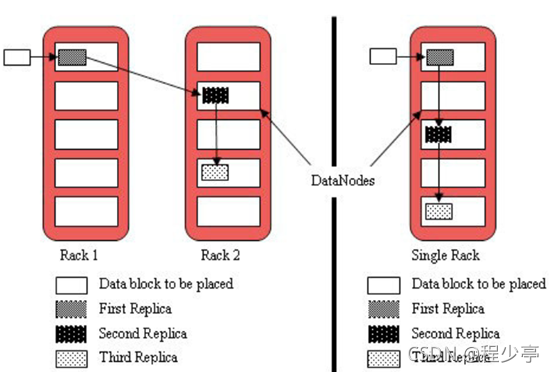
注:默認(rèn)存儲(chǔ)策略由BlockPlacementPolicyDefault(塊放置策略默認(rèn)值 )類(lèi)支持。也就是日常生活中提到最經(jīng)典的3副本策略。
1st replica 如果寫(xiě)請(qǐng)求方所在機(jī)器是其中一個(gè)datanode,則直接存放在本地,否則隨機(jī)在集群中選擇一個(gè)datanode.
2nd replica 第二個(gè)副本存放于不同第一個(gè)副本的所在的機(jī)架.
3rd replica 第三個(gè)副本存放于第二個(gè)副本所在的機(jī)架,但是屬于不同的節(jié)點(diǎn)
4、 client請(qǐng)求3臺(tái)DataNode中的一臺(tái)A上傳數(shù)據(jù)(本質(zhì)上是一個(gè)RPC調(diào)用,建立pipeline),A收到請(qǐng)求會(huì)繼續(xù)調(diào)用B,然后B調(diào)用C,將整個(gè)pipeline建立完成,后逐級(jí)返回client;
5、 client開(kāi)始往A上傳第一個(gè)block(先從磁盤(pán)讀取數(shù)據(jù)放到一個(gè)本地內(nèi)存緩存),以packet為單位(默認(rèn)64K),A收到一個(gè)packet就會(huì)傳給B,B傳給C;A每傳一個(gè)packet會(huì)放入一個(gè)應(yīng)答隊(duì)列等待應(yīng)答。
6、 數(shù)據(jù)被分割成一個(gè)個(gè)packet數(shù)據(jù)包在pipeline上依次傳輸,在pipeline反方向上,逐個(gè)發(fā)送ack(命令正確應(yīng)答),最終由pipeline中第一個(gè)DataNode節(jié)點(diǎn)A將pipeline ack發(fā)送給client;
7、 當(dāng)一個(gè)block傳輸完成之后,client再次請(qǐng)求NameNode上傳第二個(gè)block到服務(wù)器。
3.2. HDFS讀數(shù)據(jù)流程
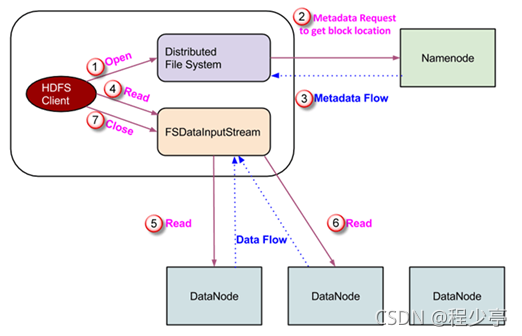
詳細(xì)步驟解析:
1、 Client向NameNode發(fā)起RPC請(qǐng)求,來(lái)確定請(qǐng)求文件block所在的位置;
2、 NameNode會(huì)視情況返回文件的部分或者全部block列表,對(duì)于每個(gè)block,NameNode都會(huì)返回含有該block副本的DataNode地址;
3、 這些返回的DN地址,會(huì)按照集群拓?fù)浣Y(jié)構(gòu)得出DataNode與客戶端的距離,然后進(jìn)行排序,排序兩個(gè)規(guī)則:網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)中距離Client近的排靠前;心跳機(jī)制中超時(shí)匯報(bào)的DN狀態(tài)為STALE,這樣的排靠后;
4、 Client選取排序靠前的DataNode來(lái)讀取block,如果客戶端本身就是DataNode,那么將從本地直接獲取數(shù)據(jù);
5、 底層上本質(zhì)是建立FSDataInputStream,重復(fù)的調(diào)用父類(lèi)DataInputStream的read方法,直到這個(gè)塊上的數(shù)據(jù)讀取完畢;一旦到達(dá)塊的末尾,DFSInputStream 關(guān)閉連接并繼續(xù)定位下一個(gè)塊的下一個(gè) DataNode;
6、 當(dāng)讀完列表的block后,若文件讀取還沒(méi)有結(jié)束,客戶端會(huì)繼續(xù)向NameNode獲取下一批的block列表;一旦客戶端完成讀取,它就會(huì)調(diào)用 close() 方法。
7、 讀取完一個(gè)block都會(huì)進(jìn)行checksum驗(yàn)證,如果讀取DataNode時(shí)出現(xiàn)錯(cuò)誤,客戶端會(huì)通知NameNode,然后再?gòu)南乱粋€(gè)擁有該block副本的DataNode繼續(xù)讀。
8、 NameNode只是返回Client請(qǐng)求包含塊的DataNode地址,并不是返回請(qǐng)求塊的數(shù)據(jù);
9、 最終讀取來(lái)所有的block會(huì)合并成一個(gè)完整的最終文件。
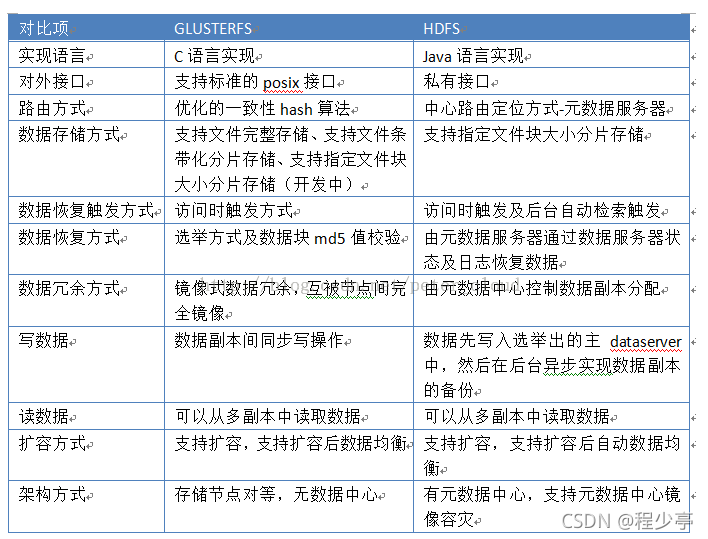
學(xué)習(xí)的時(shí)候發(fā)現(xiàn)這個(gè)竟然和Glusterfs有些相似 在網(wǎng)上找了一張對(duì)比圖片 后面也會(huì)把Google的GFS的的論文發(fā)出來(lái)供大家參考 目前來(lái)說(shuō) 分布式存儲(chǔ)都有些萬(wàn)變不離其宗的意思
GFS論文
提取碼:aq4w
--來(lái)自百度網(wǎng)盤(pán)超級(jí)會(huì)員V1000的分享
過(guò)期可以私聊我

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)